Artificial Intelligence
Build a system for catching adverse events in real-time using Amazon SageMaker and Amazon QuickSight
Social media platforms provide a channel of communication for consumers to talk about various products, including the medications they take. For pharmaceutical companies, monitoring and effectively tracking product performance provides customer feedback about the product, which is vital to maintaining and improving patient safety. However, when an unexpected medical occurrence resulting from a pharmaceutical product administration occurs, it’s classified as an adverse event (AE). This includes medication errors, adverse drug reactions, allergic reactions, and overdoses. AEs can happen anywhere: in hospitals, long-term care settings, and outpatient settings.
The objective of this post is to provide an example that showcases how to use Amazon SageMaker and pre-trained transformer models to detect AEs mentioned on social media. The model is fine-tuned on domain-specific data to perform a text classification task. We also use Amazon QuickSight to create a monitoring dashboard. Importantly, this post requires a Twitter developer account to obtain tweets. For the purposes of this demonstration, we only use publicly available tweets. While privacy and data governance is not explicitly discussed in this post, users should consider these processes and helpful resources can be found in AWS Marketplace and through featured AWS Partner Solutions for data governance. Following this demonstration, we deleted all the data used.
This post is meant to support overarching pharmacovigilance activities for the life sciences and pharmaceutical customers globally, though the reference architecture can be implemented for any customer. The model is trained on identifying adverse events and can be applicable to biotech, healthcare, and life sciences domains.
Solution overview
The following architecture diagram illustrates the workflow of the solution.

The workflow includes the following steps:
- Train a classification model using SageMaker training and deploy the trained model to an endpoint using SageMaker real-time inference.
- Create an AWS Cloud9 stream listener.
- Store live tweets in Amazon DynamoDB.
- Use DynamoDB Streams to trigger AWS Lambda to invoke the SageMaker endpoint for AE classification and call Amazon Comprehend Medical to detect symptoms and provide ICD-10 descriptions.
- Save tweets with their AE classification and symptoms in Amazon Simple Storage Service (Amazon S3) and use the AWS Glue Data Catalog to create table views.
- Analyze data from Amazon S3 using Amazon Athena.
- Create a QuickSight dashboard to monitor tweets and their AE status.
Set up the environment and implement the solution
We have created a template for the adverse event detection app using the AWS Cloud Development Kit (AWS CDK), an open-source software development framework to define your cloud application resources. Complete the following steps to run the solution end to end:
- Clone the GitHub repo either to your local machine that is configured with your AWS account and has the AWS Command Line Interface (AWS CLI) installed, or in an AWS Cloud9 environment within your AWS account:
After you clone the code repo, you can start the deployment process.
- Navigate to the project directory and create a virtual environment within this project that is stored under the
.venvdirectory. To manually create a virtual environment on macOS or Linux, use the following code: - After the virtual environment is created, activate the virtual environment:
- After the virtual environment is activated, install the required dependencies:
- At this point, you can now synthesize the AWS CloudFormation template:
cdk synth generates the CloudFormation template in JSON format as well as other necessary asset files for spinning up the resources. These files are stored in the cdk.out directory. The cdk deploy command then deploys the stack into your AWS account. You deploy two stacks: one is an S3 bucket stack and the other is the core adverse event app stack. The core app stack needs to be deployed after the Amazon S3 stack is successfully deployed. If you encounter any issues during the deployment process, refer to Troubleshooting common AWS CDK issues.
After the AWS CDK is successfully deployed, you need to train and deploy a model. On the Notebooks page of the SageMaker console, you should find a notebook instance named AdverseEventDetectionModeling. When you run the entire notebook (AE_model_train_deploy.ipynb), a SageMaker training job is launched and the model is deployed to a SageMaker endpoint. The model training data in this tutorial is based on the Adverse Drug Reaction dataset from Hugging Face but can be replaced with any other dataset.
Train and deploy a transformer model for adverse event classification
We fine-tune transformer models within the Hugging Face library for adverse event (AE) classifications. The training job is built using the SageMaker PyTorch estimator. For model deployment, we use PyTorch Model Server. In this section, we walk through the major steps for model training and deployment.
Data preparation
We use the Adverse Drug Reaction Data (ade_corpus_v2) within the Hugging Face dataset as the training and validation data. The required data structure for our model training and inference has two columns:
- One column for text content as model input data.
- Another column for the label class. We have two possible classes for a text: the
Not_AEclass and theAdverse_Eventclass.
We download the raw dataset and split it into training (80%) and validation (20%) datasets, rename the input and target columns to text and label respectively, and upload them to Amazon S3:
Our model also accepts multi-class classification, so you can bring your own dataset for model training.
Model training
We use the SageMaker built-in PyTorch estimator to fine-tune transformer models. The entry point script ./src/hf_train_deploy.py has the train() function for model training.
We have added a requirements.txt file within the script source folder ./src for a list of required packages. When you launch SageMaker training jobs, the SageMaker PyTorch container automatically looks for a requirements.txt file in the script source folder, and uses pip install to install the packages listed in that file.
In addition to batch size, sequence length, learning rate, you can also specify the model_name to choose any transformer models supported within the pre-trained model list of Hugging Face AutoModelForSequenceClassification. The column names for text and label are also needed to specified through the text_column and label_column parameters.
The following code is an example of setting hyperparameters for the model training:
Then we launch the training job:
Model deployment
We can directly deploy the PyTorch trained model using SageMaker real-time inference to an endpoint as long as the following prerequisite functions are provided within the entry point script hf_train_deploy.py:
model_fn(model_dir)for loading a model objectinput_fn(request_body, request_content_type)for loading an input text and tokenizing the textpredict_fn(input_data, model)for model prediction returning the probability value for each class
We deploy the model to a SageMaker endpoint for real-time inference with the following code:
Model serving
After the SageMaker endpoint is created, we can invoke the endpoint for real-time model inference through services like Lambda:
Set up the Twitter API stream listener for real-time data streaming
During the initial cdk deploy process, AWS CDK should have spun up an AWS Cloud9 environment in your account and cloned the code repo into the environment. We use AWS Cloud9 to host the Twitter API stream listener for live data streaming.
The Twitter API stream listener is composed of the following:
- stream_config.py – Parameters that authenticate the Twitter API and a pre-determined list of drug names to search for
- stream.py – Primarily used to keep the stream active, but also addresses other functionalities, such as processing users shared attributes and assessing if the drug mentions match the ones provided in
stream_config.py
The next step is to set up the Twitter API stream listener. After you obtain your consumer keys and authentication tokens from the Twitter developer portal, go into AWS Cloud9 under stream_config.py and provide the following information:
- Enter in the Twitter API credentials.
- Add drug names and rules of interest to obtain associated tweets; we have provided an example of drug names in the code.
- Enter
aws_access_key_idandaws_secret_access_key, respectively.

- Back in the AWS Cloud9 terminal, run the following commands to install the necessary packages and download
en_core_web_sm: - To activate the API stream listener, run the following command (make sure you’re in the
ae-blog-cdkfolder):
Run inference and crawl model prediction results
When the stream listener is active, incoming tweet data is stored in the DynamoDB table ae_tweets_ddb.

The Lambda function is triggered by Amazon DynamoDB Streams and invokes the model endpoint deployed from the SageMaker step. The function provides inference through the SageMaker deployed endpoint HF-BERT-AE-model to classify the incoming tweets as adverse events or not.
For all the tweets that are classified as adverse events, the Amazon Comprehend Medical API is used to obtain entities that detect signs, symptoms, and diagnosis of medical conditions, along with the list of ICD-10 codes and descriptions. For simplicity, we extract entities based on maximum score. The ICD-10 code and description allow us to bin the symptoms in a more normalized concept (for more information, see ICD-10-CM-linking). See the following code:
The Lambda function processes tweets and outputs predictions, associated entities, and ICD-10 codes to the S3 bucket folder lambda_predictions.
The AWS Glue crawler s3_tweets_crawler is created to crawl predictions in Amazon S3 and populate the Data Catalog, where the database s3_tweets_db and table lambda_predictions are created.

View tabular processed data using Amazon Athena
To provide stakeholders a holistic view of the tweets, you can use Athena to query the results from Amazon S3 (linked by the AWS Glue Data Catalog) and expand to create custom dashboards using QuickSight.
- If this is your first time using Athena, set up a location to save queries to an Amazon S3 location.
- Otherwise, configure to
s3_tweets_dbas shown in the model training. - Choose the
lambda_predictionstable and choose Preview table to generate a portion of your processed tweets.

The following screenshot is a custom SQL command to preview tweets associated towards a particular concept.

Create a dashboard with Amazon QuickSight
Building the QuickSight dashboard allows you to fully complete an end-to-end pipeline that publishes the analyses and inferences from our models. At a high level in QuickSight, you import the data using Athena and locate your Athena database and table that are linked to your S3 bucket. Make sure the user’s account has AWS Identity and Access Management (IAM) permissions to access Athena and Amazon S3 when using QuickSight.
- On the QuickSight console, choose Datasets in the navigation pane.
- Choose New dataset.
- Choose Athena as your data source.
- For Data source name, enter a name.
- When prompted, choose the database and table that contain the tweets that were processed through the Lambda function.
- Choose Use custom SQL.

- Change the New custom SQL name to
TweetsData(or your choice of name). - Enter the following SQL query:
- Choose Edit/Preview data.
- Select Import SPICE for quicker analysis.
We recommend importing the data using the Super-fast, Parallel, In-memory Calculation Engine (SPICE). Upon import, you can edit and visualize the data, as well as edit the data column type or rename columns towards your visuals. Furthermore, the SPICE dataset can be refreshed on a schedule, and ensure enough SPICE capacity is in place to incur charges from data refresh.
- Choose Visualize.
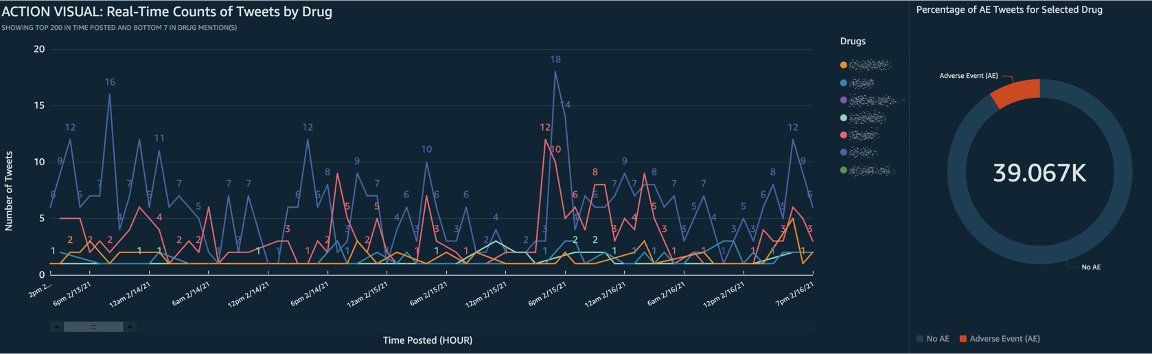
After the data is imported, you can begin to develop the analysis in the form of visuals along with custom actions for filtering and navigation to make panels more interactive. Lastly, you can publish the developed dashboard to be shared. The following screenshot shows example custom visualizations.
Clean up
Back in your AWS CDK stack, you can run the cdk destroy --all command to clean up all the resources used during this tutorial. If for any reason the command doesn’t run successfully, you can go to the AWS CloudFormation console and manually delete the stack. Also, if you created a dashboard using the data from this post, manually delete the data source and the associated dashboard within QuickSight.
Conclusion
With the expanding development of new pharmaceutical drugs comes increases in the number of associated adverse events—events that must be responsibly and efficiently monitored and reported. This post has detailed an end-to-end solution that uses SageMaker to build and deploy a classification model, Amazon Comprehend Medical to infer tweets, and Quicksight to detect possible adverse events from pharmaceutical products. This solution helps replace laborious manual reviewing with an automated machine learning process. To learn more about Amazon SageMaker, please visit the webpage.
About the Authors
 Prithiviraj Jothikumar, PhD, is a Data Scientist with AWS Professional Services, where he helps customers build solutions using machine learning. He enjoys watching movies and sports and spending time to meditate.
Prithiviraj Jothikumar, PhD, is a Data Scientist with AWS Professional Services, where he helps customers build solutions using machine learning. He enjoys watching movies and sports and spending time to meditate.
 Jason Zhu is a Sr. Data Scientist with AWS Professional Services where he leads building enterprise-level machine learning applications for customers. In his spare time, he enjoys being outdoors and growing his capabilities as a cook.
Jason Zhu is a Sr. Data Scientist with AWS Professional Services where he leads building enterprise-level machine learning applications for customers. In his spare time, he enjoys being outdoors and growing his capabilities as a cook.
 Rosa Sun is a Professional Services Consultant at Amazon Web Services. Outside of work, she enjoys walks in the rain, painting portraits, and hugging her dog.
Rosa Sun is a Professional Services Consultant at Amazon Web Services. Outside of work, she enjoys walks in the rain, painting portraits, and hugging her dog.
 Sai Sharanya Nalla is a Data Scientist at AWS Professional Services. She works with customers to develop and implement AI and ML solutions on AWS. In her spare time, she enjoys listening to podcasts and audiobooks, long walks, and engaging in outreach activities.
Sai Sharanya Nalla is a Data Scientist at AWS Professional Services. She works with customers to develop and implement AI and ML solutions on AWS. In her spare time, she enjoys listening to podcasts and audiobooks, long walks, and engaging in outreach activities.
 Shuai Cao is a Data Scientist in the Professional Services team at Amazon Web Services. His expertise is building machine learning applications at scale for healthcare and life sciences customers. Outside of work, he loves traveling around the world and playing dozens of different instruments.
Shuai Cao is a Data Scientist in the Professional Services team at Amazon Web Services. His expertise is building machine learning applications at scale for healthcare and life sciences customers. Outside of work, he loves traveling around the world and playing dozens of different instruments.