Artificial Intelligence
Create a cross-account machine learning training and deployment environment with AWS Code Pipeline
A continuous integration and continuous delivery (CI/CD) pipeline helps you automate steps in your machine learning (ML) applications such as data ingestion, data preparation, feature engineering, modeling training, and model deployment. A pipeline across multiple AWS accounts improves security, agility, and resilience because an AWS account provides a natural security and access boundary for your AWS resources. This can keep your production environment safe and available for your customers while keeping training separate.
However, setting up the necessary AWS Identity and Access Management (IAM) permissions for a multi-account CI/CD pipeline for ML workloads can be difficult. AWS provides solutions such as the AWS MLOps Framework and Amazon SageMaker Pipelines to help customers deploy cross-account ML pipelines quickly. However, customers still want to know how to set up the right cross-accounts IAM roles and trust relationships to create a cross-account pipeline while encrypting their central ML artifact store.
This post is aimed is at helping customers who are familiar with, and prefer AWS CodePipeline as their DevOps and automation tool of choice. Although we use machine learning DevOps (MLOps) as an example in this post, you can use this post as a general guide on setting up a cross-account pipeline in CodePipeline incorporating many other AWS services. For MLOps in general, we recommend using SageMaker Pipelines.
Architecture Overview
We deploy a simple ML pipeline across three AWS accounts. The following in an architecture diagram to represent what you will create.

For this post, we use three accounts:
- Account A – shared service account
- Account B – training account
- Account C – production account
- The shared service account (account A) holds an AWS CodeCommit repository, an Amazon Simple Storage Service (Amazon S3) bucket, an AWS Key Management Service (AWS KMS) key, and the CodePipeline. The Amazon S3 bucket contains training data in CSV format and the model artifacts. You can access the GitHub repo for sample files, policies, and templates.
- The pipeline, hosted in the first account, uses AWS CloudFormation to deploy an AWS Step Functions workflow to train an ML model in the training account (account B). When training completes, the pipeline invokes an AWS Lambda function to create an Amazon SageMaker model endpoint in the production account. You can use SageMaker Pipelines as a CI/CD service for ML. However, in this post, we use CodePipeline, which provides flexibility to span across accounts across AWS Organizations.
- To ensure security of your ML data and artifacts, the bucket policy denies any unencrypted uploads. For example, objects must by encrypted using the KMS key hosted in the shared service account. Additionally, only the CodePipeline and the relevant roles in the training account and the production account have permissions to use the KMS key.
- The CodePipeline references CodeCommit as the source provider and the Amazon S3 bucket as the artifact store. When the pipeline detects a change in the CodeCommit repository (for example, new training data is loaded in the Amazon S3), CodePipeline creates or updates the AWS CloudFormation stack in the training account. The stack creates a Step Function state machine. Lastly, CodePipeline invokes the state machine.
- The state machine starts a training job in the training account using SageMaker XGBoost Container on the training data in Amazon S3. Once training completes, it outputs the model artifact to the output path.
- CodePipeline waits for manual approval before the final stage of the pipeline to validate training results and ready for production.
- Once approved, Lambda deploys the model to a SageMaker endpoint for production in the production account (account C).
Deploy AWS CloudFormation Templates
If you want to follow along, clone the Git repository to your local machine. You must have:
- Access to three AWS accounts
- Git installed
- The latest version of the AWS Command Line Interface (CLI) installed
Run the following command to copy the Git repository.
In the shared service account (Account A)
- Navigate to the AWS CloudFormation console.
- Select Create stack.
- Select Upload a template file and select the a-cfn-blog.yml file. Select Next.
- Provide a stack name, a CodeCommit repo name, and the three AWS accounts used for the pipeline. Select Next.

- You can add tags. Otherwise, keep the default stack option configurations and select Next.
- Acknowledge that AWS CloudFormation might create IAM resources and Create stack.

It will take a few minutes for AWS CloudFormation to deploy the resources. We’ll use the outputs from the stack in A as input for the stacks in B and C.
In the training account (Account B)
- Select Create stack in the AWS CloudFormation console in the training account.
- Select Upload a template file and choose the b-cfn-blog.yml file. Select Next.
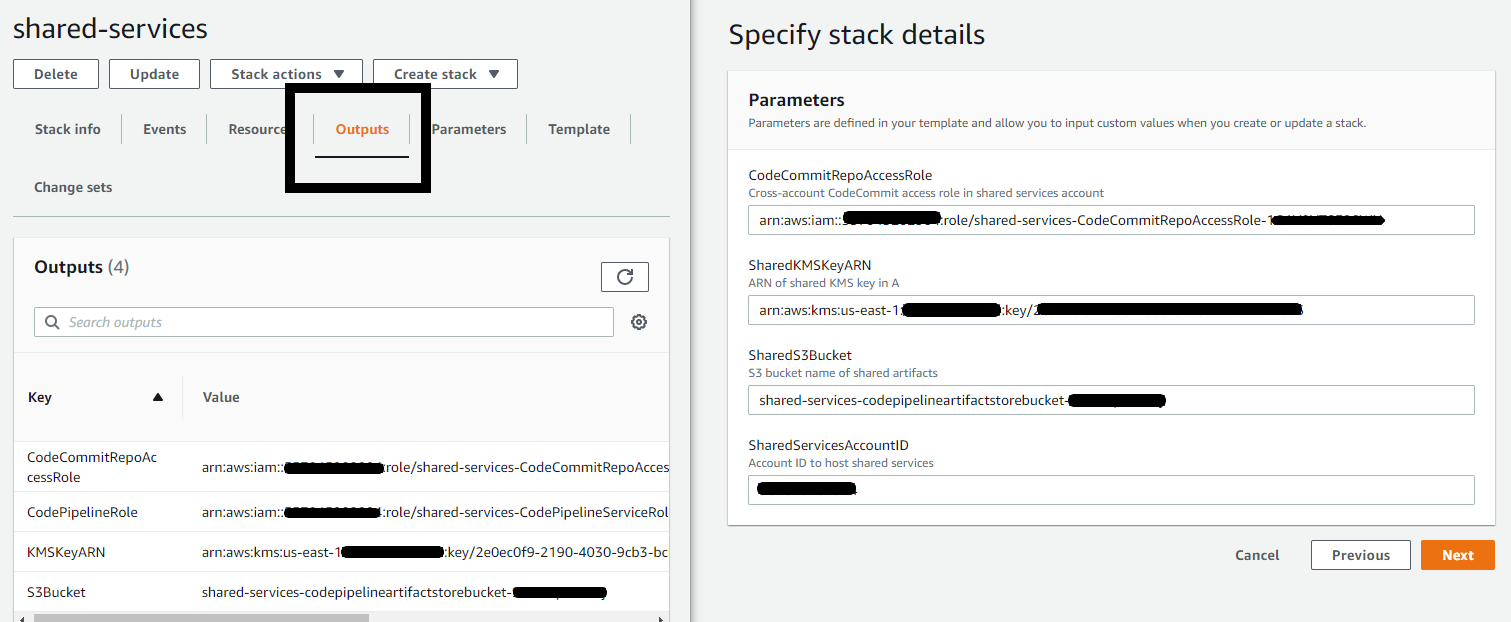
- Give the stack a name and provide the following parameters from the outputs in stack A:
- The role ARN for accessing CodeCommit in the shared service account
- The role ARN of the KMS key
- The shared S3 bucket name
- The AWS account ID for the shared service account
- Select Next.
- You can add tags. Otherwise, keep the default stack option configurations and select Next.
- Acknowledge that AWS CloudFormation might create IAM resources and Create stack.
In the production account (Account C)
- Select Create stack in the AWS CloudFormation console in the production account.
- Select Upload a template file and choose c-cfn-blog.yml file. Select Next.
- Provide the KMS key ARN, S3 bucket name, and shared service account ID. Select
- You can add tags. Otherwise, keep the default stack option configurations and select Next.
- Acknowledge that AWS CloudFormation might create IAM resources and Create stack.
AWS CloudFormation creates the required IAM policies, roles, and trust relationships for your cross-account pipeline. We’ll take the AWS resources and IAM roles created by the templates to populate our pipeline and step function workflow definitions.
Setting up the pipeline
To run the ML pipeline, you must update the pipeline and the Step Functions state machine definition files. You can download the files from the Git repository. Replace the string values within the angle brackets (e.g. ‘<TrainingAccountID >’) with the values created by AWS CloudFormation.
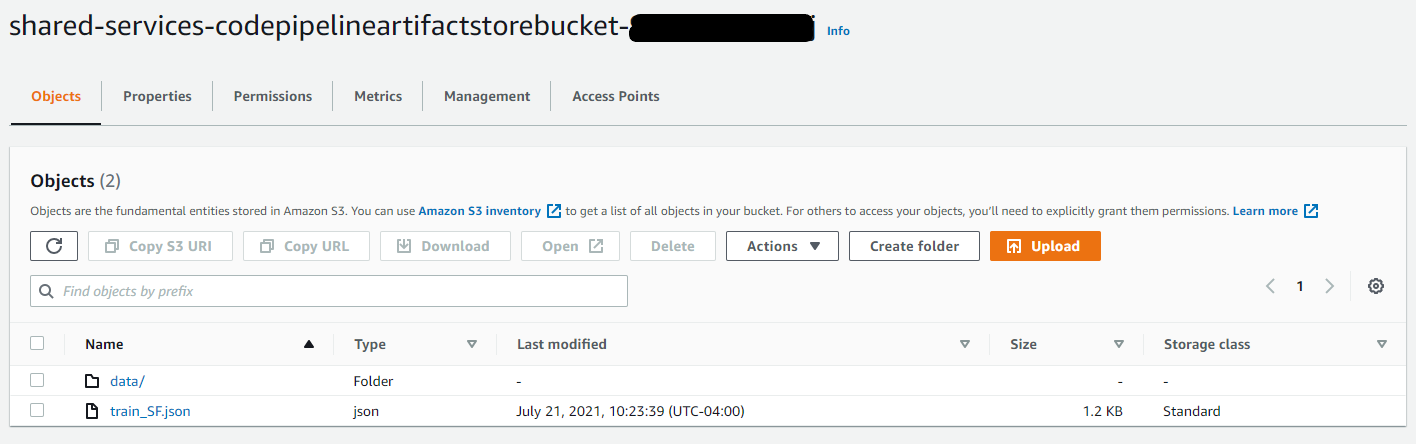
In the shared service account, navigate to the Amazon S3 console and select the Amazon S3 bucket created by AWS CloudFormation. Upload the train.csv file from the Git repository and place in a folder labeled ‘Data’. Additionally, upload the train_SF.json file in the home directory.
Note: The bucket policy denies any upload actions if not used with the KMS key. As a workaround, remove the bucket policy, upload the files, and re-apply the bucket policy.
On to the CodeCommit page select the repository created by AWS CloudFormation. Upload the sf-sm-train-demo.json file into the empty repository. The sf-sm-train-demo.json file should be updated with the values from the AWS CloudFormation template outputs. Provide a name, email, and optional message to the main branch and Commit changes.

Now that everything is set up, you can create and deploy the pipeline.
Deploying the pipeline
We secured our S3 bucket with the bucket policy and KMS key. Only the CodePipeline service role, and the cross-account roles created by the AWS CloudFormation template in the training and production accounts can use the key. The same applies to the CodeCommit repository. We can run the following command from the shared services account to create the pipeline.
After a successful response, the custom deploy-cf-train-test stage creates an AWS CloudFormation template in the training account. You can check the CodePipeline status in the console.
AWS CloudFormation Code deploys a Step Functions state machine to start a model training job by assuming the CodePipeline role in the shared services account. The cross-account role in the training account permits access to the S3 bucket, KMS key, CodeCommit repo, and pass role Step Functions state machine execution.

When the state machine successfully runs, the pipeline requests manual approval before the final stage. On the CodePipeline console choose Review and approve the changes. This moves the pipeline into the final stage of invoking the Lambda function to deploy the model.
When the training job completes, the Lambda function in the production account deploys the model endpoint. To do this, the Lambda function assumes the role in the shared service account to run the required PutJobSuccessResult CodePipeline command.

Congratulations! You’ve built the foundation for setting up a cross-account ML pipeline using CodePipeline for training and deployment. You can now see a live SageMaker endpoint in the shared service account created by the Lambda function in the production account.

Conclusion
In this blog post, you created a cross-account ML pipeline using AWS CodePipeline, AWS CloudFormation, and Lambda. You set up the necessary IAM policies and roles to enable this cross-account access using a shared services account to hold the ML artifacts in an S3 bucket and a customer managed KMS key for encryption. You deployed a pipeline where different accounts deployed different stages of the pipeline using AWS CloudFormation to create a Step Functions state machine for model training and Lambda to invoke it.
You can use the steps outlined here to set up cross-account pipelines to fit your workload. For example, you can use CodePipeline to safely deploy and monitor SageMaker endpoints. CodePipeline helps you automate steps in your software delivery process to enable agility and productivity for your teams. Contact your account team to learn how to you can get started today!
About the Authors
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 David Ping is a Principal Machine Learning Architect and Sr. Manager of AI/ML Solutions Architecture at Amazon Web Services. He helps enterprise customers build and operate machine learning solutions on AWS. David enjoys hiking and following the latest machine learning advancement.
David Ping is a Principal Machine Learning Architect and Sr. Manager of AI/ML Solutions Architecture at Amazon Web Services. He helps enterprise customers build and operate machine learning solutions on AWS. David enjoys hiking and following the latest machine learning advancement.
 Rajdeep Saha is a specialist solutions architect for serverless and containers at Amazon Web Services (AWS). He helps customers design scalable and secure applications on AWS. Rajdeep is passionate about helping and teaching newcomers about cloud computing. He is based out of New York City and uses Twitter, sparingly at @_rajdeepsaha.
Rajdeep Saha is a specialist solutions architect for serverless and containers at Amazon Web Services (AWS). He helps customers design scalable and secure applications on AWS. Rajdeep is passionate about helping and teaching newcomers about cloud computing. He is based out of New York City and uses Twitter, sparingly at @_rajdeepsaha.