Artificial Intelligence
Create a Serverless Solution for Video Frame Analysis and Alerting
Imagine capturing frames off of live video streams, identifying objects within the frames, and then triggering actions or notifications based on the identified objects. Now imagine accomplishing all of this with low latency and without a single server to manage
In this post, I present a serverless solution that uses Amazon Rekognition and other AWS services for low-latency video frame analysis. The solution is a prototype that captures a live video, analyzes it contents, and sends an alert when it detects a certain object. I walk you through the solution’s architecture and explain how the AWS services are integrated. I then give you the tools that you need to configure, build, and run the prototype. Finally, I show you the prototype in action.
Our use case
The prototype addresses a specific use case: alerting when a human appears in a live video feed from an IP security camera. At a high level, it works like this:
- A camera surveils a particular area, streaming video over the network to a video capture client.
- The client samples video frames and sends them to AWS services, where they are analyzed and stored with metadata.
- If Amazon Rekognition detects a certain object—in this case, a human—in the analyzed video frames, an AWS Lambda function sends an Amazon Simple Message Service (Amazon SMS) alert.
- After you receive an SMS alert, you will likely want to know what caused it. For that, the prototype displays sampled video frames with low latency in a web-based user interface.
How you define low latency depends on the nature of the application. Low latency can range from microseconds to a few seconds. If you use a camera for surveillance, as in our prototype, the time between the capture of unusual activity and the triggering of an alarm can be a few seconds and still be considered a low-latency response. That’s without special performance tuning.
Solution architecture
To understand the solution’s architecture, let’s trace the journey of video frames. In the following architecture diagram, an arrow represents a step done by an element in the architecture. An arrow starts at the element initiating the step. It ends at an element used in the step.
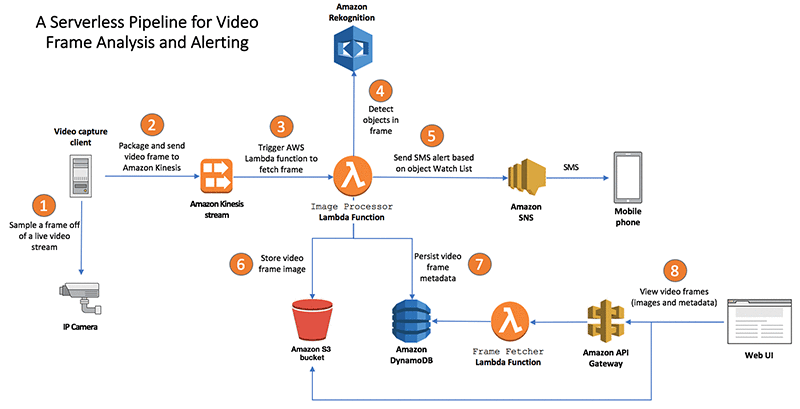
Step 1. Video capture client samples a frame off of a live video stream
It all starts with a digital camera shooting a live video stream. You can use your laptop’s camera, but it’s more practical to use a device that is capable of shooting and streaming video over a network. You can use an IP camera or, for demo purposes, your smartphone. If you use a smartphone, you can shoot and stream video using an IP camera app. Regardless of which IP camera you choose, it has to support streaming video in the MJPEG format. You can modify the source code of the video capture client to capture frames from an H.264 formatted video stream. Because of its lower bandwidth requirements, H.264 is increasingly popular with IP cameras. If you plan on sampling frames off of an H.264 video stream, use this guide as a starting point.
A camera capable of streaming MJPEG over HTTP typically exposes a local URL on the LAN to which it is connected (e.g., http://192.168.0.12:8080/video). The video capture client can connect to that MJPEG stream and receive a stream of .jpeg-encoded frames. The MJPEG video capture client is simply a Python script running on a computer that is connected to the same LAN as the IP camera. The script accepts two parameters: the MJPEG livestream URL and the frame sampling rate. The frame sampling rate is the rate at which video frames are captured and sent for subsequent processing. The default rate is one frame every 30 frames.
Step 2. Video capture client packages and streams video frames
When the video capture client samples a particular frame, it packages the JPEG-formatted bytes of that frame into an object. It also adds a number of useful attributes to the object, such as the approximate time that the frame was captured. The object is then serialized and put into an Amazon Kinesis stream—let’s call it Frame Stream—with the put_record() API. Amazon Kinesis makes it easy to collect, process, and analyze real-time streaming data.
Step 3. The Image Processor Lambda function fetches frame from Amazon Kinesis
When the video capture client puts packaged frames into Frame Stream, Amazon Kinesis triggers an AWS Lambda function called Image Processor.
Image Processor polls the Amazon Kinesis stream, fetching one or more packaged video frames. (To learn more about how Lambda and Amazon Kinesis integrate, see the documentation). Image Processor base64-decodes the package, then deserializes it, thereby creating a Python object.
Step 4. The Image Processor function detects objects in frame
Image Processor first submits the frame’s .jpeg bytes to Amazon Rekognition by calling the detect_labels() API. Amazon Rekognition makes it easy to add image analysis to your applications. With it, you can detect objects, scenes, and faces; recognize celebrities; and identify inappropriate content in images.
When the detect_labels() API call completes, it returns a list of labels for objects that Amazon Rekognition identified in the video frame. Each label has a confidence score that ranges between 0 and 1.0. The closer the confidence score of a label is to 1.0, the more certain Amazon Rekognition is that the label is accurate.
Step 5. If the Image Processor function detects any object on the Watch List, you are notified
Next, the Watch List feature kicks in. The Watch List is a configurable list of labels that you are interested in. If Amazon Rekognition recognizes an object on the Watch List, the Image Processor Lambda function sends you an SMS alert.
For instance, say that you want to be alerted if the security camera detects a human. A typical security monitoring solution with a motion detection feature alerts you when it detects any motion. Our solution alerts you only when it detects a human, so you receive only relevant alerts. You can customize the Watch List for your use case.
Let’s examine how the Watch List feature works. The Image Processor function iterates over the list of labels that Amazon Rekognition returned. If any of the labels matches one of the labels on the Watch List and has a confidence score above a minimum threshold, Image Processor uses Amazon Simple Notification Service (Amazon SNS) to send an SMS alert using the boto3 publish() API call.
You can configure the Watch List, the minimum confidence threshold, and the phone number of the SMS recipient in a JSON-formatted configuration file that is deployed with the Image Processor function. When it is invoked, the Image Processor function reads this file and parses the parameters in it.
Step 6. The Image Processor function stores the captured video frame in Amazon S3
Next, the Image Processor function stores the captured frame’s .jpeg image in Amazon S3. Amazon S3 is a service for storing and retrieving any amount of data from anywhere on the web. It also provides a simple web interface. Image Processor stores the captured frame’s image in a configurable S3 bucket.
Image Processor generates the S3 key for the frame image by concatenating the following:
- A configurable prefix (by default, frames/)
- The current year
- The current month
- The current day
- The current hour
- A Python-generated UUID
- The .jpg extension
For example, an S3 key for an image frame would look like this: “frames/2017/06/20/04/bd61af47-4a81-4148-8a6f-b98b3529848e.jpg”. For a prototype, this S3 key naming scheme is fine. However, if you intend to use this architecture at a scale that exceeds hundreds of S3 requests per second, you might need to choose a different naming scheme. For guidelines, see S3 performance best practices.
Step 7. The Image Processor function persists metadata associated with the video frame in DynamoDB
For each frame, Image Processor persists a number of metadata attributes into Amazon DynamoDB. DynamoDB is a NoSQL database service for applications that need consistent, single-digit millisecond latency at any scale. Metadata attributes include a unique identifier for the video frame, the S3 bucket and key where the frame’s image is stored, the approximate time that the frame was captured, the set of labels and confidence percentages output by Amazon Rekognition, and more. I’ll refer to this metadata and the video frame’s image as an enriched frame.
Step 8. You view the video frames and their metadata
The prototype of the solution includes a simple web-based user interface (the Web UI) for viewing the incoming stream of sampled video frames and metadata. The Web UI is a simple HTML page that uses Vue.js for rendering data items and Axios for loading data items with XMLHttpRequests.
The Web UI periodically invokes another Lambda function called Frame Fetcher. Frame Fetcher queries DynamoDB and returns the most recent list of enriched frame metadata.
What about the images associated with the enriched frames? Frame Fetcher also generates a short-lived Amazon S3 presigned URL for every frame so that the Web UI can display the images stored in Amazon S3. Frame Fetcher includes the presigned URL in its response to the Web UI.
The Web UI invokes the Frame Fetcher function through a RESTful API that is defined in and exposed by Amazon API Gateway. API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. The prototype uses Amazon API Gateway to expose a public endpoint that the Web UI can securely access using a dedicated API key.
Clone, configure, and deploy the prototype
Now run the prototype. Use the project’s README to navigate through the process. Start by following the steps in Preparing your development environment to set up your development environment. Then, get familiar with the configuration files and parameters in Configuring the project.
Most parameters are set to default values. Be sure to review the defaults. Then, set a few other parameters. For example, you need to specify the mobile phone number that the Image Processor function sends SMS alerts to. By default, this number isn’t set and the feature is inactive. For the S3 bucket names, you need to specify the names of your own buckets.
When you’re done with configuration, learn about build commands in Building the prototype. I automated the following tasks, and more, with simple build commands using pynt:
- Creating, deleting, and updating the AWS infrastructure stack with AWS CloudFormation
- Packaging Lambda code into .zip files and deploying the files to an S3 bucket
- Running the video capture client to stream from a built-in laptop webcam or a USB camera
- Running the video capture client to stream from an IP camera (creating an MJPEG stream)
- Building the web user interface (Web UI)
- Running a lightweight local HTTP server to serve the Web UI for development and demo purposes
You’ll find detailed command descriptions including sample invocations in Building the prototype. Spend some time getting familiar with the build commands.
Also, you may want to read The AWS CloudFormation Stack section. It describes the AWS resources that the prototype’s accompanying AWS CloudFormation template creates.
Finally, to get the prototype up and running in your AWS account, follow the steps in Deploy and run the prototype.
The prototype in action
Now let’s see what the prototype looks like in action. The following example screen capture shows the Web UI. The Web UI automatically loads frames captured from a camera that is monitoring an area of interest inside of a house. For testing purposes, I used my tablet to simulate a security IP camera. I used an app that is available for free.
Notice how the prototype uses Amazon Rekognition to detect what’s in the video frame and label it. Each label’s confidence score is printed in parenthesis as a percentage. The Autoload toggle, on the right under Settings, is On. This means that the Web UI will keep invoking the Frame Fetcher Lambda function every specified number of seconds. In the prototype, it’s set to 6 seconds. You can change this value in the web-ui/src/app.js source file.

When a person walks into the camera’s view, Amazon Rekognition detects it:

Understandably, there are a few seconds of lag between the time that the camera sees something and the Web UI shows it. That’s why you see an empty camera frame on the lower left.
The label for Human includes a warning that this Human is on the Watch List. As soon as Amazon Rekognition recognizes an object on the Watch List, the Image Processor Lambda function sends an SMS alert, as you see in the following screenshot:

Conclusion
In this post, I presented a serverless security monitoring and alerting solution that captures and analyzes video frames with low latency in AWS. Capturing and analyzing video frames with low latency has many potential applications. Although we designed our solution for security monitoring and alerting, I encourage you to use the prototype’s architecture and code as a starting point to address a wide variety of use cases requiring low-latency analysis of live video frames.
To learn more and download the source code, see the GitHub repository. If you have questions about this post, send them our way in the Comments section.
Additional Reading
Learn how to find distinct people in a video using Amazon Rekognition

About the Author
 Moataz Anany is an AWS Solutions Architect. He partners with our enterprise customers, helping them shorten time-to-value of their IT initiatives using AWS. In his spare time, he pursues his growing interest in shooting video.
Moataz Anany is an AWS Solutions Architect. He partners with our enterprise customers, helping them shorten time-to-value of their IT initiatives using AWS. In his spare time, he pursues his growing interest in shooting video.