Artificial Intelligence
How CCC Intelligent Solutions created a custom approach for hosting complex AI models using Amazon SageMaker
This post is co-written by Christopher Diaz, Sam Kinard, Jaime Hidalgo and Daniel Suarez from CCC Intelligent Solutions.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. CCC is a leading software-as-a-service (SaaS) platform for the multi-trillion-dollar property and casualty insurance economy powering operations for insurers, repairers, automakers, part suppliers, lenders, and more. CCC cloud technology connects more than 30,000 businesses digitizing mission-critical workflows, commerce, and customer experiences. A trusted leader in AI, Internet of Things (IoT), customer experience, and network and workflow management, CCC delivers innovations that keep people’s lives moving forward when it matters most.
The challenge
CCC processes more than $100 billion claims transactions annually. As the company continues to evolve to integrate AI into its existing and new product catalog, this requires sophisticated approaches to train and deploy multi-modal machine learning (ML) ensemble models for solving complex business needs. These are a class of models that encapsulate proprietary algorithms and subject matter domain expertise that CCC has honed over the years. These models should be able to ingest new layers of nuanced data and customer rules to create single prediction outcomes. In this blog post, we will learn how CCC leveraged Amazon SageMaker hosting and other AWS services to deploy or host multiple multi-modal models into an ensemble inference pipeline.
As shown in the following diagram, an ensemble is a collection of two or more models that are orchestrated to run in a linear or nonlinear fashion to produce a single prediction. When stacked linearly, the individual models of an ensemble can be directly invoked for predictions and later consolidated for unification. At times, ensemble models can also be implemented as a serial inference pipeline.
For our use case, the ensemble pipeline is strictly nonlinear, as depicted in the following diagram. Nonlinear ensemble pipelines are theoretically directly acyclic graphs (DAGs). For our use case, this DAG pipeline had both independent models that are run in parallel (Services B, C) and other models that use predictions from previous steps (Service D).
A practice that comes out of the research-driven culture at CCC is the continuous review of technologies that can be leveraged to bring more value to customers. As CCC faced this ensemble challenge, leadership launched a proof-of-concept (POC) initiative to thoroughly assess the offerings from AWS to discover, specifically, whether Amazon SageMaker and other AWS tools could manage the hosting of individual AI models in complex, nonlinear ensembles.
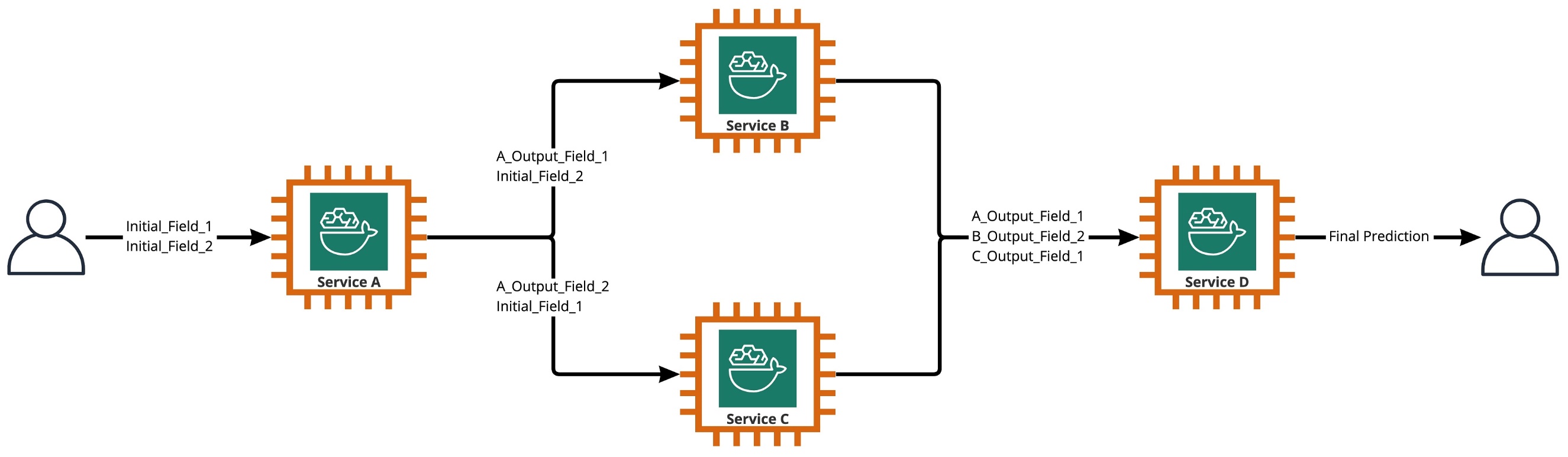
Ensemble explained: In this context, an ensemble is a group of 2 or more AI models that work together to produce 1 overall prediction.
Questions driving the research
Can Amazon SageMaker be used to host complex ensembles of AI models that work together to provide one overall prediction? If so, can SageMaker offer other benefits out of the box, such as increased automation, reliability, monitoring, automatic scaling, and cost-saving measures?
Finding alternative ways to deploy CCC’s AI models using the technological advancements from cloud providers will allow CCC to bring AI solutions to market faster than its competition. Additionally, having more than one deployment architecture provides flexibility when finding the balance between cost and performance based on business priorities.
Based on our requirements, we finalized the following list of features as a checklist for a production-grade deployment architecture:
- Support for complex ensembles
- Guaranteed uptime for all components
- Customizable automatic scaling for deployed AI models
- Preservation of AI model input and output
- Usage metrics and logs for all components
- Cost-saving mechanisms
With a majority of CCC’s AI solutions relying on computer vision models, a new architecture was required to support image and video files that continue to increase in resolution. There was a strong need to design and implement this architecture as an asynchronous model.
After cycles of research and initial benchmarking efforts, CCC determined SageMaker was a perfect fit to meet a majority of their production requirements, especially the guaranteed uptime SageMaker provides for most of its inference components. The default feature of Amazon SageMaker Asynchronous Inference endpoints saving input/output in Amazon S3 simplifies the task of preserving data generated from complex ensembles. Additionally, with each AI model being hosted by its own endpoint, managing automatic scaling policies at the model or endpoint level becomes easier. By simplifying the management, a potential cost-saving benefit from this is development teams can allocate more time towards fine-tuning scaling policies to minimize over-provisioning of compute resources.
Having decided to proceed with using SageMaker as the pivotal component of the architecture, we also realized SageMaker can be part of an even larger architecture, supplemented with many other serverless AWS-managed services. This choice was needed to facilitate the higher-order orchestration and observability needs of this complex architecture.
Firstly, to remove payload size limitations and greatly reduce timeout risk during high-traffic scenarios, CCC implemented an architecture that runs predictions asynchronously using SageMaker Asynchronous Inference endpoints coupled with other AWS-managed services as the core building blocks. Additionally, the user interface for the system follows the fire-and-forget design pattern. In other words, once a user has uploaded their input to the system, nothing more needs to be done. They will be notified when the prediction is available. The figure below illustrates a high-level overview of our asynchronous event-driven architecture. In the upcoming section, let us do a deep dive into the execution flow of the designed architecture.
Step-by-step solution
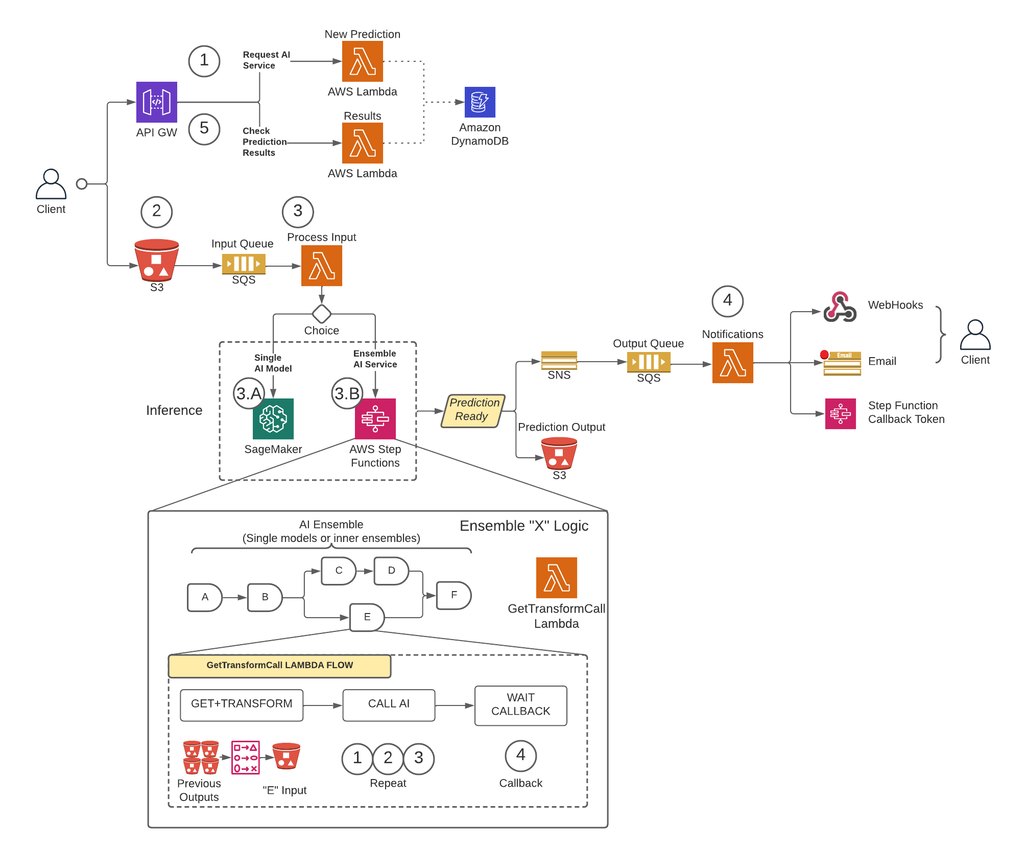
Step 1
A client makes a request to the AWS API Gateway endpoint. The content of the request contains the name of the AI service from which they need a prediction and the desired method of notification.
This request is passed to a Lambda function called New Prediction, whose main tasks are to:
- Check if the requested service by the client is available.
- Assign a unique prediction ID to the request. This prediction ID can be used by the user to check the status of the prediction throughout the entire process.
- Generate an Amazon S3 pre-signed URL that the user will need to use in the next step to upload the input content of the prediction request.
- Create an entry in Amazon DynamoDB with the information of the received request.
The Lambda function will then return a response through the API Gateway endpoint with a message that includes the prediction ID assigned to the request and the Amazon S3 pre-signed URL.
Step 2
The client securely uploads the prediction input content to an S3 bucket using the pre-signed URL generated in the previous step. Input content depends on the AI service and can be composed of images, tabular data, or a combination of both.
Step 3
The S3 bucket is configured to trigger an event when the user uploads the input content. This notification is sent to an Amazon SQS queue and handled by a Lambda function called Process Input. The Process Input Lambda will obtain the information related to that prediction ID from DynamoDB to get the name of the service to which the request is to be made.
This service can either be a single AI model, in which case the Process Input Lambda will make a request to the SageMaker endpoint that hosts that model (Step 3-A), or it can be an ensemble AI service in which case the Process Input Lambda will make a request to the state machine of the step functions that hosts the ensemble logic (Step 3-B).
In either option (single AI model or ensemble AI service), when the final prediction is ready, it will be stored in the appropriate S3 bucket, and the caller will be notified via the method specified in Step 1 (more details about notifications in Step 4).
Step 3-A
If the prediction ID is associated to a single AI model, the Process Input Lambda will make a request to the SageMaker endpoint that serves the model. In this system, two types of SageMaker endpoints are supported:
- Asynchronous: The Process Input Lambda makes the request to the SageMaker asynchronous endpoint. The immediate response includes the S3 location where SageMaker will save the prediction output. This request is asynchronous, following the fire-and-forget pattern, and does not block the execution flow of the Lambda function.
- Synchronous: The Process Input Lambda makes the request to the SageMaker synchronous endpoint. Since it is a synchronous request, Process Input waits for the response, and once obtained, it stores it in S3 in an analogous way that SageMaker asynchronous endpoints would do.
In both cases (synchronous or asynchronous endpoints), the prediction is processed in an equivalent way, storing the output in an S3 bucket. When the asynchronous SageMaker endpoint completes a prediction, an Amazon SNS event is triggered. This behavior is also replicated for synchronous endpoints with additional logic in the Lambda function.
Step 3-B
If the prediction ID is associated with an AI ensemble, the Process Input Lambda will make the request to the step function associated to that AI Ensemble. As mentioned above, an AI Ensemble is an architecture based on a group of AI models working together to generate a single overall prediction. The orchestration of an AI ensemble is done through a step function.
The step function has one step per AI service that comprises the ensemble. Each step will invoke a Lambda function that will prepare its corresponding AI service’s input using different combinations of the output content from previous AI service calls of previous steps. It then makes a call to each AI service which in this context, can wither be a single AI model or another AI ensemble.
The same Lambda function, called GetTransformCall used to handle the intermediate predictions of an AI Ensemble is used throughout the step function, but with different input parameters for each step. This input includes the name of the AI service to be called. It also includes the mapping definition to construct the input for the specified AI service. This is done using a custom syntax that the Lambda can decode, which in summary, is a JSON dictionary where the values should be replaced with the content from the previous AI predictions. The Lambda will download these previous predictions from Amazon S3.
In each step, the GetTransformCall Lambda reads from Amazon S3 the previous outputs that are needed to build the input of the specified AI service. It will then invoke the New Prediction Lambda code previously used in Step 1 and provide the service name, callback method (“step function”), and token needed for the callback in the request payload, which is then saved in DynamoDB as a new prediction record. The Lambda also stores the created input of that stage in an S3 bucket. Depending on whether that stage is a single AI model or an AI ensemble, the Lambda makes a request to a SageMaker endpoint or a different step function that manages an AI ensemble that is a dependency of the parent ensemble.
Once the request is made, the step function enters a pending state until it receives the callback token indicating it can move to the next stage. The action of sending a callback token is performed by a Lambda function called notifications (more details in Step 4) when the intermediate prediction is ready. This process is repeated for each stage defined in the step function until the final prediction is ready.
Step 4
When a prediction is ready and stored in the S3 bucket, an SNS notification is triggered. This event can be triggered in different ways depending on the flow:
- Automatically when a SageMaker asynchronous endpoint completes a prediction.
- As the very last step of the step function.
- By Process Input or GetTransformCall Lambda when a synchronous SageMaker endpoint has returned a prediction.
For B and C, we create an SNS message similar to what A automatically sends.
A Lambda function called notifications is subscribed to this SNS topic. The notifications Lambda will get the information related to the prediction ID from DynamoDB, update the entry with status value to “completed” or “error,” and perform the necessary action depending on the callback mode saved in the database record.
If this prediction is an intermediate prediction of an AI ensemble, as described in step 3-B, the callback mode associated to this prediction will be “step function,” and the database record will have a callback token associated with the specific step in the step function. The notifications Lambda will make a call to the AWS Step Functions API using the method “SendTaskSuccess” or “SendTaskFailure.” This will allow the step function to continue to the next step or exit.
If the prediction is the final output of the step function and the callback mode is “Webhook” [or email, message brokers (Kafka), etc.], then the notifications Lambda will notify the client in the specified way. At any point, the user can request the status of their prediction. The request must include the prediction ID that was assigned in Step 1 and point to the correct URL within API Gateway to route the request to the Lambda function called results.
The results Lambda will make a request to DynamoDB, obtaining the status of the request and returning the information to the user. If the status of the prediction is error, then the relevant details on the failure will be included in the response. If the prediction status is success, an S3 pre-signed URL will be returned for the user to download the prediction content.
Outcomes
Preliminary performance testing results are promising and support the case for CCC to extend the implementation of this new deployment architecture.
Notable observations:
- Tests reveal strength in processing batch or concurrent requests with high throughput and a 0 percent failure rate during high traffic scenarios.
- Message queues provide stability within the system during sudden influxes of requests until scaling triggers can provision additional compute resources. When increasing traffic by 3x, average request latency only increased by 5 percent.
- The price of stability is increased latency due to the communication overhead between the various system components. When user traffic is above the baseline threshold, the added latency can be partially mitigated by providing more compute resources if performance is a higher priority over cost.
- SageMaker’s asynchronous inference endpoints allow the instance count to be scaled to zero while keeping the endpoint active to receive requests. This functionality enables deployments to continue running without incurring compute costs and scale up from zero when needed in two scenarios: service deployments used in lower test environments and those that have minimal traffic without requiring immediate processing.
Conclusion
As observed during the POC process, the innovative design jointly created by CCC and AWS provides a solid foundation for using Amazon SageMaker with other AWS managed services to host complex multi-modal AI ensembles and orchestrate inference pipelines effectively and seamlessly. By leveraging Amazon SageMaker’s out-of-the-box functionalities like Asynchronous Inference, CCC has more opportunities to focus on specialized business-critical tasks. In the spirit of CCC’s research-driven culture, this novel architecture will continue to evolve as CCC leads the way forward, alongside AWS, in unleashing powerful new AI solutions for clients.
For detailed steps on how to create, invoke, and monitor asynchronous inference endpoints, refer to the documentation, which also contains a sample notebook to help you get started. For pricing information, visit Amazon SageMaker Pricing.
For examples on using asynchronous inference with unstructured data such as computer vision and natural language processing (NLP), refer to Run computer vision inference on large videos with Amazon SageMaker asynchronous endpoints and Improve high-value research with Hugging Face and Amazon SageMaker asynchronous inference endpoints, respectively.
About the Authors
 Christopher Diaz is a Lead R&D Engineer at CCC Intelligent Solutions. As a member of the R&D team, he has worked on a variety of projects ranging from ETL tooling, backend web development, collaborating with researchers to train AI models on distributed systems, and facilitating the delivery of new AI services between research and operations teams. His recent focus has been on researching cloud tooling solutions to enhance various aspects of the company’s AI model development lifecycle. In his spare time, he enjoys trying new restaurants in his hometown of Chicago and collecting as many LEGO sets as his home can fit. Christopher earned his Bachelor of Science in Computer Science from Northeastern Illinois University.
Christopher Diaz is a Lead R&D Engineer at CCC Intelligent Solutions. As a member of the R&D team, he has worked on a variety of projects ranging from ETL tooling, backend web development, collaborating with researchers to train AI models on distributed systems, and facilitating the delivery of new AI services between research and operations teams. His recent focus has been on researching cloud tooling solutions to enhance various aspects of the company’s AI model development lifecycle. In his spare time, he enjoys trying new restaurants in his hometown of Chicago and collecting as many LEGO sets as his home can fit. Christopher earned his Bachelor of Science in Computer Science from Northeastern Illinois University.
 Emmy Award winner Sam Kinard is a Senior Manager of Software Engineering at CCC Intelligent Solutions. Based in Austin, Texas, he wrangles the AI Runtime Team, which is responsible for serving CCC’s AI products at high availability and large scale. In his spare time, Sam enjoys being sleep deprived because of his two wonderful children. Sam has a Bachelor of Science in Computer Science and a Bachelor of Science in Mathematics from the University of Texas at Austin.
Emmy Award winner Sam Kinard is a Senior Manager of Software Engineering at CCC Intelligent Solutions. Based in Austin, Texas, he wrangles the AI Runtime Team, which is responsible for serving CCC’s AI products at high availability and large scale. In his spare time, Sam enjoys being sleep deprived because of his two wonderful children. Sam has a Bachelor of Science in Computer Science and a Bachelor of Science in Mathematics from the University of Texas at Austin.
 Jaime Hidalgo is a Senior Systems Engineer at CCC Intelligent Solutions. Before joining the AI research team, he led the company’s global migration to Microservices Architecture, designing, building, and automating the infrastructure in AWS to support the deployment of cloud products and services. Currently, he builds and supports an on-premises data center cluster built for AI training and also designs and builds cloud solutions for the company’s future of AI research and deployment.
Jaime Hidalgo is a Senior Systems Engineer at CCC Intelligent Solutions. Before joining the AI research team, he led the company’s global migration to Microservices Architecture, designing, building, and automating the infrastructure in AWS to support the deployment of cloud products and services. Currently, he builds and supports an on-premises data center cluster built for AI training and also designs and builds cloud solutions for the company’s future of AI research and deployment.
 Daniel Suarez is a Data Science Engineer at CCC Intelligent Solutions. As a member of the AI Engineering team, he works on the automation and preparation of AI Models in the production, evaluation, and monitoring of metrics and other aspects of ML operations. Daniel received a Master’s in Computer Science from the Illinois Institute of Technology and a Master’s and Bachelor’s in Telecommunication Engineering from Universidad Politecnica de Madrid.
Daniel Suarez is a Data Science Engineer at CCC Intelligent Solutions. As a member of the AI Engineering team, he works on the automation and preparation of AI Models in the production, evaluation, and monitoring of metrics and other aspects of ML operations. Daniel received a Master’s in Computer Science from the Illinois Institute of Technology and a Master’s and Bachelor’s in Telecommunication Engineering from Universidad Politecnica de Madrid.
 Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
 Justin McWhirter is a Solutions Architect Manager at AWS. He works with a team of amazing Solutions Architects who help customers have a positive experience while adopting the AWS platform. When not at work, Justin enjoys playing video games with his two boys, ice hockey, and off-roading in his Jeep.
Justin McWhirter is a Solutions Architect Manager at AWS. He works with a team of amazing Solutions Architects who help customers have a positive experience while adopting the AWS platform. When not at work, Justin enjoys playing video games with his two boys, ice hockey, and off-roading in his Jeep.