Artificial Intelligence
Run computer vision inference on large videos with Amazon SageMaker asynchronous endpoints
This blog post was last reviewed and updated August, 2022 with a generator-based approach for video payloads of longer duration.
AWS customers are increasingly using computer vision (CV) models on large input payloads that can take a few minutes of processing time. For example, space technology companies work with a stream of high-resolution satellite imagery to detect particular objects of interest. Similarly, healthcare companies process high-resolution biomedical images or videos like echocardiograms to detect anomalies. Additionally, media companies scan images and videos uploaded by their customers to ensure they are compliant and without copyright violations. These applications receive bursts of incoming traffic at different times in the day and require near-real-time processing with completion notifications at a low cost.
You can build CV models with multiple deep learning frameworks like TensorFlow, PyTorch, and Apache MXNet. These models typically have large payloads, such as images or videos. Advanced deep learning models for use cases like object detection return large response payloads ranging from tens of MBs to hundreds of MBs in size. Additionally, high-resolution videos require compute-intensive preprocessing before model inference. Processing times can range in the order of minutes, eliminating the option to run real-time inference by passing payloads over a HTTP API. Instead, there is a need to process input payloads asynchronously from an object store like Amazon Simple Storage Service (Amazon S3) with automatic queuing and a predefined concurrency threshold. The system should be able to receive status notifications and eliminate unnecessary costs by cleaning up resources when the tasks are complete.
Amazon SageMaker helps data scientists and developers prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML. SageMaker provides state-of-the-art open-source model serving containers for XGBoost (container, SDK), Scikit-Learn (container, SDK), PyTorch (container, SDK), TensorFlow (container, SDK) and Apache MXNet (container, SDK). SageMaker provides three options to deploy trained ML models for generating inferences on new data:
- Real-time inference endpoints are suitable for workloads that need to be processed with low latency requirements.
- Serverless inference is ideal for workloads with intermittent or unpredictable traffic, where occasional cold starts can be tolerated. It’s intended for workloads where you have up-to megabytes of payload that need to provide inference quickly.
- Batch transform is ideal for offline predictions on large batches of data that are collected over a period of time.
- Asynchronous inference endpoints queue incoming requests and are ideal for workloads where the request sizes are large (up to 1 GB) and inference processing times are in the order of minutes (up to 15 minutes). Asynchronous inference enables you to save on costs by auto scaling the instance count to 0 when there are no requests to process.
In this post, we show you how to serve a PyTorch CV model with SageMaker asynchronous inference to process a burst traffic of large input payload videos uploaded to Amazon S3. We demonstrate the new capabilities of an internal queue with user-defined concurrency and completion notifications. We configure auto scaling of instances to scale down to 0 when traffic subsides and scale back up as the request queue fills up. We use a g4dn instance with a Nvidia T4 GPU and the SageMaker pre-built TorchServe container with a custom inference script for preprocessing the videos before model invocation, and Amazon CloudWatch metrics to monitor the queue size, total processing time, invocations processed, and more.
The code for this example is available on GitHub.
Solution overview
The following diagram illustrates our solution architecture.
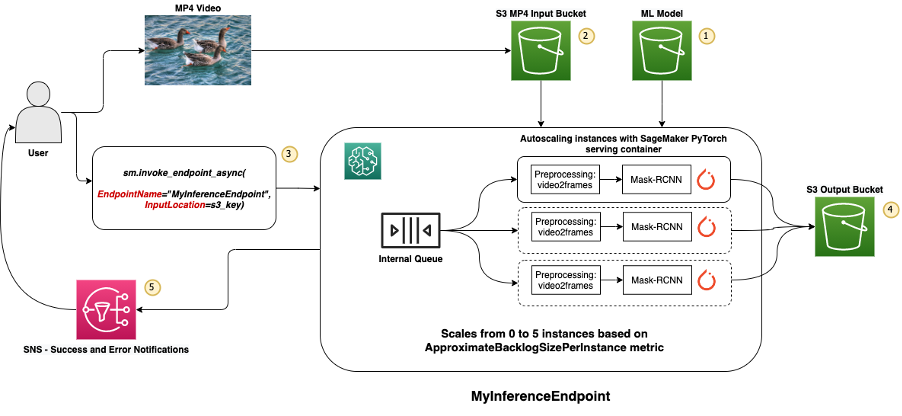
Our model is first hosted on the scaling endpoint. Next, the user or some other mechanism uploads a video file to an input S3 bucket. The user invokes the endpoint and is immediately returned an output Amazon S3 location where the inference is written. After the inference is complete, the result is saved to the output S3 bucket, and an Amazon Simple Notification Service (Amazon SNS) notification is sent to the user notifying them of the completed success or failure.
Use case model
For this object detection example, we use a TorchVision Mask-RCNN model, pre-trained on 91 classes, to demonstrate inference on a large video payload. Because our video can be up to 1 GB in size and contain thousands of frames, we suggest a generator-based approach that lazily decodes, preprocesses and invokes model one batch in a time (with a max batch size being sufficiently small to fit into GPU memory). By doing so, we can crunch through video payloads of any duration one batch after another without causing out-of-memory (OOM) errors. At the end, we merge model responses for all batches together before saving them to the S3 bucket. Naturally, when dealing with such large payloads, the total latency can be substantial. Although this isn’t ideal for a real-time endpoint, it’s easily handled by asynchronous endpoints, which process the queue and save the results to an Amazon S3 output location.
To host this model, we use a pre-built SageMaker PyTorch inference container that utilizes the TorchServe model serving stack. SageMaker containers allow you to provide your own inference script, which gives you flexibility to handle preprocessing and postprocessing, as well as dictate how your model interacts with the data.
Input and output payload
In this example, we use an input video of size 71 MB from here. Since asynchronous endpoint receives an mp4 video file as the inference request payload, we first need to do some preprocessing before invoking the model. Concretely, we decode the video, grab one in every 30 frames (i.e. 1 FPS), downsample the grabbed frames to resolution of 1024×1024 pixels, rescale the RGB values to [0, 1] range and batch the preprocessed frames into a 4D tensor, which can readily be consumed by the model. Similarly, we also perform some minor postprocessing on the model’s outputs, before returning the final inference response. In order to implement this custom inference handling logic, we provide the endpoint with a inference.py script, which defines our custom handler functions. For example, our script provides model_fn function that specifies how to load the PyTorch model, as well as transform_fn function that takes care of the entire end-to-end inference logic (i.e. preprocessing, model invocation, and postprocessing) described above. Note that you can set your custom FPS rate, preprocessing resolution, and suitable batch size via the corresponding environment variables.
In order to enable inference on videos of arbitrary lengths (or grab frames with higher FPS rates) and not cause out-of-memory (OOM) errors, we lazily decode and preprocess a batch of frames (with batch size that is sufficiently small to fit into GPU memory) so that the model can consume one batch at a time until it has crunched through the entire video (see batch_generator implementation in inference.py for details). At the end, we merge model responses for all batches together before saving them to the S3 bucket.
Below is our implementation of transform_fn function:
This function returns a JSON containing the bounding boxes, labels, and scores for detected objects. In this example, the output payload is 54 KB. We demonstrate a quick visualization of the results in the following animation.

Create the asynchronous endpoint
We create the asynchronous endpoint similarly to a real-time hosted endpoint. The steps include creation of a SageMaker model, followed by endpoint configuration and deployment of the endpoint. The difference between the two types of endpoints is that the asynchronous endpoint configuration contains an AsyncInferenceConfig section. In this section, we specify the Amazon S3 output path for the results from the endpoint invocation and optionally include SNS topics for notifications on success and failure. We also specify the maximum number of concurrent invocations per instance as determined by the customer. See the following code:
For details on the API to create an endpoint configuration for asynchronous inference, Create an Asynchronous Inference Endpoint.
Invoke the asynchronous endpoint
The input payload in the following code is a video .mp4 file uploaded to Amazon S3:
We use the Amazon S3 URI to the input payload file to invoke the endpoint. The response object contains the output location in Amazon S3 to retrieve the results after completion:
For details on the API to invoke an asynchronous endpoint, see Invoke an Asynchronous Endpoint.
Queue the invocation requests with user-defined concurrency
The asynchronous endpoint automatically queues the invocation requests. It uses the MaxConcurrentInvocationsPerInstance parameter in the preceding endpoint configuration to process new requests from the queue after previous requests are complete. This is a fully managed queue with various monitoring metrics and doesn’t require any further configuration.
Auto scaling instances within the asynchronous endpoint
We set the auto scaling policy with a minimum capacity of 0 and a maximum capacity of five instances. Unlike real-time hosted endpoints, asynchronous endpoints support scaling the instances count to 0, by setting the minimum capacity to 0. With this feature, we can scale down to 0 instances when there is no traffic and pay only when the payloads arrive.
We use the ApproximateBacklogSizePerInstance metric for the scaling policy configuration with a target queue backlog of five per instance to scale out further. We set the cooldown period for ScaleInCooldown to 120 seconds and the ScaleOutCooldown to 120 seconds. See the following code:
For details on the API to automatically scale an asynchronous endpoint, see Autoscale an Asynchronous Endpoint.
Notifications from the asynchronous endpoint
We create two separate SNS topics for success and error notifications for each endpoint invocation result:
The other options for notifications include periodically checking the output of the S3 bucket, or using S3 bucket notifications to trigger an AWS Lambda function on file upload. SNS notifications are included in the endpoint configuration section as described earlier.
For details on how to set up notifications from an asynchronous endpoint, see Check Prediction Results.
Monitor the asynchronous endpoint
We monitor the asynchronous endpoint with built-in additional CloudWatch metrics specific to asynchronous inference. For example, we monitor the queue length in each instance with ApproximateBacklogSizePerInstance and total queue length with ApproximateBacklogSize. Consider deleting the SNS topic to avoid the flooding notifications during the following invocations. In the following chart, we can see the initial backlog size due to sudden traffic burst of 1,000 requests, and the backlog size per instance reduces rapidly as the endpoint scales out from one to five instances.

Similarly, we monitor the total number of successful invocations with InvocationsProcessed and the total number of failed invocations with InvocationFailures. In the following chart, we can see the average number of video invocations processed per minute after auto scaling at approximately 18.

We also monitor the model latency time, which includes the video preprocessing time and model inference for the batch of video images at 1 FPS. In the following chart, we can see the model latency for two concurrent invocations is about 30 seconds.

We also monitor the total processing time from input in Amazon S3 to output back in Amazon S3 with TotalProcessingTime and the time spent in backlog with the TimeInBacklog metric. In the following chart, we can see that the average time in backlog and total processing time increases over time. The requests that are added during the burst of traffic in the front of the queue have a time in backlog that is similar to the model latency of 30 seconds. The requests in the end of the queue have the highest time in backlog at about 3,500 seconds.
We also monitor how the endpoint scales back down to 0 after processing the complete queue. The endpoint runtime settings display the current instance count size at 0.

The following table summarizes the video inference example with a burst traffic of 1,000 video invocations.
| Attribute | Value |
| Number of invocations (total burst size) | 1000 |
| Concurrency level | 2 |
| Instance type | ml.g4dn.xlarge |
| Input payload (per invocation) size | 71 MB |
| Video frame sampling rate (FPS) | 1 FPS |
| Output payload (per invocation) size | 54 KB |
| Model latency | 30 seconds |
| Maximum auto scaling instances | 5 |
| Throughput (requests per minute) | 18 |
| Model Size | 165 MB |
We can optimize the endpoint configuration to get the most cost-effective instance with high performance. In this example, we use a g4dn.xlarge instance with a Nvidia T4 GPU. We can gradually increase the concurrency level up to the throughput peak while adjusting other model server and container parameters.
For a complete list of metrics, see Monitoring Asynchronous Endpoints.
Clean up
After we complete all the requests, we can delete the endpoint similarly to deleting real-time hosted endpoints. Note that if we set the minimum capacity of asynchronous endpoints to 0, there are no instance charges incurred after it scales down to 0.
If you enabled auto scaling for your endpoint, make sure you deregister the endpoint as a scalable target before deleting the endpoint. To do this, run the following:
Endpoints should be deleted when no longer in use, because (per the SageMaker pricing page) they’re billed by time deployed. To do this, run the following:
Conclusion
In this post, we demonstrated how to use the new asynchronous inference capability from SageMaker to process a large input payload of videos. For inference, we used a custom inference script that allowed us to preprocess videos of arbitrary durations at a custom frame sampling rate and iteratively trigger a well-known PyTorch CV model one batch at a time to generate a list of outputs for each video. We addressed the challenges of burst traffic, high model processing times and large payloads with managed queues, predefined concurrency limits, response notifications, and scale down to zero capabilities.
To get started with SageMaker asynchronous inference, see Asynchronous Inference and refer the sample code for your own use cases.
About the Authors
 Hasan Poonawala is a Machine Learning Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family.
Hasan Poonawala is a Machine Learning Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family.
 Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Add-ons.
Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Add-ons.
 Alexander Arzhanov is an AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers to design and deploy their ML solutions across EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.
Alexander Arzhanov is an AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers to design and deploy their ML solutions across EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.