Artificial Intelligence
How Medidata used Amazon SageMaker asynchronous inference to accelerate ML inference predictions up to 30 times faster
This post is co-written with Rajnish Jain, Priyanka Kulkarni and Daniel Johnson from Medidata.
Medidata is leading the digital transformation of life sciences, creating hope for millions of patients. Medidata helps generate the evidence and insights to help pharmaceutical, biotech, medical devices, and diagnostics companies as well as academic researchers with accelerating value, minimizing risk, and optimizing outcomes for their solutions. More than one million registered users across over 1,900 customers and partners access the world’s most trusted platform for clinical development, commercial, and real-world data.
Medidata’s AI team combines unparalleled clinical data, advanced analytics, and industry expertise to help life sciences leaders reimagine what is possible, uncover breakthrough insights to make confident decisions, and pursue continuous innovation. Medidata’s AI suite of solutions is backed by an integrated team of scientists, physicians, technologists, and ex-regulatory officials—built upon Medidata’s core platform comprising over 27,000 trials and 8 million patients.
Amazon SageMaker is a fully managed machine learning (ML) platform within the secure AWS landscape. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. For hosting trained ML models, SageMaker offers a wide array of options. Depending on the type of traffic pattern and latency requirements, you could choose one of these several options. For example, real-time inference is suitable for persistent workloads with millisecond latency requirements, payload sizes up to 6 MB, and processing times of up to 60 seconds. With Serverless Inference, you can quickly deploy ML models for inference without having to configure or manage the underlying infrastructure, and you pay only for the compute capacity used to process inference requests, which is ideal for intermittent workloads. For requests with large unstructured data with payload sizes up to 1 GB, with processing times up to 15 mins, and near real-time latency requirements, you can use asynchronous inference. Batch transform is ideal for offline predictions on large batches of data that are available up front.
In this collaborative post, we demonstrate how AWS helped Medidata take advantage of the various hosting capabilities within SageMaker to experiment with different architecture choices for predicting the operational success of proposed clinical trials. We also validate why Medidata chose SageMaker asynchronous inference for its final design and how this final architecture helped Medidata serve its customers with predictions up to 30 times faster while keeping ML infrastructure costs relatively low.
Architecture evolution
System design is not about choosing one right architecture. It’s the ability to discuss and experiment multiple possible approaches and weigh their trade-offs in satisfying the given requirements for our use case. During this process, it’s essential to take into account prior knowledge of various types of requirements and existing common systems that can interact with our proposed design. The scalability of a system is its ability to easily and cost-effectively vary resources allocated to it so as to serve changes in load. This applies to both increasing or decreasing user numbers or requests to the system.
In the following sections, we discuss how Medidata worked with AWS in iterating over a list of possible scalable architecture designs. We especially focus on the evolution journey, design choices, and trade-offs we went through to arrive at a final choice.
SageMaker batch transform
Medidata originally used SageMaker batch transform for ML inference to meet current requirements and develop a minimum viable product (MVP) for a new predictive solution due to low usage and loose performance requirements of the application. When a batch transform job starts, SageMaker initializes compute instances and distributes the inference or preprocessing workload between them. It’s a high-performance and high-throughput method for transforming data and generating inferences. It’s ideal for scenarios where you’re dealing with large batches of data, don’t need subsecond latency, and need to either preprocess or transform the data or use a trained model to run batch predictions on it in a distributed manner. The Sagemaker batch transform workflow also uses Amazon Simple Storage Service (Amazon S3) as the persistent layer, which maps to one of our data requirements.
Initially, using SageMaker batch transform worked well for the MVP, but as the requirements evolved and Medidata needed to support its customers in near real time, batch transform wasn’t suitable because it was an offline method and customers need to wait anywhere between 5–15 minutes for responses. This primarily included the startup cost for the underlying compute cluster to spin up every time a batch workload needs to be processed. This architecture also required configuring Amazon CloudWatch event rules to track the progress of the batch predictions job together with employing a database of choice to track the states and metadata of the fired job. The MVP architecture is shown in the following diagram.

The flow of this architecture is as follows:
- The incoming bulk payload is persisted as an input to an S3 location. This event in turn triggers an AWS Lambda Submit function.
- The Submit function kicks off a SageMaker batch transform job using the SageMaker runtime client.
- The Submit function also updates a state and metadata tracker database of choice with the job ID and sets the status of the job to
inProgress. The function also updates the job ID with its corresponding metadata information. - The transient (on-demand) compute cluster required to process the payload spins up, initiating a SageMaker batch transform job. At the same time, the job also emits status notifications and other logging information to CloudWatch logs.
- The CloudWatch event rule captures the status of the batch transform job and sends a status notification to an Amazon Simple Notification Service (Amazon SNS) topic configured to capture this information.
- The SNS topic is subscribed by a Notification Lambda function that is triggered every time an event rule is fired by CloudWatch and when there is a message in the SNS topic.
- The Notification function then updates the status of the transform job for success or failure in the tracking database.
While exploring alternative strategies and architectures, Medidata realized that the traffic pattern for the application consisted of short bursts followed by periods of inactivity. To validate the drawbacks of this existing MVP architecture, Medidata performed some initial benchmarking to understand and prioritize the bottlenecks of this pipeline. As shown in the following diagram, the largest bottleneck was the transition time before running the model for inference due to spinning up new resources with each bulk request. The definition of a bulk request here corresponds to a payload that is a collection of operational site data to be processed rather than a single instance of a request. The second biggest bottleneck was the time to save and write the output, which was also introduced due to the batch model architecture.

As the number of clients increased and usage multiplied, Medidata prioritized user experience by tightening performance requirements. Therefore, Medidata decided to replace the batch transform workflow with a faster alternative. This led to Medidata experimenting with several architecture designs involving SageMaker real-time inference, Lambda, and SageMaker asynchronous inference. In the following sections, we compare these evaluated designs in depth and analyze the technical reasons for choosing one over the other for Medidata’s use case.
SageMaker real-time inference
You can use SageMaker real-time endpoints to serve your models for predictions in real time with low latency. Serving your predictions in real time requires a model serving stack that not only has your trained model, but also a hosting stack to be able to serve those predictions. The hosting stack typically include a type of proxy, a web server that can interact with your loaded serving code, and your trained model. Your model can then be consumed by client applications through a real-time invoke API request. The request payload sent when you invoke the endpoint is routed to a load balancer and then routed to your ML instance or instances that are hosting your models for prediction. SageMaker real-time inference comes with all of the aforementioned components and makes it relatively straightforward to host any type of ML model for synchronous real-time inference.
SageMaker real-time inference has a 60-second timeout for endpoint invocation, and the maximum payload size for invocation is capped out at 6 MB. Because Medidata’s inference logic is complex and frequently requires more than 60 seconds, real-time inference alone can’t be a viable option for dealing with bulk requests that normally require unrolling and processing many individual operational identifiers without re-architecting the existing ML pipeline. Additionally, real-time inference endpoints need to be sized to handle peak load. This could be challenging because Medidata has quick bursts of high traffic. Auto scaling could potentially fix this issue, but it would require manual tuning to ensure there are enough resources to handle all requests at any given time. Alternatively, we could manage a request queue to limit the number of concurrent requests at a given time, but this would introduce additional overhead.
Lambda
Serverless offerings like Lambda eliminate the hassle of provisioning and managing servers, and automatically take care of scaling in response to varying workloads. They can be also much cheaper for lower-volume services because they don’t run 24/7. Lambda works well for workloads that can tolerate cold starts after periods of inactivity. If a serverless function has not been run for approximately 15 minutes, the next request experiences what is known as a cold start because the function’s container must be provisioned.
Medidata built several proof of concept (POC) architecture designs to compare Lambda with other alternatives. As a first simple implementation, the ML inference code was packaged as a Docker image and deployed as a container using Lambda. To facilitate faster predictions with this setup, the invoked Lambda function requires a large provisioned memory footprint. For larger payloads, there is an extra overhead to compress the input before calling the Lambda Docker endpoint. Additional configurations are also needed for the CloudWatch event rules to save the inputs and outputs, tracking the progress of the request, and employing a database of choice to track the internal states and metadata of the fired requests. Additionally, there is also an operational overhead for reading and writing data to Amazon S3. Medidata calculated the projected cost of the Lambda approach based on usage estimates and determined it would be much more expensive than SageMaker with no added benefits.
SageMaker asynchronous inference
Asynchronous inference is one of the newest inference offerings in SageMaker that uses an internal queue for incoming requests and processes them asynchronously. This option is ideal for inferences with large payload sizes (up to 1 GB) or long-processing times (up to 15 minutes) that need to be processed as requests arrive. Asynchronous inference enables you to save on costs by autoscaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests.
For use cases that can tolerate a cold start penalty of a few minutes, you can optionally scale down the endpoint instance count to zero when there are no outstanding requests and scale back up as new requests arrive so that you only pay for the duration that the endpoints are actively processing requests.
Creating an asynchronous inference endpoint is very similar to creating a real-time endpoint. You can use your existing SageMaker models and only need to specify additional asynchronous inference configuration parameters while creating your endpoint configuration. Additionally, you can attach an auto scaling policy to the endpoint according to your scaling requirements. To invoke the endpoint, you need to place the request payload in Amazon S3 and provide a pointer to the payload as a part of the invocation request. Upon invocation, SageMaker enqueues the request for processing and returns an output location as a response. Upon processing, SageMaker places the inference response in the previously returned Amazon S3 location. You can optionally choose to receive success or error notifications via Amazon SNS.
Based on the different architecture designs discussed previously, we identified several bottlenecks and complexity challenges with these architectures. With the launch of asynchronous inference and based on our extensive experimentation and performance benchmarking, Medidata decided to choose SageMaker asynchronous inference for their final architecture for hosting due to a number of reasons outlined earlier. SageMaker is designed from the ground up to support ML workloads, whereas Lambda is more of a general-purpose tool. For our specific use case and workload type, SageMaker asynchronous inference is cheaper than Lambda. Also, SageMaker asynchronous inference’s timeout is much longer (15 minutes) compared to the real-time inference timeout of 60 seconds. This ensures that asynchronous inference can support all of Medidata’s workloads without modification. Additionally, SageMaker asynchronous inference queues up requests during quick bursts of traffic rather than dropping them, which was a strong requirement as per our use case. Exception and error handling is automatically taken care of for you. Asynchronous inference also makes it easy to handle large payload sizes, which is a common pattern with our inference requirements. The final architecture diagram using SageMaker asynchronous inference is shown in the following figure.
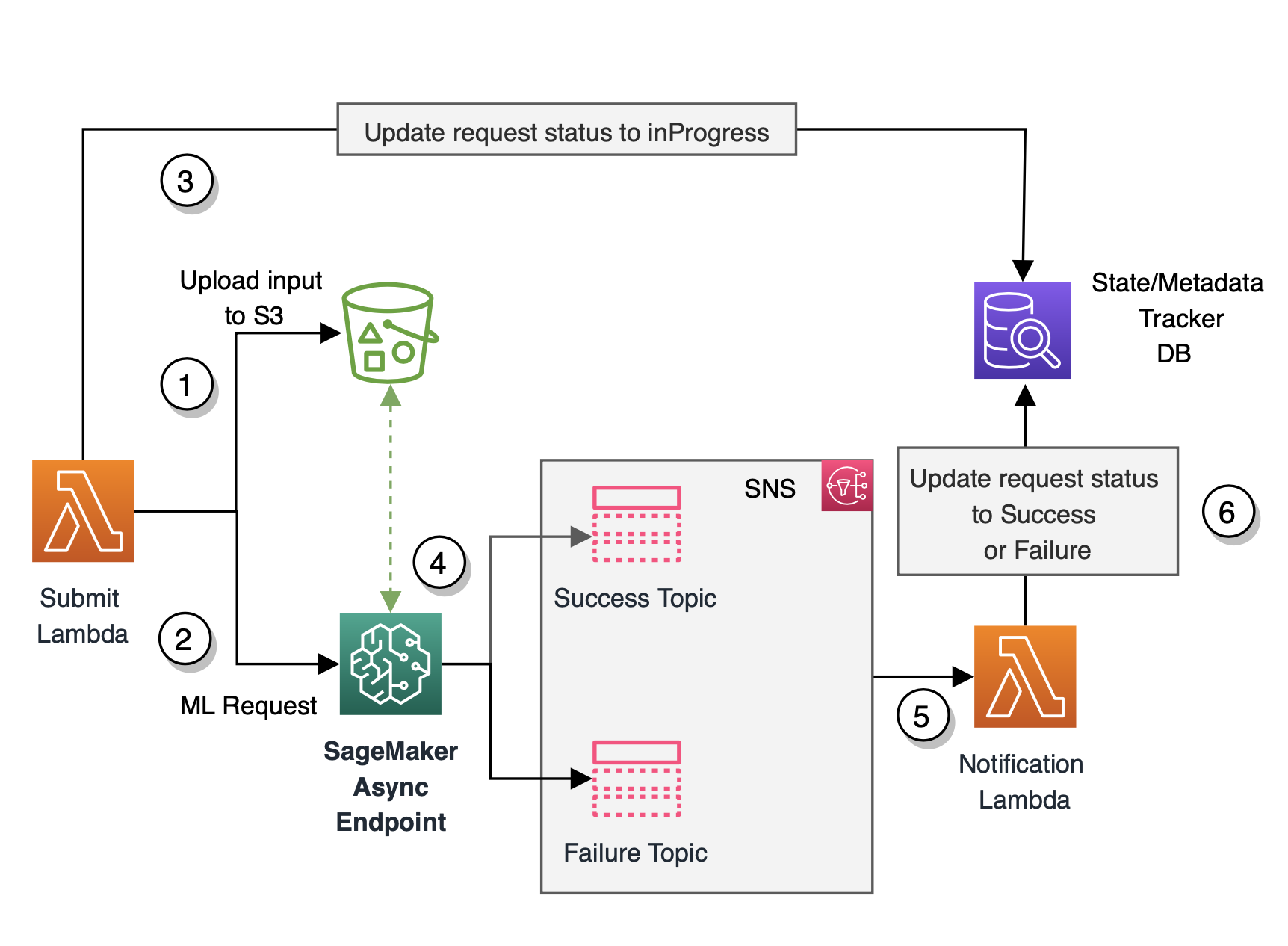
The flow of our final architecture is as follows:
- The Submit function receives the bulk payload from upstream consumer applications and is set up to be event-driven. This function uploads the payload to the pre-designated Amazon S3 location.
- The Submit function then invokes the SageMaker asynchronous endpoint, providing it with the Amazon S3 pointer to the uploaded payload.
- The function also updates the state of the request to
inProgressin the state and metadata tracker database. - The SageMaker asynchronous inference endpoint reads the input from Amazon S3 and runs the inference logic. When the ML inference succeeds or fails, the inference output is written back to Amazon S3 and the status is sent to an SNS topic.
- A Notification Lambda function subscribes to the SNS topic. The function is invoked whenever a status update notification is published to the topic.
- The Notification function updates the status of the request to success or failure in the state and metadata tracker database.
To recap, the batch transform MVP architecture we started with took 5–15 minutes to run depending on the size of the input. With the switch to asynchronous inference, the new solution runs end to end in 10–60 seconds. We see a speedup of at least five times faster for larger inputs and up to 30 times faster for smaller inputs, leading to better customer satisfaction with the performance results. The revised final architecture greatly simplifies the previous asynchronous fan-out/fan-in architecture because we don’t have to worry about partitioning the incoming payload, spawning workers, and delegating and consolidating work amongst the worker Lambda functions.
Conclusion
With SageMaker asynchronous inference, Medidata’s customers using this new predictive application now experience a speedup that’s up to 30 times faster for predictions. Requests aren’t dropped during traffic spikes because the asynchronous inference endpoint queues up requests rather than dropping them. The built-in SNS notification was able to overcome the custom CloudWatch event log notification that Medidata had built to notify the app when the job was complete. In this case, the asynchronous inference approach is cheaper than Lambda. SageMaker asynchronous inference is an excellent option if your team is running heavy ML workloads with burst traffic while trying to minimize cost. This is a great example of collaboration with the AWS team to push the boundaries and use bleeding edge technology for maximum efficiency.
For detailed steps on how to create, invoke, and monitor asynchronous inference endpoints, refer to documentation, which also contains a sample notebook to help you get started. For pricing information, visit Amazon SageMaker Pricing. For examples on using asynchronous inference with unstructured data such as computer vision and natural language processing (NLP), refer to Run computer vision inference on large videos with Amazon SageMaker asynchronous endpoints and Improve high-value research with Hugging Face and Amazon SageMaker asynchronous inference endpoints, respectively.
About the authors
 Rajnish Jain is a Senior Director of Engineering at Medidata AI based in NYC. Rajnish heads engineering for a suite of applications that use machine learning on AWS to help customers improve operational success of proposed clinical trials. He is passionate about the use of machine learning to solve business problems.
Rajnish Jain is a Senior Director of Engineering at Medidata AI based in NYC. Rajnish heads engineering for a suite of applications that use machine learning on AWS to help customers improve operational success of proposed clinical trials. He is passionate about the use of machine learning to solve business problems.
 Priyanka Kulkarni is a Lead Software Engineer within Acorn AI at Medidata Solutions. She architects and develops solutions and infrastructure to support ML predictions at scale. She is a data-driven engineer who believes in building innovative software solutions for customer success.
Priyanka Kulkarni is a Lead Software Engineer within Acorn AI at Medidata Solutions. She architects and develops solutions and infrastructure to support ML predictions at scale. She is a data-driven engineer who believes in building innovative software solutions for customer success.
 Daniel Johnson is a Senior Software Engineer within Acorn AI at Medidata Solutions. He builds APIs to support ML predictions around the feasibility of proposed clinical trials.
Daniel Johnson is a Senior Software Engineer within Acorn AI at Medidata Solutions. He builds APIs to support ML predictions around the feasibility of proposed clinical trials.
 Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
 Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.