Artificial Intelligence
Building your own brand detection and visibility using Amazon SageMaker Ground Truth and Amazon Rekognition Custom Labels – Part 1: End-to-end solution
According to Gartner, 58% of marketing leaders believe brand is a critical driver of buyer behavior for prospects, and 65% believe it’s a critical driver of buyer behavior for existing customers. Companies spend huge amounts of money on advertisement to raise brand visibility and awareness. In fact, as per Gartner, CMO spends over 21% of their marketing budgets on advertising. Brands have to continuously maintain and improve their image, understand their presence on the web or media content, and measure their marketing effort. All these are a top priority for every marketer. However, calculating the ROI from such advertisement can be augmented with artificial intelligence (AI)-powered tools to deliver more accurate results.
Nowadays brand owners are naturally more than a little interested in finding out how effectively their outlays are working for them. However, it’s difficult to assess quantitatively just how good the brand exposure is in a given campaign or event. The current approach to computing such statistics has involved manually annotating broadcast material, which is time-consuming and expensive.
In this post, we show you how to mitigate these challenges by using Amazon Rekognition Custom Labels to train a custom computer vision model to detect brand logos without requiring machine learning (ML) expertise, and Amazon SageMaker Ground Truth to quickly build a training dataset from unlabeled video samples that can be used for training.
For this use case, we want to build a company brand detection and brand visibility application that allows you to submit a video sample for a given marketing event to evaluate how long your logo was displayed in the entire video and where in the video frame the logo was detected.
This is the first in a two-part series on using Amazon Machine Learning services to build a brand detection solution.
|
Solution overview
Amazon Rekognition Custom Labels is an automated ML (AutoML) feature that enables you to train custom ML models for image analysis without requiring ML expertise. Upload a small dataset of labeled images specific to your business use case, and Amazon Rekognition Custom Labels takes care of the heavy lifting of inspecting the data, selecting an ML algorithm, training a model, and calculating performance metrics.
No ML expertise is required to build your own model. The ease of use and intuitive setup of Amazon Rekognition Custom Labels allows any user to bring their own dataset for their use case, label them into separate folders, and launch the Amazon Rekognition Custom Labels training and validation.
The solution is built on a serverless architecture, which means you don’t have to provision your own servers. You pay for what you use. As demand grows or decreases, the compute power adapts accordingly.
This solution demonstrates an end-to-end workflow from preparing a training dataset using Ground Truth to training a model using Amazon Rekognition Custom Labels to identify and detect brand logos in video files. The solution has three main components: data labeling, model training, and running inference.
Data labeling
Three types of labels are available with Ground Truth:
- Amazon Mechanical Turk – An option to engage a team of global, on-demand workers
- Vendors – Third-party data labeling services listed on AWS Marketplace
- Private labelers – Your own teams of private labelers to label the brand logo impressions frame by frame from the video
For this post, we use the private workforce option.
Training the model using Amazon Rekognition Custom Labels
After the labeling job is complete, we train our brand logo detection model using these labeled images. The solution in this post creates an Amazon Rekognition Custom Labels project and custom model. Amazon Rekognition Custom Labels automatically inspects the labeled data provided, selects the right ML algorithms and techniques, trains a model, and provides model performance metrics.
Running inference
When our model is trained, Amazon Rekognition Custom Labels provides an inference endpoint. We can then upload and analyze images or video files using the inference endpoint. The web user interface presents a bar chart that shows the distribution of detected custom labels per minute in the analyzed video.
Architecture overview
The solution uses the serverless architecture. The following architectural diagram illustrates an overview of the solution.

The solution is composed of two AWS Step Functions state machines:
- Training – Manages extracting image frames from uploaded videos, creating and waiting on a Ground Truth labeling job, and creating and training an Amazon Rekognition Custom Labels model. You can then use the model to run brand logo detection analysis.
- Analysis – Handles analyzing video or image files. It manages extracting image frames from the video files, starting the custom label model, running the inference, and shutting down the custom label model.
The solution provides a built-in mechanism to manage your custom label model runtime to ensure the model is shut down to keep your cost at a minimum.
The web application communicates with the backend state machines using an Amazon API Gateway RESTful endpoint. The endpoint is protected with a valid AWS Identity and Access Management (IAM) credential. The authentication to the web application is done through an Amazon Cognito user pool, where an authenticated user is issued a secure, time-bounded, temporary credential that can then be used to access “scoped” resources such as uploading video and image files to an Amazon Simple Storage Service (Amazon S3) bucket, invoking the API Gateway RESTful API endpoint to create a new training project, or running inference with the Amazon Rekognition Custom Labels model you trained and built. We use Amazon CloudFront to host the static contents residing on an S3 bucket (web), which is protected through OAID.
Prerequisites
For this walkthrough, you should have an AWS account with appropriate IAM permissions to launch the provided AWS CloudFormation template.
Deploying the solution
You can deploy the solution using a CloudFormation template with AWS Lambda-backed custom resources. To deploy the solution, use one of the following CloudFormation templates and follows the instructions:
| AWS Region | CloudFormation Template URL |
| US East (N. Virginia) | |
| US East (Ohio) | |
| US West (Oregon) | |
| EU (Ireland) |
- Sign in to the AWS Management Console with your IAM user name and password.
- On the Create stack page, choose Next.

- On the Specify stack details page, for FFmpeg Component, choose AGREE AND INSTALL.
- For Email, enter a valid email address to use for administrative purposes.
- For Price Class, choose Use Only U.S., Canada and Europe [PriceClass_100].
- Choose Next.

- On the Review stack page, under Capabilities, select both check boxes.
- Choose Create stack.

The stack creation takes roughly 25 minutes to complete; we’re using Amazon CodeBuild to dynamically build the FFmpeg component, and Amazon CloudFront distribution takes about 15 minutes to propagate to the edge locations.
After the stack is created, you should receive an invitation email from no-reply@verificationmail.com. The email contains a CloudFront URL link to access the demo portal, your login username, and a temporary password.

Choose the URL link to open the web portal with Mozilla Firefox or Google Chrome. After you enter your user name and temporary credentials, you’re prompted to create a new password.
Solution walkthrough
In this section, we walk you through the following high-level steps:
- Setting up a labeling team.
- Creating and training your model.
- Completing a video object detection labeling job.
Setting up a labeling team
The first time you log in to the web portal, you’re prompted to create your labeling workforce. The labeling workforce defines members of your labelers who are given labeling tasks to work on when you start a new training project. Choose Yes to configure your labeling team members.

You can also navigate to the Labeling Team tab to manage members from your labeling team at any time.
Follow the instructions to add an email and choose Confirm and add members. See the following animation to walk you through the steps.

The newly added member receives two email notifications. The first email contains the credential for the labeler to access the labeling portal. It’s important to note that the labeler is only given access to consume a labeling job created by Ground Truth. They don’t have access to any AWS resources other than working on the labeling job.

A second email “AWS Notification – Subscription Confirmation” contains instructions to confirm your subscription to an Amazon Simple Notification Service (Amazon SNS) topic so the labeler gets notified whenever a new labeling task is ready to consume.

Creating and training your first model
Let’s start to train our first model to identify logos for AWS and AWS DeepRacer. For this post, we use the video file AWS DeepRacer TV – Ep 1 Amsterdam.
- On the navigation menu, choose Training.
- Choose Option 1 to train a model to identify the logos with bounding boxes.
- For Project name, enter
DemoProject. - Choose Add label.
- Add the labels
AWSandDeepRacer. - Drag and drop a video file to the drop area.
You can drop multiple video or JPEG or PNG image files.
- Choose Create project.
The following GIF animation illustrates the process.

At this point, a labeling job is soon created by Ground Truth and the labeler receives an email notification when the job is ready to consume.
Completing the video object detection labeling job
Ground Truth recently launched a new set of pre-built templates that help label video files. For our post, we use the video object detection task template. For more information, see New – Label Videos with Amazon SageMaker Ground Truth.
The training workflow is currently paused, waiting for the labelers to work on the labeling job.
- After the labeler receives an email notification that a job is ready for them, they can log in to the labeling portal and start the job by choosing Start working.
- For Label category, choose a label.
- Draw bounding boxes around the AWS or AWS DeepRacer logos.
You can use the Predict next button to predict the bounding box in subsequent frames.
The following GIF animation demonstrates the labeling flow.

After the labeler completes the job, the backend training workflow resumes and collects the labeled images from the Ground Truth labeling job and starts the model training by creating an Amazon Rekognition Custom Labels project. The time to train a model varies from an hour to a few hours depending on the complexity of the objects (labels) and the size of your training dataset. Amazon Rekognition Custom Labels automatically splits the dataset 80/20 to create the training dataset and test dataset, respectively.
Running inference to detect brand logos
After the model is trained, let’s upload a video file AWS DeepRacer League Championship 2019 and run predictions with the model we trained.
- On the navigation menu, choose Analysis.
- Choose Start new analysis.
- Specify the following:
- Project name – The project we created in Amazon Rekognition Custom Labels.
- Project version – The specific version of the trained model.
- Inference units – Your desired inference units, so you can dial up or dial down the inference endpoint. For example, if you require higher transactions per second (TPS), use a larger number of inference endpoint.
- Drop and drop image files (JPEG, PNG) or video files (MP4, MOV) to the drop area.
- When the upload is complete, choose Done and wait for the analysis process to finish.
The analysis workflow starts and waits for the trained Amazon Rekognition Custom Labels model, runs the inference frame by frame, and shuts the model down when it’s no longer in use.
The following GIF animation demonstrates the analysis flow.

Viewing prediction results
The solution provides an overall statistic of the detected brands distributed across the video. The following screenshot shows that the AWS DeepRacer logo is detected about 25% overall and is detected approximately 60% in the 00:01:00–00:02:00 timespan. In contrast, the AWS logo is detected at a much lower rate. For this post, we only used one video to train the model, which had relatively few AWS logos. We can improve the accuracy by retraining the model with more video files.
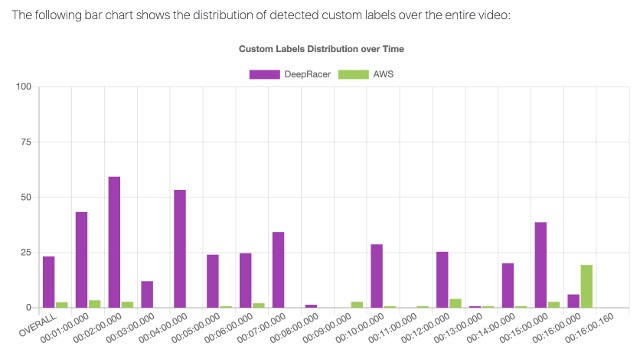
You can expand the shot element view to see how the brand logos are detected frame by frame.

If you choose a frame to view, it shows the logo with a confidence score. The images that are grayed out are the ones that don’t detect any logo. The following image shows that the AWS DeepRacer logo is detected at frame #10237 with a confidence score of 82%.

Another image shows that the AWS logo is detected with a confidence score of 60%.

Cleaning up
To delete the demo solution, simply delete the CloudFormation stack that you deployed earlier. However, deleting the CloudFormation stack doesn’t remove the following resources, which you must clean up manually to avoid potential recurring costs:
- S3 buckets (web, source, and logs)
- Amazon Rekognition Custom Labels project (trained model)
Conclusion
This post demonstrated how to use Amazon Rekognition Custom Labels to detect brand logos in images and videos. No ML expertise is required to build your own model. The ease of use and intuitive setup of Amazon Rekognition Custom Labels allows you to bring your own dataset, label it into separate folders, and launch the Amazon Rekognition Custom Labels training and validation. We created the required infrastructure, demonstrated installing and running the UI, and discussed the security and cost of the infrastructure.
In the second post, we will dive deep on the architecture implementation and how each step designed to build the whole solution
For more information about the code sample in this post, see the GitHub repo.
About the Authors
 Ken Shek is a Global Vertical Solutions Architect, Media and Entertainment in EMEA region. He helps media customers to designs, develops, and deploys workloads onto AWS Cloud using the AWS Cloud best practice. Ken graduated from University of California, Berkeley and received his master degree in Computer Science at Northwestern Polytechnical University.
Ken Shek is a Global Vertical Solutions Architect, Media and Entertainment in EMEA region. He helps media customers to designs, develops, and deploys workloads onto AWS Cloud using the AWS Cloud best practice. Ken graduated from University of California, Berkeley and received his master degree in Computer Science at Northwestern Polytechnical University.
 Amit Mukherjee is a Sr. Partner Solutions Architect with a focus on Data Analytics and AI/ML. He works with AWS partners and customers to provide them with architectural guidance for building highly secure scalable data analytics platform and adopt machine learning at a large scale.
Amit Mukherjee is a Sr. Partner Solutions Architect with a focus on Data Analytics and AI/ML. He works with AWS partners and customers to provide them with architectural guidance for building highly secure scalable data analytics platform and adopt machine learning at a large scale.
 Sameer Goel is a Solutions Architect in Seattle, who drives customer’s success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with Master’s Degree from NEU Boston, with Data Science concentration. He enjoys building and experimenting creative projects and applications.
Sameer Goel is a Solutions Architect in Seattle, who drives customer’s success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with Master’s Degree from NEU Boston, with Data Science concentration. He enjoys building and experimenting creative projects and applications.