AWS Public Sector Blog
An incident response playbook for satellite operations on AWS (Part-2): Automated response and recovery

In part one of this series, we instrumented a satellite ground segment with detection and forensic tooling using Amazon Web Services (AWS) security services. That post configured AWS CloudTrail logging for AWS Ground Station API calls, applied machine learning-based anomaly detection to satellite telemetry, and built a forensic data collection architecture that captures evidence continuously.
This blog covers what to do when those detections fire. Satellite incident response (IR) must account for constraints that ground-based systems never face: containment actions that wait for the next orbital pass, decisions that trade mission continuity against security, and recovery procedures where the compromised endpoint cannot be physically accessed. It walks through containment, eradication, recovery, automated runbooks, and tabletop exercises designed for satellite operations teams.
This blog covers phases three through five of the satellite IR lifecycle. For phases one and two (Preparation and Detection), see part one.
Automated response workflow overview
Manual incident response is too slow when contact windows impose hard deadlines. Pre-build automated runbooks using AWS Systems Manager to reduce response time from hours to minutes. The following diagram illustrates the automation flow from detection through human approval to containment action.
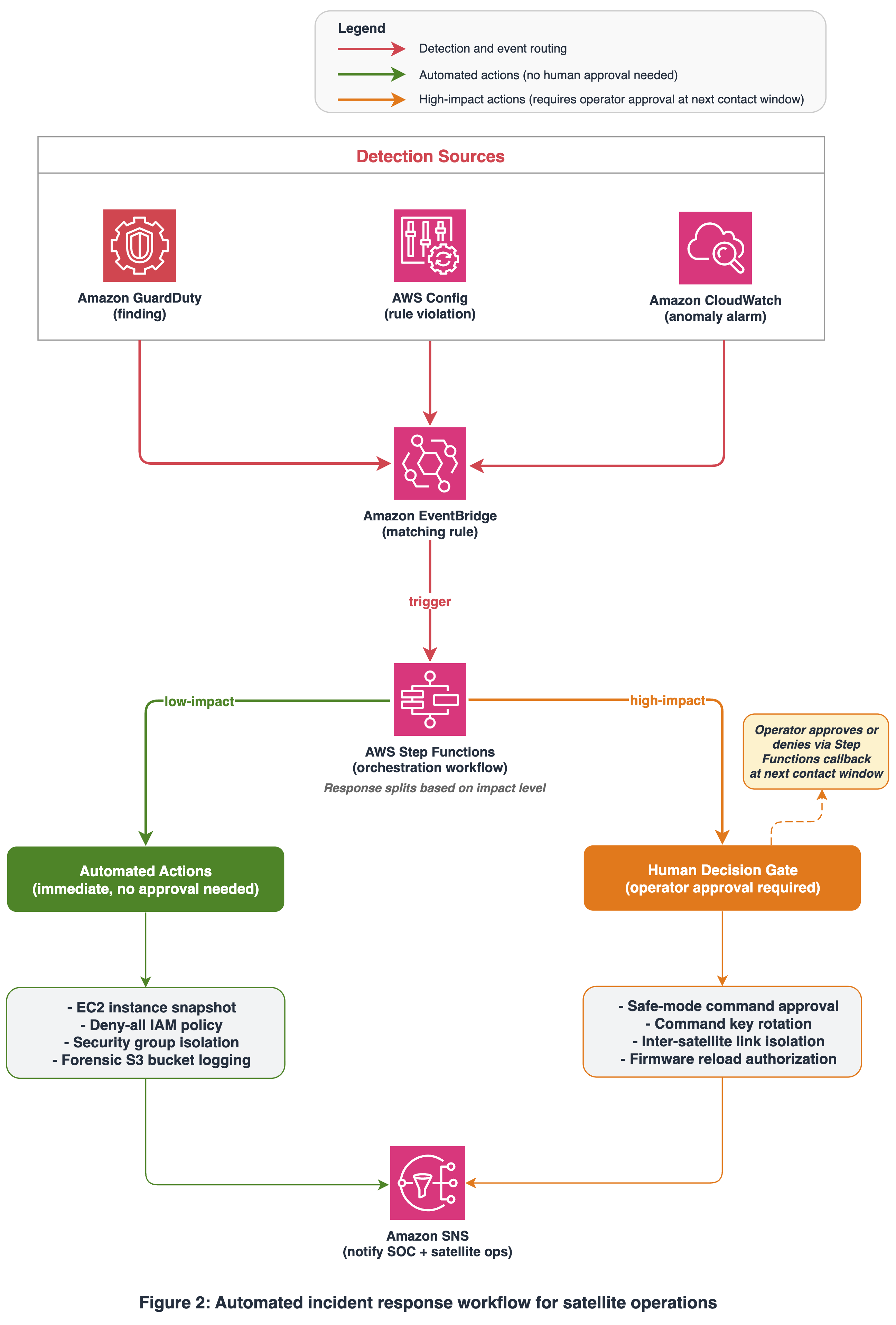
Figure 2. Automated incident response workflow for satellite operations. Detection sources feed findings into Amazon EventBridge, which triggers an AWS Step Functions orchestration workflow. The workflow executes immediate automated containment actions (such as IAM policy changes and instance snapshots) while routing high-impact decisions (such as satellite safe-mode commands) through a human approval gate before execution.
Phase 3: Containment
Containment splits into two domains with fundamentally different timelines. Ground segment actions can execute immediately through standard cloud IR techniques. Space segment actions must wait for the next available ground station pass.
Ground segment containment
For the ground segment, act immediately. Attach an explicit deny-all AWS Identity and Access Management (IAM) policy to compromised identities, preserving the entity for forensics rather than deleting it. Modify security groups on satellite data processing instances to restrict all traffic except to your forensic analysis environment. Isolate the affected VPC by removing routes to other VPCs and the internet while preserving logging connectivity. Modify AWS Ground Station dataflow endpoint configurations to route data to a clean backup environment so that subsequent contacts deliver data to uncompromised infrastructure.
Space segment containment
For the space segment, containment must wait for the next available ground station pass. At that point, switch to backup command encryption keys if primary command authentication is suspected compromised, and command the satellite to a predefined safe mode that limits operations to authenticated commands from a restricted set of ground stations. If your constellation uses inter-satellite links, isolate the affected satellite from the mesh to prevent potential lateral movement. Route subsequent contacts through geographically diverse ground stations to reduce single-point-of-compromise risk.
Containment decision framework
Every containment decision involves a trade-off between security and operational continuity. Pre-approve decision criteria before an incident occurs:
| Scenario | Action | Acceptable if |
|---|---|---|
| Suspected unauthorized command upload | Skip next contact, rotate command keys | Loss of one contact window is tolerable for the mission |
| Ground credential compromise, space segment unaffected | Isolate ground, maintain contacts via backup | Backup infrastructure is pre-provisioned |
| Active data exfiltration from ground segment | Cut network connectivity | Data sensitivity outweighs one orbit of missed data |
| Telemetry manipulation suspected | Cross-validate via multiple ground stations | Multiple stations are available for comparison |
Phase 4: Eradication and recovery
Once the incident is contained, rebuild from known-good state on the ground side and validate the space segment through controlled procedures.
Ground segment recovery
Rebuild affected Amazon Elastic Compute Cloud (Amazon EC2) instances from known-good Amazon Machine Images (AMIs) stored in a separate, access-restricted account. Rotate all credentials, including IAM users, roles, access keys, and application-layer secrets used for satellite communication. Redeploy infrastructure from version-controlled AWS CloudFormation templates, verifying source integrity through Git commit signatures. Verify data integrity by comparing checksums of recently processed satellite data against expected values before resuming normal operations.
Space segment validation
If spacecraft firmware was potentially compromised, follow your validated firmware reload procedure. Test scheduling and configuration first using the AWS Ground Station digital twin, which validates mission profiles, contact scheduling, and integration with your mission control software without consuming production antenna capacity or requiring spectrum licensing. The digital twin does not support data delivery or telemetry delivery, so it validates your operational workflow rather than simulating actual satellite communication.
Require dual approval for the first post-incident command sequence, and monitor satellite health telemetry for at least three full orbit periods (approximately 4.5 hours for a typical LEO spacecraft) after recovery to confirm nominal behavior.
Phase 5: Post-incident activity
After recovery, shift focus to preserving evidence, meeting reporting obligations, and extracting lessons for your next response.
Evidence preservation
Satellite cyber incidents may involve national security implications, regulatory reporting obligations, or insurance claims, so preserving evidence with chain-of-custody rigor is critical. Store all log data in Amazon Simple Storage Service (Amazon S3) with Object Lock in compliance mode, which prevents any principal, including the root account, from modifying or deleting data until the retention period expires. Query archived logs in S3 using Amazon Athena for SQL-based investigation. For near-real-time log analysis, configure your AWS CloudTrail trail to also deliver events to a CloudWatch Log Group, then query them with Amazon CloudWatch Logs Insights. Document the complete timeline, including satellite orbital position at time of incident, ground station used, and space weather conditions during the event window.
Regulatory reporting
Under NIS2, significant incidents require reporting within 24 hours (early warning), 72 hours (initial assessment), and one month (final report). Under SPD-5 principles, operators should share threat information with relevant government and industry bodies. Engage legal counsel early, particularly if the incident may involve state-sponsored actors or affect services across multiple jurisdictions.
Runbook details
The following three runbooks address the most common satellite IR scenarios. Each specifies a trigger (what fires the automation) and the resulting actions.
Runbook 1: Suspicious Ground Station API activity
Trigger: Amazon GuardDuty or CloudTrail Insights detect unusual Ground Station API calls (such as ReserveContact from an unexpected source or DeleteDataflowEndpointGroup outside maintenance windows).
Automated actions:
- Capture IAM entity details and session context.
- Snapshot all Amazon EC2 instances in the affected Ground Station VPC.
- Apply deny-all security group (preserve existing group for forensics).
- Notify satellite operations and security teams via Amazon Simple Notification Service (Amazon SNS).
- Create a case in AWS Security Incident Response.
- Log all actions to the forensic Amazon S3 bucket.
Runbook 2: Telemetry anomaly escalation
Trigger: Amazon CloudWatch alarm detecting telemetry outside expected thresholds, with no known environmental correlation.
Automated actions:
- Begin high-fidelity telemetry recording for subsequent contacts.
- Query your time-series data store for historical baseline comparison.
- Cross-reference with space weather data (automated query to NOAA Space Weather Prediction Center).
- If anomaly persists across multiple contacts without environmental correlation, escalate to security investigation.
- Pre-stage containment commands for human-in-the-loop approval.
Runbook 3: Ground segment credential compromise
Trigger: Amazon GuardDuty finding indicating compromised IAM credentials with Ground Station permissions.
Automated actions:
- Attach deny-all policy to the compromised identity.
- Identify all Ground Station contacts scheduled by that identity in the past 72 hours.
- Review contact outcomes to determine if commands were sent or data was routed to unexpected destinations.
- If commands were sent during suspicious contacts, flag for satellite health assessment at next pass.
- Provision clean replacement environment from AWS CloudFormation templates.
Orchestrating multi-step responses
Use AWS Step Functions to orchestrate multi-step response workflows that incorporate human decision points. For example, a workflow can detect an anomaly, automatically gather context, present a decision to the on-call engineer (“Approve safe-mode command for Satellite-7?”), then execute the approved action during the next contact window. This keeps the human in the loop for high-consequence decisions while automating the time-consuming evidence gathering.
Tabletop exercise scenarios
Regularly exercise your playbook with these scenarios designed to stress-test satellite-specific IR capabilities:
Scenario 1: Unauthorized command upload. An attacker compromises an operator credential and schedules a Ground Station contact to upload malicious firmware. Your detection fires when the ReserveContact call originates from an unrecognized IP address. Can your team cancel the contact before execution begins? What validation do you perform on the satellite afterward?
Scenario 2: Ground segment ransomware. Ransomware encrypts the Amazon EC2 instances running your mission operations center. Your next satellite pass is in 45 minutes, and the satellite requires a routine orbit maintenance maneuver within 3 hours. Can you bring up backup command generation capability in time? Do you have pre-generated emergency command sequences stored separately?
Scenario 3: Telemetry manipulation. An adversary with access to your data processing pipeline subtly modifies telemetry values to hide that they have altered the satellite’s attitude. The modification avoids standard threshold alarms but gradually points the antenna away from its intended coverage area. Can you compare raw telemetry (from DigIF recordings) against processed telemetry to identify discrepancies?
Use the AWS Ground Station digital twin to validate that your scheduling and configuration runbooks execute correctly and that Amazon EventBridge events trigger the expected workflows, without risking production antenna capacity.
Implementation roadmap
You do not need to implement everything at once. A phased approach builds capability incrementally:
Week 1: Turn on AWS CloudTrail for all accounts with Ground Station resources. Activate Amazon GuardDuty in those accounts. Configure an Amazon S3 bucket with Object Lock for forensic log storage.
Month 1: Deploy VPC Flow Logs on satellite data processing VPCs. Establish telemetry baselines in a time-series data store (Amazon Timestream for InfluxDB or Amazon OpenSearch Service). Create the first automated runbook (suspicious API activity). Configure AWS Security Incident Response for satellite operations accounts.
Quarter 1: Build all three automated runbooks with AWS Step Functions orchestration. Conduct your first tabletop exercise. Integrate space weather data feeds. Test scheduling and Amazon EventBridge-triggered workflows using the Ground Station digital twin.
Ongoing: Exercise quarterly. Update runbooks as services evolve and your constellation changes. Participate in the Space Information Sharing and Analysis Center (Space ISAC) for awareness of evolving threat actor tactics targeting space systems.
Conclusion
This blog covered containment, eradication, recovery, automated runbooks, and tabletop exercises adapted for satellite operations on AWS. The framework accounts for contact-window constraints by splitting containment into immediate ground-segment actions and contact-window-dependent space-segment actions, uses a decision table to pre-approve trade-offs between security and mission continuity, and automates response through Amazon EventBridge and AWS Step Functions with human approval gates for high-impact satellite commands.
Combined with the detection and forensic readiness capabilities from Part 1, satellite operators now have a complete IR lifecycle: from instrumentation through detection, containment, recovery, and post-incident learning.
To get started, build the first automated runbook (suspicious Ground Station API activity) using AWS Systems Manager, then schedule your first tabletop exercise using the three scenarios described in this post. For deeper engagement, reach out to the AWS Aerospace and Satellite team or explore AWS Security Incident Response for integrated case management with 24/7 access to the AWS Customer Incident Response Team.
Related reading:
- An incident response playbook for satellite operations on AWS (Part 1): Detection and forensic readiness
- Test and integrate ground segment with AWS Ground Station digital twin
- Strengthen federal space resilience with AWS Ground Station
- NIST IR 8401: Satellite Ground Segment Cybersecurity Framework
- US Space Policy Directive 5: Cybersecurity Principles for Space Systems