使用护栏构建负责任的人工智能应用程序
Amazon Bedrock 护栏提供可配置的安全保障措施,帮助您安全地大规模构建生成式人工智能应用程序。在多种基础模型(FM)中,例如 Amazon Bedrock 支持的基础模型、经过微调的模型以及在 Amazon Bedrock 之外托管的模型等等,护栏采用一致的标准方法,提供了行业领先的安全保护:
- 使用自动推理功能最大限度地减少人工智能幻觉,识别正确的模型响应,准确度最高可达 99%,这是第一项也是唯一一项执行此操作的生成式人工智能保障措施
- 行业领先的文本和图像内容安全保障措施,可以帮助客户屏蔽高达 88% 的有害多模态内容
Remitly 利用 Amazon Bedrock 实现客户支持转型并提高了速度和信任度

KONE 利用 Amazon Bedrock 为负责任的人工智能现场服务提供支持

所有生成式人工智能应用程序和模型都具有一致的安全级别
护栏是主要云提供商提供的唯一负责任的人工智能能力,帮助您为生成式人工智能应用程序构建和自定义安全性、隐私性和真实性保障措施。该服务基于特定使用案例的策略评测用户输入和模型响应,提供超越原生可用功能的额外安全保障层。通过 ApplyGuardrail API 可以将护栏的防护措施应用于在 Amazon Bedrock 上托管的模型或任何第三方模型(例如 OpenAI 和 Google Gemini)。您还可以将护栏与 Strands Agents 等代理框架一起使用,包括使用 Amazon Bedrock AgentCore 部署的代理。护栏提供针对 RAG 内容的上下文基础检查和自动推理检查功能,有助于筛选幻觉并提高事实准确度,从而提供可证明真实性的响应。 查看实施 Amazon Bedrock 护栏的分步指南以了解更多信息。

使用情境化基础检查检测模型响应中的幻觉
客户需要部署真实可信的生成式人工智能应用程序,以保持和增加用户的信任。然而,FM 会因幻觉而产生错误信息:偏离源信息、混淆多条信息或编造新信息。护栏支持情境化基础检查,如果源信息中的响应不合理(例如事实上不准确或新信息)以及与用户查询或指令无关,则可以帮助检测和过滤幻觉。情境化基础检查有助于检测 RAG、摘要和对话应用程序的幻觉,其中源信息可用作验证模型响应的参考。
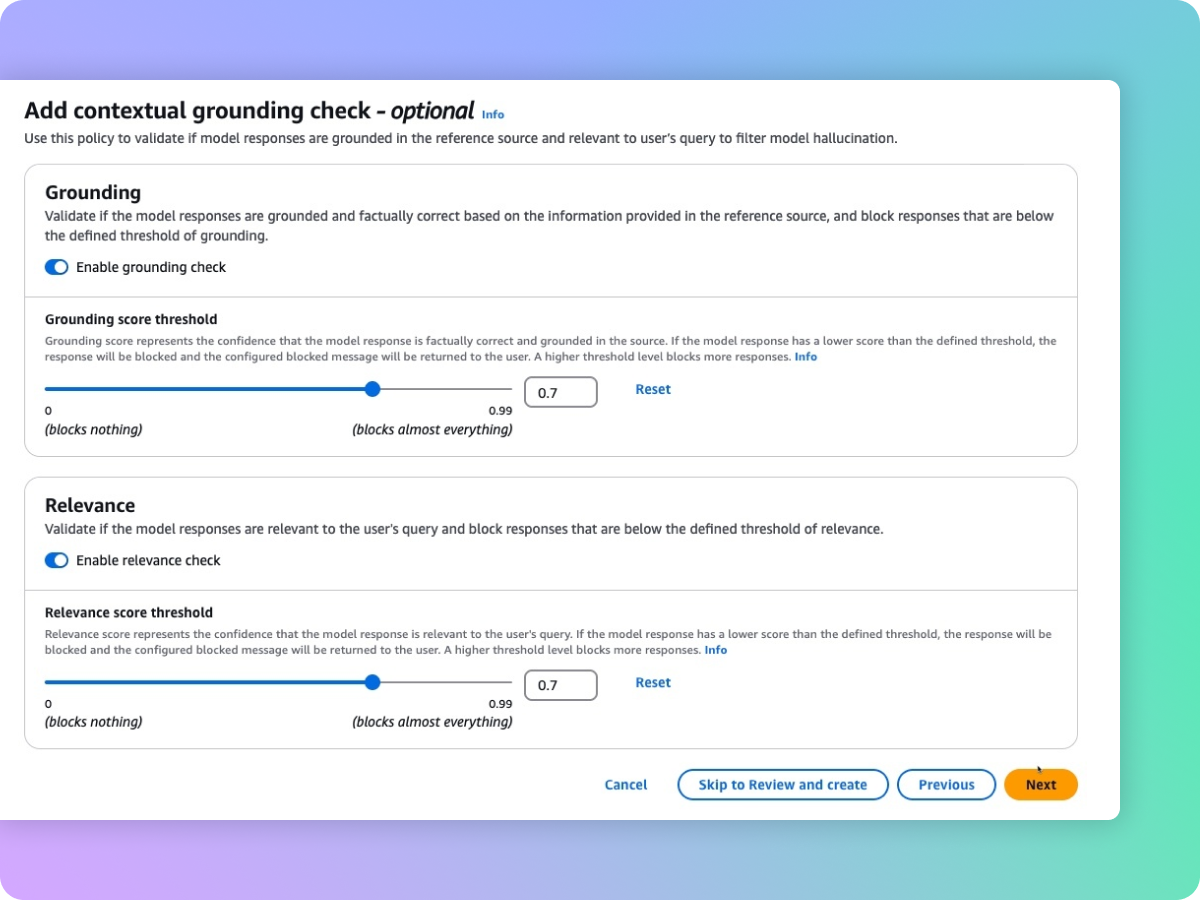
自动推理检查功能可识别正确的模型响应,准确度最高可达 99%,从而最大限度地减少幻觉
Amazon Bedrock 护栏中的自动推理检查功能是第一项也是唯一一项生成式人工智能保障措施,可使用逻辑上准确且可验证的推理来解释响应正确的原因,有助于防止幻觉导致的事实错误。自动推理借助可靠的数学技术来验证/纠正生成的信息,并从逻辑角度解释生成的信息,确保输出结果与已知事实一致,而不是基于虚构或不一致的数据,有助于减少幻觉。开发人员可以通过上传定义正确解决方案空间的现有文档(例如人力资源指南或操作手册)来创建自动推理策略。然后,Amazon Bedrock 会生成自动推理策略,并指导用户对其进行测试和完善。要根据自动推理策略验证生成的内容,用户需要在护栏中启用该策略,并使用自动推理策略列表对其进行配置。这种基于逻辑的算法验证过程可确保模型生成的信息与已知事实一致,而不是基于虚构或不一致的数据来生成信息。这些检查通过生成式人工智能模型提供可证明的真实响应,让软件供应商能够提高其应用程序在人力资源、财务、法律、合规性等使用案例中的可靠性。 查看视频教程以了解更多信息。

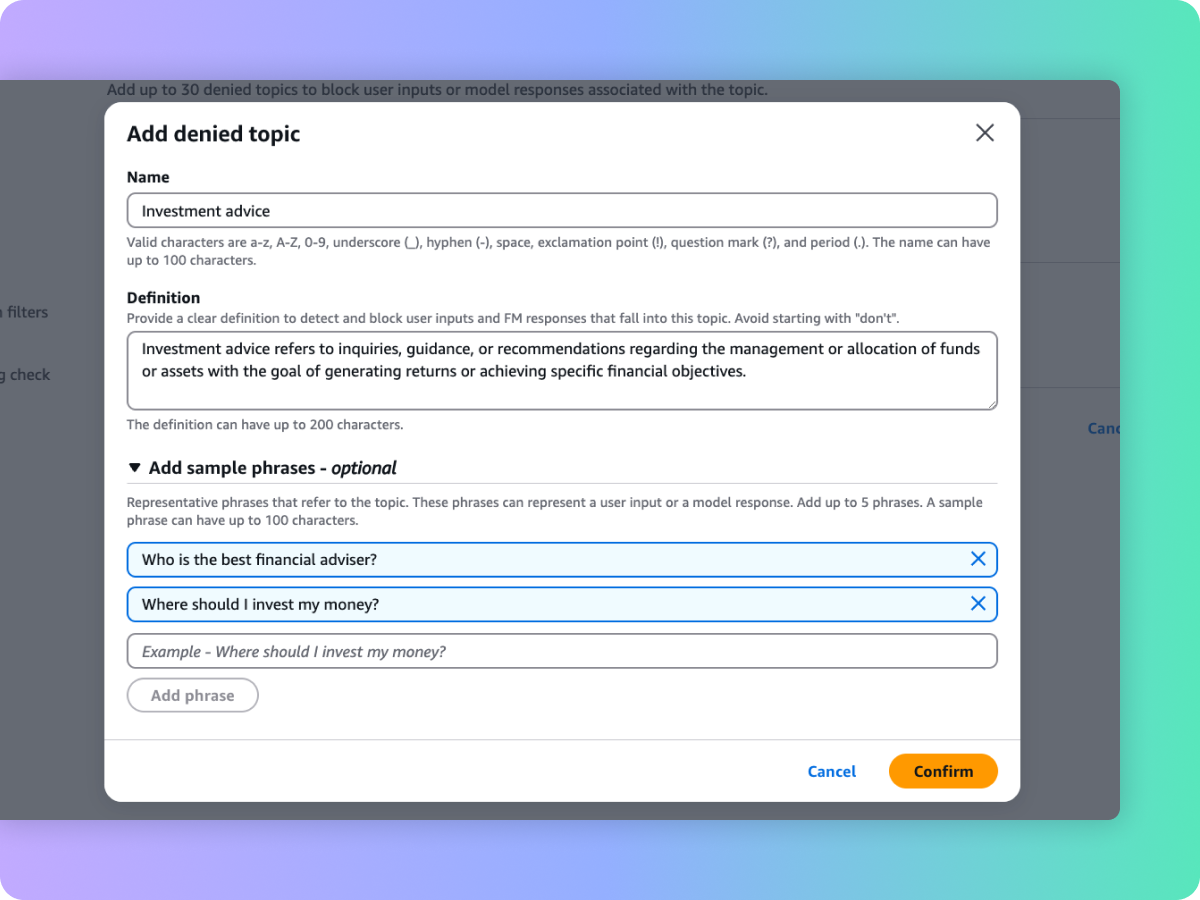
在生成式人工智能应用程序中屏蔽不良主题
组织领导者认识到需要管理生成式人工智能应用程序中的交互,以提供有针对性及安全的用户体验。他们希望进一步自定义交互,继续关注与业务相关的主题,并与公司策略保持一致。护栏有助于通过简短的自然语言描述在应用程序的上下文中定义一组要避免的主题。护栏有助于检测和屏蔽属于受限主题的用户输入和 FM 响应。例如,银行助手可以设计成避开与投资建议相关的主题。
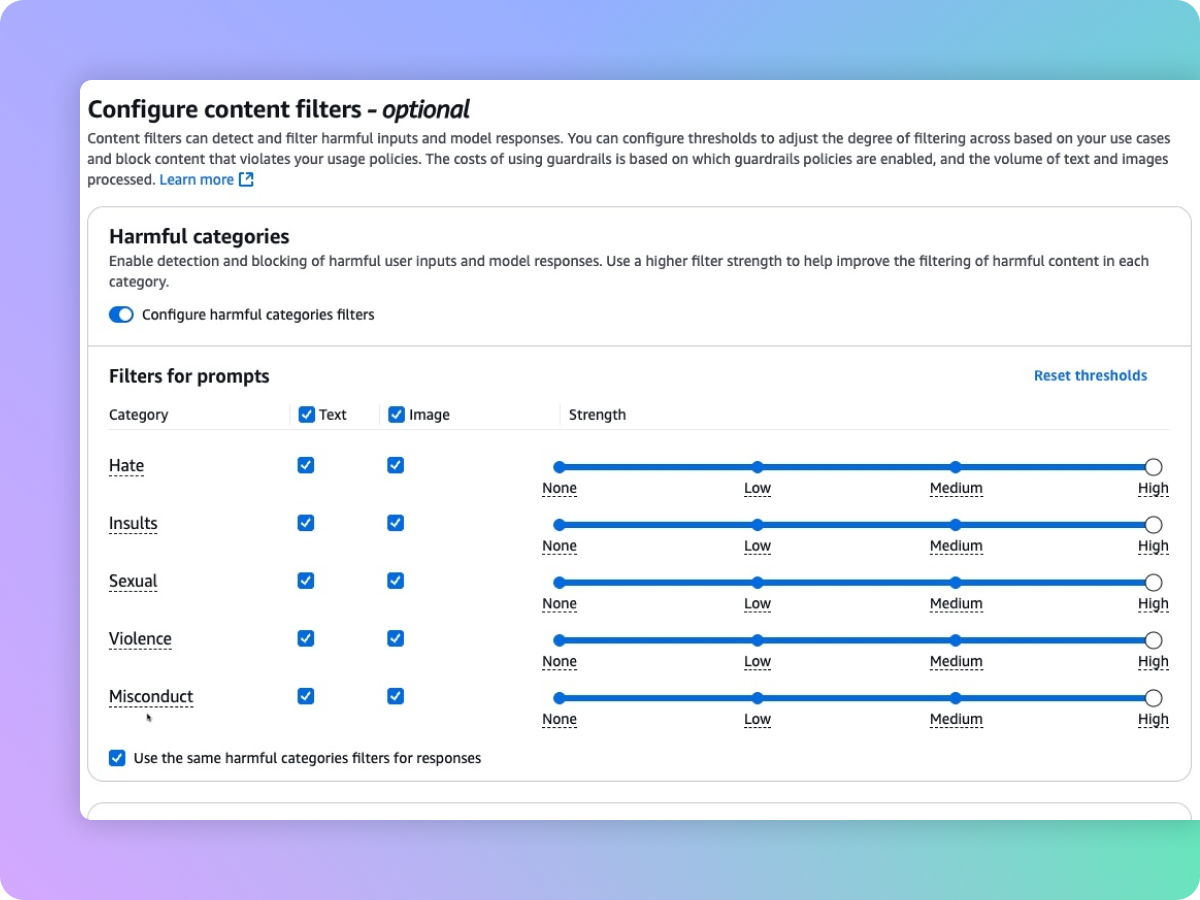
根据您负责任的人工智能策略过滤有害的多模态内容
护栏为有毒文本和图像内容提供了带可配置阈值的内容过滤器。这项安全保障措施有助于过滤包含仇恨言论、侮辱性字眼、性、暴力和不当行为(包括犯罪活动)等主题的有害多模态内容,还有助于防范提示攻击(提示注入和越狱)。内容过滤器会自动评估用户输入和模型响应,以检测并帮助防止不良和潜在有害的文本和/或图像。例如,电子商务网站可以设计其在线助手,以避免使用仇恨言论或侮辱等不当语言。
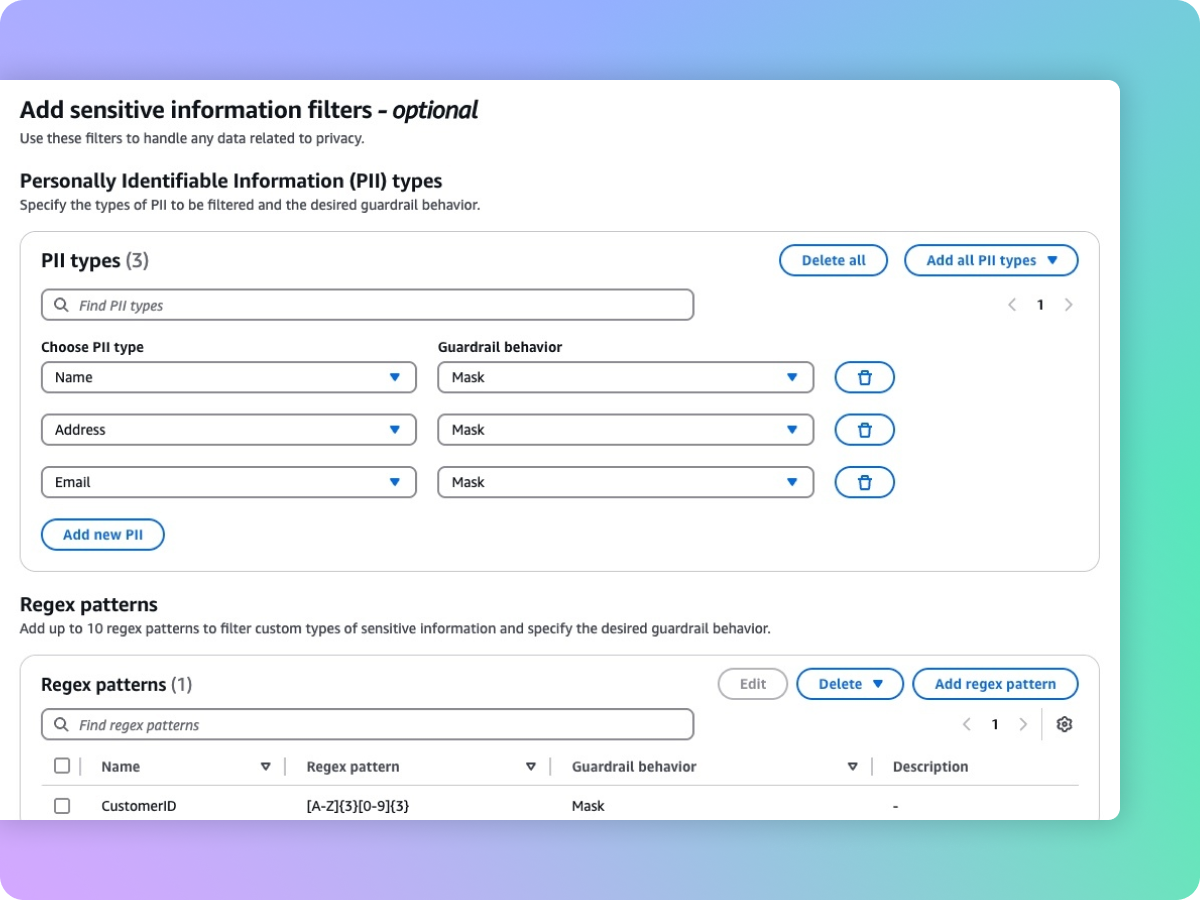
编辑 PII 等敏感信息以保护隐私
护栏帮助您检测用户输入和 FM 响应中的敏感内容,比如个人身份信息(PII)。您可以从预定义的 PII 列表中进行选择,也可以使用正则表达式(RegEx)定义敏感信息类型。根据使用案例,您可以选择性地拒绝包含敏感信息的输入或编辑 FM 响应中的敏感信息。例如,在呼叫中心根据客户和座席的对话记录生成摘要时,您可以编辑用户的个人信息。
后续步骤
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量