亚马逊AWS官方博客
将 Amazon DocumentDB(与 MongoDB 兼容)数据归档到 Amazon S3
在本文中,我们将向您展示如何将存储在 Amazon DocumentDB(与 MongoDB 兼容)中的较旧、访问频率较低的文档集合归档到 Amazon Simple Storage Service (Amazon S3)。Amazon DocumentDB 是一种快速、可扩展、高度可用且完全托管式文档数据库服务,它支持 MongoDB 工作负载。Amazon S3 提供高度耐用、经济高效的归档目标,便于您通过使用标准 SQL 的 Amazon Athena 进行查询。您可以使用 Amazon DocumentDB 和 Amazon S3 针对归档使用案例创建经济高效的 JSON 存储层次结构,以实现以下目标:
- 根据政策、适用的法律法规,支持企业对延长保留期的合规性要求
- 以较低的成本长期存储文档,以满足不常见的使用案例要求
- 将 Amazon DocumentDB 专用于运营数据,同时在 Amazon S3 中维护 JSON 集合以用于分析目的
- 满足 Amazon DocumentDB 中当前最大 64 TiB 数据库和 32 TiB 集合大小限制以外的容量需求
通常,较旧的文档集合访问频率较低,且不需要 Amazon DocumentDB 更高的性能特性。因此,较旧的文档很适合归档到成本较低的 Amazon S3 中。本文介绍了一种使用 tweet 数据的解决方案,它将文档更新存储在 Amazon DocumentDB 中,同时将文档更改流式传输到 Amazon S3。为了保持或减少集合大小,最佳做法是使用滚动集合方法删除较早的集合。相关详情,请参阅使用滚动集合优化 Amazon DocumentDB 中的数据归档成本。
解决方案概述
要将 Amazon DocumentDB 数据归档到 Amazon S3,我们使用 Amazon DocumentDB 更改流功能。更改流提供集群集合中发生的更改事件序列(按时间顺序排列)。应用程序可以使用更改流订阅单个集合或数据库的数据更改。
在该解决方案中,我们使用 AWS Secrets Manager,提供对 Amazon DocumentDB 凭据、集群端点和端口号的安全访问。我们还使用按计划运行的 Amazon EventBridge 规则来触发 AWS Lambda 函数,以将文档更改写入 Amazon S3。EventBridge 是一种无服务器事件总线,使用从应用程序生成的事件,可以轻松地大规模构建事件驱动型应用程序。Lambda 是一种无服务器事件驱动型计算服务,让您能够为几乎任何类型的应用程序或后端服务运行代码,而无需预置或管理服务器。下图展示了该解决方案架构。
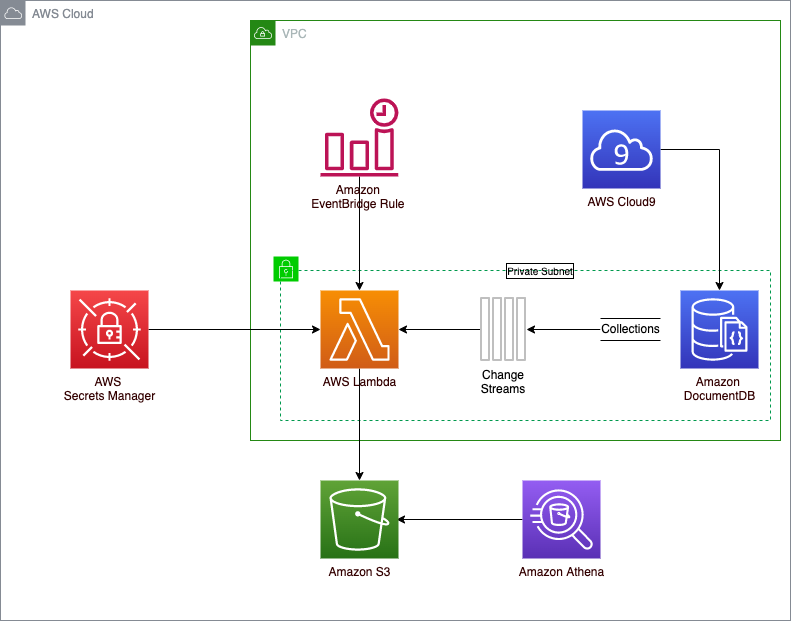
将 Amazon DocumentDB 更改流写入 Amazon S3
我们使用 Lambda 轮询更改流事件并将文档写入 Amazon S3。GitHub 上提供 Lambda 函数。此外,Amazon DocumentDB 研讨会可供您试用该解决方案。
Lambda 函数为无状态函数,运行时持续时间有限。由于这些特性,该解决方案要求 EventBridge 安排 Lambda 函数以定义的频率(在本例中为 1 分钟)运行,以确保对 Amazon DocumentDB 更改流事件进行持续轮询。Lambda 函数连接到 Amazon DocumentDB,并在预定义的 15 秒时间段内监视是否发生更改。在每个轮询周期结束时,该函数将最后轮询的恢复令牌写入不同的集合,以供后续检索。恢复令牌是一种更改流功能,它使用的令牌等于上次检索的更改事件文档的 _id 字段。在 Amazon DocumentDB 中,每个文档都需要一个唯一的 _id 字段作为主键。恢复令牌用作下一次 Lambda 函数调用的更改流检查点机制,以便从上一个函数停止的地方恢复新文档的轮询活动。更改流事件在集群上发生时按顺序排列,默认情况下会在事件记录后存储 3 小时。
对于要归档现有数据的集合,在启用更改流之前,您可以使用 mongoexport 等实用程序,将您的集合以 JSON 格式复制到 Amazon S3。mongoexport 工具可创建数据的时间点快照。然后,您可以使用 resumeAfter 更改流选项,并在导出完成时记录恢复令牌。大致步骤如下所示:
- 使用 mongoexport 将要归档的集合导出到 Amazon S3。
- 记录时间戳和上次更新的 _id。
- 插入 canary 文档,该文档可用作更改流监视文档更新的起点(我们在下面提供了代码块示例)。
- 使用 startAtOperationTime 或 resumeAfter 命令在集合上启用更改流。
如果使用的是 Amazon DocumentDB 4.0+ 版本,则您可以使用更改流的 startAtOperationTime 命令,无需插入 canary 记录(第 3 步)。使用 startAtOperationTime 时,更改流游标仅返回在指定时间戳或之后发生的更改。有关使用 startAtOperationTime 命令的示例代码,请参阅通过 startAtOperationTime 恢复更改流。
您可以使用 change_stream_log_retention_duration 参数,将更改流保留期配置为将更改的文档存储长达 7 天。执行导出操作时,更改流保留期必须足够长,以确保存储从第 1 步中开始导出到第 4 步中完成导出后启用更改流的所有文档更改。
Lambda 代码演示
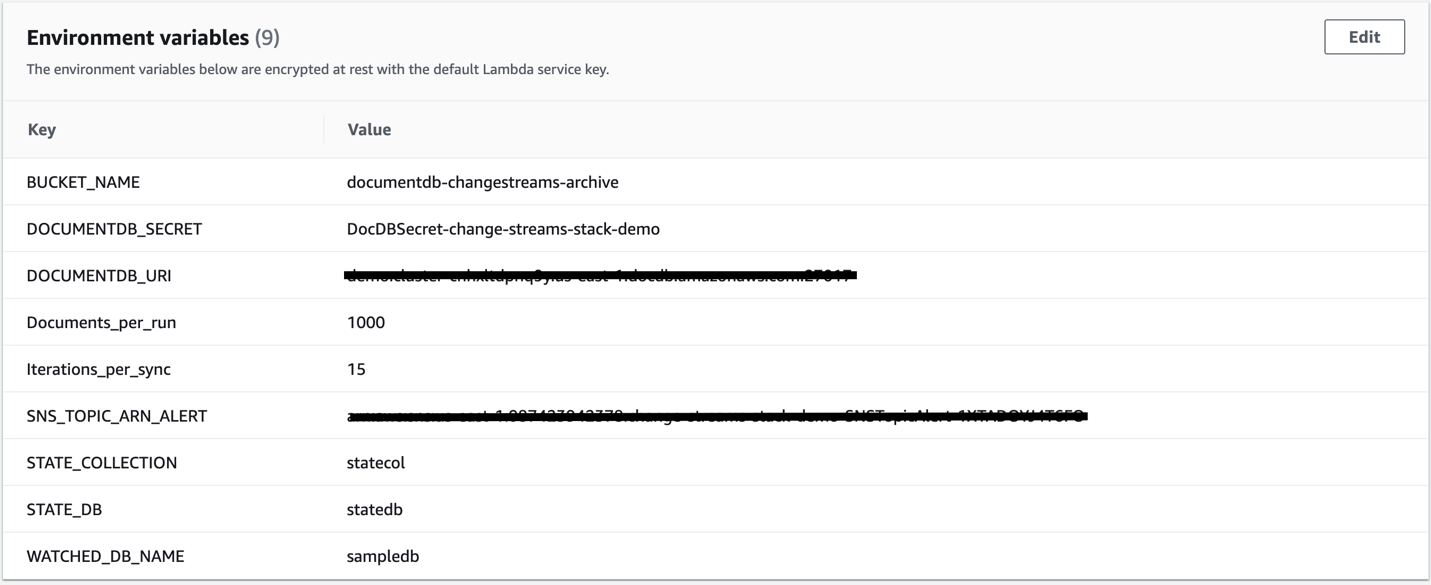
本部分中介绍的 Lambda Python 代码示例可在 GitHub 上找到。Lambda 函数使用环境变量配置数据库以监视更改事件、用于归档数据的 S3 存储桶、Amazon DocumentDB 集群端点以及其他一些可配置的变量,如以下屏幕截图所示。
代码中的 Lambda 处理程序函数使用 PRIMARY 读取首选项建立与 Amazon DocumentDB 集群的连接,并连接到在环境变量 WATCHED_DB_NAME 中配置的数据库。只有连接到 Amazon DocumentDB 集群的主实例(在撰写本文时)才支持更改流。然后,Lambda 处理程序函数检索最后处理过的 _id,以用作下一次 Lambda 调用的恢复令牌,并将其存储在由 STATE_DB 和 STATE_COLLECTION 环境变量识别的单独数据库和集合中。
接下来,我们来讨论一些关键的 Python 代码块。
以下代码是 get_last_processed_id 函数,它存储与上次成功处理的变更事件相对应的恢复令牌:
Lambda 处理程序函数监视更改流中是否存在任何更改事件,并调用 get_last_processed_id 函数:
启用更改流后首次触发 Lambda 函数时,将 last_processed_id 设置为 None。要激活更改流并开始捕获更改事件,需要插入并删除一条 canary 记录,以用作虚拟记录来开始捕获更改事件:
更改在当前调用的循环中流式传输 1 分钟,或者直到每次调用要处理的文档数量达到为止:
change_event 变量包含一个操作类型,用于指示事件是否对应于插入、更新或删除事件。所有事件都包含 _id。插入和更新事件也包括文档正文。change_event 变量的内容用于创建包含文档 ID、正文和上次更新时间戳的负载。然后,此负载将写入由 BUCKET_NAME 环境变量指示的 Amazon S3 存储桶中。
对于删除操作,文档 ID 和上次更新的时间戳存储在 Amazon S3 中:
最后,如果您想要识别已删除的文档并查看文档修订,可以使用文档 ID 通过 Athena 查询 Amazon S3。若要了解详情,请访问研讨会通过 Amazon DocumentDB 更改流归档数据。
结论
在本文中,我们提供了将 Amazon DocumentDB 文档归档到 Amazon S3 的使用案例,以及指向 Amazon DocumentDB 研讨会的链接,供您试用该解决方案。我们还提供了指向解决方案核心的 Lambda 函数的链接,并介绍了一些关键代码部分,便于您更好地理解。
您有需要跟进的问题或反馈吗? 发表评论。要开始使用 Amazon DocumentDB,请参阅开发人员指南。
关于作者
 Mark Mulligan 是 AWS 的高级数据库专家解决方案架构师。他乐于帮助客户采用 Amazon 专门构建的数据库,包括 NoSQL 和 Relational 数据库,以满足业务需求并最大限度地提高投资回报率。他的职业生涯始于客户,担任过大型机系统程序员和 UNIX/Linux 系统管理员等职务,从而使自己逐渐理解了客户对成本、性能、卓越运营、安全性、可靠性和可持续性等方面的要求。
Mark Mulligan 是 AWS 的高级数据库专家解决方案架构师。他乐于帮助客户采用 Amazon 专门构建的数据库,包括 NoSQL 和 Relational 数据库,以满足业务需求并最大限度地提高投资回报率。他的职业生涯始于客户,担任过大型机系统程序员和 UNIX/Linux 系统管理员等职务,从而使自己逐渐理解了客户对成本、性能、卓越运营、安全性、可靠性和可持续性等方面的要求。
 Karthik Vijayraghavan 是 AWS 的资深 DocumentDB 专家解决方案架构师。他一直在帮助客户使用 NoSQL 数据库实现应用程序现代化。他喜欢解决客户问题,热衷于大规模地提供具有成本效益的解决方案。Karthik 在职业生涯之初是开发人员,构建 Web 和 REST 服务,重点关注与关系数据库的集成,从而能够与正在迁移到 NoSQL 的客户产生关系。
Karthik Vijayraghavan 是 AWS 的资深 DocumentDB 专家解决方案架构师。他一直在帮助客户使用 NoSQL 数据库实现应用程序现代化。他喜欢解决客户问题,热衷于大规模地提供具有成本效益的解决方案。Karthik 在职业生涯之初是开发人员,构建 Web 和 REST 服务,重点关注与关系数据库的集成,从而能够与正在迁移到 NoSQL 的客户产生关系。