亚马逊AWS官方博客
在 AWS 上构建自动驾驶和 ADAS 数据湖
Original Link : https://amazonaws-china.com/blogs/architecture/field-notes-building-an-autonomous-driving-and-adas-data-lake-on-aws
领域说明:在 AWS 上构建自动驾驶和 ADAS 数据湖
在开发自动驾驶汽车技术的过程中,客户不断面临着在开发生命周期中捕获和创建大量数据带来的挑战。由于需要对高级驾驶辅助系统 (ADAS) 进行设计和推出增量功能改进,加速了客户受到的挑战。通过努力地提升 ADAS 功能,我们现在开发出新的方法来存储、编目和分析从正在行驶的车辆中获取的驾驶数据。要想将通过蜂窝网络传输的联网自动驾驶车队的数据,与通过手动方式从车辆数据记录仪中提取的数据相结合,需要复杂的架构和弹性数据湖功能,这项功能只有 AWS 能够提供。
本博客介绍了如何使用此参考架构构建自动驾驶数据湖。我们讨论的工作流范围从如何提取数据、为机器学习准备数据、将 ADAS 系统和车辆传感器的输出进行编目、对其进行标注、自动检测场景,到管理那些将其移动到有组织的数据湖构造所需的各种工作流。开发 AWS 自动驾驶和 ADAS 数据湖参考架构之前,我们曾与众多客户合作应对实现这一目标所面临的挑战。通过使用多种 AWS 服务和解决方案最佳实践,我们概述了一种方法,我们发现它对其他人有帮助。
在本博客文章 AWS 上的自动驾驶车辆和 ADAS 开发第 1 部分:实现规模中,我们概述了在云中拥有数据湖与构建自己的本地数据湖解决方案相比的优势。
在深入了解参考架构的详细信息之前,我们先回顾一下自动驾驶汽车和 ADAS 开发的典型工作流程。下图显示了以下步骤,其中很多步骤在机器学习项目中非常常见:
- 数据获取和提取,
- 数据处理和分析,
- 标记、地图开发,
- 模型和算法开发,
- 模拟和验证,以及
- 编排和部署。
本博客重点介绍数据摄取、数据处理和分析、标注以及数据湖本身,如下面的工作流程图所示:

为什么要为 ADAS 和自动驾驶系统开发构建数据湖?
在 AWS re:Invent 2019 期间,BMW 在会议上发表了演讲;(AUT306):在 BMW Group 建立数据驱动型原生云生态系统,在此次讲话中,他们解释了开发企业级云数据湖(他们称之为云数据中心)的动机。云数据中心从多个业务领域提取信息,包括制造系统、物流、客户服务、售后服务和互联车辆传感器遥测数据等来源。
BMW 还创建了一个全球性组织,以推动开发运维文化,重点关注工具、数据质量和端到端数据沿袭。最初,他们从 Hadoop 生态系统(Hive、HBase)起步,该生态系统具有本地、异构且难以扩展的环境,然后再迁移到将重点放在数据质量的原生云构建数据块中。AWS 云实施带来了很多优势,例如多区域部署、高安全标准以及对本地法规的合规性。我们的目标是将最有价值的信息资产民主化,以便可以在遍布全球的广泛社区中使用这些资产。
BMW 云数据中心仅是介绍客户如何管理信息资产以便在整个企业内共享的一个例子。使用类似的方法,AWS 自动驾驶和 ADAS 数据湖参考架构扩展了数据湖模式,以解决以下方面的具体挑战:
- 元数据和数据目录,包括自动场景检测;
- 从来源到语义层的数据沿袭;
- 通过 Amazon SageMaker Ground Truth 与外部消费者和第三方服务提供商共享数据。
现在,我们来回顾一下自动驾驶数据湖参考架构的详细信息:
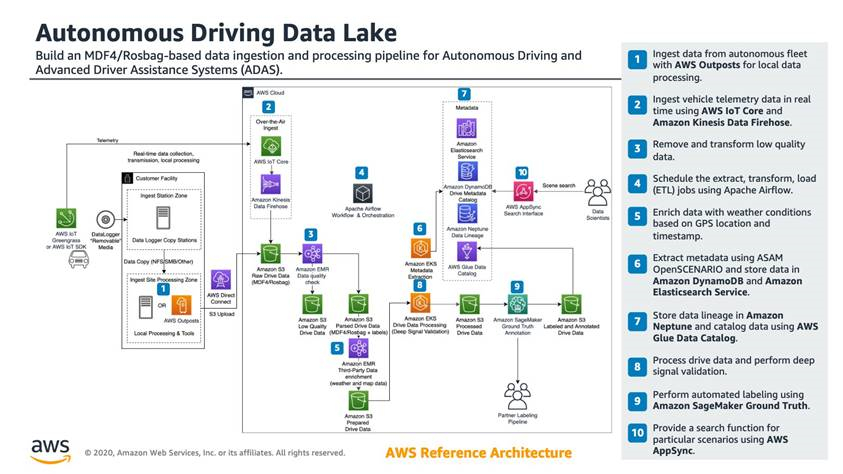
1.使用 AWS Outposts 从自动驾驶车队中提取数据,以进行本地数据处理。
捕获传感器数据并将其写入包含多个 SSD 硬盘的数据记录器中。一旦车辆到达车库或客户场所,硬盘将被移除并插入复制站。 在复制站,数据将复制到 Amazon S3 或本地存储系统和 AWS Outposts 以进行预处理。AWS Outposts 是一项完全托管型服务,可通过 Amazon Elastic Kubernetes Service、Amazon Relational Database Service、Amazon S3 上的 Amazon EMR(EMR 支持 EMRFS 和 HDFS,后两者都在本地支持 S3)等 AWS 服务扩展 AWS 基础设施。这些服务可用于运行数据完整性检查、压缩数据以删除冗余信息并为下游 AD 工作负载准备数据。
使用 AWS DataSync,可以以较高的数据速率在本地网络连接存储 (NAS) 源与 Amazon S3 之间安全地同步数据。该过程通过 AWS Direct Connect 提供的高带宽连接完成。
2.使用 AWS IoT Core 和 Amazon Kinesis Data Firehose 实时提取车辆遥测数据。
使用多种不同的技术(通常通过 HTTPS 或 MQTT)捕获车辆遥测并将其发布到云中。在此架构中,AWS IoT Greengrass 在车辆中提供智能边缘运行时,且其应用程序逻辑在本地部署的 Lambda 函数中运行,以过滤车辆网络信号,如 CAN 数据、GPS 位置、ADAS 系统输出、摄像头生成的道路条件元数据和其他车辆传感器信息。
AWS IoT Greengrass 使客户能够部署容器、机器学习推理模型、创建多个数据流并根据您定义的业务逻辑确定它们的优先级。最终,数据最终会存储在 S3 中,以与从上面第一步定义的数据记录器进程中捕获的传感器数据结合。
3.删除和转换低质量数据。
自动驾驶汽车每小时会生成数 TB 数据。在这个信息宝库中,可能也会有来自车辆遥测流和原始传感器堆栈中的冗余数据以及损坏的数据。 需要对这些数据进行规范化,以实现最佳的下游处理。客户可以使用很多技术来实现这一点。例如,Amazon EMR 使用开源 Apache 大数据处理引擎(如 Spark)为大容量的复杂数据处理提供运行时。 数据转换过程有几个常见步骤,包括:
- 通过合并批处理文件和流数据,检查驾驶是否完成;
- 根据记录格式(rosbag,mdf4 等)解析日志文件;
- 将信号从二进制格式解码为可读文本;
- 过滤不一致的数据文件;以及
- 同步信号的时间戳
EMR Launch 是 AWS Labs 开发的一个开源框架,可供客户加快和简化定义、部署、管理和使用 Amazon EMR 集群的过程,具有以下功能:
- 将集群安全配置(EMR 配置文件)和集群资源配置(集群配置)的定义分离成可重复使用和可共享的构造;以及
- 提供一套工具,以使用 Amazon Step Functions(EMR 启动函数)简化编排管道的构建。
4.使用 Apache Airflow 计划提取、转换、加载 (ETL) 作业。
要创建值得信赖的见解,并为您的下一个机器学习使用案例提供可靠的数据基础,您需要将数据创建过程置于设计控制之下。实现这种方法的基础是一个由 Apache Airflow 提供支持的集中管理的工作流系统。借助 Airflow,您可以通过将工作流作为代码库的一部分来实现透明、可重复的管道执行,从而建立对数据处理管道的信任。
下面的解决方案图显示了 MDF4 格式的雷达和视频数据处理如何通过利用适用于 Amazon ECS 的 AWS Fargate 实现最高的可扩展性。
-
- 为确保数据管道的完整性,该解决方案通过端到端 TLS 安全地部署在 Amazon Virtual Private Cloud 中,并且只能从私有堡垒主机访问。
- 为了实现高可用性,Airflow Webserver、计划程序和工作线程部署在多个可用区中。
- 这些组件之间的通信通过 Amazon ElastiCache for Redis 解耦。
- 正在运行的作业的状态存储在 Amazon Aurora 中。
- 要了解有关如何在 AWS 上利用复杂的工作流程和对训练作业进行建模的更多信息,未来我们将通过一篇博客文章来介绍 Apache Airflow 的详细架构。

5.利用基于 GPS 位置和时间戳的地图信息和天气条件丰富数据。
使用 Amazon EMR 通过来自外部地理空间和气象服务提供商的地图或天气信息丰富数据集,并将数据集存储在 Amazon S3 或 Amazon DynamoDB 之类的数据库服务中。摄像头和 LiDAR 等传感器在恶劣天气条件下可能会出现故障,甚至失效。先进的传感器融合可以实时进行天气感知。天气感知的结果可以使用真实的天气条件进行验证。
6.将元数据提取到 Amazon DynamoDB 和 Amazon Elasticsearch Service 中。
使用包含遥测、远程信息处理、感知和传感器数据的驾驶日志构建目录,以创建可搜索的定量元数据,其中包括速度、转弯角度、位置以及场景片段简单而复杂的语义描述,例如“高速”、“左转”或“行人”。 使用场景数据对数据湖目录进行更新,并在 Amazon Elastic Search 中编入索引,以便分析师和 ADS 工程师发现。 提取过程理想情况下是完全自动的,但很多高阶行为描述可能需要后续处理步骤中的人为注释。
大多数系统利用驾驶数据的量化和简单的语义描述,其明显趋势在于需要在数据湖目录中提取更高阶的行为。 这些更复杂的行为是增强搜索功能和更好地验证覆盖映射的理想选择。 ASAM OpenSCENARIO 定义了一种场景描述语言,该语言提供通用的本体和层次结构,用于详细说明车辆和周围环境的行为。
该标准提供了一种开放的方法,用于描述涉及多个实体的复杂、同步的操作,包括其他车辆、易受伤害的道路使用者 (VRU)(如行人、骑行者、建筑工人和其他交通参与者)。操作的描述可能基于驾驶员的操作,例如通过自我执行车道更换,或者基于场景中其他人的操作,例如超车。OpenSCENARIO 还对场景中参与者的出现/描述进行了解释。
7.将数据沿袭存储在 Amazon Neptune 中,并使用 AWS Glue Data Catalog 对数据进行编目。
Amazon Neptune 是全面托管型图表数据库服务。可以用它帮助在图表模型中进行数据沿袭编目,以可视化文件和对象依赖项。AWS Glue 是一项完全托管型服务,可提供数据目录,使数据湖中的资产可被发现。Amazon Athena 是一种交互式查询服务,可使用标准 SQL 轻松分析 Amazon S3 中的数据。
下图显示了我们如何使用 Amazon EMR 解析来自福特自动驾驶车辆数据集中的 Rosbag 格式的数据。我们将数据以 parquet 格式存储在 Amazon S3 中,使用 AWS Glue 爬网程序读取文件架构并在 AWS Glue Data Catalog 中创建表,最后使用 Amazon Athena 查询速度数据。

8.处理驾驶数据并执行深度信号验证。
在 Amazon Elastic Kubernetes Service (Amazon EKS) 中部署您的驾驶数据信号验证代码。EKS 是一种托管服务,使您可以轻松运行 Kubernetes,而无需支持或维护自己的 Kubernetes 控制平面。将只会从 Rosbag 或 MDF4 文件中提取信号子集来进行 KPI 计划和聚合,从而可能会将存储的数据量从 GB 减少到 MB。
9.使用 Amazon SageMaker Ground Truth 执行自动标记。
Amazon SageMaker Ground Truth 是一项完全托管的数据标记服务,可用于轻松构建高度精确的训练数据集以进行机器学习。Ground truth 提供自动数据标记和/或注释,该服务使用机器学习模型来标记您的数据。
此外,该服务还可帮助您创建用于数据标记的自定义工作流,该工作流利用 Amazon Mechanical Turk、AWS 合作伙伴网络的人工工作人员或您自己的私人劳动力来提高自动标记准确性。Ground Truth 现在支持 3D 点云标记来执行对象检测、对象跟踪和语义分割之类的任务类型。本博客介绍了如何通过 Audi A2D2 和 KITTI 中的开放数据集使用该服务。或者,客户还可以在 Amazon EKS 上运行自定义容器,以进行 Ground Truth 生成或标记。
10.使用 AWS AppSync 为特定场景提供搜索功能。
开发人员和数据科学家可以搜索某个特定场景以及与之相关的所有相关元数据。AWS AppSync 是一种托管服务,它使用 GraphQL 使应用程序能够轻松地从一系列数据源(例如 Amazon DynamoDB、Amazon ES 和 AWS Lambda)中获取数据。
需要考虑的其他方面
-
-
- 中国:收集包括视频、激光雷达、雷达和 GPS 数据在内的原始数据,该过程被定义为政府受控活动(地理信息测绘)。这是一项受管制的活动,必须在拥有导航测量许可证的本地认证地图供应商的管理下进行。
- 数据加密和匿名化:一些 ADS/ADAS 使用案例包括敏感信息或个人信息。AWS Key Management Service (KMS) 支持客户主密钥 (CMK)。车辆识别号 (VIN) 可以通过 Amazon EMR 作业进行匿名化。本博客展示了如何使用 Amazon Rekognition 对视频中的人脸等个人数据进行匿名化处理。
- 与合作伙伴交换数据:AWS Data Exchange 是一项服务,使 AWS 客户能够轻松地在 AWS 云中安全地交换基于文件的数据集。AWS Data Exchange 中的提供商拥有安全、透明且可靠的渠道,可以联系 AWS 客户并更有效地将订阅授予现有客户。
- 数据湖即代码:AWS 提供完整的开发运维工具堆栈,其中包括 AWS CodeCommit、AWS CodeBuild 和 AWS CodePipeline,以简化基础设施的预置和管理、部署应用程序代码、自动执行软件发布流程,以及监控应用程序和基础设施性能。还可以集成 Jenkins 和 Zuul 之类的第三方 CI/CD 工具。
-
结论
在本博文中,我们讨论了此参考架构中概述的用于在 AWS 上构建自动驾驶和 ADAS 数据湖的步骤。我们希望它对您有所帮助,并期待您对此架构提出建议。
此外,请查看 AWS Architecture Monthly Magazine 的自动驾驶期刊。
领域说明根据 AWS 解决方案架构师、顾问和技术客户经理在为客户解决实际业务问题方面的经验,提供了来自他们的实践技术指导。