AWS for Industries
Autonomous Vehicle and ADAS development on AWS Part 1: Achieving Scale
Companies focused on Autonomous Vehicle (AV) and ADAS (Advanced Driving-Assistance Systems) development require extensive computing resources to accelerate the development process and get ADS/ADAS vehicles to roads. A typical SAE L2+ company collects and stores 10s-100s of TBs of new vehicle data daily that they have to process and analyze. They need 1000s of GPUs to train their ML models, and they require millions of CPUs to validate their software/models with log or synthetic simulations. Most executives in the space know they will run into data center constraints given their expected storage (i.e., capacity, IO, data pipeline flexibility) and compute scale – using only on-premises infrastructure reduces the speed of developing autonomous systems.
To solve this data center problem, most of these companies have incorporated cloud computing as part of their AV development strategies, whether it’s to augment their existing on-premises resources or to rely on cloud infrastructure for the bulk of their compute needs. Or perhaps, like some of our AV customers, they recognized early on that they could not fulfill their development needs in their own data centers and were born in the cloud.
So how should a company think of doing of their AV development on AWS? There are nuanced differences across customers, but we’ve assessed a common set of workload categories across most of our customers (see the “AD/ADAS Development Flywheel” below): Data Acquisition and Collection, Data Ingest , Data Processing and Analytics, Labeling and Data Mining, Map Development, Simulation/Validation, Model and Algorithm Training, Management and Orchestration, and Deployment.
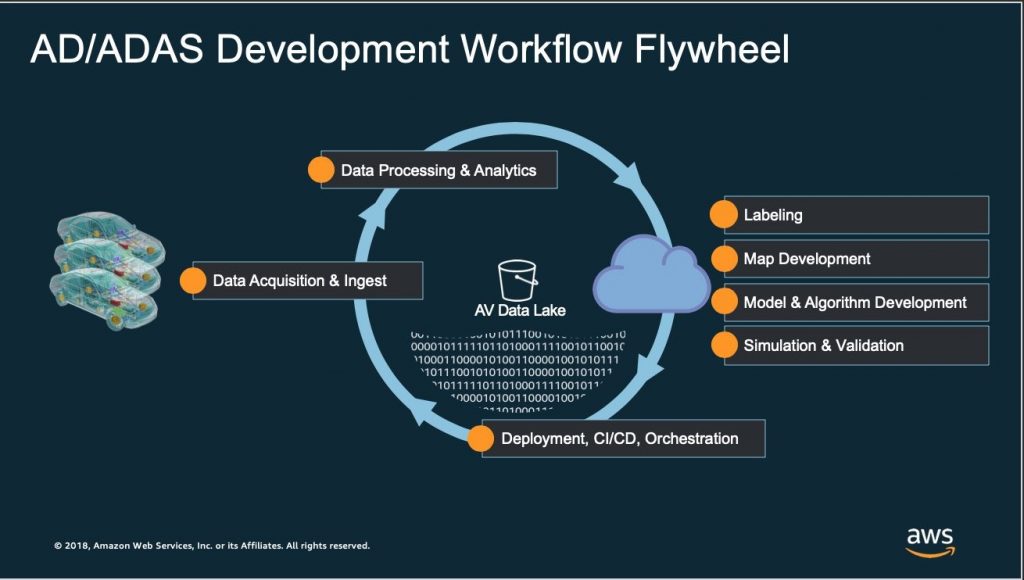
I don’t have space in a single blog post to talk about each workload and how it runs on AWS, so over the next few months in our “AD/ADAS Development on AWS” blog series we will dive deeper into each of these to provide some background context, a framework for how to execute on AWS, and some application in context.
Today, I want to start with the problems we see customers encounter with scalability and cost. To simplify, I narrowed the cost/scale challenge to three different cost buckets: storage, networking, and compute. Cloud makes sense to augment or replace on-premises resources in each of these categories.
Storage
The starting point of the model and algorithmic development process is data collection. Lots of data — as in exabyte-scale data lakes. Customers don’t have the space and equipment to handle this much data, or it’s simply cost prohibitive for them to try. These storage subsystems require highly complex data pipelines that the data lake needs to accommodate, stressing on-premises build outs with limited throughput, capacity, elasticity, and integrated security mechanisms. We often see customers start with HPC oriented solutions that are difficult to build, manage, and maintain. AWS provides Amazon Simple Storage Service (Amazon S3) in multiple storage classes to tier data based on retrieval frequency. AWS also provides a host of other services such as Amazon Athena for massive scale querying of your data, data lake patterns with integrated processing and analytics pipelines using open source or native AWS services such as Amazon Elastic Search (Developer interface), DynamoDB (metadata noSQL database), and FSx for Lustre to quickly and cost-effectively process datasets for large ML training jobs and massive scale simulations.
Networking
But before you can store and process data, you have to get it from the car to the cloud. And then you have to retrieve/reprocess these datasets for testing hardware that more often than not sits on-premises. The closer the cloud data center, the better. Customers use AWS Direct Connect to get up to 100G network connections, speeding up the ingestion of their datasets. With the long list of AWS Direct Connect partners spread across the globe, it’s easier to find an AWS Direct Connect hookup closer to your ingest sites or work with our APN partners to manage ingest for you. AWS has 89 Direct Connect locations and counting.
Compute
Finally, AV companies are concerned about being able to achieve supercomputer scale running hundreds of thousands of concurrent CPUs and thousands of GPUs for simulation and training (respectively). Customers are trying to find ways to reduce or completely eliminate their need to acquire cost prohibitive hardware. Particularly when it comes to GPUs where extensive experience is required to fully utilize the hardware, customers are doing away with inefficient on-premises deployments in order to match their GPU capacity to their actual (rather than predicted) training and inference needs.
Amazon EC2 is able to meet those compute needs across CPUs (i.e., Intel and AMD) and GPUs (K80s, V100s, T4s, A100s, etc.), as well as with AWS custom silicon such as AWS Graviton (CPU) and AWS Inferentia, a chip specially designed for our customers’ inference needs.
Here’s an example where we scaled to more than 1.6M vcpus just in the Northern Virginia region. We could have kept going, but decided to end the test early and save some money.

AWS Scale: 1.66M vcpus – all on EC2 Spot. Image Source: Pierre-Yves Aquilanti
We did this all on EC2 Spot, our spare capacity (which average discounts of 70-90% over On-Demand Instances). People often consider their costs at scale. What people rarely consider, however, is the cost benefit more total capacity implies for total spare capacity. The fact that AWS has so much capacity enables customers to take advantage of more spare capacity (which is much cheaper — this is critical at such high scales).
Summary and Future Posts
To recap, the fact that AWS has more storage, compute, and network capacity across more geographies enables customers to accommodate the scale they need, and in the right locations to satisfy hybrid scenarios such as ingest or hardware-in-the-loop (HIL) workloads, as well as data locality and other regulatory requirements.
Throughout the rest of 2020 we will dive into each of these main AV Development workloads (see flywheel above), beginning with our next post on methodologies regarding vehicle data acquisition and ingestion of that data into AWS.