亚马逊AWS官方博客
使用 R 和 Amazon Web Services 进行文档分析
本博文由 Summit Consulting 的主管数据科学家 David Kretch 特约发表。
在我们以前的博文中,我们讨论了 R 的基本知识和 AWS 上 R 的常见工作负载对。在这个两篇系列文章的第二篇中,我们将更加深入的探讨如何使用 AWS 服务构建文档处理应用程序。我们将介绍如何将 AWS 与 R 结合使用来创建数据管道,以便从 PDF 中提取数据供以后处理。
在本示例中,我们从 Amazon Simple Storage Service (Amazon S3) 中存储的 PDF 开始,使用 Amazon Textract 提取文本和表格形式的信息,然后将数据上传到 PostgreSQL Amazon Relational Database Service (Amazon RDS) 数据库。我们将使用 Paws AWS 开发工具包从 R 运行时中访问所有这些服务。下图显示了它的工作原理。
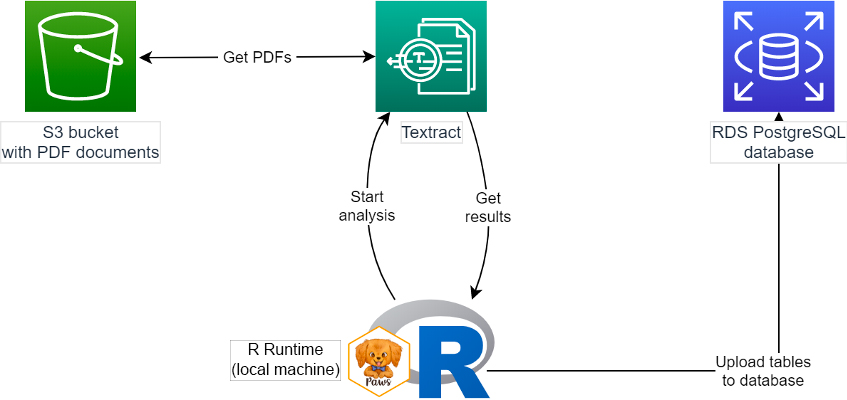
对研究人员来说,很难从 PDF 和图像中提取大量有价值的数据来进行分析。例如,SEC Form 10-K 年度财务报告、报纸文章的扫描件、历史文档、FOIA 回应等等。分析它们中的数据在逻辑上是不切实际的,但现在,使用更好的机器学习技术,我们可以开始将它们用作研究的数据源。
在本文的示例中,我们使用的是联邦储备银行制作的包含美国经济历史预测的 PDF 文档,称为 Greenbook 预测(或 Greenbook 数据集)。这些 PDF 由文本组成,中间穿插着表格和图形,额外增加了难度。Greenbook 预测由费城联邦储备银行提供。
在本文中,我们假设您已经有包含 PDF 和 Amazon RDS 数据库的现有 S3 存储桶。虽然您可以从 R 内创建这些 AWS 资源,但我们还是建议您使用专为预置基础设施而设计的工具,例如 AWS CloudFormation、AWS 管理控制台或 Terraform。
我们还假设您已经配置本地凭证来访问 Amazon Textract。您可以通过导入环境变量并将它们存储在凭证文件中,或者在 EC2 实例或者附加了具有适当权限的 AWS Identity and Access Management (IAM) 角色的容器中运行 R 来实现此配置。如果没有,您必须明确提供凭证;您可以在以前的文章中查看相关文档,并在 Paws 文档中查看明确的说明。
提取文本和表格
众所周知,从 PDF 中提取数据很难。最早的 Greenbook 预测 PDF 是 20 世纪 60 年代编制的原始报告页面的图片。较新的报告使用 PDF 版面语言,但即便如此,PDF 中也没有底层结构,只有位于页面上各个点的字符。
为了从这些 PDF 中获取有用的数据,用户必须使用光学字符识别将文本图片转换为字符(需要时),然后根据这些字符在页面上的位置推断句子、段落和语篇结构。Greenbook 预测中还包含表格。在此,我们需要识别表格的位置,然后根据页面上的单词或数字的位置和间隔来重建表格的行和列。
为执行此操作,我们使用 AWS 托管的 AI 服务 Amazon Textract 从图片和 PDF 中获取数据。借助适用于 R 的 Paws 开发工具包,我们可以使用操作 start_document_text_detection 获取 PDF 文档的文本,并且可使用操作 start_document_analysis 获取文档的表格和表单。
这些操作属于异步操作,这表示,它们将初始化文本检测和文档分析作业,从而返回特定作业的标识符,我们可以对此标识符进行轮询以检查完成状态。作业完成后,我们可以通过传入作业 ID,分别使用第二个操作 get_document_text_detection 和 get_document_analysis 检索结果。
我们使用以下代码获取单个文档的表格数据。我们告知 Amazon Textract 文档在 S3 存储桶中的位置,Amazon Textract 则会将即将开始的文档分析作业的 ID 返回给我们。然后 Textract 在后台读取文件并执行分析。同时,我们可以继续检查作业是否完成,然后在作业完成后,立即获取结果。
这是一个简化的示例;事实上,我们可能会同时开始所有的文档分析作业,然后再收集所有结果,因为作业可能并行运行。此外,分析结果可能会太大,无法一次性全部发送,您可能需要单独获取额外的部分;文本结尾处提供的完整的源代码列表可处理此情况。
我们从 Textract 文档分析作业中重获的结果将分为多个数据块。对于包含表格的文档,有些数据块为 TABLE 数据块,表的单元格在 CELL 数据块中,而单元格的内容在 WORD 数据块中。您可以在 Textract 表格文档中阅读关于它们的运行方式的更多信息。
现在,我们需要将 Textract 结果转换为我们可以更轻松使用的形状。首先,我们来看看原始形式的表格,及如何通过 Textract 将该表格返回给我们。下面是 1966 年 1 月文档第三部分的表格。

下面是 Textract 分析返回的三个示例数据库:
1.这是此表格的数据块;您可以在下面看到,它的 BlockType 为 TABLE,它来自第 3 页(在页面元素中),且在关系下拥有 256 个子数据库(单元格)。
2.这是表格第 1 行第 2 列的单元格,如 RowIndex 和 ColumnIndex 元素所示。此单元格有一个子数据块。
3.最后是上述单元格中的单词数据块,其中包含文本 Year。
要重建表格,我们使用每个单元格的行和列编号合并表格中的所有单元格。下面的代码可执行此操作;它将返回文档中所有表格的列表,每个都以矩阵形式。该代码通过以下操作实现这一点:
- 逐个迭代每个表格的单元格
- 从单词数据块中提取每个单元格的内容
- 将单元格内容插入内存表矩阵中的适当行和列
请注意,上面的函数get_children 可获取数据块的子数据库;为了简洁起见,此处予以省略,但显示在本文结尾提供的源代码列表中。
此代码产生类似以下内容的矩阵,这非常好:

要在我们的所有 PDF 上运行这个相同过程,我们只需要从 S3 中获取 PDF 列表,我们可以使用 S3 list_objects 操作获取此列表。然后,我们可以循环处理所有可用的 PDF,并使 Textract 通过多个并行处理作业获取其文本和表格。
将数据上传到数据库
现在,我们已经处理好表格,接下来将它们上传到我们的 PostgreSQL 数据库中,以便稍后进行进一步的下游分析。
在 RDS 上运行的适当配置的 PostgreSQL 服务器支持通过 IAM 进行身份验证,从而无需存储密码。如果我们使用具有适当权限的 IAM 用户或角色,我们可以使用 IAM 身份验证令牌从 R 连接到我们的 PostgreSQL 数据库。Paws 软件包也支持此功能;在 AWS 开源计划的支持下开发的功能。
我们使用 build_auth_token 生成的令牌从 Paws 软件包连接到我们的数据库。
在此连接下,我们将结果上传到数据库中的表格。由于我们从文档中获取的表格不一定都拥有相同的形状,我们将它们上传为 JSON 数据。PostgreSQL 的其中一项功能为,它在本地允许我们将任何形状的数据存储在 JSON 列中。
现在,数据已在数据库中,我们可以轻松访问它,以便今后进行分析。
后续步骤
在此实现中,由于 R 默认为单线程,一次将处理一个文档(按顺序)。在较为复杂的实现中,我们可以使用 parallel 或 futures 软件包来并行处理这些文档,或者无需等待每个文档处理完成。由于复杂性增加,我们避免在本文中展示此情况。对于希望增加自动化的人,可以将 S3 文件上传设置为调用下游计算服务(Lambda、ECS)的事件触发器,这些计算服务可以执行此处引用的代码。

David Kretch
David Kretch 是 Summit Consulting 的主管数据科学家,他为联邦政府和私人企业客户构建了数据分析系统和软件。他还和 Adam Banker 共同编写了 Paws,R 编程语言的 AWS 开发工具包。Adam Banker 是 Smylen 的全堆栈开发人员,对本文也有贡献。
本博文中的内容和意见属于第三方作者,AWS 不对本博文的内容或准确性负责。
精选图片来自 Pixabay。