使用 Amazon Aurora 机器学习集成进行情感分析



低于 1 美元

数据库、机器学习
数据库管理员、开发人员和数据科学家


概述
Amazon Aurora 是一款专为云环境打造的关系型数据库,与 MySQL 和 PostgreSQL 兼容,集传统企业级数据库的高性能和高可用性与开源数据库的简单性和经济性于一身。
Amazon Aurora 机器学习 (ML) 能支持通过熟悉的 SQL 编程语言将基于机器学习的预测功能添加到应用程序中,因此您无需学习单独的工具或具备机器学习经验。它在 Aurora 和 AWS 机器学习服务之间提供简单、优化且安全的集成,无需构建自定义集成或迁移数据。因此,使用 Postgres 或 MySQL 引擎的开发人员就可以使用熟悉的 SQL 技术、语法和接口向应用程序添加功能。
在您运行机器学习查询时,Aurora 会调用 Amazon SageMaker 执行各种机器学习算法,或调用 Amazon Comprehend 进行情感分析,这样您的应用程序就无需直接调用这些服务。因此,Aurora 机器学习适合有低延迟、实时需求的使用场景,例如欺诈检测、广告定位和产品推荐。
在本教程中,您将学习如何创建 Aurora PostgresSQL 数据库,如何实现该数据库与 Amazon Comprehend 的集成,以及如何使用 Comprehend 根据数据库表中的记录进行情感分析。
在本教程中,您将完成以下步骤:
- 创建允许 Amazon Aurora 访问 Amazon Comprehend 和 Amazon S3 所需的 IAM 角色。
- 创建 Amazon Aurora PostgreSQL 数据库实例
- 下载并安装 PostgreSQL 客户端
- 使用 PostgreSQL 客户端连接 Aurora 数据库实例
- 安装 AWS 机器学习和 S3 扩展程序,以查询数据库并分析示例表和客户评论数据集的情感
- 清理本教程中使用的资源
本教程将使用两个数据表:一个表需要您手动填充本教程中的示例数据,而另一个表要加载来自示例客户评论数据集的示例数据。
步骤 1:创建 IAM 角色
在此步骤中,您将创建 AWS Identity and Access Management (IAM) 角色,这些角色让 Amazon Aurora 能访问 Amazon Comprehend 和 Amazon S3。
1.1 — 打开 AWS 管理控制台并使用您的 AWS 账户凭证登录。如果您还没有 AWS 账户,请先注册一个 AWS 账户。
1.2 — 前往 IAM 控制面板。在 IAM 控制面板的导航窗格中,选择 Roles(角色),然后点击 Create Role(创建角色)。
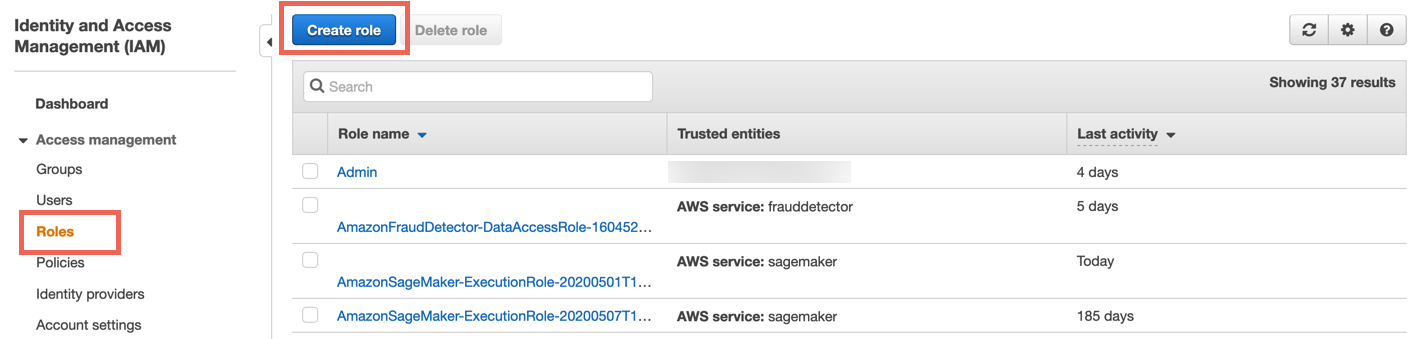
1.3 — 对于 Select type of trusted entity(选择受信任实体类型),选择 AWS service(AWS 服务)。对于 Choose a use case(选择使用场景),选择 RDS。
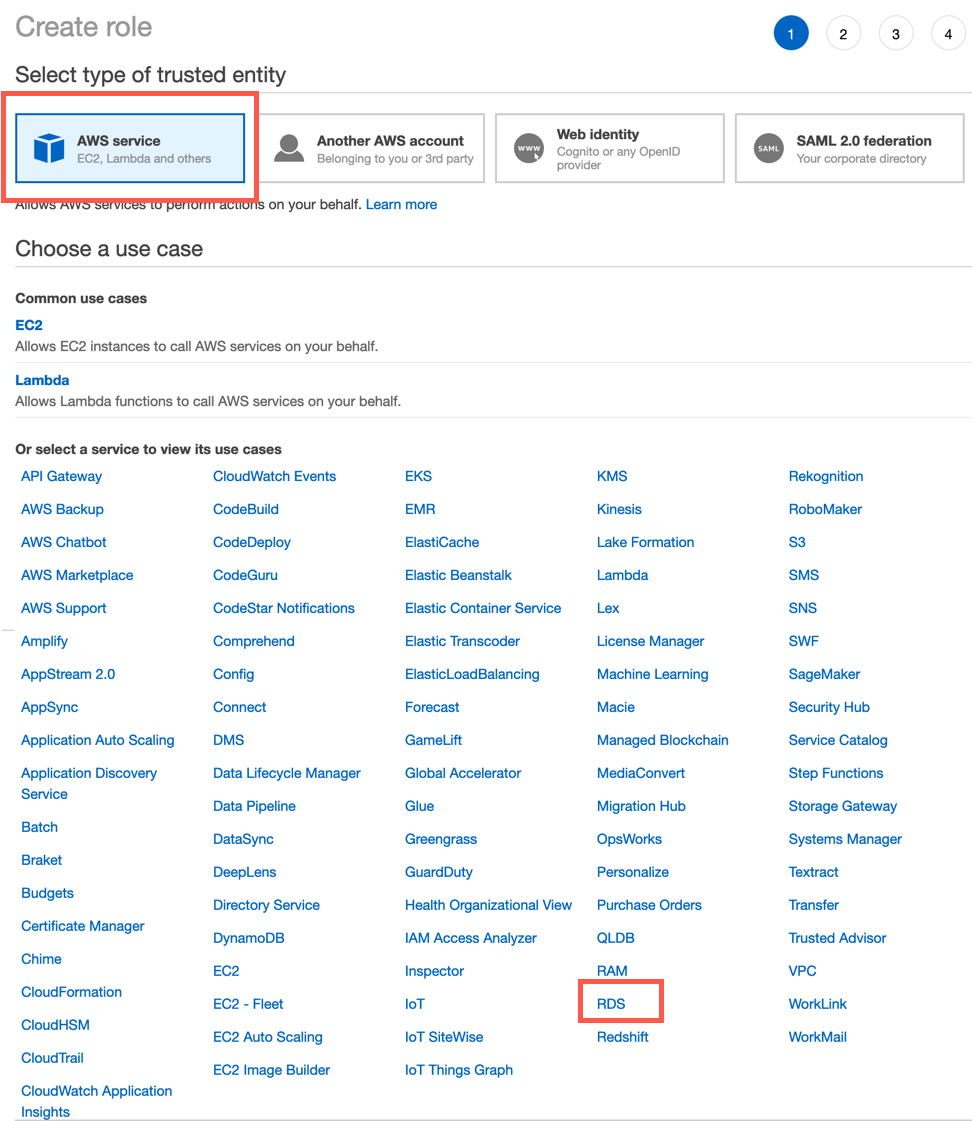
1.4 — 对于 Select your use case(选择使用场景),选择 RDS - Add Role to Database(RDS - 添加角色到数据库),然后点击 Next: Permissions(下一步:权限)。
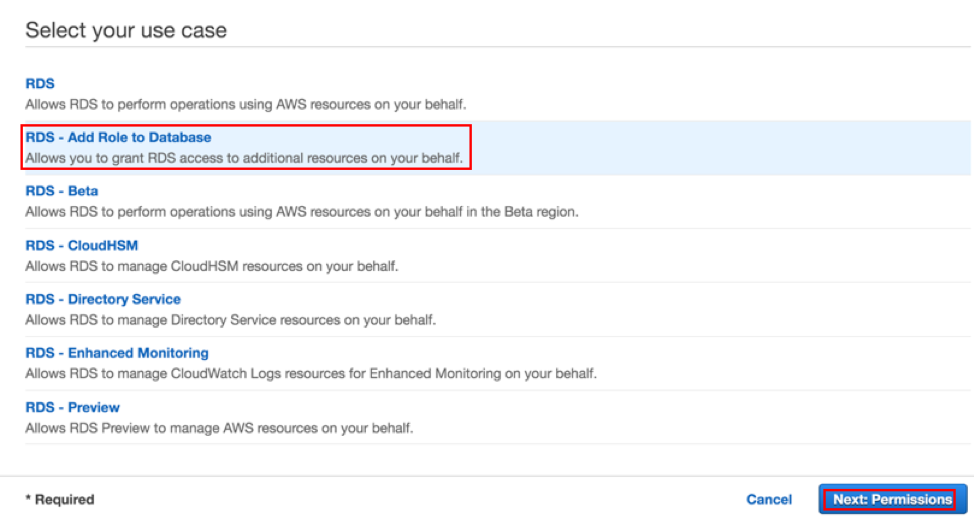
1.5 — 在搜索框中,输入 ComprehendReadOnly。选择 ComprehendReadOnly 策略,然后点击 Next: Tags(下一步:标签)。
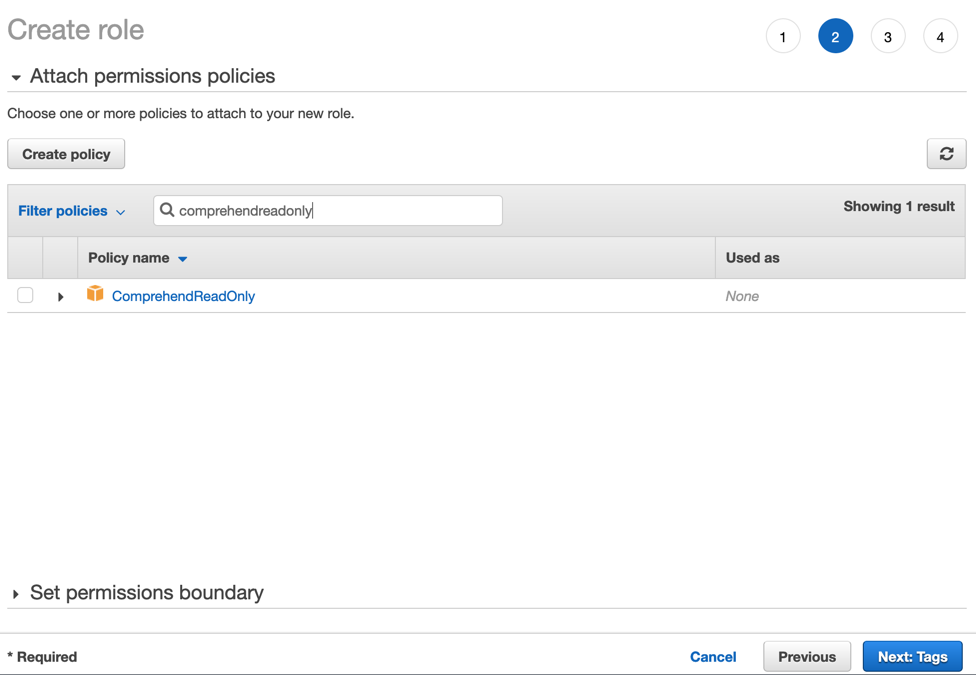
1.6 — 跳过标记部分,点击 Next: Review(下一步:检查)。
1.7 — 在 Review(检查)部分,将角色命名为 TutorialAuroraComprehendRole,然后点击 Create role(创建角色)。
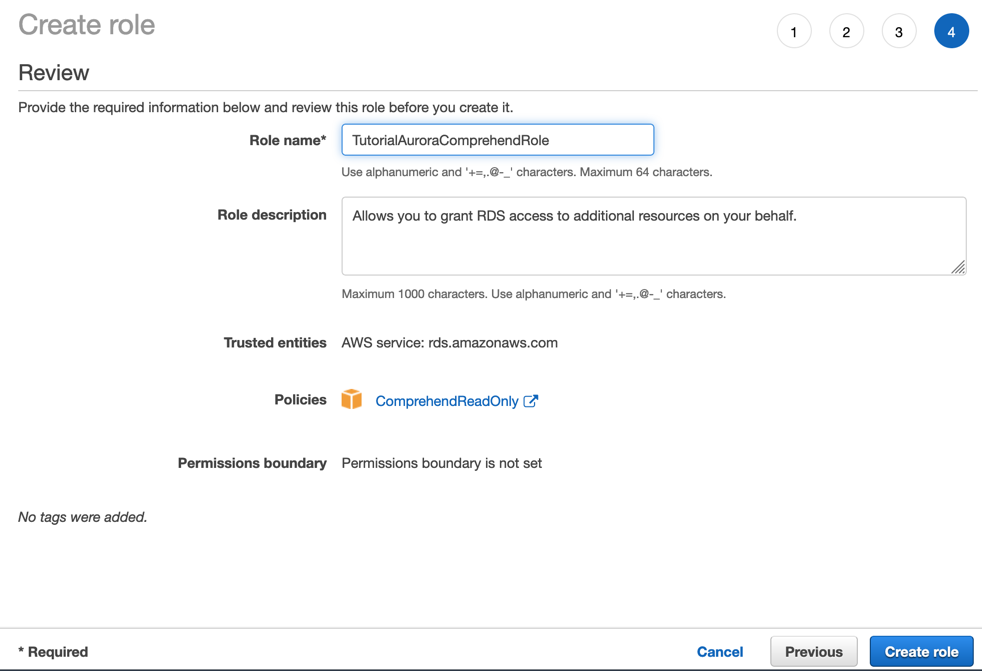
1.8 — 重复步骤 1.2 — 1.7,但更改以下选择以创建另一个用于访问 S3 的角色。
- 对于步骤 1.5,在 Attach permissions policies(附加权限策略)页面上,搜索并选择 AmazonS3ReadOnlyAccess。
- 对于步骤 1.7,在 Review(检查)页面上,将角色命名为 TutorialAuroraS3Role。

1.9 — 确认角色已创建。

步骤 2:创建 Aurora 数据库实例
在此步骤中,您将创建一个 Amazon Aurora PostgreSQL 数据库实例,并附加您在步骤 1 中创建的角色。
2.1 — 打开 Amazon RDS 控制台,在左侧导航窗格中,选择 Databases(数据库),然后点击 Create database(创建数据库)。

2.2 — 对于 Choose a database creation method(选择数据库创建方式),选择 Standard Create(标准创建)。

2.3 — 对于 Engine options(引擎选项),进行以下选择:
- Engine type(引擎类型):Amazon Aurora
- Edition(版本):Amazon Aurora with PostgreSQL compatibility(兼容 PostgreSQL 的 Amazon Aurora)
- Capacity type(容量类型):Provisioned(预配)
- Version(版本):Aurora PostgreSQL(与 PostgreSQL 11.7 兼容)

2.4 — 对于 Templates(模板),选择 Dev/Test(开发/测试)。

2.5 — 在 Settings(设置)部分,将数据库命名为 aurora-ml-db。对于 Credential Settings(凭证设置),保留默认用户名并为数据库实例创建密码。

2.6 — 对于 DB instance size(数据库实例大小),选择 Burstable classes (includes t classes)(可突增类(包括 t 类)),然后选择 db.t3.medium 实例类型。

2.7 — 在 Availability & durability(可用性与持久性)下,对于 Multi-AZ deployment(多可用区部署),选择 Don't create an Aurora Replica(不创建 Aurora 副本)。

2.8 — 对于 Connectivity(连接),选择 Create a new VPC(创建新的 VPC)。然后,展开 Additional connectivity configuration(其他连接配置)部分:
- 对于 Subnet group(子网组),选择 Create new DB Subnet Group(创建新的数据库子网组)。
- 对于 Public access(公共访问),选择 Yes(是)。
- 对于 VPC security group(VPC 安全组),选择 Create new(新建),并将安全组命名为 TutorialVPCSecurityGroup。

2.9 — 对于 Database authentication(数据库身份验证),选择 Password authentication(密码身份验证)。然后,点击 Create database(创建数据库)。

Aurora 数据库启动,状态为 Creating(正在创建)。几分钟后,Aurora 数据库实例创建完成,状态变为 Available(可用)。

2.10 — 当实例状态显示为 Available(可用)时,选择 aurora-ml-db 实例以查看详细信息。选择 Connectivity & security(连接与安全)选项卡,在 Manage IAM roles(管理 IAM 角色)部分,对于 Add IAM roles to this cluster(将 IAM 角色添加到此集群),选择 TutorialAuroraComprehendRole。对于 Feature(功能),选择 Comprehend,然后点击 Add role(添加角色)。

2.11 — 当 TutorialAuroraComprehendRole 的状态显示为 Active(活跃)时,在 Manage IAM roles(管理 IAM 角色)部分,对于 Add IAM roles to this cluster(将 IAM 角色添加到此集群),选择 TutorialAuroraS3Role。对于 Feature(功能),选择 S3Import,然后点击 Add role(添加角色)。

2.12 — 确认两个角色都已添加到集群并处于活动状态。

2.13 — 选择 aurora-ml-db 写入器实例以查看详细信息。选择 Connectivity & security(连接与安全)选项卡,并记下实例端点。
此值是您的 Aurora PostgreSQL 数据库实例的 DNS 名称。在步骤 4 中,您需要此值来连接数据库。

步骤 3:下载并安装 PostgreSQL 客户端
在此步骤中,您将下载并安装 PostgreSQL 客户端,用于连接您的 Aurora PostgreSQL 数据库实例。
您可以根据偏好,选择任意 PostgreSQL 数据库客户端连接 Aurora PostgreSQL 数据库实例。本教程使用 pgAdmin 客户端,但您也可以使用 SQL Workbench 或任何其他首选客户端。
- 对于 pgAdmin,请从 pgAdmin 网站下载并安装 pgAdmin 4 客户端。
- 对于 SQL Workbench,请参阅创建并连接 PostgreSQL 数据库中的相关说明。
注意:您必须在创建 Aurora PostgreSQL 数据库实例的同一设备和网络上运行 PostgreSQL 客户端。在本教程中,数据库安全组被配置为仅允许从创建数据库实例时使用的设备进行连接。您的数据库可以配置为从任何 IP 地址访问,但为了简单起见,本教程保持配置简单。
下载并安装您选择的客户端后,请继续步骤 4。
步骤 4:连接 Aurora 数据库实例
在此步骤中,您将使用 pgAdmin 4 PostgreSQL 客户端连接 Aurora PostgreSQL 数据库实例。有关其他连接选项,请参阅连接运行 PostgreSQL 数据库引擎的数据库实例。
4.1 — 启动 pgAdmin PostgreSQL 客户端应用程序,然后点击 Add New Server(添加新服务器)。

4.2 – 在 Create - Server(创建 - 服务器)对话框中,对于 Name(名称),输入 TutorialServer。

4.3 – 选择 Connection(连接)选项卡,然后输入以下信息:
- 对于 Host name/address(主机名/地址),粘贴您在步骤 2.13 中复制的数据库集群端点。
- 对于 Password(密码),输入创建数据库实例时指定的密码。
点击 Save(保存)。在左侧窗格的导航树中,您应该能看到新服务器 TutorialServer。

4.4 – 展开 TutorialServer 导航树,打开 postgres 数据库节点的上下文菜单,然后选择 Query Tool(查询工具)以打开查询窗口。现在,您可以对数据库实例运行查询了。

步骤 5:使用 Amazon Comprehend 查询数据库
在此步骤中,您将安装用于机器学习和访问 Amazon S3 的扩展程序。然后,您将设置并查询示例表。最后,您将从客户评论数据集加载示例数据,并对客户评论运行查询,以进行情感分析并获得置信度。
5.1 — 在查询编辑器中,运行以下语句以安装用于模型推理的 Amazon 机器学习服务扩展程序。
CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;现在,您可以创建表、添加一些数据并尝试使用 Comprehend。您的示例表将包含来自宣布机器学习集成功能的文章的评论,包含 ID 和评论文本列。
5.2 — 运行以下语句以创建名为 comments 的示例表。
CREATE TABLE IF NOT EXISTS comments (
comment_id serial PRIMARY KEY,
comment_text VARCHAR(255) NOT NULL
);5.3 — 使用以下语句将数据添加到 comments 表中。
INSERT INTO comments (comment_text)
VALUES ('This is very useful, thank you for writing it!');
INSERT INTO comments (comment_text)
VALUES ('Awesome, I was waiting for this feature.');
INSERT INTO comments (comment_text)
VALUES ('An interesting write up, please add more details.');
INSERT INTO comments (comment_text)
VALUES ('I do not like how this was implemented.');5.4. – 运行以下语句以调用 aws_comprehend.detect sentiment 函数。
SELECT * FROM comments, aws_comprehend.detect_sentiment(comments.comment_text, 'en') as s此语句向 Comprehend 传递两个参数:需要评估的列以及该列中文本的语言代码(本例中为代表英语的 en)。此语句返回两个附加列:
- sentiment(情感),将情感分为 POSITIVE(正面)、NEGATIVE(负面)、NEUTRAL(中立)或 MIXED(混合)
- confidence(置信度),提供 Comprehend 模型情感分析的置信度,范围从 0 到 1

太棒了!您在示例表上运行了 Comprehend 情感分析。在以下步骤中,您将使用从公开可读的 S3 存储桶中获取的客户评论数据示例。
5.5 — 运行以下语句以安装 Amazon S3 服务扩展程序。通过此扩展程序,您可以使用 SQL 将来自 Amazon S3 的数据加载到 Aurora 数据库实例中。
CREATE EXTENSION IF NOT EXISTS aws_s3 CASCADE;接下来,您可以创建一个表来保存 S3 上数据集中的数据。数据以制表符分隔值 (TSV) 格式存储在公开可读的 S3 存储桶中。
5.6 — 复制并粘贴以下代码以创建名为 review_simple 的表。
create table review_simple
(
marketplace char(2),
customer_id varchar(20),
review_id varchar(20) primary key,
product_id varchar(20),
product_parent varchar(20),
product_title text,
product_category varchar(20),
star_rating int,
helpful_votes int,
total_votes int,
vine char,
verified_purchase char,
review_headline varchar(255),
review_body text,
review_date date,
scored_sentiment varchar(20),
scored_confidence float4
)在创建表时,您将在表中纳入与客户评论数据集中的输入数据模式匹配的列,并添加两个与情感相关的增量列:scored_sentiment 和 scored_confidence。您将在步骤 5.8 中使用这些列来存储调用 Comprehend 的结果。
5.7 — 运行以下语句以直接从 Aurora PostgreSQL 加载数据。
注意:在生产环境中,您可以选择使用 AWS Glue 或其他 ETL 流程来加载数据。
select aws_s3.table_import_from_s3(
'review_simple', 'marketplace, customer_id,review_id,product_id,
product_parent, product_title, product_category, star_rating,
helpful_votes, total_votes, vine, verified_purchase,review_headline,
review_body, review_date',
'(FORMAT CSV, HEADER true, DELIMITER E''\t'', QUOTE ''|'')',
'amazon-reviews-pds',
'tsv/sample_us.tsv',
'us-east-1'
)此语句指定了要加载的列集、文件格式,并提供了存储桶名称、键和 AWS 区域。此示例文件有 49 行数据加一个标题行。
5.8 — 加载数据时,表中的 scored_sentiment 和 scored_confidence 列被忽略;从 S3 加载的数据集不包含这些列。现在,您将使用 Comprehend 评估情感,并使用结果更新表中的这些列。运行以下语句以调用 Comprehend 并更新表。
update review_simple
set scored_sentiment = s.sentiment, scored_confidence = s.confidence
from review_simple as src,
aws_comprehend.detect_sentiment( src.review_body, 'en') as s
where src.review_id = review_simple.review_id
and src.scored_sentiment is null该语句会为尚未获取情感值的各行调用 Comprehend,并更新 scored_sentiment 和 scored_confidence 列。
这种方法有助于优化后续使用情感值的报告或查询在成本和性能方面的表现。如果评论文本没有变化,那么您就无需每次要使用情感值时都调用 Comprehend。您可以直接将数据存储起来,并在需要时从数据库中检索即可。在将新行加载到表中时,您可以使用此类语句来设置情感,而无需对现有行重新推理。
考虑到调用 Comprehend 的成本和时间消耗,我们应该尽量避免重复提交批次,从而减少不必要的开销。此外,如果将情感值存储在数据库的列中,在您需要优化查询以支持查询更大的数据集时,您还能为情感值创建索引。
接下来,尝试对数据运行一些查询。
5.9 — 运行以下语句以查看返回的数据。
select customer_id, review_id, review_body, scored_sentiment, scored_confidence from review_simple
5.10 — 运行以下语句,根据 Comprehend 返回的情感查看汇总的数据。
select scored_sentiment,count(*) as nReviews from review_simple group by scored_sentiment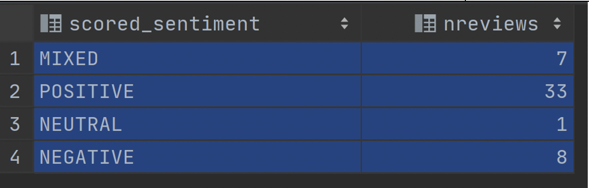
5.11 — 运行以下语句,根据置信度阈值 > .9 查询数据。
select scored_sentiment,count(*) as nReviews from review_simple where scored_confidence > .9
group by scored_sentiment 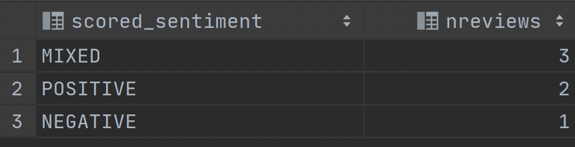
在此查询中,您正在利用保存在表中的情感分数和置信度值。此示例说明了将情感值直接保存在数据库中能提高灵活性和性能。直接在数据库中执行此操作可以让更熟悉 SQL 的人更轻松地访问数据。
步骤 6:清理资源
在接下来的步骤中,您将清理在本教程中创建的资源。
删除不再使用的实例和资源是一种最佳实践,以免持续产生不必要的费用。
删除 Aurora 数据库
6.1 — 导航到 RDS 控制台,在左侧窗格中,选择 Databases(数据库)。
6.2 — 选择教程 aurora-ml-db 实例。注意:在 Connectivity & security(连接和安全)部分,在 Networking(网络)下,复制 VPC 的值。您可以在下一步中删除此资源。
6.3 — 选择 Actions(操作),然后点击 Delete(删除)。
6.4 — 取消选中 Create final snapshot(创建最终快照)复选框,然后选中 I acknowledge(我确认)复选框。输入 delete me,然后点击 Delete(删除)。
删除 VPC
6.5 — 导航到 VPC 控制台。
6.6 — 在左侧导航窗格中,选择 Your VPCs(您的 VPC),然后选择与您在步骤 6.2 中记下的 ID 匹配的 VPC。
6.7 — 选择 Actions(操作),然后点击 Delete VPC(删除 VPC)。
6.8 — 在确认框中,输入 delete,点击 Delete(删除)。
删除 IAM 角色
6.9 — 导航到 IAM 控制台,在导航窗格中,点击 Roles(角色)。
6.10 — 搜索 Tutorial,然后选中您为本教程创建的角色旁边的复选框:TutorialAuroraComprehendRole 和 TutorialAuroraS3Role。
6.11 — 在页面顶部,点击 Delete role(删除角色)。
6.12 — 在确认对话框中,选择 Yes, Delete(是,删除)。
删除其他资源
您可以选择删除在本教程中下载的 PostgreSQL 数据库客户端。
恭喜您
您已经创建了 Aurora PostgreSQL 数据库,实现了该数据库与 Amazon Comprehend 的集成,并且使用 Comprehend 根据数据库中的记录进行了情感分析。
推荐的后续步骤
了解有关 Amazon Aurora 机器学习功能的更多信息
了解有关 Amazon Aurora 机器学习功能的更多信息。
阅读有关更多 Amazon Aurora 机器学习应用程序的信息
在 AWS 机器学习博客上了解有关更多 Amazon Aurora 机器学习应用程序的信息。
了解有关 Amazon Aurora 的更多信息
访问 Amazon Aurora 资源以获取入门提示和更多信息。

