Artificial Intelligence
Analyzing and tagging assets stored in Veeva Vault PromoMats using Amazon AI services
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Veeva Systems is a provider of cloud-based software for the global life sciences industry, which offers products that serve multiple domains ranging from clinical, regulatory, quality, and more. Veeva’s Vault Platform manages both content and data in a single platform that allows you to deploy powerful applications that manage the end-to-end process with content, data, and workflows. The Vault Platform offers an open architecture and comprehensive API that allows customization with rapid configuration and modifications of business applications, and seamless integration with other systems to extend Veeva Vault capabilities, migrate data, or automate processing.
One such product in the commercial space is Veeva Vault PromoMats. More than 400 life sciences companies across over 165 countries rely on Veeva Vault PromoMats for commercial content and digital asset management.
Veeva Vault PromoMats combines digital asset management with review and distribution capabilities, providing easy review and approval, plus automated content distribution and withdrawal across channels, which gives you complete visibility and control of all your digital assets and materials. Veeva Vault PromoMats provides you with a single source of truth for compliant content that local product managers can access, search, and find what they need quickly.
A typical digital marketing team uses Veeva Vault PromoMats to store, search, curate, review, and distribute marketing assets across their global workforce. These assets could be anything from emails, webpages, images, videos, and audio files. To promote reuse, marketing teams typically use a globally dispersed human team to analyze and tag these assets to make them easily searchable. This current process is susceptible to incorrect, inconsistent, and inefficient tagging, which results in human teams spending valuable cycles to locate a given asset. Organizations typically deploy an army of reviewers to keep the content accurate and easily searchable, which not only increases the cost but also forces teams to focus on undifferentiated heavy lifting, which diminishes the value add that your talented human workforce is capable of.
Working backward from the customer, automating these manual processes requires a solution that can:
- Identify content types (such as emails, texts, images, and media files)
- Differentiate content and automate taxonomy values corresponding to the identified content type
- Enable asset tagging automation and provide a solution to search these assets easily
- Continuously enrich, such as with machine learning (ML) values for tagging
This post demonstrates how you can use Amazon AI services to quickly, reliably, and cost-efficiently analyze the rich content stored in Veeva Vault at scale. The post discusses the overall architecture, the steps to deploy a solution and dashboard, and a use case of asset metadata tagging. For more information about the proof of concept code base for this use case, see the GitHub repo.
Overview of solution
The following diagram illustrates the solution architecture.
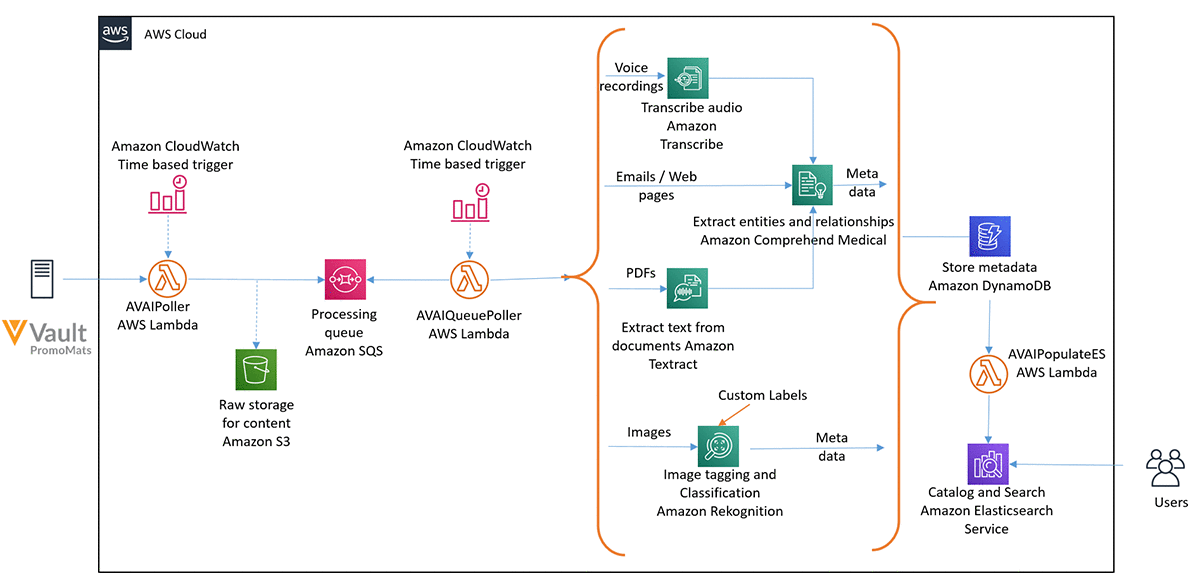
Using the Veeva Vault APIs and the AVAIPoller AWS Lambda function, you set up an inward data flow for Veeva PromoMats, which allows you to get updates on Amazon Simple Storage Service (Amazon S3). These updates could be periodic, event-driven, or batched, depending on your need. The AVAIPoller function handles Veeva authentication and uses an Amazon CloudWatch time-based trigger (every 5 minutes) to periodically call Veeva Vault APIs to ingest data. You can change this frequency by modifying the AWS CloudFormation template provided in this post.
The AVAIPoller function begins by getting all the data for the first run. After that, it just gets the Veeva Vault assets that have been created or modified since the last run.
The function stores the incoming assets on Amazon S3 and inserts a message into an Amazon Simple Queue Service (Amazon SQS) queue. Using Amazon SQS provides a loose coupling between the producer and processor sections of the architecture and also allows you to deploy changes to the processor section without stopping the incoming updates.
A second poller function (AVAIQueuePoller) reads the SQS queue at frequent intervals (every minute) and processes the incoming assets. Depending on the incoming message type, the solution uses various AWS AI services to derive insights from your data. Some examples include:
- Text files – The function uses the DetectEntities operation of Amazon Comprehend Medical, a natural language processing (NLP) service that makes it easy to use ML to extract relevant medical information from unstructured text. This operation detects entities in categories like A
natomy,Medical_Condition,Medication,Protected_Health_Information, andTest_Treatment_Procedure. The resulting output is filtered forProtected_Health_Information, and the remaining information, along with confidence scores, is flattened and inserted into an Amazon DynamoDB This information is plotted on the Elasticsearch Kibana cluster. In real-world applications, you can also use the Amazon Comprehend Medical ICD-10-CM or RxNorm feature to link the detected information to medical ontologies so downstream healthcare applications can use it for further analysis. - Images – The function uses the DetectLabels method of Amazon Rekognition to detect labels in the incoming image. These labels can act as tags to identify the rich information buried in your images. If labels like Human or Person are detected with a confidence score of more than 80%, the code uses the DetectFaces method to look for key facial features such as eyes, nose, and mouth to detect faces in the input image. Amazon Rekognition delivers all this information with an associated confidence score, which is flattened and stored in the DynamoDB table.
- Voice recordings – For audio assets, the code uses the StartTranscriptionJob asynchronous method of Amazon Transcribe to transcribe the incoming audio to text, passing in a unique identifier as the
TranscriptionJobName. The code assumes the audio language to be English (US), but you can modify it to tie to the information coming from Veeva Vault. The code calls the GetTranscriptionJob method, passing in the same unique identifier as theTranscriptionJobNamein a loop, until the job is complete. Amazon Transcribe delivers the output file on an S3 bucket, which is read by the code and deleted. The code calls the text processing workflow (as discussed earlier) to extract entities from transcribed audio. - Scanned documents (PDFs) – A large percentage of life sciences assets are represented in PDFs—these could be anything from scientific journals and research papers to drug labels. Amazon Textract is a service that automatically extracts text and data from scanned documents. The code uses the StartDocumentTextDetection method to start an asynchronous job to detect text in the document. The code uses the
JobIdreturned in the response to call GetDocumentTextDetection in a loop, until the job is complete. The output JSON structure contains lines and words of detected text, along with confidence scores for each element it identifies, so you can make informed decisions about how to use the results. The code processes the JSON structure to recreate the text blurb and calls the text processing workflow to extract entities from the text.
A DynamoDB table stores all the processed data. The solution uses DynamoDB Streams and AWS Lambda triggers (AVAIPopulateES) to populate data into an Elasticsearch Kibana cluster. The AVAIPopulateES function is fired for every update, insert, and delete operation that happens in the DynamoDB table and inserts one corresponding record in the Elasticsearch index. You can visualize these records using Kibana.
This solution offers a serverless, pay-as-you-go approach to process, tag, and enable comprehensive searches on your digital assets. Additionally, each managed component has high availability built in by automatic deployment across multiple Availability Zones. For Amazon Elasticsearch Service (Amazon ES), you can choose the three-AZ option to provide better availability for your domains.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account with appropriate AWS Identity and Access Management (IAM) permissions to launch the CloudFormation template
- Appropriate access credentials for a Veeva Vault PromoMats domain
- Digital assets in the PromoMats Vault accessible to the preceding credentials
Deploying your solution
You use a CloudFormation stack to deploy the solution. The stack creates all the necessary resources, including:
- An S3 bucket to store the incoming assets.
- An SQS FIFO queue to act as a loose coupling between the producer function (
AVAIPoller) and the poller function (AVAIQueuePoller). - A DynamoDB table to store the output of Amazon AI services.
- An Amazon ES Kibana (ELK) cluster to visualize the analyzed tags.
- Required Lambda functions:
- AVAIPoller – Triggered every 5 minutes. Used for polling the Veeva Vault using the Veeva Query Language, ingesting assets to AWS, and pushing a message to the SQS queue.
- AVAIQueuePoller – Triggered every 1 minute. Used for polling the SQS queue, processing the assets using Amazon AI services, and populating the DynamoDB table.
- AVAIPopulateES – Triggered when there is an update, insert, or delete on the DynamoDB table. Used for capturing changes from DynamoDB and populating the ELK cluster.
- The Amazon CloudWatch Events rules that trigger
AVAIPollerandAVAIQueuePoller. These triggers are in the DISABLED state for now. - Required IAM roles and policies for interacting AI services in a scoped-down manner.
To get started, complete the following steps:
- Sign in to the AWS Management Console with your IAM user name and password.
- Choose Launch Stack and open it on a new tab:

- On the Create stack page, choose Next.

- On the Specify stack details page, provide a name for the stack.
- Enter values for the parameters.
- Choose Next.

- On the Configure stack options page, leave everything as the default and choose Next.

- On the Review page, in the Capabilities and transforms section, select the three check boxes.
- Choose Create stack.

- Wait for the stack to complete executing. You can examine various events from the stack creation process on the Events
- After the stack creation is complete, you can look on the Resources tab to see all the resources the CloudFormation template created.
- On the Outputs tab, copy the value of
ESDomainAccessPrincipal.
This is the ARN of the IAM role that the AVAIPopulateES function assumes. You use it later to configure access to the Amazon ES domain.
Setting up Amazon ES and Kibana
This section walks you through securing your Elasticsearch cluster and installing a local proxy to access Kibana securely.
- On the Amazon ES console, select the domain that you created for this example.
- Under Actions, Choose Modify access policy.

- For Domain access policy, choose Custom access policy.

- In the Access policy will be cleared pop-up window, choose Clear and continue.

- On the next page, configure these statements to lock down access to the Amazon ES domain:
- Allow IPv4 address – Your IP address.
- Allow IAM ARN – Value of
ESDomainAccessPrincipalyou copied earlier.

- Choose Submit.This creates an access policy that grants access to the
AVAIPopulateESfunction and Kibana access from your IP address. For more information about scoping down your access policy, see Configuring Access Policies. - Wait for the domain status to show as
Active. - On the CloudWatch console, under Events, choose Rules.
You can see two disabled rules that the CloudFormation template created.
- Select each rule and enable them by choosing Enable from the Actions menu.

In 5–8 minutes, the data should start flowing in and entities are created in the Elasticsearch cluster. You can now visualize these entities in Kibana. To do this, you use an open-source proxy called aws-es-kibana. To install the proxy on your computer, enter the following code:
You can find the domain endpoint on the Outputs tab of the CloudFormation stack under ESDomainEndPoint. You should see the following output:

Creating visualizations and analyzing tagged content
In this step, you set up the indexes and create your visualizations. As the assets are processed by the AI services, their output is collected in a DynamoDB table. Each row in the table corresponds to one document in the index and is used to create the Kibana visualizations. This post provides some reusable assets in the file ESConfig.zip.
For example, you use the asset AVAI_ES_Entity_Dashboard.ndjson to create sample visualizations on Kibana. To get you started, this post provides a pre-built dashboard for you, which uses various visualizations to present different dimensions of the mined data in an easy-to-read format.
You can create a folder on your computer and download the .zip file into it. To configure the Elasticsearch cluster and Kibana, unzip the file and complete the following steps:
- To open the Kibana dashboard, copy the URL for Kibana and paste it in your browser window.
- On the Management Console, choose Index patterns.
- Choose Create index pattern.
- In the Index pattern text box, enter
avai_index. - Choose Next step.

- For Time Filter field name, choose TimeStamp.
- Choose Create index pattern.

You can see the field and attribute names in Kibana, on which you build some visualizations.
- On the Management Console, choose Saved Objects.

- Choose Import and navigate to the
AVAI_ES_Entity_Dashboard.ndjsonfile under the artifacts you downloaded and extracted earlier. - Choose Import.

A message window appears that says some index patterns don’t exist. - From the drop-down menu of new index patterns, choose avai-index.
- Choose Confirm all changes.

This ties up the imported visualizations with the newly created index. You should see a new dashboard called AVAI_Dashboard. - Choose Dashboard and choose AVAI_Dashboard.
- In a different browser window, log in to the Veeva domain and populate it with some sample data (such as images, PDFs, or audio files).
You should see the dashboard with visualizations generated from the extracted entities. The following visualization is a term cloud that tells you the most common terms extracted from the assets.

There are other visualizations that show you metrics like total assets analyzed, total tags analyzed, total assets with human faces, and average confidence scores. The following screenshot shows the following visualizations:
- Average confidence score by operation type
- Count of operations
- Total assets of human faces
- Distribution of asset types
- The tags trend over a date histogram, broken up by types of detected tags

The following visualization shows the facial attributes trend, broken up by facial emotion types.
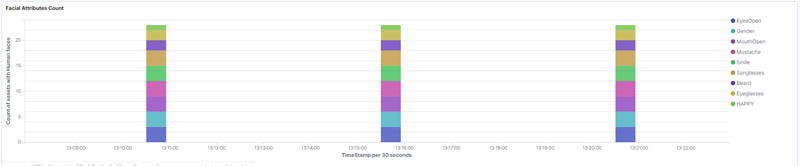
You can experiment with different visualizations and options to build your own visual dashboards.
Cleaning up
To avoid incurring future charges, delete the resources when not in use.
Conclusion
This post demonstrated how to use Amazon AI services to extend the functionality of Veeva Vault PromoMats (or any other Veeva Vault offerings) and extract valuable information quickly and easily. Although no ML output is perfect, it can come very close to human behavior and help offset a substantial portion of your team’s efforts. You can use this additional capacity towards value-added tasks, while dedicating a small capacity to check the output of the ML solution. This solution can also help to optimize costs, achieve tagging consistency, and enable quick discovery of existing assets.
Finally, you can maintain ownership of your data and choose which AWS services can process, store, and host the content. AWS doesn’t access or use your content for any purpose without your consent, and never uses customer data to derive information for marketing or advertising. For more information, see Data Privacy FAQ.
You can also extend the functionality of this solution further with additional enhancements. For example, in addition to the AI/ML services in this post, you can easily add any of your custom ML models built using Amazon SageMaker to the architecture. You can also build a loop back mechanism to update the tags back to Veeva Vault and enable auto-tagging of your assets. This makes it easier for your team to find and locate assets quickly.
Veeva Systems has reviewed and approved this content. For additional Veeva Vault-related questions, please contact Jade Bezuidenhout (Senior Product Manager, Product Alliances, Veeva Systems) at jade.bezuidenhout@veeva.com.
About the Author
 Mayank Thakkar is a Sr. Solutions Architect in the Global Healthcare and Life Sciences team at AWS, specializing in building serverless, artificial intelligence, and machine learning-based solutions. At AWS, he works closely with global pharma companies to build cutting-edge solutions focused on solving real-world industry problems. Apart from work, Mayank, along with his wife, is busy raising two energetic and mischievous boys, Aaryan (6) and Kiaan (4), while trying to keep the house from burning down or getting flooded!
Mayank Thakkar is a Sr. Solutions Architect in the Global Healthcare and Life Sciences team at AWS, specializing in building serverless, artificial intelligence, and machine learning-based solutions. At AWS, he works closely with global pharma companies to build cutting-edge solutions focused on solving real-world industry problems. Apart from work, Mayank, along with his wife, is busy raising two energetic and mischievous boys, Aaryan (6) and Kiaan (4), while trying to keep the house from burning down or getting flooded!