- Amazon Builders' Library
- Vermeiden von Fallback in verteilten Systemen
Vermeiden von Fallback in verteilten Systemen
ARCHITEKTUR | LEVEL 300
Einführung
Kritische Ausfälle verhindern, dass Services brauchbare Ergebnisse liefern. Wenn z. B. eine Datenbankabfrage für Produktinformationen auf einer E-Commerce-Website fehlschlägt, kann die Produktseite nicht richtig dargestellt werden. Für einen zuverlässigen Betrieb der Amazon-Services müssen kritische Ausfälle zum Großteil bewältigt werden. Strategien zur Bewältigung kritischer Ausfälle können in vier Hauptkategorien gefasst werden:
-
Erneut versuchen: Führen Sie die fehlgeschlagene Aktivität entweder sofort oder nach einer gewissen Verzögerung erneut aus.
-
Proaktive Wiederholung: Führen Sie die Aktivität mehrmals parallel aus und nutzen Sie die erste, um sie abzuschließen.
-
Failover: Führen Sie die Aktivität erneut für eine andere Kopie des Endpunkts aus, oder führen Sie vorzugsweise mehrere parallele Kopien der Aktivität durch, um die Wahrscheinlichkeit zu erhöhen, dass mindestens eine davon erfolgreich ist.
-
Fallback: Verwenden Sie einen anderen Mechanismus, um dasselbe Ergebnis zu erzielen.
In diesem Artikel zum Thema Fallback-Strategien wird erklärt, warum diese bei Amazon fast keine Anwendung finden. Diese Aussage überrascht Sie jetzt möglicherweise. Schließlich ist es nicht ungewöhnlich, dass sich Entwickler beim Entwurf neuer Konzepte an der realen Welt orientieren. Dort sind Fallback-Strategien gang und gäbe – sie werden im Voraus entwickelt und bei Bedarf umgesetzt. Angenommen, an einem Flughafen kommt es zum Ausfall der Anzeigetafeln. Für diese Situation muss ein Notfallplan vorliegen (z. B., dass die Fluginformationen von menschlicher Hand auf Whiteboards geschrieben werden), damit die Fluggäste trotzdem zum richtigen Flugsteig finden. Der beispielhafte Notfallplan ist allerdings mangelhaft: Die Informationen auf den Whiteboards können unleserlich sein, das Aktualisieren ist mühselig und es besteht jederzeit das Risiko, dass falsche Informationen hinzugefügt werden. Die Fallback-Strategie "Whiteboard" ist zwar erforderlich, weist aber eine Reihe von Problemen auf.
Im Kontext verteilter Systeme gehört die Entwicklung von Fallback-Strategien zu den größten Herausforderungen, insbesondere bei zeitkritischen Services. Dabei kommt erschwerend hinzu, dass es mitunter Jahre dauern kann, bis sich die Folgen schlechter Strategien bemerkbar machen. Außerdem kann der Unterschied zwischen einer guten und einer schlechten Strategie geringfügig sein. In diesem Artikel möchten wir beleuchten, wie es dazu kommt, dass Fallback-Strategien mehr Probleme aufwerfen, als sie lösen. Dies veranschaulichen wir unter anderem an Beispielen bei Amazon, in denen Fallback-Strategien zu Problemen geführt haben. Abschließend beschreiben wir Fallback-Alternativen, die bei Amazon zum Einsatz kommen.
Die Analyse von Fallback-Strategien für Services ist keine intuitive Angelegenheit und es ist schwer abzusehen, welche Konsequenzen in verteilten Systemen auftreten können. Deshalb möchten wir mit Fallback-Strategien für Anwendungen beginnen, die auf einzelnen Computern ausgeführt werden.
Ein-Computer-Fallback
Das folgende C-Code-Snippet veranschaulicht einen Ansatz, mit dem in vielen Anwendungen Fehler bei der Speicherzuordnung bewältigt werden. Bei diesem Code erfolgt die Speicherzuordnung über die Funktion malloc(). Dann wird ein Bildpuffer in den Speicher geladen, während eine Art Umwandlung durchgeführt wird:
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}Fallback für einen einzelnen Computer, (Fortsetzung)
Die Wiederherstellung des Codes nach einem Ausfall der Funktion ist weniger elegant. In der Praxis schlagen malloc-Aufrufe selten fehl, weshalb Entwickler diese Ausfälle im Code oft ignorieren. Warum ist diese Strategie so verbreitet? Wenn malloc auf einem einzelnen Computer fehlschlägt, liegt das in der Regel daran, dass auf dem Computer nicht genügend Arbeitsspeicher vorhanden ist. Das wiederum bedeutet, dass der Computer jeden Moment abstürzen können – ein fehlgeschlagener malloc-Aufruf ist in dem Fall das kleinere Problem. Bei einem einzelnen Computer ist an dieser Argumentation meistens auch nichts auszusetzen. Viele Anwendungen sind nicht wichtig genug, um die aufwendige Lösung eines derart heiklen Problems zu rechtfertigen. Angenommen, Sie möchten den Fehler trotzdem unbedingt beheben. In dieser Situation ist es nicht leicht, etwas Nützliches zu tun. Wir implementieren eine zweite Methode namens malloc2, bei der die Speicherzuordnung auf andere Weise erfolgt, und rufen diese Funktion auf, wenn die malloc-Standardimplementierung fehlschlägt:
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}Fallback für einen einzelnen Computer, (Fortsetzung)
Auf den ersten Blick sieht der Code in Ordnung aus. Er weist jedoch offensichtliche und nicht so offensichtliche Mängel auf. Zunächst ist die Fallback-Logik schwer zu testen. Wir könnten den Aufruf an malloc abfangen und einen Fehler einschleusen. Das würde jedoch unter Umständen nicht die realen Abläufe in der Produktionsumgebung widerspiegeln. Wenn malloc in der Produktion ausfällt, steht auf dem Computer wahrscheinlich nicht genügend Arbeitsspeicher zur Verfügung. Allgemeine Speicherprobleme dieser Art lassen sich nur schwer simulieren. Selbst wenn Sie eine Umgebung mit unzureichendem Speicher schaffen könnten, in der Sie den Test ausführen (z. B. in einem Docker-Container), müssten Sie dafür sorgen, dass der nötige Speicherzustand mit der Ausführung des Fallback-Codes von malloc2 zusammenfällt.
Ein weiteres Problem ist, dass der Fallback selbst fehlschlagen könnte. Da der bisherige Fallback-Code malloc2-Fehler nicht verarbeiten kann, bietet das Programm nicht den Nutzen, den Sie vielleicht erwartet hätten. Die Fallback-Strategie reduziert unter Umständen die Wahrscheinlichkeit eines Totalausfalls – möglich bleibt er trotzdem noch. Bei Amazon haben wir die Erfahrung gemacht, dass sich unsere Erfolgschancen erhöhen, wenn wir Entwickler speziell darauf ansetzen, den primären Code (im Gegensatz zum Fallback-Code) zuverlässiger zu machen, statt in die Entwicklung einer Fallback-Strategie zu investieren, die letztendlich nur selten zum Einsatz kommt.
Wenn Verfügbarkeit unsere höchste Priorität hat, ist die Fallback-Strategie außerdem das Risiko möglicherweise nicht wert. Warum sollten wir uns mit malloc aufhalten, wenn malloc2 größere Erfolgschancen verspricht? Logisch betrachtet muss die hohe Verfügbarkeit von malloc2 bedeuten, dass die Funktion in einem anderen Aspekt Abstriche macht. Vielleicht ordnet Sie den Arbeitsspeicher über einen größeren SSD-basierten Speicher zu, der eine höhere Latenz aufweist. Das wirft allerdings die Frage auf, wieso dieser Abstrich bei malloc2 möglich ist. Folgender Ereignisverlauf soll veranschaulichen, was bei Verwendung dieser Fallback-Strategie passieren könnte. Zuerst nutzt der Kunde die Anwendung. Plötzlich fällt malloc aus, malloc2 wird aktiviert und die Anwendungsleistung nimmt ab. Das ist schlecht: Soll die Leistung abnehmen? Damit gehen die Probleme aber erst los. Wie bereits erwähnt, ist auf dem Computer wahrscheinlich kein (oder nur sehr wenig) Arbeitsspeicher verfügbar. Jetzt hat der Kunde nicht nur ein, sondern schon zwei Probleme: eine langsame Anwendung und ein langsamer Computer. Der Wechsel zu malloc2 kann die Gesamtproblematik unter Umständen sogar verschlimmern. Es könnte zum Beispiel sein, dass andere Teilsysteme auf denselben SSD-basierten Speicher zugreifen.
Die Fallback-Logik kann das System auch unvorhersehbar belasten. Beispiel: Eine einfache alltägliche Logik wie das Schreiben einer Fehlermeldung in ein Protokoll mithilfe eines Stack-Trace ist in der Regel harmlos. Eine plötzliche Änderung kann jedoch bewirken, dass der Fehler mit einer höheren Frequenz ausgelöst wird und sich eine CPU-abhängige Anwendung auf einmal in eine E/A-abhängige Anwendung verwandelt. Wenn der Datenträger nicht in der Lage ist, Schreibvorgänge mit einer so hohen Frequenz zu verarbeiten oder die Menge der auf einmal vorliegenden Daten zu speichern, kann die Leistung des Speichers einbrechen oder er verursacht einen Absturz der Anwendung.
Die Fallback-Strategie könnte das Problem nicht nur verschlimmern, sondern dies wird wahrscheinlich auch als latenter Bug auftreten. Es ist einfach, Strategien für Fallbacks zu entwickeln, die in der Produktion nur selten ausgelöst werden. Bis einem kundenseitigen Computer zum richtigen Zeitpunkt der Arbeitsspeicher ausgeht, damit der spezifische Code mit dem Fallback auf malloc2 zum Tragen kommt (wie zuvor gezeigt), können Jahre vergehen. Wenn dann in der Fallback-Logik ein Fehler vorliegt oder das Gesamtproblem durch einen Nebeneffekt verschlimmert wird, haben die zuständigen Entwickler die genaue Funktionsweise des Codes wahrscheinlich schon vergessen, was die Behebung des Codefehlers erschwert. Bei einer Anwendung, die auf einem einzigen Computer ausgeführt wird, mag diese Vorgehensweise aus ökonomischer Sicht vertretbar sein. In verteilten Systemen sind die Konsequenzen jedoch enorm, wie wir später noch genauer ausführen.
Für keins dieser Probleme gibt es eine einfache Lösung. Unserer Erfahrung nach können sie in Anwendungen auf Einzelcomputern aber bedenkenlos ignoriert werden. Die am häufigsten angewendete Lösung haben wir bereits angeschnitten: Lassen Sie einfach zu, dass der Speicherzuordnungsfehler die Anwendung zum Absturz bringt. Der für die Speicherzuordnung zuständige Code teilt das Schicksal des Computers, der in diesem Fall aller Wahrscheinlichkeit nach ausfällt. Selbst wenn Code und Computer nicht ausfallen, befindet sich die Anwendung mittlerweile in einem unvorhergesehenen Zustand – an diesem Punkt ist ein schneller Ausfall keine schlechte Strategie. Ökonomisch gesehen ist es ein akzeptabler Kompromiss.
Bei kritischen Ein-Computer-Anwendungen, die im Fall eines Fehlers bei der Speicherzuordnung funktionsfähig bleiben müssen, können Sie das Problem lösen, indem Sie den gesamten Heapspeicher schon beim Start zuordnen, damit sie selbst unter Fehlerbedingungen nicht mehr auf malloc angewiesen sind. Amazon hat diese Strategie mehrfach umgesetzt, z. B. für Überwachungs-Daemons auf Produktionsservern und für Amazon Elastic Compute Cloud(Amazon EC2)-Daemons, die zur Überwachung der CPU-Bursts bei Kunden eingesetzt werden.
Verteilter Fallback
Für verteilte Systeme, vor allem wenn sie in Echtzeit reagieren sollen, lassen wir bei Amazon nicht dieselben Abstriche zu wie für Ein-Computer-Anwendungen. Das liegt zum einen an den mangelnden Folgen eines Ausfalls für den Kunden. Bei Anwendungen können wir davon ausgehen, dass sie auf dem Computer des Kunden ausgeführt werden. Wenn nicht mehr genügend Arbeitsspeicher zum Ausführen der Anwendung vorhanden ist, erwartet der Kunde wahrscheinlich nicht, dass sie trotzdem weiter ausgeführt wird. Services werden allerdings nicht direkt auf dem Computer des Kunden ausgeführt, weshalb seine Erwartung eine andere ist. Abgesehen davon werden Services üblicherweise genau aus diesem Grund genutzt – sie bieten eine höhere Verfügbarkeit, weil sie nicht wie Anwendungen auf einem einzelnen Server ausgeführt werden. Daher sollten wir diese Verfügbarkeit gewährleisten. In der Theorie müssten wir demnach einen Fallback implementieren, um die Zuverlässigkeit des Service zu erhöhen. Allerdings liegen beim verteilten Fallback dieselben Probleme vor wie beim Ein-Computer-Fallback. Bei kritischen Systemfehlern kommen sogar noch viel mehr Probleme hinzu.
Verteilte Fallback-Strategien sind schwieriger zu testen. Ein Fallback für einen Service ist komplizierter als für eine Anwendung, die auf einem einzigen Computer ausgeführt wird, da im Fall eines Fehlers weitere Computer und Downstream-Services involviert sind. Die Fehlermodi selbst, z. B. Überlastungsszenarien, lassen sich im Rahmen eines Tests schwer replizieren, auch wenn eine geräteübergreifende Testorchestrierung zur Verfügung steht. Die Kombinatorik sorgt außerdem für eine riesige Anzahl von Testfällen, sodass Sie mehr Tests ausführen müssen, die obendrein deutlich schwerer einzurichten sind.
Verteilte Fallback-Strategien selbst können scheitern. Obwohl es den Anschein hat, dass Fallback-Strategien den Erfolg garantieren, verbessern sie unserer Erfahrung nach in der Regel nur die Erfolgschancen.
Verteilte Fallback-Strategien verschlimmern den Ausfall oft. Wir haben festgestellt, dass Fallback-Strategien den Auswirkungsradius eines Ausfalls vergrößern und die Wiederherstellungszeit verlängern.
Verteilte Fallback-Strategien bergen oft unverhältnismäßige Risiken. Wie bei malloc2 können wir auch bei anderen Fallback-Strategie davon ausgehen, dass an anderer Stelle Abstriche gemacht werden. Sonst würden wir sie ständig einsetzen. Wenn bereits ein Problem vorliegt, sollte die Fallback-Lösung es nicht noch verschlimmern.
Verteilte Fallback-Strategien haben oft latente Fehler, die nur dann auftauchen, wenn eine unwahrscheinliche Anzahl von Zufällen eintritt, möglicherweise Monate oder Jahre nach ihrer Einführung.
Alle diese Probleme können anhand eines schweren Ausfalls veranschaulicht werden, der durch einen Fallback-Mechanismus auf der Geschäftswebsite von Amazon ausgelöst wurde. Der Ausfall trat um das Jahr 2001 auf und wurde von einer neuen Funktion verursacht, mit deren Hilfe aktualisierte Lieferzeiten für alle auf der Website gezeigten Produkte bereitgestellt wurden.
Die neue Funktion sah ungefähr so aus:

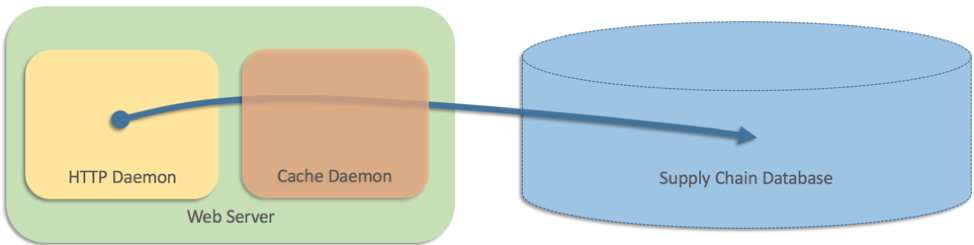
Also haben wir eine Caching-Ebene hinzugefügt, die als separater Prozess auf jedem Webserver läuft.
Die Websitearchitektur bestand damals nur aus zwei Tiers und die Daten wurden in einer Lieferketten-Datenbank gespeichert. Deshalb mussten Webserverabfragen direkt an die Datenbank gesendet werden. Die Datenbank konnte die Menge der Anforderungen von der Website jedoch nicht verarbeiten. Die Website hatte hohe Zugriffszahlen und auf einigen Seiten wurden 25 oder mehr Produkte aufgeführt, deren Lieferzeiten jeweils inline angezeigt wurden. Also haben wir eine Caching-Ebene hinzugefügt, die als separater Prozess auf jedem Webserver läuft (ähnlich wie Memcached):
Unsere Lösung war folgender Pseudocode:
Das hat gut funktioniert. Dann versuchte das Team allerdings, ein Problem zu beheben, bei dem aus unerfindlichen Gründen ein Fehler mit dem Cache (einem eigenen Prozess) auftrat. In diesem Szenario fielen die Webserver darauf zurück, Datenbankabfragen direkt durchzuführen. In Pseudocode haben wir so etwas geschrieben: Der Rückgriff auf direkte Datenbankabfragen war eine intuitive Lösung, die mehrere Monate lang funktionierte. Irgendwann fiel dann aber jeder Cache zur gleichen Zeit aus, was bedeutete, dass jeder Webserver direkte Abfragen an die Datenbank sendete. Die Belastung war so groß, dass es zum vollständigen Funktionsstillstand der Datenbank kam. Die gesamte Website konnte nicht mehr erreicht werden, da alle Webserverprozesse von der Datenbank blockiert wurden. Diese Supply-Chain-Datenbank war auch für Logistikzentren von entscheidender Bedeutung, sodass sich der Ausfall noch weiter ausbreitete und alle Logistikzentren weltweit zum Erliegen kamen, bis das Problem behoben war. Alle Probleme, die wir im Fall einer einzelnen Maschine sahen, traten auch im verteilten Fall auf, und hatten schlimmere Folgen. Es war schwierig, den Fall des verteilten Fallbacks zu testen. Selbst wenn wir den Cache-Ausfall simuliert hätten, hätten wir das Problem nicht gefunden, da Ausfälle auf mehreren Computern erforderlich waren, um ausgelöst zu werden. Und in diesem Fall verstärkte die Fallback-Strategie selbst das Problem und war schlimmer als gar keine Fallback-Strategie. Durch den Fallback wurde aus einem teilweisen Ausfall der Website (da die Versandgeschwindigkeiten nicht angezeigt werden konnten) ein vollständiger Ausfall der Website (es wurden überhaupt keine Seiten geladen) und das gesamte Amazon-Versandnetzwerk im Backend lahmgelegt. Die Überlegungen hinter unserer Fallback-Strategie waren in diesem Fall unlogisch. Da die direkte Abfrage der Datenbank zuverlässiger war als die Verwendung des Cache, hätten wir von Anfang an auf die Cache-Lösung verzichten können. Unsere Sorge bestand darin, dass ein Verzicht auf den Cache eine Überlastung der Datenbank zur Folge haben könnte. Stattdessen implementierten wir einen Fallback-Code, der uns viel größere Probleme bescherte. Wir haben unseren Fehler vielleicht schon früh bemerkt, aber der Fehler war ein latenter Fehler, und die Situation, die den Ausfall verursacht hat, tauchte Monate nach dem Start auf.
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}Wie Fallback bei Amazon umgangen wird
Aufgrund unserer Erfahrungen mit Fallbacks in verteilten Systemen ziehen wir heute fast immer alternative Lösungswege vor. Diese werden im Folgenden beschrieben.
Zuverlässigkeit von Fallback-Alternativen verbessern
Wie bereits erwähnt tragen Fallback-Strategien nur dazu bei, die Wahrscheinlichkeit von Totalausfällen zu reduzieren. Sie können die Verfügbarkeit eines Service deutlich erhöhen, wenn Sie den Hauptcode ausfallsicherer machen. Statt eine Fallback-Logik zwischen zwei Datenspeichern zu implementieren, könnten Sie zum Beispiel in eine Datenbank wie Amazon DynamoDB investieren, die eine von Haus aus höhere Verfügbarkeit bietet. Diese Strategie führt bei Amazon oft zum Erfolg. In diesem Vortrag wird beispielsweise beschrieben, wie Amazon.com am Prime Day 2017 mit DynamoDB betrieben wird.
Fehler vom Aufrufer verarbeiten lassen
Eine Strategie bei kritischen Systemfehlern besteht darin, den Fehler vom aufrufenden System verarbeiten zu lassen (z. B. durch Wiederholungsversuche), anstatt einen Fallback durchzuführen. Diese Strategie wird bei AWS-Services bevorzugt, da eine Logik für Wiederholungsversuche bereits in unsere CLIs und SDKs integriert ist. Wir versuchen Sie so oft wie möglich einzusetzen, besonders wenn ausreichende Vorkehrungen für Fate-Sharing getroffen und die Wahrscheinlichkeit reduziert wurden, dass die Hauptanwendung ausfällt (und eine Verbesserung der Verfügbarkeit durch die Fallback-Logik nur sehr unwahrscheinlich wäre).
Daten proaktiv weiterleiten
Eine weitere Taktik, mit deren Hilfe wir Fallbacks vermeiden, besteht darin, die Anzahl der Variablen bei der Beantwortung von Anforderungen zu reduzieren. Wenn ein Service beispielsweise Daten zum Erfüllen einer Anforderung benötigt und diese Daten bereits lokal gespeichert sind (nicht abgerufen werden müssen), ist keine Failover-Strategie erforderlich. Ein erfolgreiches Beispiel dafür ist die Implementierung von AWS Identity and Access Management (IAM) -Rollen für Amazon EC2 . Der IAM-Service muss Code, der auf EC2-Instances ausgeführt wird, mit signierten, rotierten Anmeldeinformationen versorgen. Um Fallback vollständig zu vermeiden, werden die Anmeldeinformationen proaktiv an sämtliche Instances übertragen und bleiben viele Stunden lang gültig. Das sorgt dafür, dass Anforderungen bezüglich IAM-Rollen bei einem unwahrscheinlichen Ausfall des Push-Mechanismus weiterhin funktionieren.
Fallback in Failover verwandeln
Einer der größten Nachteile von Fallback-Lösungen ist der Umstand, dass sie nicht regelmäßig getestet werden und beim Einsatz in der Praxis fehlschlagen bzw. die Auswirkungen eines Ausfalls verschlimmern können. Die Bedingungen, unter denen ein Fallback ausgelöst wird, sind möglicherweise über Monate oder gar Jahre hinweg nicht gegeben. Um das Problem latenter Fehler in der Fallback-Strategie zu beheben, muss diese in der Produktion regelmäßig ausgeführt werden. Ein Service muss gleichzeitig sowohl auf der Fallback-Logik als auch auf der normalen Logik laufen. Dabei muss der Fallback jedoch nicht bloß ausgeführt, sondern als gleichwertige Datenquelle behandelt werden. Zum Beispiel kann ein Service zufällig zwischen Fallback und Nicht-Fallback-Antworten wählen (wenn er beide erhält), um die Funktion beider Lösungen zu testen. Ab diesem Punkt lässt sich die Strategie jedoch nicht mehr als Fallback kategorisieren, sondern ist als Failover einzuordnen.
Wiederholungsversuche und Timeouts nicht als Fallback-Lösungen verwenden
Wiederholungen und Timeouts werden im Artikel Timeouts, Retries und Backoff with Jitter behandelt. In dem Artikel heißt es, dass Wiederholungsversuche ein leistungsfähiger Mechanismus sind, um angesichts vorübergehender und zufälliger Fehler eine hohe Verfügbarkeit zu gewährleisten. Anders ausgedrückt: Wiederholungsversuche und Timeouts schützen vor gelegentlichen Ausfällen aufgrund geringfügiger Fehler wie scheinbarem Paketverlust, unzusammenhängenden Ausfällen einzelner Computer usw. Aber auch Wiederholungsversuche und Timeouts bergen hohes Fehlerpotenzial. Services erfordern oft über Monate hinweg kaum Wiederholungsversuche. Diese können jedoch genau in Szenarien nötig werden, die von Ihrem Team nie getestet wurden. Aus diesem Grund setzen wir Metriken ein, mit denen die Anzahl der Wiederholungen und Alarme erfasst werden. Bei häufigen Wiederholungsversuchen erhalten unsere Teams eine entsprechende Benachrichtigung.
Eine andere Möglichkeit, zu verhindern, dass Wiederholungsversuche zu einem Fallback werden, besteht darin, sie ständig mit proaktiven Wiederholungsversuchen auszuführen (auch bekannt als Hedging oder parallele Anfragen). Diese Technik wird nativ in Systeme integriert, die Quorum-Lese- oder Schreibvorgänge durchführen, wenn für eine Reaktion des Systems zwei von drei Servern antworten müssen. Der proaktive Wiederholungsversuch folgt dem Entwurfsmuster der ständigen Arbeit. Da die redundanten Anforderungen ohnehin ausgeführt werden, wird das System durch Wiederholungsversuche nicht zusätzlich belastet, wenn mehr redundante Anforderungen erforderlich werden.
Fazit
Wir bei Amazon konzipieren unsere System ohne Fallback, da Funktion und Effektivität des Konzepts schwer nachzuweisen sind. Fallback-Strategien bringen einen Betriebsmodus mit sich, in den Systeme nur in absoluten Notlagen übergehen, wenn Fehler auftreten. Der Wechsel in diesen Modus verschlimmert die Situation nur. Zwischen der Implementierung einer Fallback-Strategie und deren Inkrafttreten in der Produktionsumgebung vergeht oft viel Zeit.
Deshalb bevorzugen wir Codepfade, die nicht bloß sporadisch, sondern dauerhaft in der Produktion ausgeführt werden. Unser Schwerpunkt liegt darauf, die Verfügbarkeit unserer Primärsysteme zu erhöhen. Dazu übertragen wir Daten z. B. an Zielsysteme, bevor sie durch einen Remote-Aufruf geladen werden müssen, der zu einem kritischen Zeitpunkt fehlschlagen kann. Zu guter Letzt achten wir auf subtile Verhaltensmuster in unserem Code, z. B. eine ungewöhnlich große Anzahl von Wiederholungsversuchen, die einen Fallback-artigen Betriebsmodus auslösen könnten.
Erfordert ein System zwingend eine Fallback-Strategie, führen wir diese in der Produktion so oft wie möglich aus, sodass sie genau so zuverlässig und vorhersehbar funktioniert wie der primäre Betriebsmodus.
Über den Autor
Jacob Gabrielson ist Senior Principal Engineer bei Amazon Web Services. Er arbeitet seit 17 Jahren für Amazon, hauptsächlich an den internen Mikroservice-Plattformen. In den vergangenen 8 Jahren hat er sich der Arbeit an EC2 und ECS gewidmet, darunter an Systemen zur Softwarebereitstellung, Services für Steuerebenen, dem Spot-Markt, Lightsail und jüngst auch Containern. Jacob beschäftigt sich gerne mit Systemprogrammierung, Programmiersprachen und verteilter Verarbeitung. Er ist nicht besonders begeistert vom bimodalen Systemverhalten, besonders in Fehlerzuständen. Er hat seinen Bachelor in Informatik an der University of Washington in Seattle abgeschlossen.
