Fehlerbehebung
Übersicht
Ein Verständnis für die Behebung von Problemen mit CloudFront hilft Betreibern und SREs bei der schnellen Behebung von Fehlern, die an verschiedenen Stellen der Webanwendung auftreten können: CloudFront, Edge-Funktionen oder am Ursprung. Zu diesen Fehlern gehören: Ein überlasteter Ursprung, der 5xx-Fehler zurückgibt, CloudFront, das sich nicht mit dem Ursprung verbinden kann, oder eine fehlerhafte Lambda@Edge-Ausführung nach einer unbehandelten Ausnahme im Code.
Verfolgung von Anfragen von Benutzern bis zum Ursprung
CloudFront generiert für jede einzelne Anfrage, die es verarbeitet, eine eindeutige Anfrage-ID. Es wird empfohlen, die Anfrage anhand ihrer ID zu verfolgen, während sie durch den Anwendungsstapel fließt:
- CloudFront fügt einen x-amz-cf-id-Header hinzu, der die Anfrage-ID enthält, wenn es die Antwort auf eine HTTP-Anfrage zurückgibt.
- CloudFront fügt die Anfrage-ID in das Feld x-edge-request-id des Protokolldatensatzes ein, der für eine Anfrage in den Zugriffsprotokollen erstellt wurde. Wenn die CloudFront-Verteilung mit einer AWS-WAF-WebACL verknüpft ist, fügt die WAF die Anfrage-ID in das Feld requestId des Protokolleintrags ein, der für die Anfrage in den WAF-Protokollen erstellt wurde. OLX hat beispielsweise einen Chatbot entwickelt, der von seinen Kundensupporttechnikern in Slack verwendet werden kann, um eine bestimmte Anfrage anhand ihrer Anfrage-ID aus den WAF-Protokollen abzufragen. So können sie herausfinden, warum die Anfrage blockiert wurde, und dann täglich schneller auf Kundentickets reagieren.
- Wenn eine Edge-Funktion auf der CloudFront-Verteilung konfiguriert ist, wird die Anfrage-ID der Funktion im Feld requestId im Ereignisobjekt zur Verfügung gestellt, sowohl für (CloudFront-Funktionen als auch Lambda@Edge).
- Bei fehlgeschlagenen Caches leitet CloudFront die Anfrage an den Ursprung weiter und fügt den Header x-amz-cf-id mit dem Wert der Anfrage-ID an die Anfrage an. Es wird empfohlen, diesen Header auf Ihren Ursprungsservern zu protokollieren.
Fehlerbehebung mit CloudFront
Wenn Ihre Überwachungssysteme (z. B. CloudWatch-Warnungen) eine Zunahme der Antworten mit 4xx- oder 5xx-Fehlern feststellen, müssen Sie den Fehlertyp und den Ort, an dem er auftritt, untersuchen, um ihn zu beheben.
Filtern Sie dazu die Zugriffsprotokolle von CloudFront nach Datensätzen, die einen Fehlercode enthalten, und überprüfen Sie die Protokollfelder x-edge-result-type, x-edge-response-result-type und x-edge-detailed-result-type, um das Problem näher zu bestimmen. Die Analyse der Zugriffsprotokolle hängt davon ab, wo Sie Ihre Protokolle speichern. Ein sehr einfacher Ansatz ist die Überprüfung von in S3 gespeicherten Protokollen mit Athena und Standard-SQL-Abfragen. Die folgende SQL-Abfrage filtert beispielsweise die Protokolle nach 5xx-Fehlern in einem bestimmten Zeitraum und beschränkt sich auf die ersten 100 Datensätze.
SELECT * AS count FROM cloudfront_logs
WHERE status >= 500 AND "date" BETWEEN DATE '2022-06-09' AND DATE '2022-06-10'
LIMIT 100;
In bestimmten Fällen können Sie in den Protokollen von WAF oder CloudFront weitere Informationen zur Fehlerbehebung finden. Beispielsweise könnten die AWS-WAF-Protokolle erklären, warum eine bestimmte Anfrage blockiert wurde. Ein anderes Beispiel ist die Überprüfung von Edge-Funktionsprotokollen in CloudWatch Logs, um zu verstehen, warum ein Ausführungsfehler zu einem 5xx führte. Darüber hinaus ist es ratsam zu verstehen, wie CloudFront Fehler zwischenspeichert, um zu erfahren, wann eine Fehlerantwort aus dem CloudFront-Cache zurückgegeben wird oder nicht.
Fehlerbehebung der Latenz mit CloudFront
Wenn Ihre Überwachungssysteme (z. B. CloudWatch-Warnungen zur Ursprungslatenz und Metriken zur Cache-Trefferrate) einen Anstieg der Antwortlatenzen feststellen, sollten Sie verstehen, wo der Latenzengpass liegt, um ihn zu beheben. Zu diesem Zweck sollten Sie die Latenzfelder in den Zugriffsprotokollen von CloudFront analysieren. Berücksichtigen Sie die folgenden Felder:
- time-to-first-byte: Latenz des ersten Bytes zwischen CloudFront und dem Betrachter, verfügbar in Standardprotokollen und Echtzeitprotokollen
- time-taken: Latenz im letzten Byte zwischen CloudFront und dem Betrachter, verfügbar in Standardprotokollen und Echtzeitprotokollen
- origin-fbl: Latenzzeit des ersten Bytes zwischen CloudFront und Ihrem Ursprung, verfügbar in Echtzeitprotokollen
- origin-lbl: Latenzzeit im letzten Byte zwischen CloudFront und Ihrem Ursprung, verfügbar in Echtzeitprotokollen
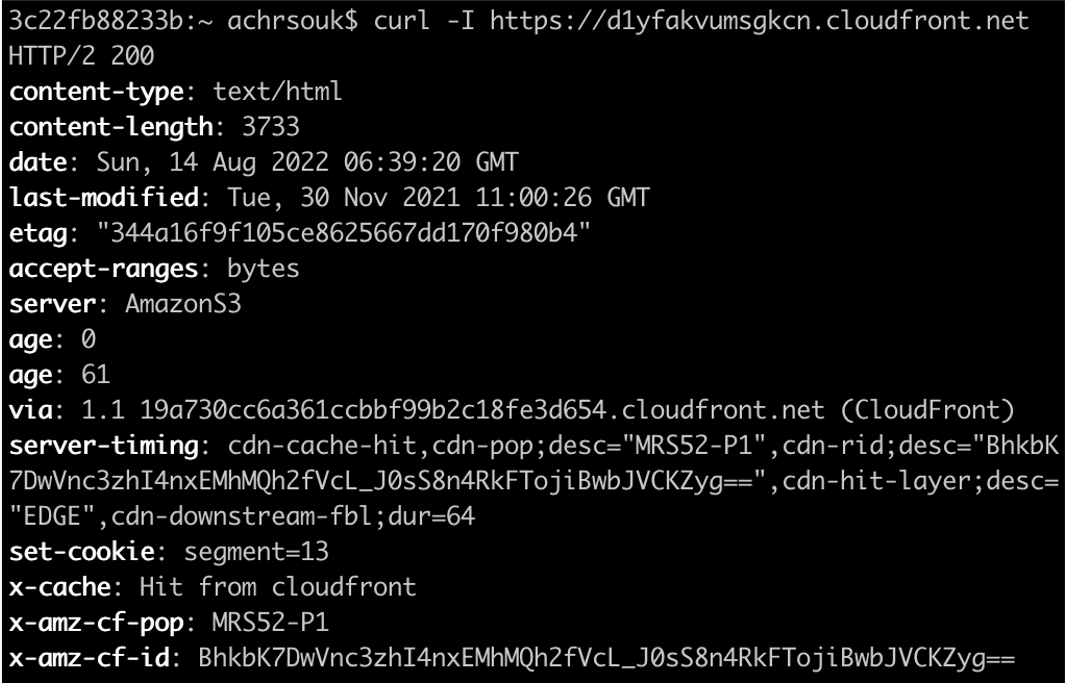
Sie können diese Felder analysieren, indem Sie die SQL-Abfrage nach einer der relevanten Dimensionen gruppieren, z. B. nach URL oder Land. Dies hilft Ihnen, das Problem der Latenz einzugrenzen. Darüber hinaus finden Sie dieselben Informationen auf der Client-Seite mithilfe der Server-Timing-Header von CloudFront, sofern diese in der Richtlinie des Antwort-Headers konfiguriert sind. Der folgende Server-Timing-Header erklärt, dass meine Anfrage ein Cache-Treffer auf dem MRS52-P1-Pop in Marseille war, mit einer Downstream-Latenz des ersten Bytes von 64 Millisekunden. Beachten Sie den von CloudFront generierten Age-Header, der erklärt, dass dieser Inhalt seit 61 Sekunden vom Ursprung abgerufen oder aktualisiert wurde.
Fehlerbehebung bei der Webleistung mit CloudWatch RUM
Mit CloudWatch RUM können Sie Ihre Anwendung auf der Client-Seite überwachen, indem Sie ein JavaScript-Tag in Ihre Webseiten integrieren. Das Javascript sammelt Daten von Browser-APIs, wie Seitenladezeiten mit Aufschlüsselung der Verbindungsschritte (DNS-Lookup, TCP-Verbindung usw.) oder Google Core Web Vitals (LCP, FID usw.), und sendet sie dann an CloudWatch RUM für das Dashboarding. Sie können die Leistung Ihrer Anwendung analysieren, indem Sie nach bestimmten Dimensionen wie dem Browsertyp, dem Benutzerland oder einer bestimmten Seiten-ID filtern.
Anfrage für Unterstützung durch AWS-Support
In Szenarien, in denen Sie die Unterstützung des AWS Supports benötigen, um weitere Probleme mit Fehlern oder Latenzen zu beheben, können Sie ein Ticket beim Support eröffnen. Dort finden Sie eine Liste von CloudFront-Anfrage-IDs, die den langsamen Anfragen oder den Anfragen entsprechen, die zu Fehlern führen. Mit diesen bereitgestellten Anfrage-IDs können Support-Techniker interne Protokolle einsehen, um das Problem besser zu verstehen und Ihnen Empfehlungen zur Behebung zu geben.
Ressourcen
- Dokumentation: Beheben Sie häufige Probleme, die beim Einrichten von Amazon CloudFront für die Verteilung Ihrer Inhalte auftreten können
- Blog: Vier Schritte zum Debuggen Ihrer Inhaltsbereitstellung auf AWS. Beachten Sie, dass dieser Blog zwar veraltet, die Methodik jedoch weiterhin gültig ist.
- Dokumentation: Wie behebe ich Fehler und reduziere die erhöhte Latenz von CloudFront?
- Anleitung: Artikel zur Fehlerbehebung für CloudFront von AWS Support
- Anleitung: Artikel zur Fehlerbehebung für AWS WAF von AWS Support
- AWS re:Invent 2021 – Anwendungsoptimierung auf Basis von Informationen zum Endbenutzerverhalten mit Amazon CloudWatch RUM
- Blog: Analysieren von AWS-WAF-Protokollen in Amazon CloudWatch Logs
- Dokumentation: Testen und Debuggen von Lambda@Edge -Funktionen
- Blog: End-to-End-Ablaufverfolgung mit Amazon CloudFront mit OpenTelemetry einrichten