AWS Glue
Alle Ihre Daten in beliebigem Umfang entdecken, vorbereiten und integrieren
Warum AWS Glue?
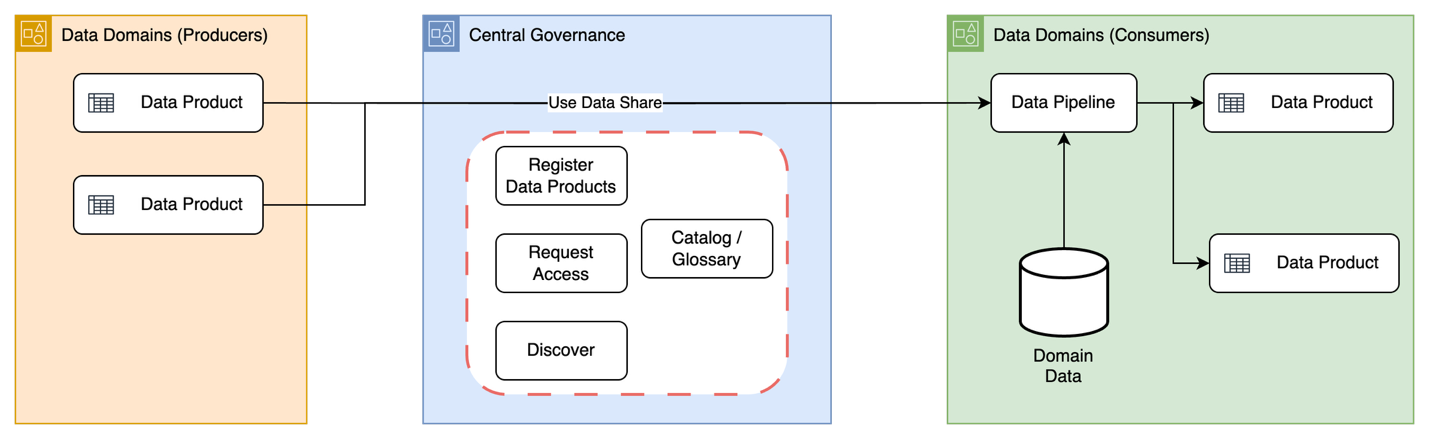
Die Vorbereitung Ihrer Daten zur Erzielung hochwertiger Ergebnisse ist der erste Schritt in einem Analytik- oder KI-Projekt. AWS Glue ist ein Serverless-Service, der die Datenintegration einfacher, schneller und kostengünstiger macht. Sie können mehr als 100 verschiedene Datenquellen finden und mit ihnen verbinden, Ihre Daten in einem zentralen Datenkatalog verwalten und Datenpipelines visuell erstellen, ausführen und überwachen, um Daten in Ihre Data Lakes, Data Warehouses und Lakehouses zu laden. Mit den integrierten Funktionen mit generativer KI können Sie Apache-Spark-Aufträge modernisieren und dank intelligenter Unterstützung für ETL-Authoring und Spark-Fehlerbehebung schneller entwickeln.

Integrieren Sie Ihre Daten mit AWS Glue in die nächste Generation von Amazon SageMaker
Mit AWS Glue in der nächsten Generation von Amazon SageMaker können Sie Ihre Workloads an einem Ort verwalten und erstellen – mit einer kostengünstigen, Serverless- und skalierbaren Datenintegration.

Vorteile
-
AWS Glue bietet alle Funktionen, die für die Datenintegration erforderlich sind, sodass Sie Erkenntnisse gewinnen und Ihre Daten schnell nutzen können. AWS Glue bietet ein vollständig verwaltetes, Serverless-Toolkit zur Gestaltung und Automatisierung moderner Datenpipelines – mit integrierter ETL, Schemaerkennung und serviceübergreifender Integration.
AWS Glue skaliert selbst die anspruchsvollsten ressourcenintensiven Datenverarbeitungsaufgaben automatisch von Gigabyte auf Petabyte, ohne dass eine Infrastruktur verwaltet werden muss. Sie zahlen lediglich für die tatsächlich genutzten Ressourcen.
-
AWS Glue macht die Infrastrukturverwaltung überflüssig, indem es Serverless-Datenpipelines mit integrierten Planungs- und Überwachungsfunktionen bereitstellt, sodass sich Teams auf die Erstellung von Daten-Workflows konzentrieren können, anstatt sich um die Wartung von Servern zu kümmern.
-
Holen Sie sich KI-gestützte Hilfe während Ihrer gesamten Datenintegration – von der automatischen Generierung von ETL-Code bis hin zur Modernisierung Ihrer Spark-Auftrags. AWS Glue bietet intelligente Code-Generierung, KI-gestützte Spark-Upgrades und integrierte Spark-Fehlerbehebung.
-
Integrieren Sie Ihre Daten, wo auch immer sie sich befinden, mit schneller und einfacher Konnektivität zu Datenquellen in der nächsten Generation von Amazon SageMaker. Erstellen Sie ein Datenverarbeitungsprojekt mit einer Kombination aus AWS Glue, Amazon Athena, Amazon EMR und MWAA – alles innerhalb von Amazon SageMaker – und profitieren Sie von einem gemeinsamen Verwaltungs- und Überwachungserlebnis. Die Datenverarbeitungsfunktionen von AWS Glue sind in Amazon-SageMaker-Notebooks und Amazon SageMaker Visual ETL verfügbar.
Anwendungsfälle
Die Verwaltung von ETL-Pipelines vereinfachen
Beseitigen Sie das Infrastrukturmanagement mit automatischer Bereitstellung und Worker-Management und konsolidieren Sie all Ihre Datenintegrationsanforderungen in einem einzigen Service.
Interaktives Erkunden, Experimentieren und Verarbeiten von Daten
Mit interaktiven AWS-Glue-Sitzungen können Dateningenieure Daten interaktiv erkunden und vorbereiten, indem sie die integrierte Entwicklungsumgebung (IDE) oder das Notebook ihrer Wahl verwenden.
Daten effizient entdecken
Identifizieren Sie schnell Daten in AWS, lokalen und anderen Clouds und stellen Sie sie dann sofort für Abfragen und Transformationen zur Verfügung.
Unterstützung verschiedener Verarbeitungs-Frameworks und Workloads
Einfachere Unterstützung verschiedener Datenverarbeitungs-Frameworks wie ETL und ELT sowie verschiedener Workloads, einschließlich Batch, Micro-Batch und Streaming.
Neuerungen




Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern