Was ist die Datenbeschriftung?
Was ist die Datenbeschriftung?
Beim maschinellen Lernen ist Datenkennzeichnung der Prozess, bei dem Rohdaten (Bilder, Textdateien, Videos usw.) identifiziert und eine oder mehrere aussagekräftige und informative Bezeichnungen hinzugefügt werden, um den Kontext bereitzustellen, sodass ein maschinelles Lernmodell daraus lernen kann. So kann beispielsweise angegeben werden, ob auf einem Foto ein Vogel oder ein Auto zu sehen ist, welche Wörter in einer Audioaufnahme gesprochen wurden oder ob eine Röntgenaufnahme einen Tumor enthält. Das Daten-Labeling ist für eine Vielzahl von Anwendungsfällen erforderlich, darunter Computer Vision, natürliche Sprachverarbeitung und Spracherkennung.
Wie funktioniert das Daten-Labeling?
Heutzutage verwenden die meisten praktischen Modelle für Machine Learning überwachtes Lernen, bei dem ein Algorithmus angewendet wird, um eine Eingabe einer Ausgabe zuzuordnen. Damit überwachtes Lernen funktioniert, benötigen Sie einen beschrifteten Datensatz, aus dem das Modell lernen kann, um richtige Entscheidungen zu treffen. Das Daten-Labeling beginnt in der Regel damit, dass Menschen gebeten werden, Urteile über bestimmte unbeschriftete Daten zu fällen. Beispielsweise können Labeler gebeten werden, alle Bilder in einem Datensatz zu taggen, bei denen „Enthält das Foto einen Vogel“ zutrifft. Das Tagging kann so grob wie ein einfaches Ja/Nein oder so detailliert wie die Identifizierung der spezifischen Pixel im Bild sein, die dem Vogel zugeordnet sind. Das Modell des Machine Learnings verwendet von Menschen bereitgestellte Beschriftungen, um die zugrunde liegenden Muster in einem Prozess zu lernen, der als „Modelltraining“ bezeichnet wird. Das Ergebnis ist ein trainiertes Modell, das verwendet werden kann, um Vorhersagen über neue Daten zu treffen.
Beim Machine Learning wird ein korrekt beschrifteter Datensatz, den Sie als objektiven Standard verwenden, um ein bestimmtes Modell zu trainieren und zu bewerten, oft als „Ground Truth“ bezeichnet. Die Genauigkeit Ihres trainierten Modells hängt von der Genauigkeit Ihrer Ground Truth ab. Daher ist es wichtig, Zeit und Ressourcen aufzuwenden, um ein hochgenaues Daten-Labeling sicherzustellen.
Was sind einige gängige Arten des Daten-Labelings?
Computervision
Wenn Sie ein Computer-Vision-System entwickeln, müssen Sie zunächst Bilder, Pixel oder wichtige Punkte beschriften oder einen Rahmen erstellen, der ein digitales Bild vollständig umschließt, einen so genannten Begrenzungsrahmen, um Ihren Trainingsdatensatz zu generieren. Sie können Bilder beispielsweise nach Qualitätstyp (wie Produkt- oder Lifestyle-Bilder) oder Inhalt (was tatsächlich im Bild selbst enthalten ist) klassifizieren, oder Sie können ein Bild auf Pixelebene segmentieren. Sie können diese Trainingsdaten dann verwenden, um ein Computer-Vision-Modell zu erstellen, das verwendet werden kann, um Bilder automatisch zu kategorisieren, die Position von Objekten zu erkennen, wichtige Punkte in einem Bild zu identifizieren oder ein Bild zu segmentieren.
Natürliche Sprachverarbeitung
Bei der Verarbeitung natürlicher Sprache müssen Sie wichtige Textabschnitte zunächst manuell identifizieren oder den Text mit bestimmten Bezeichnungen kennzeichnen, um Ihren Trainingsdatensatz zu generieren. Beispielsweise möchten Sie vielleicht die Stimmung oder Absicht eines Textblurbs ermitteln, Wortarten identifizieren, Eigennamen wie Orte und Personen klassifizieren und Text in Bildern, PDFs oder anderen Dateien identifizieren. Dazu können Sie Begrenzungsrahmen um den Text zeichnen und den Text dann manuell in Ihrem Trainingsdatensatz transkribieren. Modelle zur Verarbeitung natürlicher Sprache werden für die Stimmungsanalyse, die Erkennung von Entitätsnamen und die optische Zeichenerkennung verwendet.
Audioverarbeitung
Die Audioverarbeitung wandelt alle Arten von Geräuschen wie Sprache, Geräusche von Wildtieren (Bellen, Pfeifen oder Zwitschern) und Gebäudegeräusche (Glasbruch, Scans oder Alarme) in ein strukturiertes Format um, sodass sie für Machine Learning verwendet werden können. Bei der Audioverarbeitung müssen Sie sie häufig zuerst manuell in geschriebenen Text transkribieren. Von dort aus können Sie tiefere Informationen über das Audio aufdecken, indem Sie Tags hinzufügen und das Audio kategorisieren. Dieses kategorisierte Audio wird zu Ihrem Trainingsdatensatz.
Was sind einige bewährte Methoden für das Daten-Labeling?
Es gibt viele Techniken, um die Effizienz und Genauigkeit des Daten-Labelings zu verbessern. Einige dieser Techniken umfassen:
- Intuitiv verwendbare und optimierte Aufgaben-Benutzeroberflächen, um die kognitive Belastung und den Kontextwechsel für menschliche Labeler zu minimieren.
- Labeler-Konsens, um dem Fehler/der Voreingenommenheit einzelner Annotatoren entgegenzuwirken. Der Labeler-Konsens beinhaltet das Senden jedes Datensatzobjekts an mehrere Annotatoren und die anschließende Konsolidierung ihrer Antworten (sogenannte „Anmerkungen“) in einer einzigen Beschriftung.
- Prüfung der Beschriftungen, um die Richtigkeit der Beschriftungen zu überprüfen und sie bei Bedarf zu aktualisieren.
- Aktives Lernen, um das Daten-Labeling effizienter zu gestalten, indem Machine Learning verwendet wird, um die nützlichsten Daten zu identifizieren, die von Menschen beschriftet werden sollen.
Wie kann das Daten-Labeling effizient durchgeführt werden?
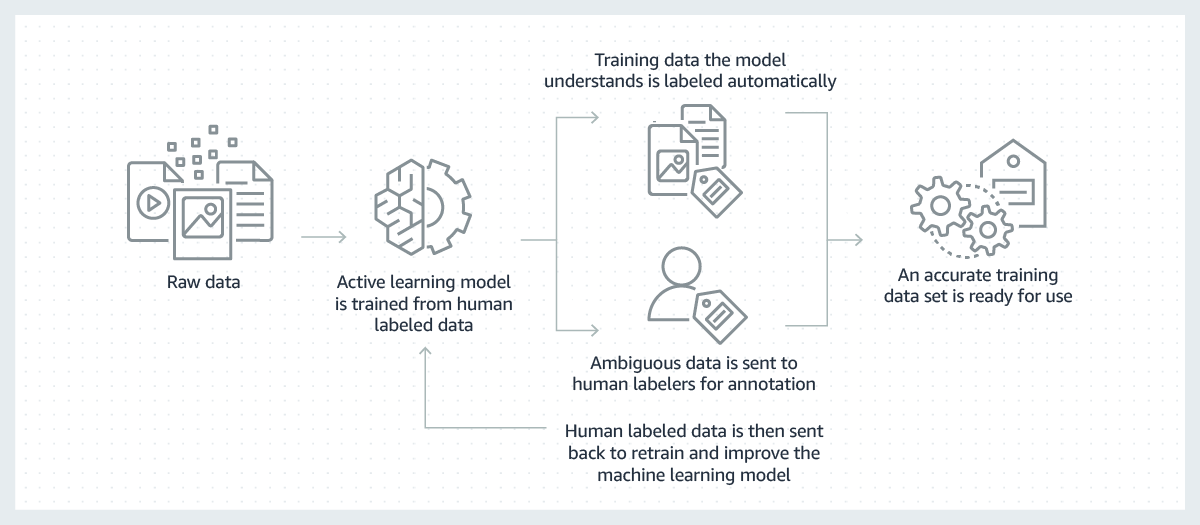
Erfolgreiche Machine Learning-Modelle wurden auf Grundlage großer Mengen qualitativ hochwertiger Trainingsdaten erstellt. Das Erstellen der Trainingsdaten, die zum Aufbauen dieser Modelle notwendig sind, ist meist teuer, kompliziert und zeitaufwendig. Die meisten heute erstellten Modelle erfordern, dass eine Person Daten per Hand so kennzeichnet, dass das Modell lernt, die richtigen Entscheidungen zu treffen. Um diese Herausforderung zu bewältigen, kann das Labeling effizienter gestaltet werden, indem ein Modell für Machine Learning verwendet wird, um Daten automatisch zu beschriften.
In diesem Prozess wird ein Modell für Machine Learning zur Beschriftung von Daten zunächst an einer Teilmenge Ihrer Rohdaten trainiert, die von Menschen beschriftet wurden. Wenn das kennzeichnende Modell auf Grundlage des bisher Gelernten eine hohe Sicherheit aufweist, wendet es Labels automatisch auf Rohdaten an. Wenn das kennzeichnende Modell eine niedrigere Sicherheit hat, überlässt es Personen das Kennzeichnen. Die von Menschen generierten Beschriftungen werden dann an das Beschriftungsmodell zurückgegeben, damit es daraus lernen und seine Fähigkeit verbessern kann, den nächsten Satz von Rohdaten automatisch zu beschriften. Mit der Zeit kann das Modell immer mehr Daten beschriften und die Erstellung von Trainingsdatensätzen erheblich beschleunigen.
Wie kann AWS Ihre Anforderungen an Daten-Labeling unterstützen?
Amazon SageMaker Ground Truth verringert deutlich den Zeit- und Arbeitsaufwand, der zur Erstellung von Trainingsdatensätzen erforderlich ist. SageMaker Ground Truth bietet Zugriff auf öffentliche und private menschliche Kennzeichner und stellt diesen integrierte Workflows und Schnittstellen für gängige Labeling-Aufgaben zur Verfügung. Der Einstieg in SageMaker Ground Truth ist einfach. Mit dem Tutorial Erste Schritte können Sie in wenigen Minuten Ihren ersten Labeling-Auftrag erstellen.
Beginnen Sie mit Daten-Labeling in AWS, indem Sie noch heute ein Konto erstellen.
Nächste Schritte mit AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages