Blog de Amazon Web Services (AWS)
Cómo crear un modelo de recomendación basado en machine learning.
Recomendaciones personalizadas de anime
Por Elizabeth Fuentes Leone, AWS Developer Advocate
Conocí los animes cuando estaba en la universidad, entre amigos nos recomendábamos los más populares y nuevos. Al terminar la universidad también acabaron los momentos para hablar de animes, quedé desactualizada y dejé de verlos.
Recientemente descubrí un anime que me encanto, quería ver otro similar y a falta de los momentos universitarios recordé los modelos de recomendación basados en Machine Learning (ML) utilizados en muchas aplicaciones, donde mejoran resultados entregando predicciones en forma de sugerencias personalizadas a cada usuario y, pueden disminuir los costos de promoción ofreciendo recomendaciones con gran probabilidad de aceptación.
Algunos ejemplos de recomendaciones personalizadas son:
- Las recomendaciones de series o películas en las plataformas de Video a Demanda (Video On Demand = VoD) son basadas en el historial de contenido.
- Al buscar productos determinados en un comercio electrónico, por ejemplo Amazon.com entrega sugerencias basada en el historial de lo que se haya buscado o comprado.
Este es el primer episodio de una serie de artículos llamados “Recomendaciones personalizadas de anime” donde vamos a construir una aplicación web capaz de entregar una experiencia personalizada de recomendaciones de animes nuevos de preferencia del usuario y, a medida que la utilice con mayor frecuencia, va a conocer sus gustos casi a la perfección.
Esta serie consistirá en los siguientes episodios:
- Cómo crear un modelo de recomendaciones personalizadas (este episodio)
- Cómo desplegar el modelo recomendador de anime en una API REST
- Crea una aplicación web para probar las recomendaciones personalizadas de anime en tiempo real.
- Agrega autenticación a tu aplicación web.
- Medir el impacto de las recomendaciones personalizadas en los usuarios.
¡Comencemos!
Crear un proyecto para generar recomendaciones personalizadas normalmente tiene un alto nivel de complejidad por los skills y tecnologías involucradas. En este articulo utilizaremos Amazon Personalize para convertirlo en algo sencillo sin necesidad de conocimientos avanzados de ML.
Amazon Personalize:
Es un servicio basado en la misma tecnología de ML utilizada por Amazon.com, permite entrenar modelos de personalización y obtener recomendaciones relevantes, utiliza técnicas de Deep Learning y no requiere tener experiencia en ML
Personalize brinda un «servicio de motor de recomendaciones entrenado con tus propios datos», listo para entrenar, disminuyendo la carga de un proyecto de ML completo y con resultados más rápidos (comparados con un proyecto tradicional de Machine Learning). Además, ofrece una capa gratuita ?.
¿Cómo funciona Amazon Personalize? ?
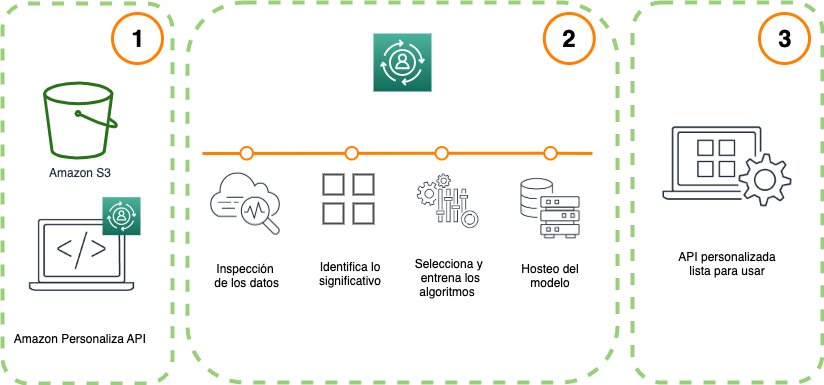
Fig. 1 Funcionamiento Amazon Personalize.
- Debes proporcionar datos sobre usuarios e ítems para realizar la personalización.
Los datos que utilizamos para modelar en Personalize son de tres tipos:
- a. Interactions DataSet(obligatorio): consiste en las interacciones de los usuarios con los ítems, por ejemplo, clics, compras, visualizaciones, calificaciones.
- b. Item DataSet (opcional): información de los ítems, tales como categoría o género.
- c. Users DataSet (opcional): datos de los usuarios como edad o género.
- Detrás de cámaras, Amazon Personalizeautomáticamente:
- a. Inspecciona los datos.
- b. Identifica las variables más significativas.
- c. Selecciona los algoritmos adecuados, entrena y optimiza modelos candidatos. Seleccionando el modelo con mejor desempeño.
- d. Almacena el modelo entrenado.
- Después del entrenamiento, Amazon Personalize permite desplegar el modelo entrenado para hacer inferencias a través de una API.
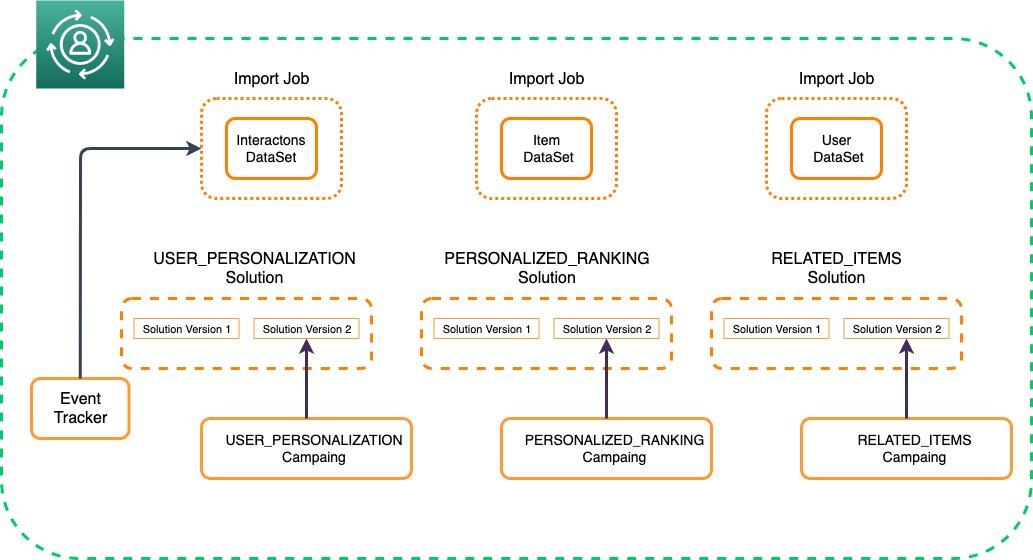
Fig. 2 Recursos de Amazon Personalize.
Y, ahora me detengo a explicarte los recursos que utiliza Amazon Personalize y como se relacionan con los términos de Machine Learning (Fig.2)
- Recipe (Receta): Distintos casos de uso para recomendación. Cada uno aprende algo distinto de los datasets, por ejemplo, recomendaciones de ítems similares o recomendaciones para usuarios. El equivalente a un algoritmo de aprendizaje de Machine Learning.
- Solution (Solución): El modelo que utilizaremos para realizar predicciones.
- Solution Version (Versión de Solución): El resultado de la solución después del entrenamiento del modelo. De acuerdo a los conceptos de ML, es el modelo que ya aprendió de los datos y puede entregar recomendaciones.
- Campaign (Campaña): Es como Amazon Personalize llama a un modelo en línea que entrega recomendaciones en una modalidad request-response, como una API.
Actualización 05/2023: Actualmente Amazon Personalize te permite crear recomendadores por dominio, para lo cual puedes crear un Domain dataset group (Video on demand – Ecommerce) o un Custom datasest groups, esta demo esta basada en el segundo.
El proyecto ??: Recomendaciones personalizadas de Anime
Este primer episodio está basado en Personalize POC Guide, utilizaremos el servicio de Amazon Personalize para entrenar un modelo de recomendaciones con los datos de Anime Recommendation Database 2020 de kaggle, utilizando las interacciones que han tenido los usuarios con los animes y, otros datos disponibles como Genero y Calificación.
Pre-requisitos
- Una Cuenta AWS
- Conocimientos básicos en Python.
Manos a la obra ? ???
Paso 1: Crear una instancia de Notebook de Amazon SageMaker
Amazon SageMaker Notebook es una instancia de Amazon Elastic Compute Cloud (Amazon EC2) completamente administrada con los paquetes necesarios para crear un Notebooks de Jupyter
Para crearlo sigue el Paso 1 y 2 del tutorial Crear, entrenar e implementar un modelo de Machine Learning, en el Paso 2 selecciona la instancia ml.t3.medium.
Recuerda detener el notebook de SageMaker cuando no lo estes usando. No perderás información, liberas el recurso sin gastar innecesariamente.
Paso 2: Agrega la política al AWS Identity and Access Management (IAM) al IAM Role de Amazon SageMaker para interactuar con Amazon Personalize
Los permisos al notebook de SageMaker permitirán crear el rol IAM para interactuar con Amazon Personalize y Amazon Simple Storage Service (S3).
- En el lado izquierdo del panel de la consola de SageMaker, selecciona Bloc de notas -> Instancias de bloc de notas.
- Selecciona la instancia creada en el paso anterior y en Permisos y cifrado selecciona el hyperlink del ARN del rol de IAM (ver Fig.3), se abrirá una nueva página de IAM.
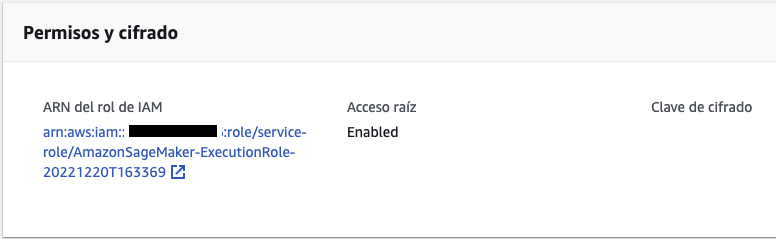
Fig. 3 ARN del rol de IAM hyperlink.
- En la nueva página, selecciona Añadir permisos y luego Crear política insertada.
- Selecciona JSON, copia y pega el texto a continuación y sustituye TU-ID-CUENTA por el ID de tu cuenta:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"iam:CreateRole",
"iam:AttachRolePolicy"
],
"Resource": "arn:aws:iam::TU-ID-CUENTA:role/*"
}
]
}
- Selecciona Revisar la política, escribe el Nombre IAM-W-ROLE, y selecciona Crear una política.
- Selecciona nuevamente Añadir permisos y esta vez Asociar políticas.
- En el buscador escribe AmazonPersonalizeFullAccess, presiona la tecla Enter y selecciona el cuadrado de la política.
- Quita el filtro anterior, escribe en el buscador AmazonS3FullAccess, presiona la tecla Enter y selecciona el cuadrado de la política.
- Selecciona Asociar políticas.
- Al finalizar deberías ver 5 políticas en el IAM rol (Fig. 4).
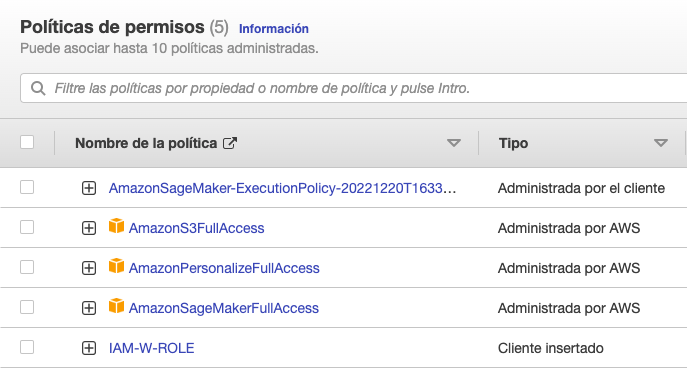
Fig. 4 Políticas en IAM rol.
Paso 3: Clonar el repositorio de GitHub y descargar el dataset
Abre JupyterLab en el jupyter notebook creado en el Paso 1, luego accede a la terminal y copia lo siguiente:
cd SageMaker/
git clone https://github.com/aws-samples/aws-recomendador-anime
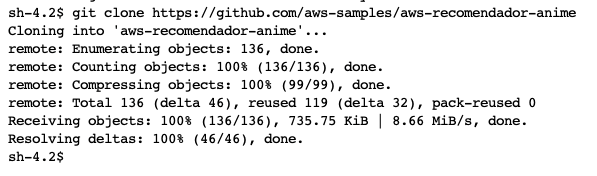
Fig. 5 Clonación de repositorio exitosa.
Una vez listo (Fig. 5), podrás acceder al código de este proyecto (Fig. 6).
Fig. 6 Carpeta aws-recomendador-anime
Para descargar los datos de kaggle necesitas un API Token, genéralo siguiendo estos pasos:
- Crear una cuenta en https://www.kaggle.com. Es una buena fuente de datasets para seguir experimentando en futuros proyectos.
- Ve al menú de la cuenta: https://www.kaggle.com/<username>/account
- Descarga el API Token (json) en “Create New API Token” (Fig. 7).

Fig. 7 Descargar API Token de kaggle
Sube el archivo kaggle.json a la carpeta /home/ec2-user/.kaggle del notebook de SageMaker:
- Arrastra el archivo a la ventana del notebook de SageMaker y déjalo en la carpeta recomendador-de-anime.
Fig. 8 kaggle.json en el notebook de SageMaker
- Abre el terminal y ejecuta las siguiente líneas:
mv aws-recomendador-anime/recomendador-de-anime/kaggle.json /home/ec2-user/.kaggle
chmod 600 /home/ec2-user/.kaggle/kaggle.jsonLuego, accede a la carpeta aws-recomendador-anime -> recomendador-de-anime y abre el notebook 01_Descarga_Dataset.ipynb y ejecuta los comandos para descargar el dataset en la carpeta anime-data (Fig. 9):
!pip3 install kaggle
data_dir = "anime-data"
dataset_name = "hernan4444/anime-recommendation-database-2020"
!mkdir $data_dir
!kaggle datasets download -p {data_dir}/ --unzip {dataset_name}
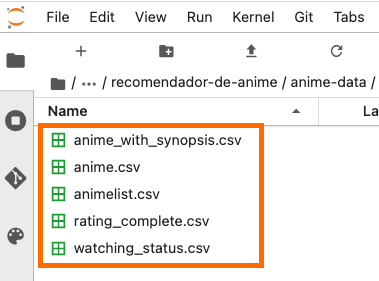
Fig.9 Dataset anime-recommendation-database-2020
Paso 4: Preparar el dataset y crear un DatasetGroup
Emplea el notebook 02_Exploración_Prepariación.ipynb.
En la preparación se crea la columna TIMESTAMP, el momento de la interacción, un campo necesario para el dataset “interaction”.
Luego se crea el Dataset Group, una agrupación lógica de todos los recursos del proyecto de Personalize (dataset, modelos, endpoints).Es posible crear varios Dataset Groups, uno para cada aplicación. Por ejemplo, un Dataset Groups para una aplicación de recomendaciones de vídeos y otro para una que recomienda audiolibros.
El Dataset Group se crea con estos comandos:
create_dataset_group_response = personalize.create_dataset_group( name = "personalize-anime" ) dataset_group_arn = create_dataset_group_response['datasetGroupArn']
El resultado en la consola:
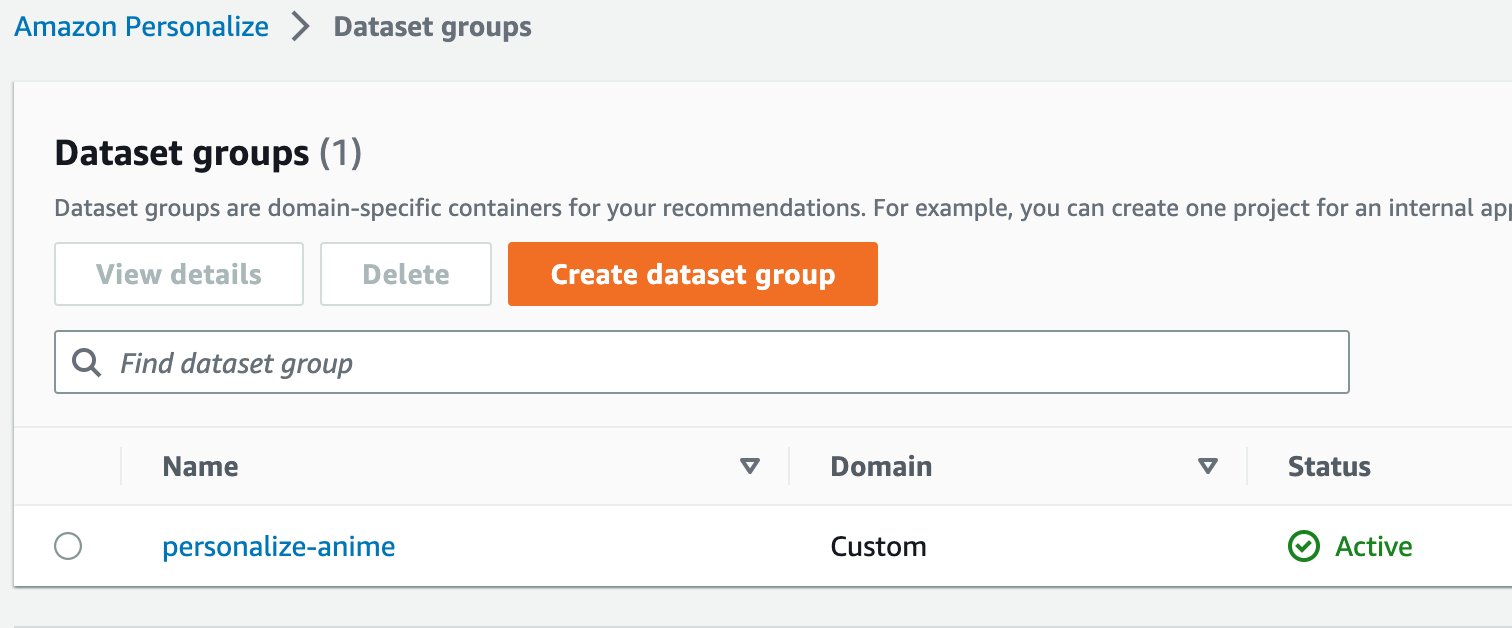
Fig.10 DataSet groups en la consola
Paso 5: Creación de los conjuntos de datos y el esquema
El esquema en Personalize permite analizar la estructura, define las columnas y el tipo de dato.
Para el recomendador de anime utilizaremos dos conjuntos de datos:
- Interaction DataSet
- Items DataSet
En este proyecto no vamos a emplear el User DataSet.
Interaction DataSet
Corresponde a los datos del archivo interactions.csv, creado en el paso anterior, con las columnas:
- USER_ID (ID del usuario – Requerido)
- ITEM_ID (ID del anime – Requerido)
- TIMESTAMP (cuando ocurrió esta evaluación – Requerido)
- EVENT_VALUE (valor obtenido por el anime – Opcional).
- EVENT_TYPE (tipo del valor, en este caso rating – Opcional)
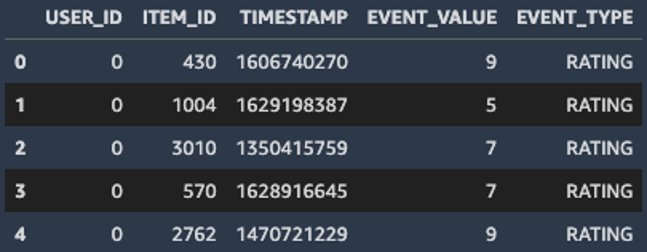
Fig.11 Interaction Dataset
El esquema se crea con los comandos:
interactions_schema = schema = {
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
},
{
"name": "EVENT_VALUE",
"type": "float"
},
{
"name": "EVENT_TYPE",
"type": "string"
},
],
"version": "1.0"
}
create_schema_response = personalize.create_schema(
name = "personalize-anime-interactions1",
schema = json.dumps(interactions_schema)
)
Items DataSet
Corresponde a los datos del archivo item-meta.csv con las columnas:
- ITEM_ID (ID del anime – Requerido)
- STUDIOS (estudio que lo creo – Opcional)
- YEAR (año de su lanzamiento -Opcional)
- GENRE (géneros – Opcional)
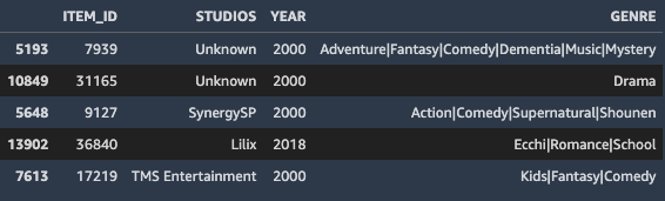
Fig.12 Items DataSets
En la creación del esquema los atributos adicionales deben tener categorical = True para que sean tomados en cuenta en el entrenamiento del modelo, estas características adicionales las podemos usar para crear filtros (ya hablaremos de los filtros).
El esquema se define con los comandos:
itemmetadata_schema = {
"type": "record",
"name": "Items",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "STUDIOS",
"type": "string",
"categorical": True
},
{
"name": "YEAR",
"type": "int",
},
{
"name": "GENRE",
"type": "string",
"categorical": True
},
],
"version": "1.0"
}
create_schema_response = personalize.create_schema(
name = "personalize-anime-item",
schema = json.dumps(itemmetadata_schema)
)
En la consola:
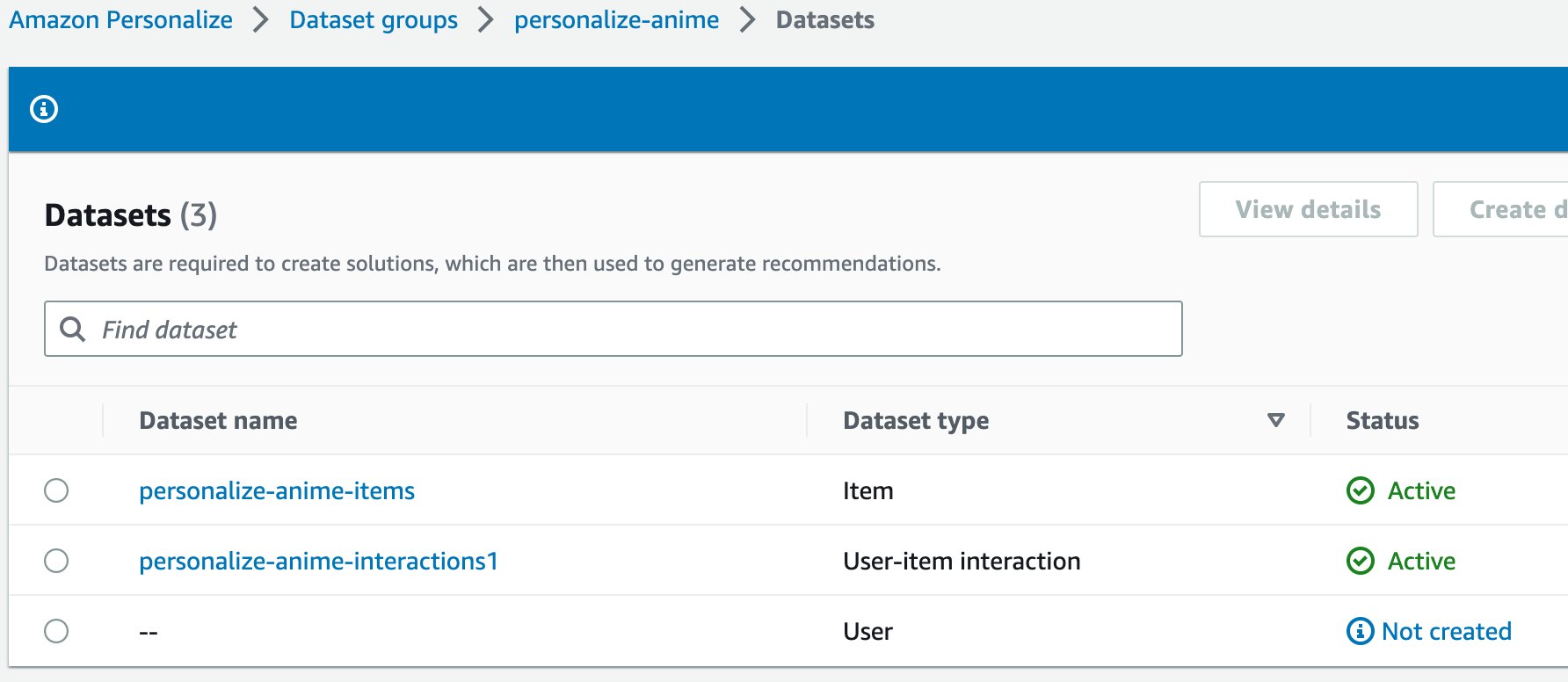
Fig.13 DataSets en la consola
Paso 6: importación de los datos para uso de Amazon Personalize.
Previa a la importación, los datos deben estar en el formato correcto (Formatear los datos) y deben estar en un bucket de Amazon S3 (Cargar a un bucket de S3).
La importación de los datos de forma masiva se hace creando un import jobs:
create_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-anime-item-import",
datasetArn = items_dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket_name, itemmetadata_filename)
},
roleArn = role_arn
)
dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']Paso 7: Creación de la solución: modelo de recomendación de anime
Fig.14 La solución: modelo de recomendación de anime.
La solución (Fig. 14) la creamos en el notebook 03_Creación_Soluciones.ipynb.
Pasos a seguir:
- Seleccionar los recipes para las soluciones:
Personalize proporciona 3 tipos de recipes:
User personalization: recomendaciones para un usuario (USER_ID) específico.
Personalized Ranking: reordenar un listado de ítems (ITEM_ID) de acuerdo a las recomendaciones de un usuario (USER_ID) específico.
Similar items: Items Similares a un item (ITEM_ID) específico.
Las soluciones se crean con los comandos:
user_personalization_create_solution_response = personalize.create_solution( name = "personalize-anime-userpersonalization", datasetGroupArn = dataset_group_arn, recipeArn = user_personalization_recipe_arn ) user_personalization_solution_arn = user_personalization_create_solution_response['solutionArn']
Se repite para cada solución.
Resultado en la consola:
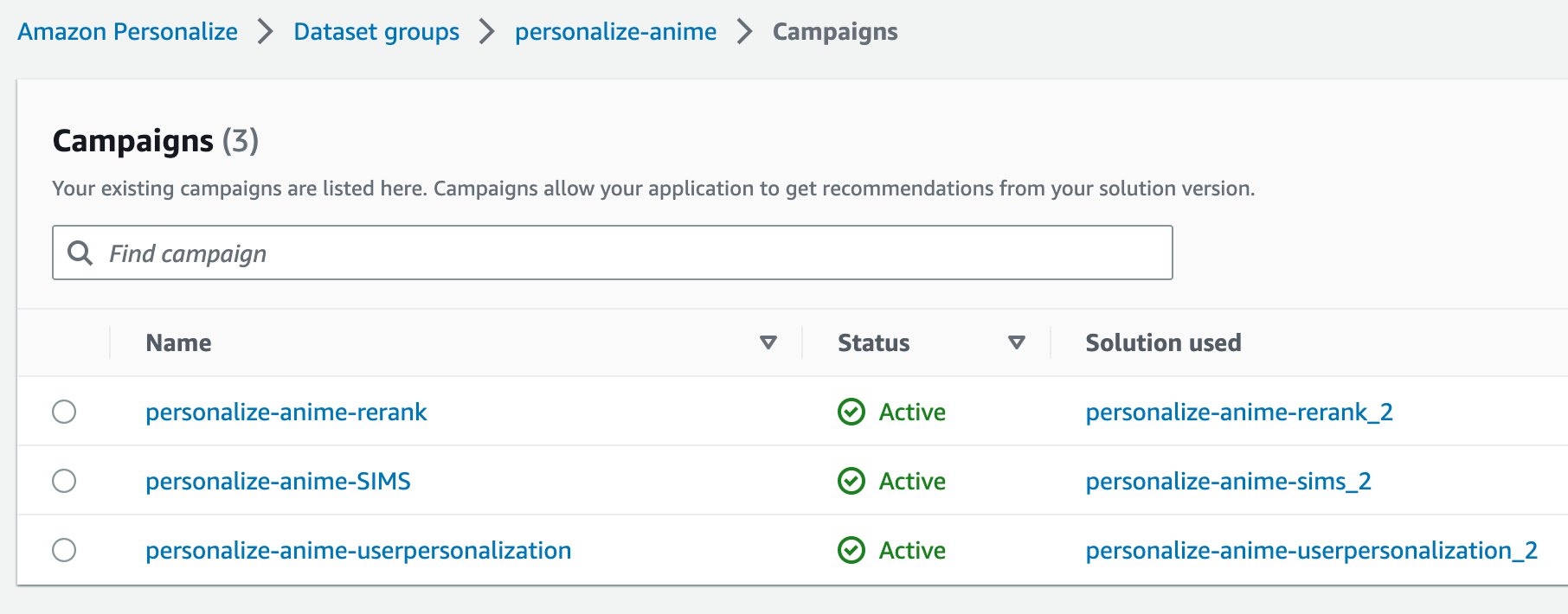
Fig.15 Soluciones en la consola
- Creación de versión de la solución (entrenar un modelo de aprendizaje automático):
Creamos una versión de la solución para cada recipe con los siguientes comandos:
user_personalization_create_solution_version_response = personalize.create_solution_version( solutionArn = user_personalization_solution_arn ) user_personalization_solution_version_arn = user_personalization_create_solution_version_response['solutionVersionArn']
Puede tardar más de una hora, el código tiene un loop donde informa el estado cada 60 segundos.
Finaliza con el siguiente resultado:

Fig.16 Construcción exitosa de la versión del modelo.
Nota: La solución admite HPO y AutoML y el entrenamiento admite training_mode.
Las versiones por campaña en la consola:
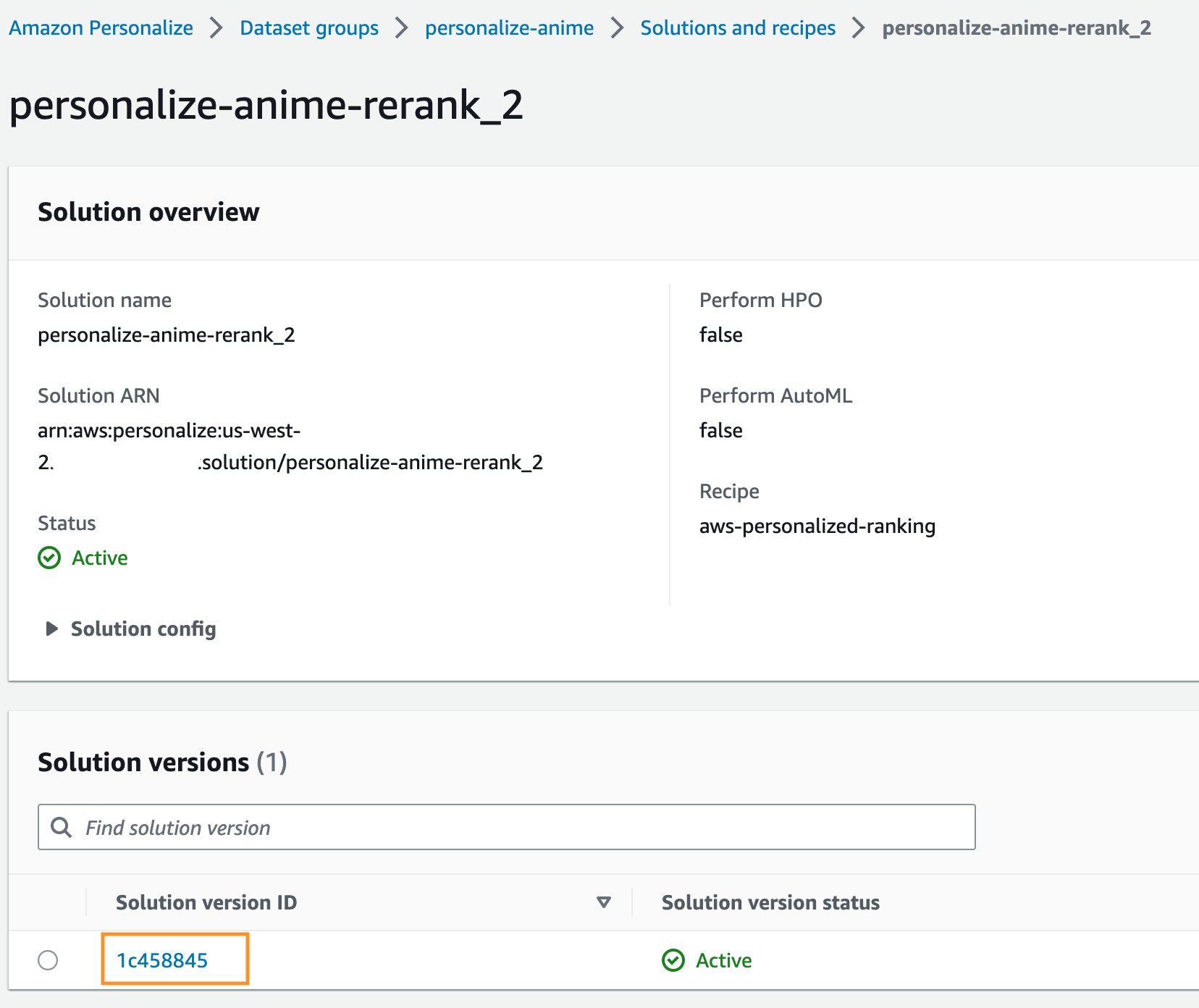
Fig.16 Construcción exitosa de la versión del modelo en la consola.
- Evaluar la versión de la solución:
Para evaluar que versión es la más adecuada Personalize separa el dataset en entrenamiento y pruebas.
Las métricas las obtienes para cada recipe con estos comandos:
user_personalization_solution_metrics_response =
personalize.get_solution_metrics(
solutionVersionArn = userpersonalization_solution_version_arn
)['metrics']
Al finalizar el notebook 03_Creación_Soluciones.ipynb, veremos el cuadro con la evaluación (Fig. 17):
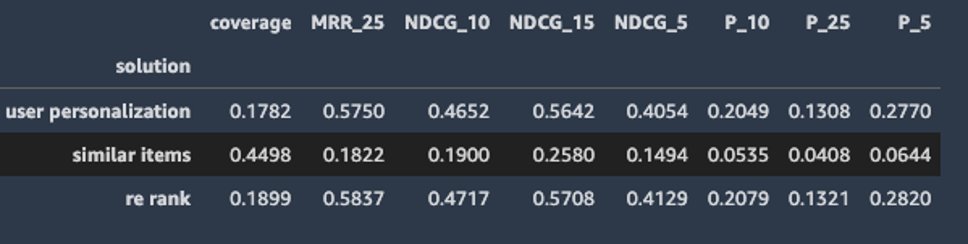
Fig.17 Evaluación de la versión del modelo entrenado.
Para visualizar las métricas en la consola debes acceder a cada versión de solución :
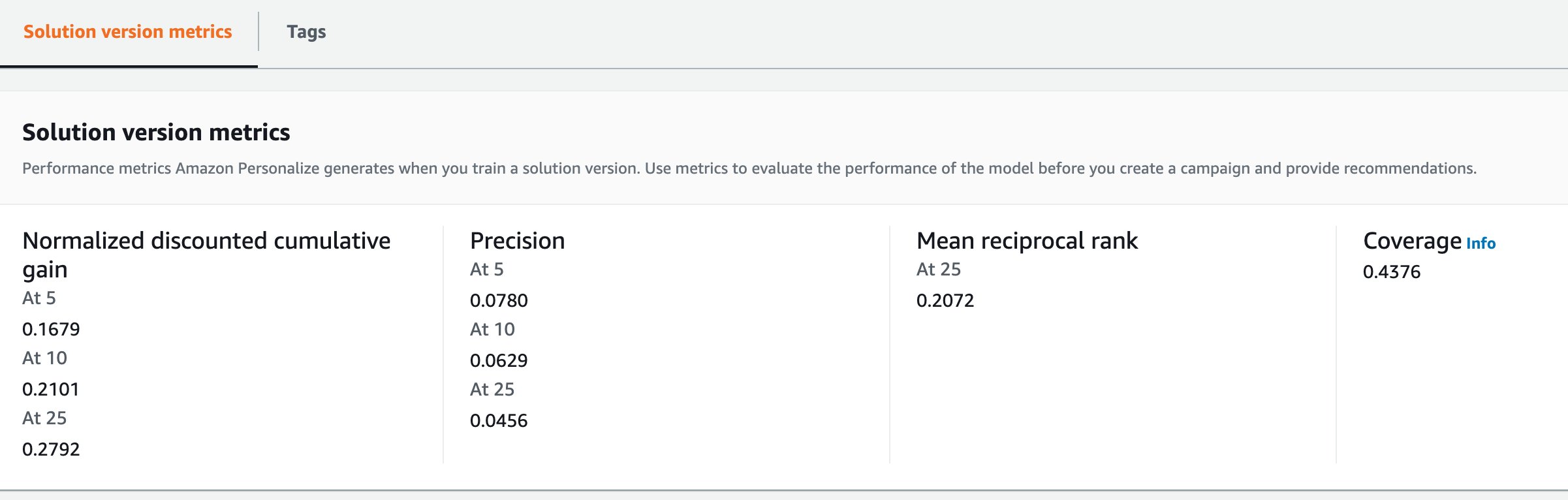
Fig.18 Evaluación de la versión del modelo entrenado en la consola.
- Coverage es el porcentaje de los items que el modelo está recomendando en general. Por ejemplo, en SIMS, tiene un coverage de 45% es decir hay un 55% de items que no están siendo recomendados.
- Precision 5, 10 y 25 son la precisión de las recomendaciones. Por ejemplo, si recomienda 10 items y el usuario interactuó con 2, mi precisión a 10 es de 20%.
- Normalized discount gain 5,10 y 25 es muy similar a precisión, pero el orden importa, y hay incentivo por entregar las recomendaciones en orden real de preferencia.
Para mejorar el coverage el modelo debe incorporar los ítems nuevos y los antiguos con poca preferencia, esto lo puedes modificar con el parámetro campaignConfig al crear la campaña.
Más Información en create_campaign() de Boto3 Amazon Personalize Documentation.
Paso 8: Crear un endpoint de inferencias (Campaña)
Entrenada la Solution Version, creamos la campaña para cada recipe y las desplegamos ejecutando el código en el notebbok 04_Desplegando_campanas.ipynb .
Los comandos que crean las campañas son:
sims_create_campaign_response = personalize.create_campaign( name = "personalize-anime-SIMS", solutionVersionArn = sims_solution_version_arn, minProvisionedTPS = 1 )sims_campaign_arn = sims_create_campaign_response['campaignArn']
Nota: minProvisionedTPS = 1 corresponde a la cantidad de TPS (transacciones por segundo) que este endpoint podrá soportar, este dimensionamiento dependerá del volumen de recomendaciones que queramos entregar.
Nota: en el notebook hay un loop que consulta el estado hasta que están creadas.
El estado de las Solution Version en la consola:
Fig.19 Campañas creadas en la consola
Paso 9: Creación del Event Tracker
Para que el modelo de recomendaciones realice sugerencias más acertadas se debe interactuar con él, alimentarlo con las preferencias de los usuarios. Este proceso hará que el modelo aprenda y actualice las recomendaciones mientras se usa la aplicación, mejorando la relevancia de las recomendaciones no solo para el usuario que interactúa, sino que también para usuarios nuevos o con gustos parecidos.
Las interacciones pueden ser compras, en el caso de una tienda, o visualizar el contenido en una plataforma de VoD, que es el caso de uso para el proyecto de recomendaciones personalizadas de anime. Otra forma de alimentar al modelo de recomendaciones, es calificando de acuerdo a tus gustos.
En Personalize puedes incorporar estas nuevas interacciones utilizando Event Tracker, lo creamos con los comandos en el notebook 05_Probando_Recomendaciones.ipynb:
response = personalize.create_event_tracker( name='AnimeTracker', datasetGroupArn=dataset_group_arn )
El resultado en la consola:
Fig.20 Anime Tracker en la consola
Paso 10: Creación de filtros
Los filtros permiten entregar recomendaciones bajo una condición del ítem dataset. En este proyecto se puede filtrar por año, estudio o géneros, pero solo crearemos el filtro de géneros.
Se crea con estos comandos en el notebook 05_Probando_Recomendaciones.ipynb:
createfilter_response = personalize.create_filter(
name=genre,
datasetGroupArn=dataset_group_arn,
filterExpression='INCLUDE ItemID WHERE Items.GENRE IN ("'+ genre +'")'
)
Vista en la consola:
Fig.21 Filtros en la consola.
Paso 11: Obtener recomendaciones.
En el notebook 05_Probando_Recomendaciones están las funciones necesarias para la comunicación con Personalize y probar la solución.
- Recomendaciones por campañas (SIMS – Filters – User personalization) :
Para recibir las recomendaciones por anime, usamos get_recommendations() de la librería Boto3 Amazon Personalize Run time, con la siguiente sintaxis:
get_recommendations_response = personalize_runtime.get_recommendations( campaignArn = campaign_arn, itemId = str(anime_ID), )
Si la campaña es de personalización de usuario, pasamos el user_id:
get_recommendations_response = personalize_runtime.get_recommendations( campaignArn = userpersonalization_campaign_arn, userId = str(user_id), )
Para recibir las recomendaciones filtradas, agregamos filterArn:
get_recommendations_response = personalize_runtime.get_recommendations( campaignArn = userpersonalization_campaign_arn, userId = str(user_id), filterArn = filter_arn )
- Actualizar datos con Event Tracker:
Para ingresar nuevos datos, por ejemplo, calificar un nuevo anime, empleamos la función put_events() de la librería Boto3 Amazon personalize events:
personalize_events.put_events(
trackingId = TRACKING_ID,
userId= str(USER_ID),
sessionId = session_ID,
eventList = [{
'sentAt': int(time.time()),
'eventType': str(EVENT_TYPE),
'eventValue': int(EVENT_VALUE),
'properties': event_json
}]
)
Te invito a explorar el notebook 05_Probando_Recomendaciones en la instancia de SageMaker, las funciones están listas para que hagas volar tu imaginación.
Paso 12: Borrar los recursos de la cuenta de AWS.
Estos pasos son opcionales, si tu intención es continuar con la construcción de la aplicación web, puedes mantener el notebook de Sagemaker en estado Stopped (Acciones -> Detener) , lo vamos a utilizar en el próximo episodio de esta serie.
De lo contrario, sigue los siguientes pasos:
- Borrar recursos de Amazon Personalize: sigue los pasos del notebookipynb.
- Borrar el notebook de Amazon SageMaker: antes de proceder, copia el nombre del IAM Role que se creó con el notebook, es necesario en el siguiente paso. Ahora, con el notebook en estado Stopped, selecciona Acciones ->
- Borrar AWS IAM Role: en la consola de AWS IAM en el menú de la izquierda selecciona Roles, y pega en el buscador el nombre del role que copiaste en el paso anterior, presiona la tecla Enter, selecciónalo y luego
Conclusión:
En este episodio creaste un modelo de recomendaciones de anime utilizando la data histórica del dataset Recommendation Database 2020 de kaggle.
No fue necesario aplicar conocimientos de AI/ML para crear este modelo de recomendaciones y, con esta experiencia ya eres capaz de crear otros tipos de recomendadores, solo debes tener un dataset y usar el repositorio de github empelado acá como base.
Si quieres aprender más sobre Amazon Personalize puedes revisar los siguientes recursos:
- Developer Guide
- Boto3 Amazon Personalize Documentation
- Boto3 Amazon Personalize Events Documentation
- Boto3 Amazon Personalize Runtime Documentation
- Amazon Personalize Samples
- Caso de uso exitoso en LATAM
En la próxima entrega de esta serie aprenderemos cómo disponibilizar un modelo de recomendación de anime en una API REST, para invocar el modelo de recomendación que creamos en este blog.
Acerca de la autora
 Elizabeth Fuentes Leone es Developer Advocate en AWS con experiencia en Data Analytics y Machine Learning. Le encanta ayudar a los desarrolladores a aprender mientras meten las manos construyendo.
Elizabeth Fuentes Leone es Developer Advocate en AWS con experiencia en Data Analytics y Machine Learning. Le encanta ayudar a los desarrolladores a aprender mientras meten las manos construyendo.