Orientación para la integración y el análisis de datos multimodales y multiómicos en AWS
Información general
Funcionamiento
Arquitectura
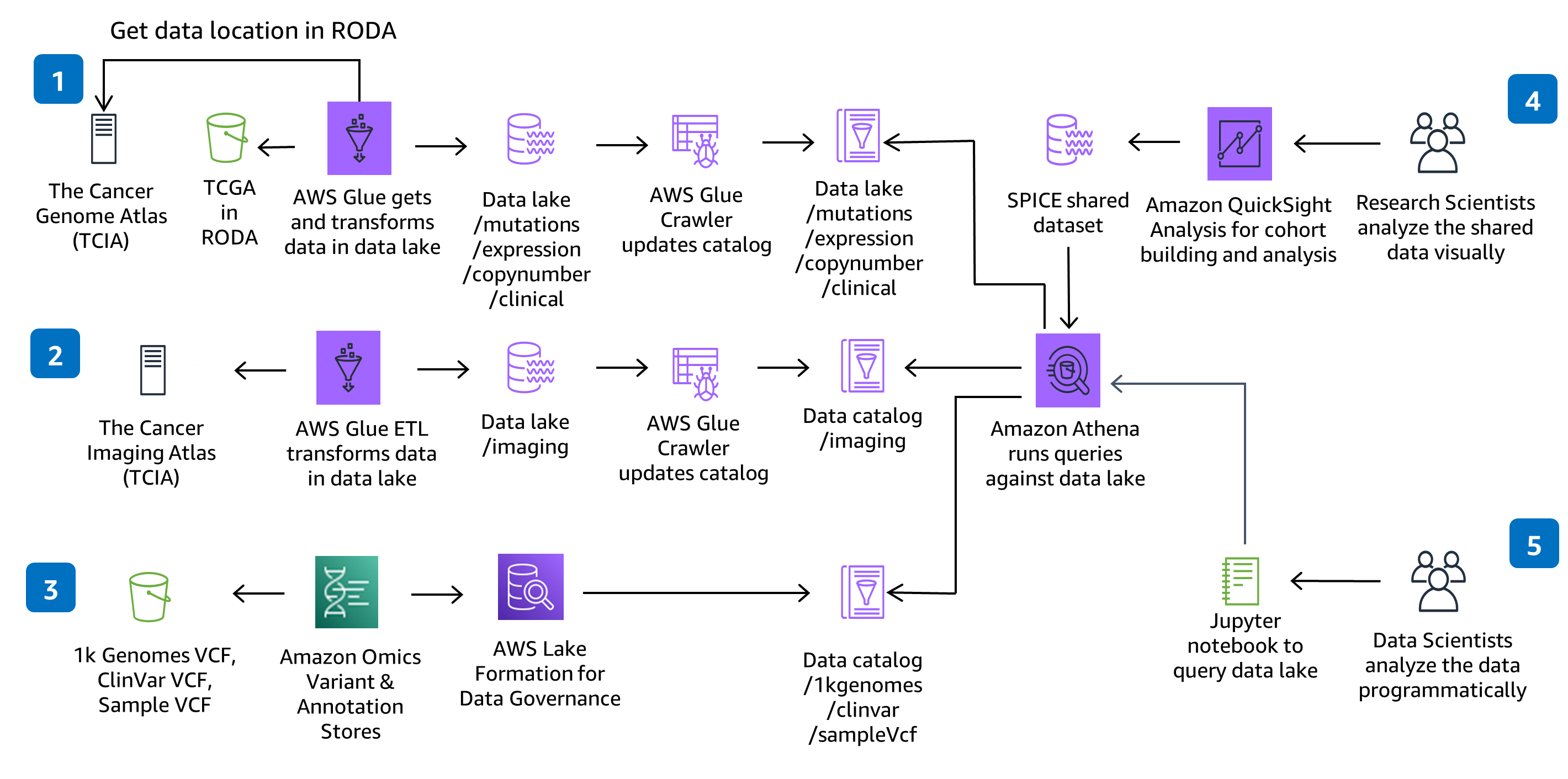
Prepare datos genómicos, clínicos, de mutaciones, de expresión y de imágenes para el análisis a gran escala y para realizar consultas en un lago de datos.
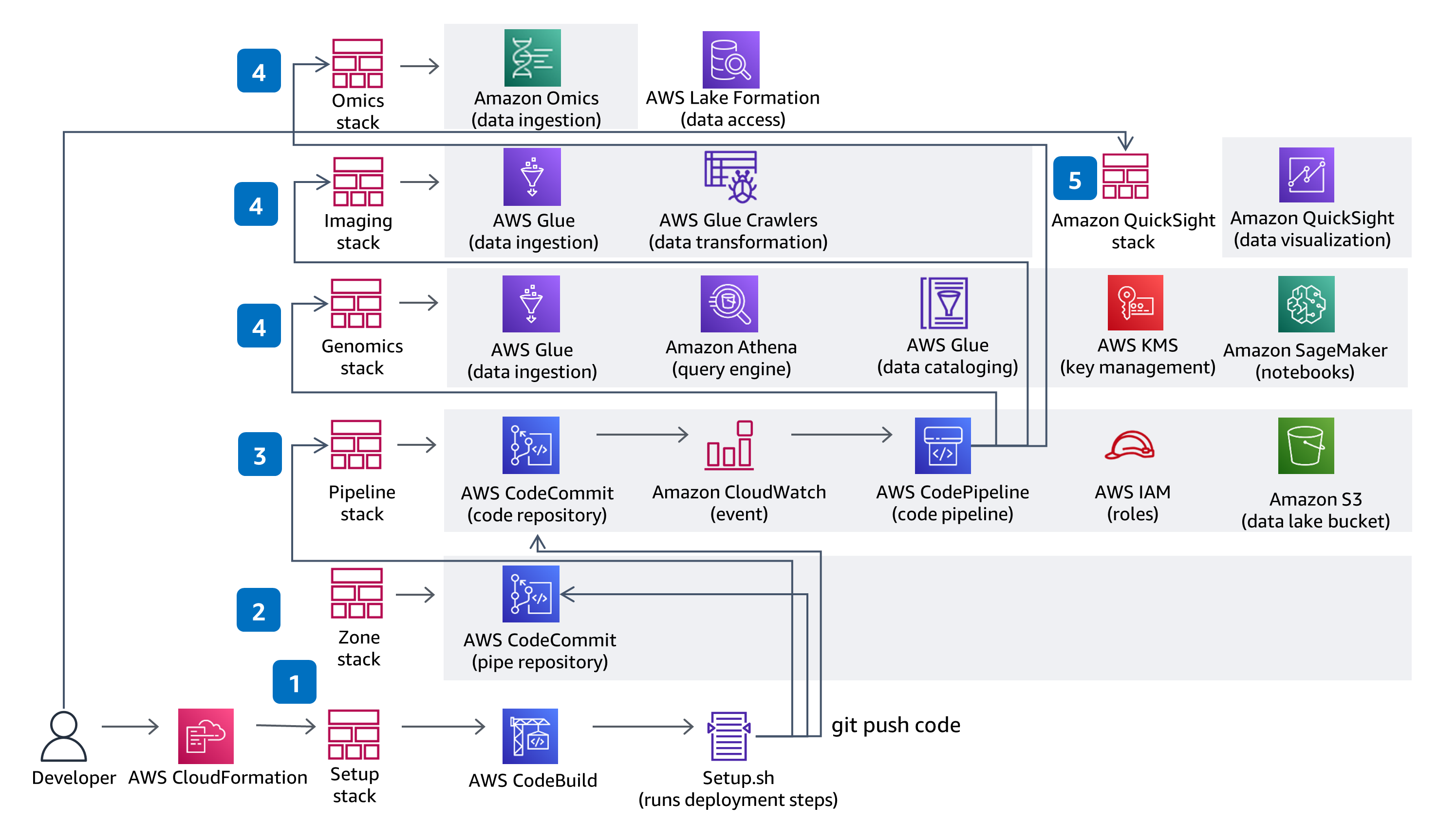
CI/CD
Prepare datos genómicos, clínicos, de mutaciones, de expresión y de imágenes para el análisis a gran escala y para realizar consultas en un lago de datos.
Pilares de Well-Architected
El diagrama de arquitectura mencionado es un ejemplo de una solución que se creó teniendo en cuenta las prácticas recomendadas de Well-Architected. Para tener completamente una buena arquitectura, debe seguir todas las prácticas recomendadas de Well-Architected posibles.
En esta orientación, se utilizan CodeBuild y CodePipeline para compilar, empaquetar y desplegar todo lo necesario en la solución a fin ingerir y almacenar archivos de llamadas de variantes (VCF) y trabajar con datos multimodales y multiómicos de los conjuntos de datos del Atlas del Genoma del Cáncer (TCGA) y el Atlas de Imágenes Oncológicas (TCIA). Se demuestra la ingesta y el análisis de datos genómicos sin servidor mediante un servicio completamente administrado: Amazon Omics. Los cambios de código que se realicen en el repositorio de CodeCommit de la solución se desplegarán a través de la canalización de despliegue de CodePipeline proporcionada.
En esta orientación, se utiliza el acceso basado en roles con IAM y todos los buckets tienen el cifrado habilitado, son privados y bloquean el acceso público. El catálogo de datos en AWS Glue cuenta con el cifrado habilitado y todos los metadatos escritos por AWS Glue en Amazon S3 se encuentran cifrados. Todos los roles se definen con privilegios mínimos y todas las comunicaciones entre servicios permanecen en la cuenta del cliente. Los administradores pueden controlar el acceso al cuaderno de Jupyter, los datos de almacenes de variantes de Amazon Omics y al catálogo de AWS Glue con Lake Formation, y el acceso a los datos de Athena, el cuaderno de SageMaker y QuickSight con los roles de IAM proporcionados.
AWS Glue, Amazon S3, Amazon Omics y Athena no tienen servidor y escalarán el rendimiento del acceso a los datos a medida que aumente su volumen de datos. AWS Glue aprovisiona, configura y escala los recursos necesarios para ejecutar sus trabajos de integración de datos. Athena no tiene servidor, por lo que puede realizar consultas en sus datos con rapidez sin tener que configurar ni administrar servidores ni almacenes de datos. El almacenamiento en memoria SPICE de QuickSight escalará su exploración de datos a miles de usuarios.
Mediante el uso de tecnologías sin servidor, solo aprovisiona los recursos exactos que utiliza. Cada trabajo de AWS Glue aprovisionará un clúster de Spark bajo demanda para transformar los datos y desaprovisionar los recursos cuando termine. Si elige agregar conjuntos de datos del TCGA nuevos, puede agregar trabajos de AWS Glue y rastreadores de AWS Glue nuevos que también predicen recursos bajo demanda. Athena ejecuta consultas de manera simultánea automáticamente, por lo que la mayoría de los resultados se obtiene en cuestión de segundos. Amazon Omics optimiza el rendimiento de las consultas de variantes a escala al transformar archivos en Apache Parquet.
Mediante el uso de tecnologías sin servidor que escalan bajo demanda, solo paga por los recursos que utiliza. Para optimizar aún más los costos, puede detener los entornos de cuadernos en SageMaker cuando no se utilicen. El panel de QuickSight también se despliega a través de una plantilla de CloudFormation independiente, por lo que si no tiene la intención de utilizar el panel de visualización, puede optar por no desplegarlo a fin de ahorrar costos. Amazon Omics optimiza el costo de almacenamiento de datos de variantes a escala. Los costos de las consultas vienen determinados por la cantidad de datos analizados por Athena y pueden optimizarse al escribir las respectivas consultas.
Al utilizar ampliamente los servicios administrados y el escalado dinámico, minimiza el impacto ambiental de los servicios de backend. Un componente fundamental para la sostenibilidad es maximizar el uso de las instancias de servidores de cuadernos. Debería detener los entornos de cuadernos cuando no se utilicen.
Consideraciones adicionales
Transformación de datos
En esta arquitectura se eligió AWS Glue para el proceso de extracción, transformación y carga (ETL) necesario a fin de ingerir, preparar y catalogar los conjuntos de datos en la solución para consultas y rendimiento. Puede agregar trabajos de AWS Glue y rastreadores de AWS Glue nuevos para ingerir conjuntos de datos nuevos del Atlas del Genoma del Cáncer (TCGA) y el Atlas de Imágenes Oncológicas (TCIA), según sea necesario. También puede agregar trabajos y rastreadores nuevos para ingerir, preparar y catalogar sus propios conjuntos de datos.
Análisis de datos
En esta arquitectura, se eligieron los cuadernos de SageMaker a fin de proporcionar un entorno de cuadernos de Jupyter para el análisis. Puede agregar cuadernos nuevos al entorno existente o crear entornos nuevos. Si prefiere RStudio a los cuadernos de Jupyter, puede utilizar RStudio en Amazon SageMaker.
Visualización de datos
En esta arquitectura, se eligió QuickSight a fin de proporcionar paneles interactivos para la visualización y exploración de datos. La configuración del panel de QuickSight se realiza a través de una plantilla de CloudFormation independiente, por lo que si no tiene la intención de utilizar el panel, no es necesario que lo aprovisione. En QuickSight, puede crear su propio análisis, explorar filtros o visualizaciones adicionales y compartir conjuntos de datos y análisis con colegas.
Despliegue con confianza
Este repositorio crea un entorno escalable en AWS a fin de preparar datos genómicos, clínicos, de mutaciones, de expresión y de imágenes para el análisis a gran escala y realizar consultas interactivas en un lago de datos. La solución muestra cómo 1) utilizar el almacén de variantes y el almacén de anotaciones de HealthOmics para almacenar datos de variantes genómicas y datos de anotaciones, 2) proporcionar canalizaciones de ingesta de datos sin servidor para la preparación y catalogación de datos multimodales, 3) visualizar y explorar datos clínicos a través de una interfaz interactiva y 4) ejecutar consultas analíticas interactivas en un lago de datos multimodales mediante Amazon Athena y Amazon SageMaker.
Se proporciona una guía detallada para experimentar y utilizar dentro de su cuenta de AWS. Se examina cada etapa de la creación de la guía, incluido el despliegue, el uso y la limpieza, con el fin de prepararla para su despliegue.
El código de muestra es un punto de partida. Está validado por el sector, es prescriptivo pero no definitivo, y le permite profundizar en su funcionamiento para que le sea más fácil empezar.
Contenido relacionado
Orientación
Guía para el análisis de datos multimodales con servicios de IA y ML para el sector sanitario en AWS
En esta guía, se muestra cómo configurar un marco integral para analizar los datos multimodales sanitarios y de ciencias biológicas (HCLS).
Colaboradores
Descargo de responsabilidad
¿Ha encontrado lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios