¿Qué es una canalización de datos?
¿Qué es una canalización de datos?
Una canalización de datos consiste en una serie de pasos de procesamiento dirigidos a preparar los datos empresariales para llevar a cabo análisis. Las organizaciones tienen un gran volumen de datos de diversas fuentes, como aplicaciones, dispositivos de Internet de las cosas (IoT) y otros canales digitales. Sin embargo, los datos sin procesar carecen de utilidad; se deben trasladar, ordenar, filtrar, reformatear y analizar para adquirir inteligencia empresarial. Una canalización de datos se compone de varias tecnologías encargadas de verificar, resumir y encontrar patrones en los datos que sirvan de base para fundamentar las decisiones empresariales. Las canalizaciones de datos bien organizadas facilitan diversos proyectos de big data, como las visualizaciones de datos, los análisis exploratorios de datos y las tareas de machine learning.
¿Qué beneficios ofrece una canalización de datos?
Las canalizaciones de datos le permiten integrar datos de diferentes orígenes y transformarlos para su análisis. Eliminan silos de datos y hacen que su análisis de datos sea más confiable y preciso. A continuación, se muestran algunos beneficios clave de una canalización de datos.
Calidad de los datos mejorada
Las canalizaciones de datos limpian y refinan los datos sin procesar, lo que mejora su utilidad para los usuarios finales. Estandarizan formatos para campos como fechas y números de teléfono, al mismo tiempo que revisan si hay errores de entrada. También eliminan la redundancia y garantizan una calidad de datos coherente en toda la organización.
Procesamiento de datos eficiente
Los ingenieros de datos tienen que llevar a cabo muchas tareas repetitivas al transformar y cargar datos. Las canalizaciones de datos les permiten automatizar las tareas de transformación de datos para que así pueda centrarse en la mejor información empresarial. Las canalizaciones de datos también ayudan a los ingenieros de datos a procesar más rápidamente los datos sin procesar que pierden valor con el tiempo.
Integración de datos completa
Una canalización de datos hace uso de las funciones de transformación de datos para integrar conjuntos de datos de orígenes dispares. Puede comparar los valores de los mismos datos de diversos orígenes y corregir incoherencias. Por ejemplo, imagine que el mismo cliente hace una compra en su plataforma de comercio electrónico y su servicio digital. Sin embargo, escribe mal su nombre en el servicio digital. La canalización puede arreglar esta incoherencia antes de enviar los datos para su análisis.
¿Cómo funciona una canalización de datos?
Del mismo modo que una canalización de agua lleva el agua del embalse a su grifo, una canalización de datos lleva los datos desde el punto de recopilación hasta el almacenamiento. Una canalización de datos extrae datos de un origen, hace cambios y, después, los guarda en un destino específico. Explicamos los componentes fundamentales de la arquitectura de canalización de datos a continuación.
Orígenes de datos
Un origen de datos puede ser una aplicación, un dispositivo u otra base de datos. Orígenes dispares pueden enviar datos a la canalización. La canalización también puede extraer puntos de datos con una llamada a la API, un webhook o un proceso de duplicación de datos. Puede sincronizar la extracción de datos para el procesamiento en tiempo real o recopilar datos en intervalos programados de sus orígenes de datos.
Transformaciones
A medida que los datos sin procesar fluyen a través de la canalización, van cambiando a fin de ser más útiles para la inteligencia empresarial. Las transformaciones son operaciones, como, por ejemplo, la clasificación, el cambio de formato, la deduplicación, la verificación y la validación, que cambian datos. La canalización puede filtrar, resumir o procesar datos para que cumplan sus requisitos de análisis.
Dependencias
Puesto que los cambios tienen lugar de forma secuencial, pueden existir dependencias específicas que reduzcan la velocidad de los datos en movimiento en la canalización. Hay dos tipos principales de dependencias, técnicas y empresariales. Por ejemplo, si la canalización tiene que esperar a que una cola central se llene antes de proceder, se trata de una dependencia técnica. Por el contrario, si la canalización se tiene que pausar hasta que otra unidad empresarial comprare los datos, se trata de una dependencia empresarial.
Destinos
El punto de conexión de su canalización de datos puede ser un almacenamiento de datos, un lago de datos u otra aplicación de análisis de datos o inteligencia empresarial. A veces, también nos referimos al destino como un sumidero de datos.
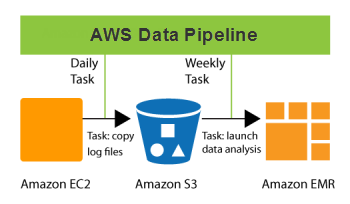
¿Qué tipos de canalizaciones de datos existen?
Hay dos tipos principales de canalizaciones de datos: canalizaciones de procesamiento de flujos y canalizaciones de procesamiento por lotes.
Canalizaciones de procesamiento de flujos
Un flujo de datos es una secuencia progresiva y continua de paquetes de datos de tamaño pequeño. Suele representar una serie de eventos que tiene lugar durante un periodo determinado. Por ejemplo, un flujo de datos podría mostrar datos de sensores que contengan medidas de la última hora. Una sola acción, como una transacción financiera, también puede llamarse un evento. Las canalizaciones de flujos procesan una serie de eventos para un análisis en tiempo real.
Los datos de flujos requieren una baja latencia y una alta tolerancia a errores. Su canalización de datos debería poder procesar datos incluso si algunos paquetes de datos se pierden o llegan en un orden distinto al esperado.
Canalizaciones de procesamiento por lotes
Las canalizaciones de datos de procesamiento por lotes procesan y almacenan datos en grandes volúmenes o lotes. Son adecuados para tareas ocasionales de un alto volumen, como puede ser la contabilidad mensual.
La canalización de datos contiene una serie de comandos secuenciados. Cada comando se ejecuta en todo el lote de datos. La canalización de datos entrega la salida de un comando como la entrada del siguiente comando. Una vez completadas todas las transformaciones de datos, la canalización carga todo el lote en un almacenamiento de datos en la nube u otro almacén de datos similar.
Más información sobre el procesamiento por lotes »
¿Qué diferencia hay entre los datos de lotes y los datos de flujos?
Las canalizaciones de procesamiento por lotes se ejecutan de forma poco frecuente y, normalmente, durante las horas de menor demanda. Requieren una alta potencia informática durante el corto periodo en el que se ejecutan. Por el contrario, las canalizaciones de procesamiento de flujos se ejecutan continuamente, pero requieren poca potencia informática. En su lugar, necesitan conexiones de redes confiables y de baja latencia.
¿Qué diferencia hay entre las canalizaciones de datos y las canalizaciones de ETL?
Una canalización de extracción, transformación y carga (ETL) es un tipo especial de canalización de datos. Las herramientas de ETL extraen o copian datos sin procesar de múltiples orígenes y los almacenan en un área de ensayo. Transforman datos en el área de ensayo y los cargan en lagos de datos o almacenamientos.
No todas las canalizaciones de datos siguen la secuencia de ETL. Algunas pueden extraer los datos de un origen y cargarlo en otro sitio sin transformaciones. Otras canalizaciones de datos siguen una secuencia de extracción, carga y transformación (ELT), en la que extraen datos sin estructura y directamente los cargan en un lago de datos. Llevan a cabo cambios después de mover la información a almacenamientos de datos.
¿Cómo puede satisfacer AWS sus requisitos de canalizaciones de datos?
AWS Glue es un servicio de integración de datos sin servidor que facilita a los usuarios de análisis descubrir, preparar, mover e integrar datos de varias fuentes para el análisis, el aprendizaje automático y el desarrollo de aplicaciones.
- Puede descubrir y conectarse a más de 80 almacenes de datos diferentes.
- Puede administrar sus datos en un catálogo de datos centralizado.
- Los ingenieros de datos, los desarrolladores de ETL, los analistas de datos y los usuarios empresariales pueden usar AWS Glue Studio para crear, ejecutar y monitorear canalizaciones de ETL para cargar datos en lagos de datos.
- AWS Glue Studio ofrece interfaces de Visual ETL, Notebook y editor de código, de modo que los usuarios disponen de las herramientas adecuadas a sus habilidades.
- Con Interactive Sessions, los ingenieros de datos pueden explorar los datos, así como crear y probar trabajos con su IDE o portátil preferido.
- AWS Glue es sin servidor y se escala automáticamente bajo demanda, por lo que puede centrarse en obtener información de datos a escala de petabytes sin administrar la infraestructura.
Para empezar a usar AWS Glue, cree una cuenta de AWS.
Siguientes pasos con Data Pipeline
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages