Membuat model pembelajaran mesin secara otomatis
dengan Amazon SageMaker Autopilot
Amazon SageMaker adalah layanan yang dikelola sepenuhnya yang memberi setiap pengembang dan ilmuwan data kemampuan membangun, melatih, dan menerapkan model pembelajaran mesin (ML) dengan cepat.
Dalam tutorial ini, Anda akan membuat model pembelajaran mesin secara otomatis tanpa mengetik baris kode! Anda menggunakan Amazon SageMaker Autopilot, kapabilitas AutoML yang secara otomatis membuat model pembelajaran mesin klasifikasi dan regresi terbaik sementara visibilitas dan kontrol penuh diaktifkan.
Dalam tutorial ini, Anda akan belajar cara:
- Membuat Akun AWS
- Menyiapkan Amazon SageMaker Studio untuk mengakses Amazon SageMaker Autopilot
- Mengunduh dataset publik menggunakan Amazon SageMaker Studio
- Membuat eksperimen pelatihan dengan Amazon SageMaker Autopilot
- Menjelajahi berbagai tingkatan eksperimen pelatihan
- Mengidentifikasi dan menerapkan model performa terbaik dari eksperimen pelatihan
- Memprediksi dengan model yang diterapkan
Dalam tutorial ini, Anda akan mengisi peran sebagai pengembang yang bekerja di bank. Anda diminta untuk mengembangkan model pembelajaran mesin untuk memprediksi apakah nasabah akan mengajukan sertifikat deposito (CD). Model ini akan dilatih pada dataset pemasaran yang berisi informasi tentang demografi nasabah, tanggapan terhadap acara pemasaran, dan faktor eksternal.
| Tentang Tutorial ini | |
|---|---|
| Waktu | 10 menit
|
| Biaya | Kurang dari 10 USD |
| Kasus Penggunaan | Machine Learning |
| Produk | Amazon SageMaker |
| Audiens | Pengembang |
| Tingkat | Pemula |
| Terakhir Diperbarui | 12 Mei 2020 |
Langkah 1. Buat Akun AWS
Biaya lokakarya ini kurang dari USD 10. Untuk informasi selengkapnya, lihat Biaya Amazon SageMaker Studio.
Sudah memiliki akun? Masuk
Langkah 2. Amazon SageMaker Studio
Selesaikan langkah-langkah berikut untuk orientasi ke Amazon SageMaker Studio agar dapat mengakses ke Amazon SageMaker Autopilot.
Catatan: Untuk informasi selengkapnya, lihat Memulai Amazon SageMaker Studio di dokumentasi Amazon SageMaker.
a. Masuk ke konsol Amazon SageMaker.
Catatan: Di bagian sudut kanan atas, pastikan untuk memilih Wilayah AWS tempat Amazon SageMaker Studio tersedia. Untuk mengetahui daftar Wilayah, lihat Orientasi ke Amazon SageMaker Studio.


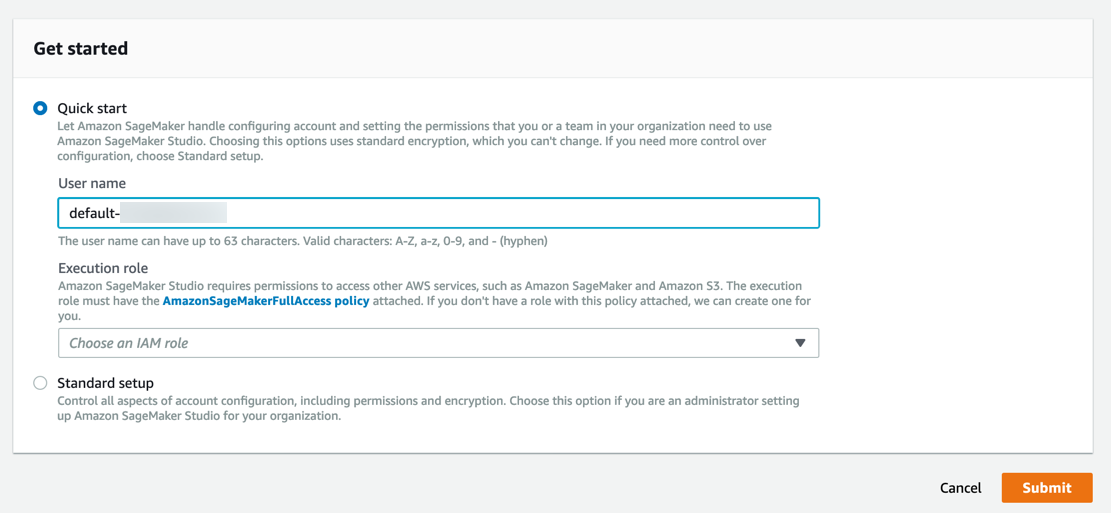
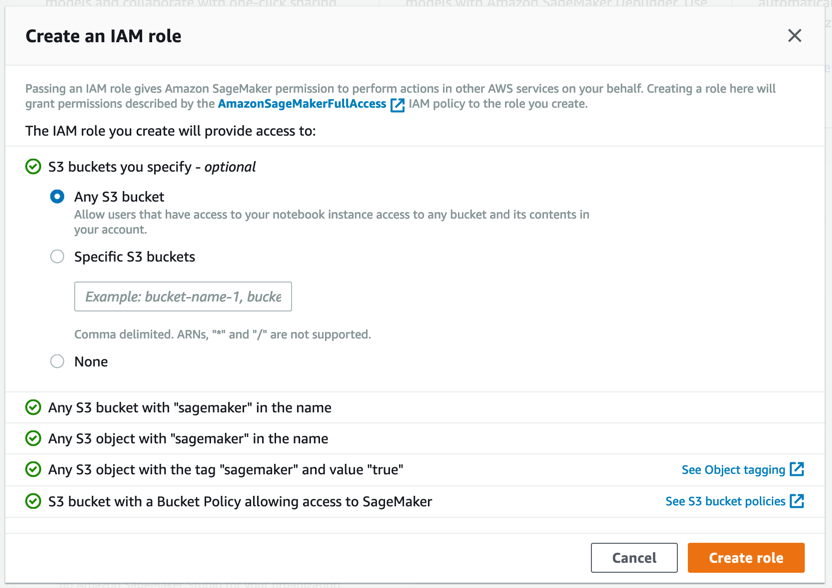
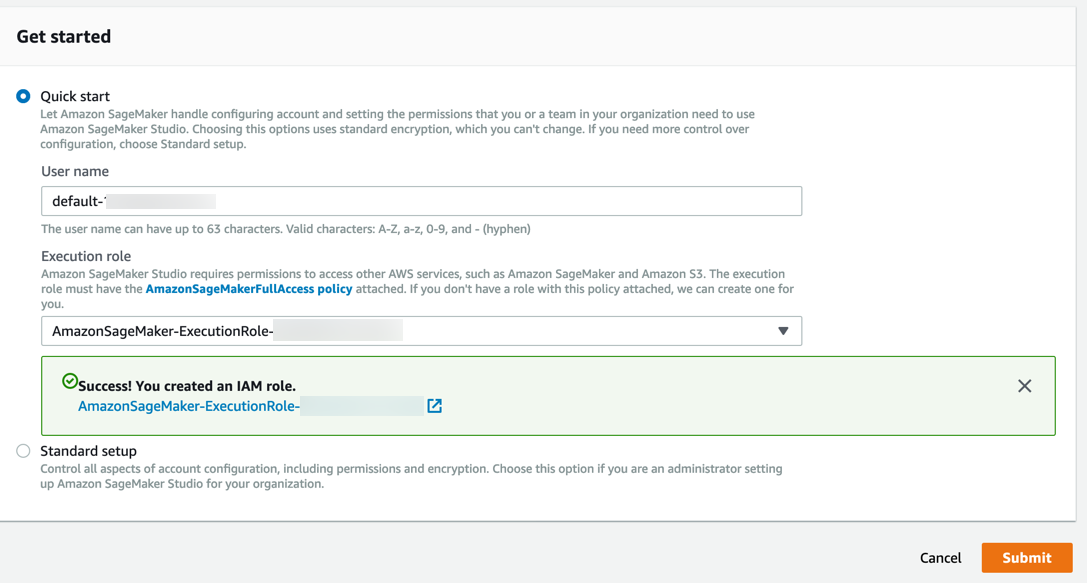
Amazon SageMaker akan membuat peran dengan izin yang diperlukan dan menugaskannya ke instans Anda.
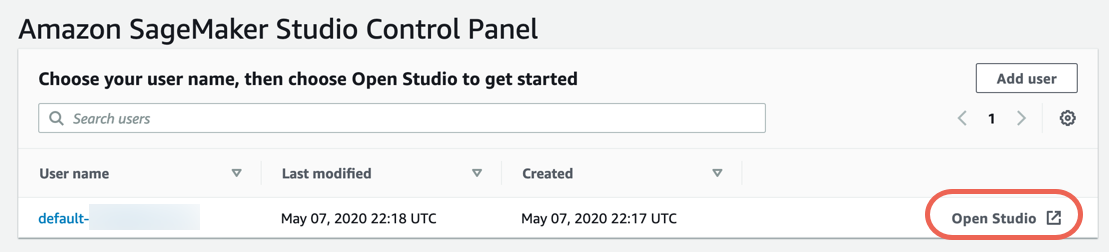
Langkah 3. Unduh dataset
Selesaikan langkah-langkah berikut untuk mengunduh dan menjelajahi dataset.
Catatan: Untuk informasi selengkapnya, lihat tur Amazon SageMaker Studio di dokumentasi Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Salin dan tempelkan kode berikut ke sel kode baru dan pilih Run.
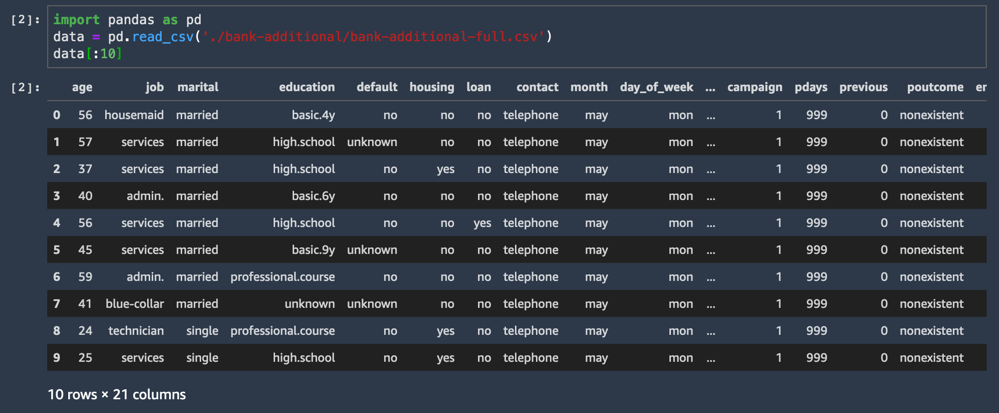
Dataset CSV akan membuat dan menampilkan sepuluh baris pertama.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Salah satu kolom dataset diberi nama y, dan mewakili label untuk setiap sampel: apakah pelanggan ini menerima tawaran atau tidak?
Ini adalah langkah di mana ilmuwan data mulai menjelajahi data, membuat fitur baru, dan sebagainya. Dengan Amazon SageMaker Autopilot, Anda tidak perlu menjalankan langkah-langkah tambahan ini. Anda cukup mengunggah data tabular dalam file dengan nilai yang dipisahkan koma (misalnya, dari spreadsheet atau database), pilih kolom target untuk diprediksi, dan Autopilot akan membangun model prediktif untuk Anda.
d. Salin dan tempelkan kode berikut ke sel kode baru dan pilih Run.
Langkah ini mengunggah dataset CSV ke dalam bucket Amazon S3. Anda tidak perlu membuat bucket Amazon S3; Amazon SageMaker akan secara otomatis membuat bucket default dalam akun saat Anda menggunggah data.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Selesai! Output kode menampilkan URI bucket S3 seperti contoh berikut:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvIngatlah URI S3 yang dicetak di buku catatan Anda. Anda akan memerlukannya lagi di langkah berikutnya.

Langkah 4. Membuat eksperimen SageMaker Autopilot
Setelah mengunduh dan mengatur dataset di Amazon S3, Anda dapat membuat eksperimen Amazon SageMaker Autopilot. Eksperimen adalah serangkaian proses dan tugas pelatihan yang terkait dengan proyek pembelajaran mesin yang sama.
Selesaikan langkah-langkah berikut untuk membuat eksperimen baru.
Catatan: Untuk informasi selengkapnya, lihat Membuat Pengalaman Amazon SageMaker Autopilot di SageMaker Studio dalam dokumentasi Amazon SageMaker.
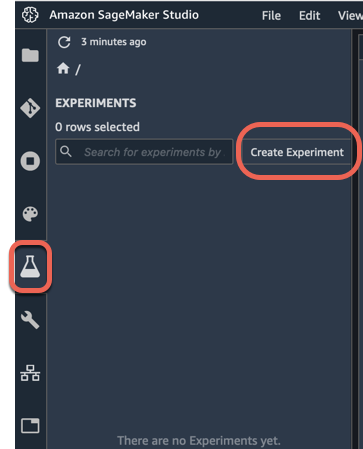
a. Di panel navigasi kiri Amazon SageMaker Studio, pilih Experiments (ikon dengan simbol labu), lalu pilih Create Experiment.
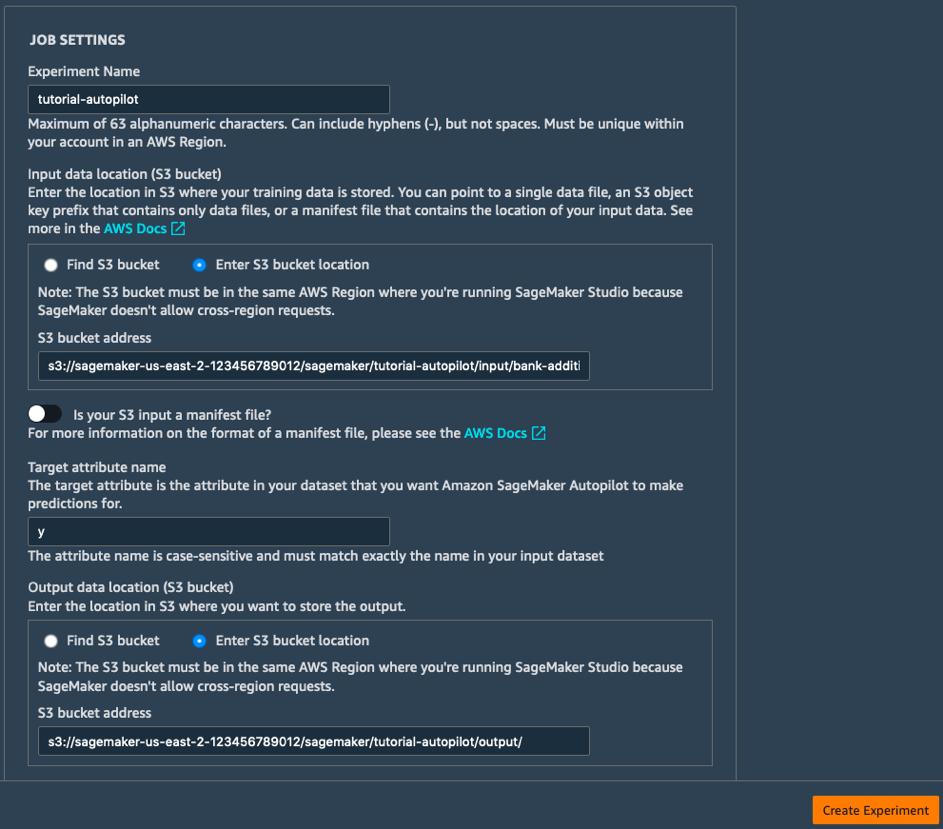
b. Isi kolom Job Settings seperti berikut ini:
- Experiment Name: tutorial-autopilot
- S3 location of input data: URI S3 yang dicetak di atas
(contoh s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name: y
- S3 location for output data: s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(pastikan untuk mengganti [ACCOUNT-NUMBER] dengan nomor akun Anda)
c. Biarkan pengaturan lainnya dalam kondisi default dan pilih Buat Eksperimen.
Berhasil! Ini adalah awal dari eksperimen Amazon SageMaker Autopilot! Proses tersebut akan menghasilkan model serta statistik yang dapat Anda lihat secara aktual selama eksperimen berjalan. Setelah eksperimen selesai, Anda dapat melihat hasil percobaan, mengurutkan berdasarkan metrik objektif dan mengeklik kanan guna menerapkan model untuk penggunaan di lingkungan lain.
Langkah 5. Jelajahi tahapan eksperimen SageMaker Autopilot
Saat eksperimen berjalan, Anda dapat mempelajari dan menjelajahi berbagai tahapan eksperimen SageMaker Autopilot.
Bagian ini menjelaskan lebih detail tentang tahapan eksperimen SageMaker Autopilot:
- Analisis Data
- Penyusunan Fitur
- Penyetelan Model
Catatan: Untuk informasi selengkapnya, lihat SageMaker Autopilot Notebook Output.
Analisis Data
Tahapan Analisis Data mengidentifikasi jenis masalah yang harus dipecahkan (regresi linier, klasifikasi biner, klasifikasi multikelas). Selanjutnya, akan diberikan hingga sepuluh potensi rancangan. Rancangan menggabungkan langkah prapemrosesan data (penanganan nilai yang hilang, penyusunan fitur baru, dll.), dan langkah pelatihan model menggunakan algoritme ML yang cocok dengan jenis masalah. Setelah langkah ini selesai, tugas selanjutnya beralih ke penyusunan fitur.
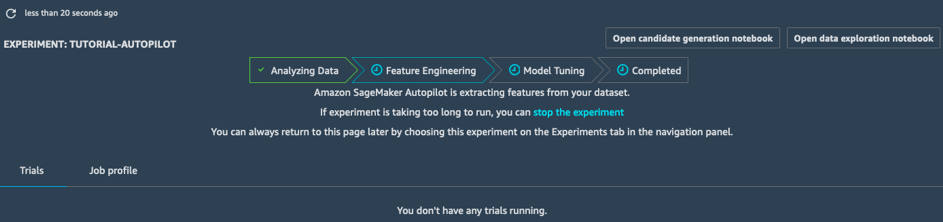
Perancangan Fitur
Di tahap Perancangan Fitur, eksperimen akan membuat dataset pelatihan dan validasi untuk setiap potensi rancangan, menyimpan semua artefak dalam bucket S3 Anda. Saat berada di tahap Penyusunan Fitur, Anda dapat membuka dan melihat dua notebook yang dibuat secara otomatis:
- Data exploration notebook berisi informasi dan statistik mengenai dataset.
- Candidate generation notebook berisi penjelasan dari sepuluh rancangan. Sebenarnya, ini adalah notebook yang dapat dijalankan: Anda dapat mereproduksi dengan tepat yang dilakukan tugas AutoPilot, memahami cara berbagai model dibuat, dan bahkan terus memodifikasinya jika Anda mau.
Dengan dua notebook ini, Anda dapat memahami secara detail cara data diproses sebelumnya, dan cara model dibangun dan dioptimalkan. Transparansi ini adalah fitur penting Amazon SageMaker Autopilot.
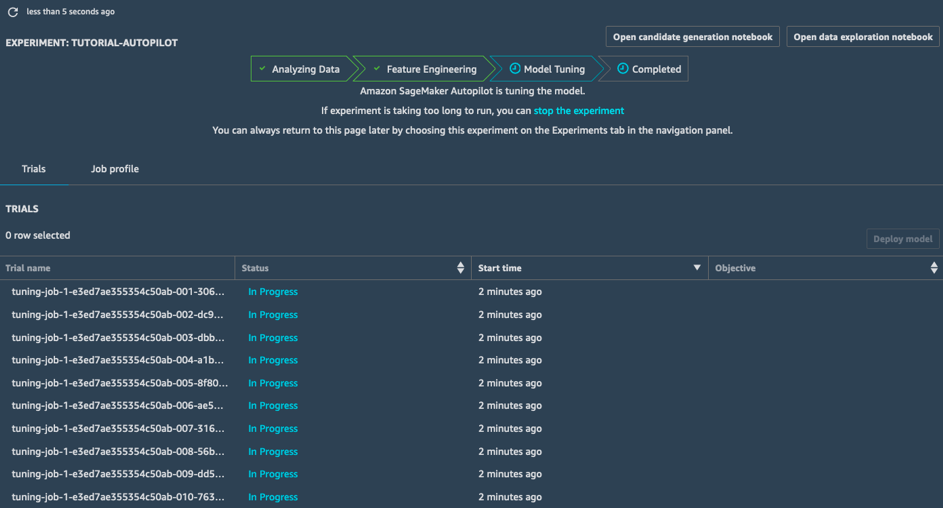
Penyetelan Model
Dalam tahap Penyetelan Model, untuk setiap potensi rancangan dan dataset yang telah diproses, SageMaker Autopilot meluncurkan tugas optimisasi hyperparameter; tugas pelatihan terkait mengeksplorasi berbagai nilai hyperparameter, dan dengan cepat memusat menjadi model kinerja tinggi.
Setelah tahap ini selesai, tugas SageMaker Autopilot selesai. Anda dapat melihat dan menjelajahi semua tugas di SageMaker Studio.
Langkah 6. Menerapkan model terbaik
Setelah eksperimen selesai, Anda dapat memilih model penyetelan terbaik dan menerapkan model ke titik akhir yang dikelola oleh Amazon SageMaker.
Ikuti langkah-langkah berikut untuk memilih tugas penyetelan terbaik dan menerapkan model.
Catatan: Untuk informasi selengkapnya, lihat Memilih dan menerapkan model terbaik.
a. Dalam daftar Trial eksperimen Anda, pilih carrot di sebelahObjective untuk mengurutkan tugas penyetelan dari besar ke kecil. Tugas penyetelan terbaik ditandai dengan bintang.
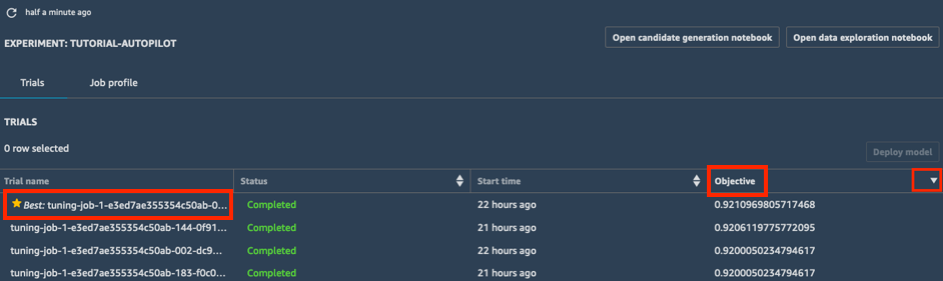
b. Pilih tugas penyetelan terbaik (ditunjukkan dengan bintang) dan pilih Deploy model.
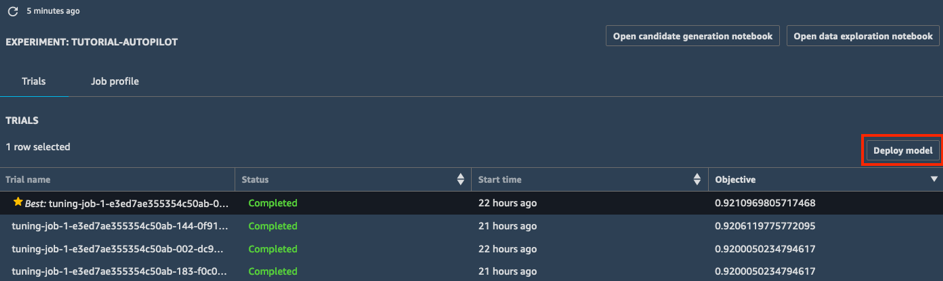
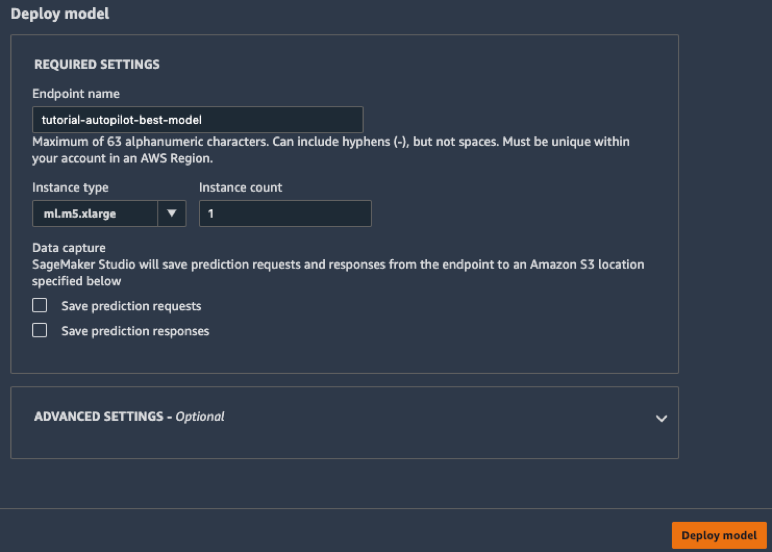
c. Di kotak Deploy model, beri nama titik akhir Anda (misalnya tutorial-autopilot-best-model) dan biarkan pengaturan lainnya dalam kondisi default. PilihDeploy model.
Model diterapkan ke titik akhir HTTPS yang dikelola oleh Amazon SageMaker.
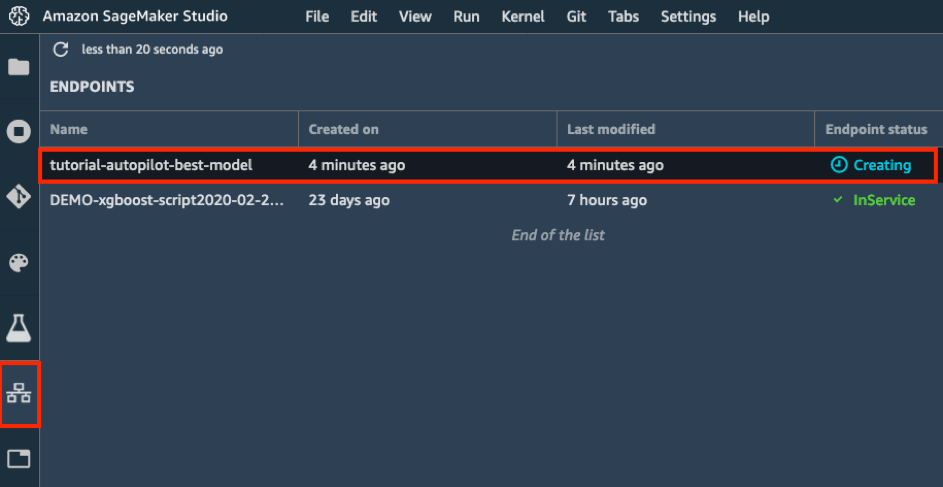
d. Di toolbar sebelah kiri, pilih ikon Endpoints. Anda akan melihat model sedang dibuat, yang memerlukan waktu beberapa menit. Setelah status titik akhir menunjukkan InService, Anda dapat mengirimkan data dan menerima prediksi!
Langkah 7. Prediksikan dengan model Anda
Setelah model diterapkan, Anda dapat memprediksi 2,000 sampel dataset pertama. Untuk langkah ini, gunakan invoke_endpoint API di boto3 SDK. Dalam proses tersebut, Anda melakukan komputasi metrik pembelajaran mesin penting: akurasi, presisi, ingatan, dan skor F1.
Ikuti langkah-langkah berikut untuk memprediksi dengan model Anda.
Catatan: Untuk informasi selengkapnya, lihat Mengelola Pembelajaran Mesin dengan Eksperimen Amazon SageMaker.
Dalam notebook Jupyter Anda, salin dan tempelkan kode berikut dan pilih Run.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
Anda akan melihat output berikut.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Output ini adalah indikator progres yang menunjukkan jumlah sampel yang telah diprediksi!
Langkah 8. Pembersihan
Di langkah ini, Anda akan menghentikan sumber daya yang digunakan di lab ini.
Penting: Menghentikan sumber daya yang tidak digunakan secara aktif akan mengurangi biaya dan merupakan praktik terbaik. Tidak menghentikan sumber daya Anda akan menimbulkan biaya.
Hapus titik akhir Anda: Di notebook Jupyter Anda, salin dan tempelkan kode berikut dan pilih Run.
sess.delete_endpoint(endpoint_name=ep_name)Jika ingin membersihkan semua artefak pelatihan (model, kumpulan data praproses, dll.), salin dan tempel kode berikut ke dalam sel kode Anda lalu pilih Run.
Catatan: Pastikan untuk mengganti ACCOUNT_NUMBER dengan nomor akun Anda.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Selamat
Anda telah membuat model pembelajaran mesin dengan akurasi terbaik secara otomatis menggunakan Amazon SageMaker Autopilot
Langkah berikutnya yang direkomendasikan
Ikuti tur Amazon SageMaker Studio
Pelajari selengkapnya tentang Amazon SageMaker Autopilot
Jika ingin mempelajari selengkapnya, baca postingan blog atau tonton rangkaian video Autopilot.