Apa itu Penyematan di Machine Learning?
Apa itu penyematan dalam machine learning?
Penyematan adalah representasi numerik dari objek dunia nyata yang digunakan sistem pembelajaran mesin (ML) dan kecerdasan buatan (AI) untuk memahami domain pengetahuan yang kompleks seperti yang dilakukan manusia. Sebagai contoh, algoritma komputasi memahami bahwa perbedaan antara 2 dan 3 adalah 1, yang menunjukkan hubungan yang dekat antara 2 dan 3 dibandingkan dengan 2 dan 100. Namun, data dunia nyata mencakup hubungan yang lebih kompleks. Misalnya, sarang burung dan sarang singa adalah pasangan analog, sedangkan siang-malam adalah istilah yang berlawanan. Penyematan mengubah objek dunia nyata menjadi representasi matematika kompleks yang menangkap properti dan hubungan yang melekat antara data dunia nyata. Seluruh proses diotomatiskan, dengan sistem AI yang membuat penyematan sendiri selama pelatihan dan menggunakannya sesuai kebutuhan untuk menyelesaikan tugas baru.
Mengapa penyematan itu penting?
Penyematan memungkinkan model deep-learning untuk memahami domain data dunia nyata dengan lebih efektif. Mereka menyederhanakan cara data dunia nyata diwakili dengan mempertahankan hubungan semantik dan sintaksis. Hal ini memungkinkan algoritma machine learning untuk mengekstraksi dan memproses tipe data yang kompleks dan mengaktifkan aplikasi AI yang inovatif. Bagian berikut menjelaskan beberapa faktor penting.
Kurangi dimensi data
Ilmuwan data menggunakan penyematan untuk mewakili data dimensi tinggi dalam ruang dimensi rendah. Dalam ilmu data, istilah dimensi biasanya mengacu pada fitur atau atribut data. Data dimensi lebih tinggi dalam AI mengacu pada set data dengan banyak fitur atau atribut yang menentukan setiap titik data. Ini bisa berarti puluhan, ratusan, atau bahkan ribuan dimensi. Misalnya, gambar dapat dianggap sebagai data dimensi tinggi karena setiap nilai warna piksel adalah dimensi yang terpisah.
Saat disajikan dengan data dimensi tinggi, model deep-learning membutuhkan lebih banyak daya komputasi dan waktu untuk belajar, menganalisis, dan menyimpulkan secara akurat. Penyematan mengurangi jumlah dimensi dengan mengidentifikasi kesamaan dan pola di antara berbagai fitur. Akibatnya, hal ini dapat mengurangi sumber daya komputasi dan waktu yang dibutuhkan untuk memproses data mentah.
Latih model bahasa besar
Penyematan meningkatkan kualitas data saat melatih model bahasa besar (LLM). Misalnya, ilmuwan data menggunakan penyematan untuk membersihkan data pelatihan dari penyimpangan yang memengaruhi pembelajaran model. Rekayasawan ML juga dapat menggunakan kembali model yang telah dilatih sebelumnya dengan menambahkan penyematan baru untuk pembelajaran transfer, yang membutuhkan penyempurnaan model dasar dengan set data baru. Dengan penyematan, rekayasawan dapat menyempurnakan model untuk set data khusus dari dunia nyata.
Bangun aplikasi inovatif
Penyematan memungkinkan pembelajaran mendalam baru dan aplikasi kecerdasan buatan generatif (AI generatif). Teknik penyematan yang berbeda diterapkan dalam arsitektur jaringan neural supaya memungkinkan model AI yang akurat untuk dikembangkan, dilatih, dan dilakukan deployment di berbagai bidang dan aplikasi. Misalnya:
- Dengan penyematan gambar, para rekayasawan dapat membangun aplikasi penglihatan komputer presisi tinggi untuk deteksi objek, pengenalan gambar, dan tugas terkait visual lainnya.
- Dengan penyematan kata, perangkat lunak pemrosesan bahasa alami dapat memahami konteks dan hubungan kata-kata lebih akurat.
- Penyematan grafik mengekstraksi dan mengategorikan informasi terkait dari simpul yang saling berhubungan untuk mendukung analisis jaringan.
Model visi komputer, chatbot AI, dan sistem rekomendasi AI semuanya menggunakan penyematan untuk menyelesaikan tugas-tugas kompleks yang meniru kecerdasan manusia.
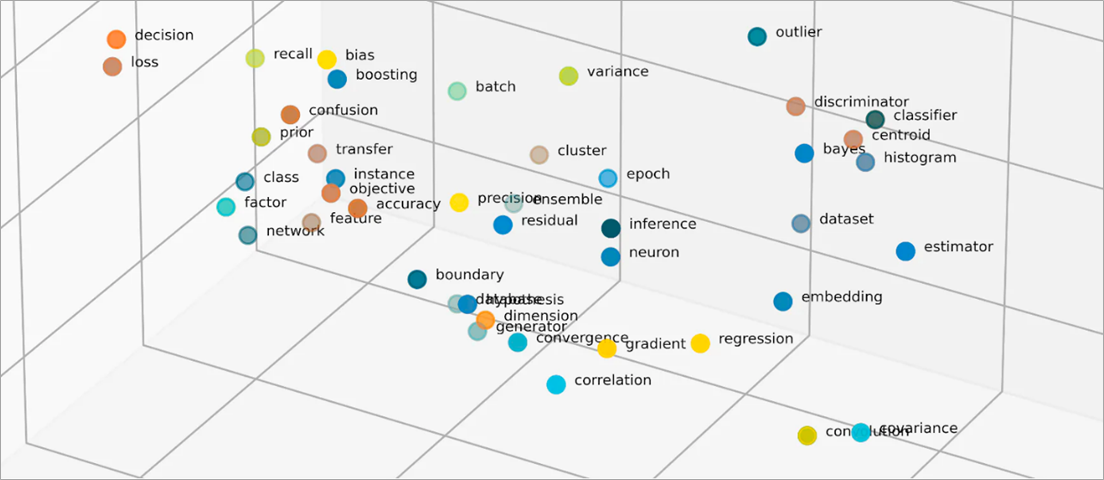
Apa itu vektor dalam penyematan?
Model ML tidak dapat menafsirkan informasi secara cerdas dalam format mentahnya dan memerlukan data numerik sebagai input. Mereka menggunakan penyematan jaringan neural untuk mengonversi informasi kata nyata menjadi representasi numerik yang disebut vektor. Vektor adalah nilai numerik yang mewakili informasi dalam ruang multidimensi. Mereka membantu model ML untuk mencari kesamaan di antara item yang jarang didistribusikan.
Setiap objek yang dipelajari model ML memiliki berbagai karakteristik atau fitur. Sebagai contoh sederhana, pertimbangkan film dan acara TV berikut. Masing-masing dicirikan oleh genre, jenis, dan tahun rilis.
The Conference (Horor, 2023, Film)
Upload (Komedi, 2023, Acara TV, Musim 3)
Tales from the Crypt (Horor, 1989, Acara TV, Musim 7)
Dream Scenario (Komedi Horor, 2023, Film)
Model ML dapat menafsirkan variabel numerik seperti tahun, tetapi tidak dapat membandingkan variabel non-numerik, seperti genre, jenis, episode, dan total musim. Vektor penyematan mengenkodekan data non-numerik ke dalam serangkaian nilai yang dapat dipahami dan dihubungkan oleh model ML. Misalnya, berikut ini adalah representasi hipotetis dari program TV yang tercantum sebelumnya.
The Conference (1,2, 2023, 20,0)
Upload (2,3, 2023, 35,5)
Tales from the Crypt (1,2, 1989, 36,7)
Dream Scenario (1,8, 2023, 20,0)
Angka pertama dalam vektor sesuai dengan genre tertentu. Model ML akan mencari bahwa The Conference dan Tales from the Crypt berbagi genre yang sama. Demikian juga, model akan mencari lebih banyak hubungan antara Upload dan Tales from the Crypt berdasarkan nomor ketiga, yang mewakili format, musim, dan episode. Karena lebih banyak variabel diperkenalkan, Anda dapat menyempurnakan model untuk memadatkan lebih banyak informasi dalam ruang vektor yang lebih kecil.
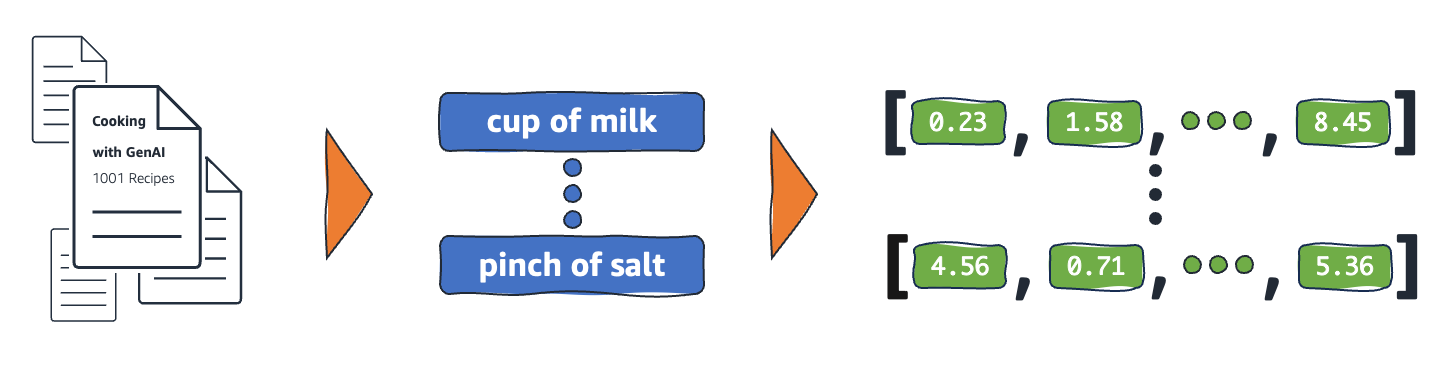
Bagaimana cara kerja penyematan?
Penyematan mengonversi data mentah menjadi nilai berkelanjutan yang dapat ditafsirkan oleh model ML. Secara konvensional, model ML menggunakan pengodean one-hot untuk memetakan variabel kategoris ke dalam bentuk yang dapat mereka pelajari. Metode pengenkodean membagi setiap kategori menjadi baris dan kolom serta menetapkan nilai binari. Pertimbangkan kategori produk berikut beserta harganya.
|
Buah |
Harga |
|
Apple |
5,00 |
|
Orange |
7,00 |
|
Wortel |
10,00 |
Mewakili nilai dengan pengenkodean one-hot menghasilkan tabel berikut.
|
Apple |
Jeruk |
Pir |
Harga |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
Tabel direpresentasikan secara matematis sebagai vektor [1,0,0,5,00], [0,1,0,7,00], dan [0,0,1,10,00].
Pengenkodean one-hot memperluas nilai dimensi 0 dan 1 tanpa memberikan informasi yang membantu model menghubungkan objek yang berbeda. Misalnya, model tidak dapat mencari kesamaan antara apel dan jeruk meskipun itu buah, juga tidak dapat membedakan jeruk dan wortel sebagai buah dan sayuran. Karena lebih banyak kategori ditambahkan ke daftar, pengenkodean menghasilkan variabel yang jarang didistribusikan dengan banyak nilai kosong yang menghabiskan ruang memori yang sangat besar.
Penyematan memvektorisasi objek ke dalam ruang dimensi rendah dengan mewakili kesamaan antara objek dan nilai numerik. Penyematan jaringan neural memastikan bahwa jumlah dimensi tetap dapat dikelola dengan memperluas fitur input. Fitur input adalah ciri-ciri objek tertentu yang ditugaskan untuk dianalisis oleh algoritma ML. Pengurangan dimensi memungkinkan penyematan untuk mempertahankan informasi yang digunakan model ML dalam mencari persamaan dan perbedaan dari data input. Ilmuwan data juga dapat memvisualisasikan penyematan dalam ruang dua dimensi untuk lebih memahami hubungan objek terdistribusi.
Apa itu model penyematan?
Model penyematan adalah algoritma yang dilatih untuk merangkum informasi ke dalam representasi padat dalam ruang multidimensi. Ilmuwan data menggunakan model penyematan untuk memungkinkan model ML memahami dan bernalar dengan data dimensi tinggi. Ini adalah model penyematan umum yang digunakan dalam aplikasi ML.
Analisis komponen pengguna utama
Analisis komponen pengguna utama (PCA) adalah teknik reduksi dimensi yang mengurangi tipe data kompleks menjadi vektor dimensi rendah. PCA menemukan titik data dengan kesamaan dan mengompresinya menjadi vektor penyematan yang mencerminkan data asli. Meskipun PCA memungkinkan model untuk memproses data mentah lebih efisien, tetapi kehilangan informasi dapat terjadi selama pemrosesan.
Dekomposisi nilai tunggal
Dekomposisi nilai tunggal (SVD) adalah model penyematan yang mengubah matriks menjadi matriks tunggal. Matriks yang dihasilkan mempertahankan informasi asli sambil memungkinkan model untuk lebih memahami hubungan semantik dari data yang mereka wakili. Ilmuwan data menggunakan SVD untuk mengaktifkan berbagai tugas ML, termasuk kompresi gambar, klasifikasi teks, dan rekomendasi.
Word2Vec
Word2Vec adalah algoritma ML yang dilatih untuk mengaitkan kata-kata dan merepresentasikannya dalam ruang penyematan. Ilmuwan data memasukkan model Word2Vec dengan set data tekstual besar untuk memungkinkan pemahaman bahasa alami. Model mencari kesamaan dalam kata-kata dengan mempertimbangkan konteks dan hubungan semantiknya.
Ada dua varian Word2Vec—Continuous Bag of Words (CBOW) dan Skip-gram. CBOW memungkinkan model untuk memprediksi kata dari konteks yang diberikan, meskipun Skip-gram memperoleh konteks dari kata tertentu. Meskipun Word2Vec adalah teknik penyematan kata yang efektif, ia tidak dapat membedakan perbedaan kontekstual secara akurat dari kata yang sama yang digunakan untuk menyiratkan makna yang berbeda.
BERT
BERT adalah model bahasa berbasis transformator yang dilatih dengan set data besar untuk memahami bahasa seperti manusia. Seperti Word2Vec, BERT dapat membuat penyematan kata dari data input yang dilatih dengannya. Selain itu, BERT dapat membedakan makna kontekstual kata-kata saat diterapkan pada frasa yang berbeda. Misalnya, BERT membuat penyematan yang berbeda untuk 'bermain' seperti dalam “Saya bermain dalam sebuah drama” dan “Saya suka bermain.”
Bagaimana penyematan dibuat?
Insinyur menggunakan jaringan saraf untuk membuat penyematan. Jaringan neural terdiri dari lapisan neuron tersembunyi yang membuat keputusan rumit secara berulang. Saat membuat penyematan, salah satu lapisan tersembunyi mempelajari cara memfaktorkan fitur input ke dalam vektor. Ini terjadi sebelum lapisan pemrosesan fitur. Proses ini diawasi dan dipandu oleh para rekayasawan dengan langkah-langkah berikut:
- Rekayasawan memberi makan jaringan neural dengan beberapa sampel vektor yang disiapkan secara manual.
- Jaringan neural belajar dari pola yang ditemukan dalam sampel dan menggunakan pengetahuan untuk membuat prediksi akurat dari data yang tidak terlihat.
- Kadang-kadang, rekayasawan mungkin perlu menyempurnakan model untuk memastikan model tersebut mendistribusikan fitur input ke dalam ruang dimensi yang sesuai.
- Seiring waktu, penyematan beroperasi secara independen, memungkinkan model ML untuk menghasilkan rekomendasi dari representasi vektor.
- Rekayasawan terus memantau performa penyematan dan menyempurnakan dengan data baru.
Bagaimana AWS dapat membantu memenuhi kebutuhan penyematan Anda?
Amazon Bedrock adalah layanan yang dikelola sepenuhnya yang menawarkan pilihan model dasar berkinerja tinggi (FM) dari perusahaan AI terkemuka, bersama dengan serangkaian fitur yang luas untuk membangun aplikasi kecerdasan buatan generatif (AI generatif). Amazon Nova adalah generasi baru model dasar (FM) canggih (SOTA) yang menghadirkan kecerdasan perbatasan dan kinerja harga terdepan di industri. Model fondasi adalah model serba guna yang tangguh yang dibuat untuk mendukung berbagai kasus penggunaan. Gunakan apa adanya atau sesuaikan dengan data Anda sendiri.
Titan Embeddings adalah LLM yang menerjemahkan teks ke dalam representasi numerik. Model Titan Embeddings mendukung pengambilan teks, kesamaan semantik, dan pembuatan klaster. Teks input maksimum adalah 8K token dan panjang vektor output maksimum adalah 1.536.
Tim pembelajaran mesin juga dapat menggunakan Amazon SageMaker untuk membuat penyematan. Amazon SageMaker adalah sebuah hub di mana Anda bisa membangun, melatih, dan menggunakan model ML di lingkungan yang aman dan dapat diskalakan. Amazon SageMaker menyediakan teknik penyematan yang disebut Object2Vec, yang dengannya para rekayasawan dapat memvektorisasi data dimensi tinggi dalam ruang dimensi rendah. Anda dapat menggunakan penyematan yang telah dipelajari untuk menghitung hubungan antar objek untuk tugas-tugas hilir, seperti klasifikasi dan regresi.
Mulailah dengan penyematan di AWS dengan membuat akun hari ini.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages