“Burns Cliff”, “Columbia Hills”, “Endeavour” e “Bonneville Crater” ti sembrano nomi fuori dal mondo? È proprio così! Sono alcune delle strutture geografiche visitate dalle missioni dei Mars Exploration Rover (MER) della NASA. Nel corso degli anni, i rover hanno riportato indietro grandi volumi di dati entusiasmanti, tra cui immagini ad alta risoluzione del Pianeta rosso. Ora, Amazon Simple Workflow Service (Amazon SWF) entra a far parte delle tecnologie di computing fondamentali alla base di queste missioni, consentendo agli scienziati della NASA di condurre in modo affidabile operazioni critiche e di elaborare con efficienza i volumi sempre maggiori di informazioni che raccogliamo sul nostro universo.
Mars Exploration Rover
Il Jet Propulsion Laboratory (JPL) della NASA utilizza Amazon SWF come parte integrante delle numerose missioni, tra cui MER (Mars Exploration Rover) e CARVE (Carbon in the Arctic Reservoir Vulnerability Experiment). Tali missioni generano costantemente grandi volumi di dati da elaborare, analizzare e archiviare in modo efficiente e affidabile. Le pipeline di elaborazione dei dati per le operazioni tattiche e l'analisi scientifica prevedono l'esecuzione ordinata di fasi su larga scala, con ampie opportunità di confronto in parallelo tra più macchinari. Gli esempi includono la generazione di dati stereoscopici a partire da coppie di immagini, la fusione di panorami composti da numerosi gigapixel per permettere agli scienziati di immergersi nel terreno di Marte e la suddivisione di queste immagini di gigapixel in modo da consentire il caricamento su richiesta. C'è un'intera community globale di operatori e scienziati che si affida a questi dati. Questa community si trova spesso a operare all'interno di tempistiche tattiche ristrette, talvolta anche di poche ore. Per soddisfare queste esigenze, gli ingegneri JPL stabiliscono un obiettivo di elaborazione e disseminazione delle immagini di Marte nel giro di pochi minuti.
JPL archivia ed elabora da tempo i dati in AWS. Gran parte di questo lavoro viene svolto con il framework Polyphony, ovvero l'implementazione di riferimento dell'architettura orientata al cloud di JPL. Fornisce supporto per provisioning, storage, monitoraggio e orchestrazione delle attività di elaborazione dati nel cloud. Il set di strumenti esistente di Polyphony per l'elaborazione e l'analisi dei dati consisteva in Amazon EC2 per la funzionalità di calcolo, Amazon S3 per lo storage e la distribuzione dei dati, nonché implementazioni di Amazon SQS e MapReduce, come Hadoop, per la distribuzione e l'esecuzione delle attività. Tuttavia, mancava un pezzo fondamentale: un servizio di orchestrazione per gestire in modo affidabile le attività per flussi di lavoro grandi e complessi.
Sebbene le code costituiscano un approccio efficace alla distribuzione di massa di attività parallele, gli ingegneri incontravano spesso delle carenze. L'incapacità di esprimere ordini e dipendenze all'interno delle code le rendeva inadatte ai flussi di lavoro complessi. Inoltre, con l'utilizzo delle code, gli ingegneri JPL dovevano gestire la duplicazione dei messaggi. Ad esempio, un'attività duplicata di fusione di un'immagine in questa fase comportava un'elaborazione ridondante e dispendiosa, il cui risultato innescava ulteriori calcoli costosi per arrivare a un futile completamento della pipeline. JPL dispone inoltre di numerosi casi d'uso che vanno oltre la mera elaborazione dei dati e richiedono meccanismi di gestione del flusso di controllo. Benché gli ingegneri fossero in grado di implementare facilmente i propri flussi basati sui dati con MapReduce, incontravano difficoltà nell'espressione di ogni fase della pipeline all'interno della semantica del framework. In particolare, con l'aumento della complessità di elaborazione dei dati, hanno dovuto affrontare alcune difficoltà nella rappresentazione delle dipendenze tra fasi di elaborazione e nella gestione degli errori di calcolo distribuiti.
Gli ingegneri JPL hanno rilevato l'esigenza di un servizio di orchestrazione con le seguenti caratteristiche:
- Alta disponibilità: a supporto delle operazioni mission critical
- Scalabilità: per facilitare l'esecuzione parallela simultanea da centinaia di istanze di Amazon EC2
- Affidabilità: un'attività programmata deve essere eseguita una sola volta con una probabilità molto elevata
- Espressività: semplice espressione di flussi di lavoro complessi per accelerare lo sviluppo
- Flessibilità: l'esecuzione dei flussi di lavoro non deve essere limitata ad Amazon EC2 e le attività devono essere instradabili
- Performance: le attività devono essere programmate con la minima latenza
Gli ingegneri JPL hanno utilizzato Amazon SWF e integrato il servizio con le pipeline Polyphony responsabili dell'elaborazione dati delle immagini di Marte per le operazioni tattiche. Hanno ottenuto un controllo e una visibilità senza precedenti sull'esecuzione distribuita delle proprie pipeline. Inoltre, aspetto ancora più importante, sono stati in grado di esprimere flussi di lavoro complessi in modo succinto, senza essere costretti a esprimere il problema in alcun paradigma specifico.
Per supportare il test sul campo di rapido movimento per il rover Curiosity, meglio noto come Mars Science Laboratory, gli ingegneri JPL hanno dovuto elaborare immagini, generarne di stereoscopiche e creare panorami. Le immagini stereoscopiche richiedono una coppia di immagini acquisite contemporaneamente e generano dati di intervallo che indicano a un operatore tattico la distanza e la direzione tra il rover e i pixel dell'immagine. Le immagini di sinistra e destra possono essere elaborate in parallelo; tuttavia, l'elaborazione stereoscopica non può avere inizio fino a quando ciascun'immagine non è stata elaborata. Questo flusso di lavoro classico di suddivisione e fusione è difficile da esprimere con un sistema basato su code, mentre la sua espressione con SWF richiede poche semplici righe di codice Java abbinate ad annotazioni di AWS Flow Framework.


Anche la creazione di panorami viene implementata come un flusso di lavoro. A scopi tattici, i panorami vengono generati in ciascuna posizione in cui il rover parcheggia e scatta fotografie. Di conseguenza, ogni volta che da una particolare posizione arriva una nuova immagine, il panorama viene ampliato con le nuove informazioni disponibili. A causa dell'ampia scala dei panorami e della necessità di crearli quanto più rapidamente possibile, il problema deve essere suddiviso e orchestrato tra numerose macchine. L'algoritmo impiegato dagli ingegneri suddivide il panorama in molteplici righe di grandi dimensioni. La prima attività del flusso di lavoro è quella di creare ognuna delle righe in base alle immagini disponibili nella posizione data. Una volta generate le righe, queste vengono ridimensionate in molteplici risoluzioni e suddivise in riquadri per la fruizione da parte di client remoti. Mediante l'utilizzo di un ricco set di caratteristiche fornito da Amazon SWF, gli ingegneri JPL hanno espresso questo flusso di applicazioni come un flusso di lavoro di Amazon SWF.
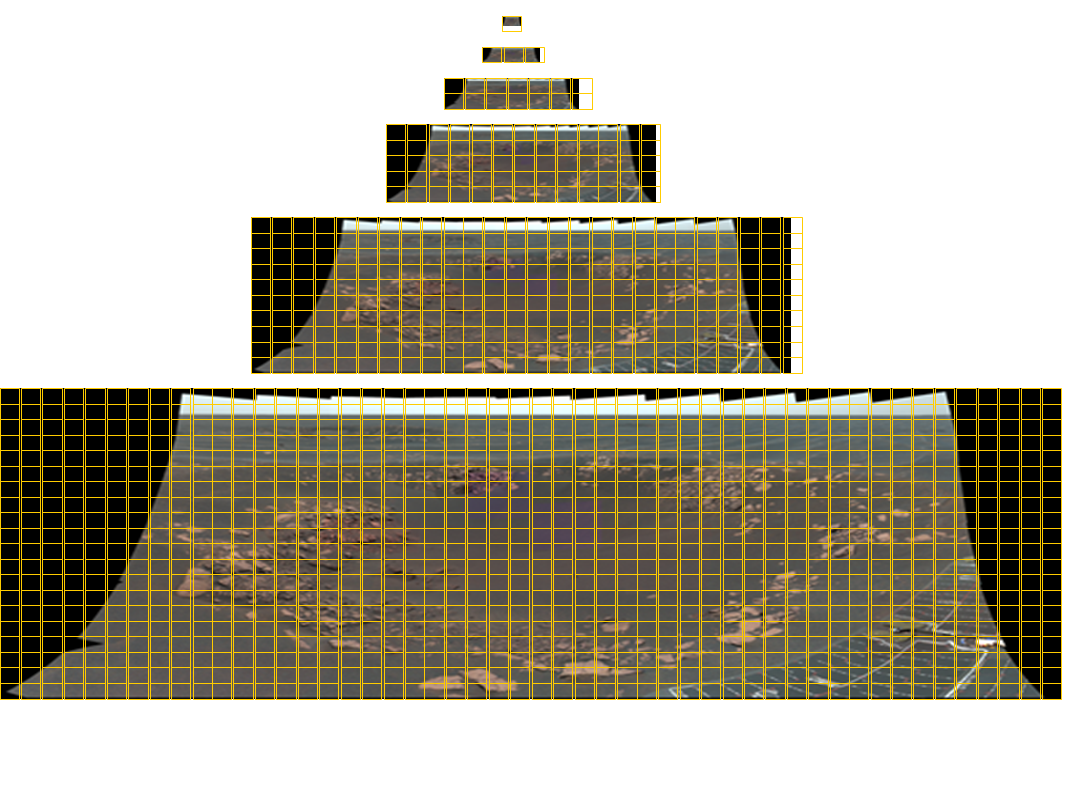
Un mosaico della fotocamera panoramica di Opportunity delle dimensioni totali di 11280×4280 pixel contenente 77 immagini a colori. Per fornire quest'immagine a un visualizzatore a qualsiasi dimensione arbitraria, sono necessari riquadri con sei livelli di dettaglio. Le righe gialle della griglia indicano i riquadri necessari per ciascun'immagine. Lo strumento Panoramas for Mastcam su Mars Science Laboratory contempla fino a 1296 immagini con una risoluzione di quasi 2 gigapixel! La corrispondente immagine panoramica è illustrata sotto.

Rendendo disponibile l'orchestrazione nel cloud, Amazon SWF offre a JPL la possibilità di sfruttare le risorse all'interno e all'esterno del proprio ambiente e di distribuire uniformemente l'esecuzione delle applicazioni nel cloud pubblico, consentendo alle applicazioni il dimensionamento dinamico e l'esecuzione in modo veramente distribuito.
Molte pipeline di elaborazione dei dati di JPL sono strutturate come operatori automatizzati per il caricamento di dati protetti da firewall, operatori per l'elaborazione dei dati in parallelo e operatori per il download dei risultati. Gli operatori di caricamento e download vengono eseguiti sui server locali, mentre gli operatori di elaborazione dei dati possono essere eseguiti sia in locale, sia sui nodi di Amazon EC2. Utilizzando le funzionalità di instradamento in Amazon SWF, gli sviluppatori JPL hanno incorporato in modo dinamico i lavoratori nella pipeline, sfruttandone al tempo stesso le caratteristiche, come la località dei dati. Quest'applicazione di elaborazione ha anche una disponibilità elevata, dal momento che anche quando gli operatori locali restituiscono errori, quelli basati sul cloud continuano a far progredire l'elaborazione. Dal momento che Amazon SWF non vincola la posizione dei nodi degli operatori, JPL esegue le attività in molteplici regioni, così come nei propri data center locali, per consentire la massima disponibilità per i sistemi mission critical. Con la disponibilità di Amazon SWF in più regioni, JPL prevede di integrare un failover automatico in SWF tra le varie regioni.

L'utilizzo da parte di JPL di Amazon SWF non si limita alle applicazioni di elaborazione dati. Utilizzando le funzionalità di programmazione di Amazon SWF, gli ingegneri JPL hanno sviluppato un sistema di attività Cron distribuite, in grado di eseguire operazioni mission critical in modo affidabile e tempestivo. Oltre all'affidabilità, JPL ha ottenuto una visibilità centralizzata e senza precedenti su queste attività distribuite, attraverso le funzionalità di visibilità di Amazon SWF disponibili nella Console di gestione AWS. JPL ha persino sviluppato un'applicazione per il backup di dati fondamentali da MER in Amazon S3. Con le attività Cron distribuite, JPL aggiorna i backup e controlla l'integrità dei dati con la frequenza desiderata dal progetto. Tutte le fasi di questa applicazione, inclusi crittografia, caricamento in S3, selezione casuale di dati da controllare e audit effettivo mediante confronto dei dati in loco con S3, vengono orchestrate in modo affidabile tramite Amazon SWF. Inoltre, numerosi team JPL hanno effettuato rapidamente la migrazione delle proprie applicazioni esistenti per utilizzare l'orchestrazione nel cloud sfruttando il supporto alla programmazione fornito attraverso AWS Flow Framework.
JPL continua a utilizzare Hadoop per le pipeline di elaborazione dei dati semplici e Amazon SWF è ora una scelta naturale per l'implementazione di applicazioni con dipendenze complesse tra le fasi di elaborazione. Gli sviluppatori utilizzano inoltre in modo frequente le funzionalità di diagnostica e analisi disponibili tramite la Console di gestione AWS per effettuare il debug delle applicazioni in fase di sviluppo e per il monitoraggio delle esecuzioni distribuite. Con AWS, per lo sviluppo, il test e la distribuzione di applicazioni mission critical che prima richiedevano mesi, ora occorrono solo pochi giorni.