- AWS Builder Center›
- builders.flash
ML 駆動の検索エンジンで企業の情報管理を革新 ! Amazon Kendra をグラレコで解説
2024-03-04 | Author : 米倉 裕基 (監修 : 関谷 侑希, 本橋 和貴)
はじめに
builders.flash 読者のみなさん、こんにちは ! テクニカルライターの米倉裕基と申します。
目次
本記事では、AWS が提供するエンタープライズ向けのインテリジェント検索サービス Amazon Kendra の機能と特徴を紹介します。
Kendra は、Amazon Simple Storage Service (Amazon S3)、Microsoft SharePoint、Salesforce など、複数のデータソースに分散するドキュメントを、自然言語で横断的に検索できるインテリジェントなエンタープライズ検索サービスです。Kendra は機械学習を活用することで、ユーザーの検索意図を理解し、関連性の高い結果を高速に返します。また、AWS の AI/ML サービスと連携することで、ドキュメント以外の音声や動画などをインデックス化でき、単なる文書検索に留まらない、高度な検索システムの構築が可能となります。Kendra はシームレスなエンタープライズ検索と柔軟な拡張性を両立した、多目的なインテリジェント検索サービスです。
本記事では、Amazon Kendra の主な機能と特徴を以下の項目に分けてご説明します。
-
Amazon Kendra とは
-
主なユースケース
-
Kendra の使い方
-
インテリジェント検索
-
AWS サービスとの連携
-
信頼性の高い生成 AI の構築
-
セキュリティとデータ保護
-
Kendra の料金体系
それでは、項目ごとに詳しく見ていきましょう。
builders.flash メールメンバー登録
Amazon Kendra とは
多彩なデータソース
Kendra の大きな特徴の一つは、非常に多様なデータソースを検索対象にできる点です。30 種類以上のネイティブコネクタにより、データベースや各種クラウドストレージ、SaaS アプリケーションなど、様々な情報管理サービスとシームレスに接続できます。
コネクタ
Kendra が提供するコネクタを利用することで、AWSのストレージサービスや SaaS アプリケーション、オンプレミス環境のデータなど、多様なソースから情報を収集できます。
以下は AWS から提供されているコネクタにより接続可能なサービスの一部です。
-
Amazon S3
-
Amazon RDS
-
Amazon FSx
-
Salesforce
-
Box
-
Microsoft SharePoint
上記以外にも多くのコネクタが提供されています。その他のデータソースコネクタについて詳しくは、「Amazon Kendra ネイティブコネクタ」をご覧ください。

ドキュメント形式
Kendra は、コネクタの豊富さに加えて、対応しているドキュメント形式のバリエーションも多彩です。CSV や JSON、XML のような構造化データに加えて、PDF、HTML、Microsoft Word、Microsoft PowerPoint などの一般的なオフィスドキュメントをサポートします。このドキュメント形式の対応の広さにより、組織の持つ様々なドキュメントを統合的に検索できます。
サポートしているドキュメント形式について詳しくは、「ドキュメントタイプまたは書式」をご覧ください。
自然言語による検索
Kendra を使用すると、自然言語での検索 (セマンティック検索) が可能です。平易な会話文のようなクエリを入力するだけで、Kendra が文意を理解し、最適な検索結果を高速に返してくれます。そのため、キーワード検索よりも柔軟な検索が可能です。
例えば、「1 月の売上データを教えて」「製品 X のバッテリーの交換方法は ?」「来週の東京オフィスの会議室予約状況」などの検索クエリを入力することで、該当する文書やデータを検索できます。検索結果には、関連性の高いコンテンツが表示され、文書の抜粋、FAQ、データベースレコードなど、質問の意図に合わて文章から該当箇所を抜粋して返答します。
多言語対応
2024 年 3 月時点で、Kendra のセマンティック検索は、英語、日本語、スペイン語、フランス語、ドイツ語、ポルトガル語、韓国語、中国語 の 8 言語がサポートされており、キーワード検索のみを含めると 36 言語をサポートしています。
Kendra の対応言語について詳しくは、「英語以外の言語でドキュメントを追加する」をご覧ください。
その他 Kendra の特徴について詳しくは、製品ページの「Amazon Kendra の特徴」をご覧ください。
主なユースケース
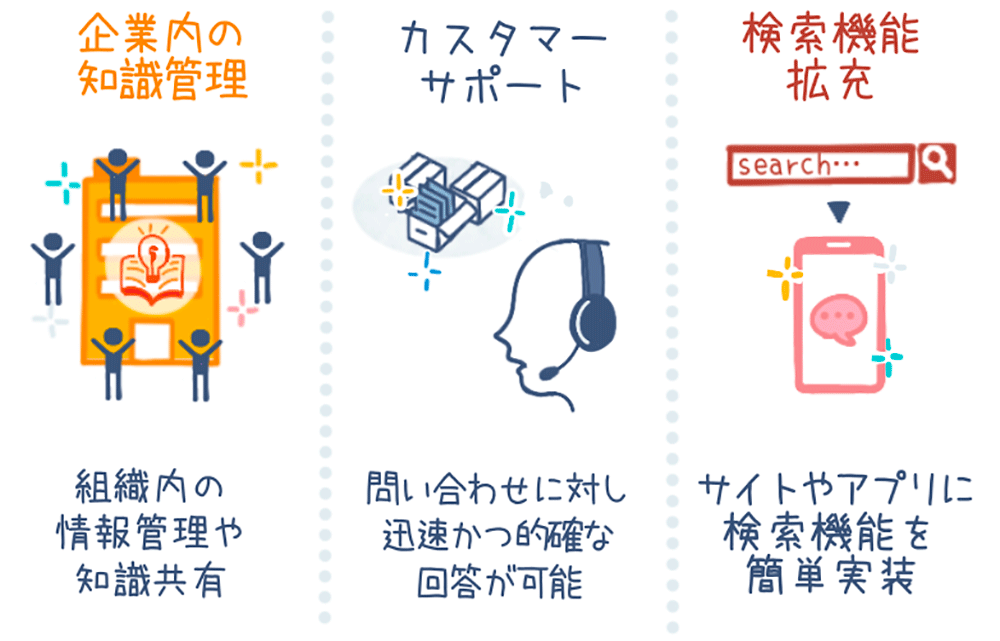
Kendra がさまざまなデータソースに対して、セマンティック検索で目的の情報を迅速に見つけ出すためのサービスということは説明した通りです。以下では、Kendra の多岐にわたるユースケースの中で主要なものを紹介します。
- 企業内の知識管理
企業はさまざまな形式の膨大な量の情報を保有しています。Kendra は、社内文書、メール、FAQ、技術文書などの多様な情報源を統合し、統一のインターフェースで情報を簡単に検索できるよう支援します。これにより、従業員のナレッジの共有が活発化し、データ主導の意思決定に必要なインサイトを一元的に得られるようになります。
- カスタマーサポート
Kendra は、カスタマーサポート業務においても大いに効果を発揮します。Kendra で製品マニュアルや FAQ などの情報源をインデックス化することで、カスタマーサポート担当者はお客様からの問合せに迅速に検索し、正確に回答することが可能になります。これにより顧客満足度の向上とサポート業務の効率化が期待できます。
- 自社製品への検索機能拡充
Kendra のシンプルで機能豊富な API を使えば、既存のウェブサイトやアプリケーションに強力な検索機能を実装できます。例えば 公共機関のウェブサイトに検索機能を実装するなど、柔軟に高度な検索機能を拡張することが可能です。
Kendra の用途は非常に幅広く、様々なアイデアに基づいたユースケースを実現できます。例えば、社内ドキュメントを使って自動応答する Q&A チャットボットを構築したり、ウェブクローラーで収集したコンテンツを用いたウェブサイト内検索を実装したり、また Amazon Transcribe でテキスト化した音声データや動画を Kendra で検索可能にする、といったことも可能です。
Kendra を使った Q&A チャットボットの構築については AWS ブログの「Amazon Kendra を使用して、よくある質問ボットをよりスマートに」をご覧ください。
Kendra の使い方
インデックスの作成
Kendra コンソールを使用することで GUI 操作だけでインデックスを作成できます。
-
インデックスの作成 :
Kendra コンソールで、インデックス名、説明、IAM ロールなどを設定し、インデックスを作成します。 -
データソースの追加 :
コネクタを使って、検索対象となるデータソースをインデックスに追加します。 -
検索機能のテスト :
Kendra コンソール上で検索をテストします。
GUI 操作だけでインデックスの作成から検索のテストまでを簡単に行うことができます。また、アプリケーション開発の場合やインデックスの動的な管理が必要な場合は、Kendra が提供する API を利用することでインデックスのリアルタイムの作成・更新・削除や、アプリケーションとのシームレスな連携が可能です。

フィールドマッピングとカスタム属性
Kendra が高速かつ適切な情報を検出する仕組みとして、ドキュメントのフィールド構造やメタデータの定義が挙げられます。
例えば、多くの社内文書にはタイトル、日付、著者、本文などのフィールドがあります。それぞれのフィールドをタイトル、作成日、作成者、コンテンツなどに マッピング してインデックス化することで、Kendra はドキュメントの構造をより正しく理解し、検索時に適切なフィールドを参照できるようになります。
また、ドキュメントにはない「商品カテゴリ」や「重要度」などのメタデータを カスタム属性 として定義することもできます。フィールドマッピングとカスタム属性により、検索結果の精度を高めるメタデータを柔軟に追加できます。
このように、Kendra は自然言語処理、機械学習、メタデータ管理を高度に組み合わせることで、ユーザーの真の検索意図を理解し、最適な検索エクスペリエンスを提供します。
Kendra の仕組みついて詳しくは、「Amazon Kendra の働き」をご覧ください。
インテリジェント検索
検索のフロー
アプリケーションから Kendra のインテリジェント検索を実行する場合は、以下のプロセスで事前に登録したインデックスに対して行われます。
- 検索実行 :
ユーザーが、アプリケーションに検索クエリを入力します。 - クエリ送信 :
クライアントアプリケーションが Query API を呼び出して、Kendra へ検索クエリを送信します。 - インデックス検索 :
Kendra がクエリを解析し、インデックスから関連ドキュメントを選び出します。 - 検索結果の返却 :
検索結果をスコア付けしてランキングし、アプリケーションに返却します。 - 検索結果の表示 :
アプリケーションが検索結果をユーザーに表示します。
高精度な検索
Kendra では以下のような仕組みにより高い検索精度を実現しています。
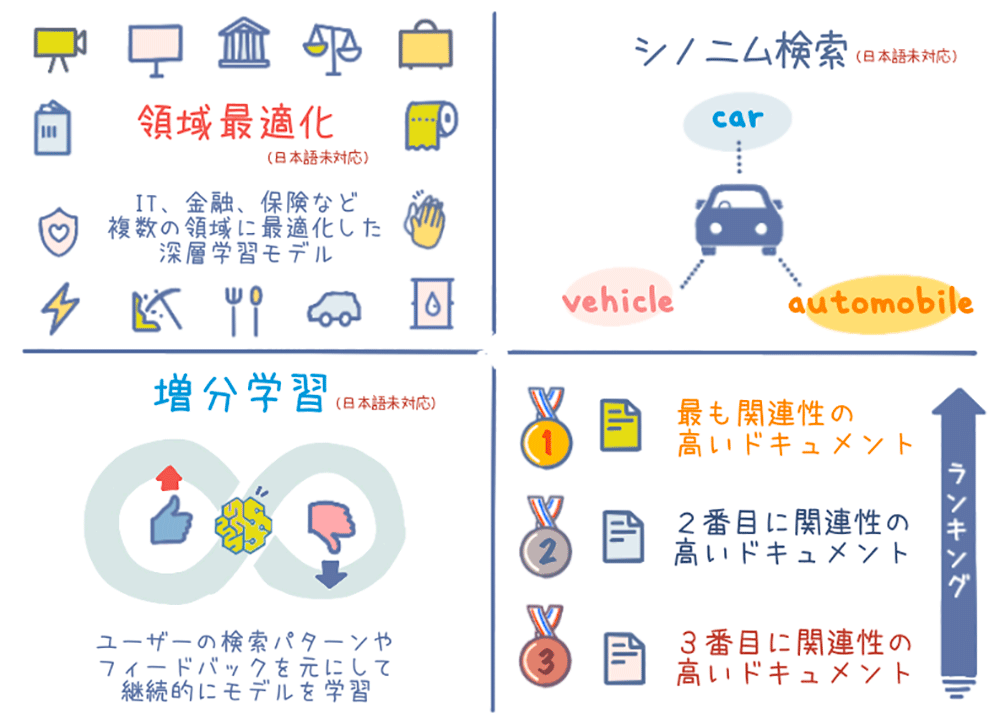
領域に最適化されたモデル
Kendra は、IT、金融サービス、保険など特定の業界に特化した深層学習モデルを使用して、その分野の専門知識や専門用語を理解し、正確に関連性の高い検索結果を提供します。
※ 2024 年 3 月現在、英語のみ対応
増分学習
Kendra は、ユーザーの検索クエリとフィードバックをもとに、検索結果のランキングアルゴリズムを継続的に改善します。これにより、検索結果の精度が向上し、ユーザーの意図に適った結果が返されるようになります。
※ 2024 年 3 月現在、英語のみ対応
ランキングアルゴリズム
Kendra は、複数の要因を考慮して検索結果の順位付けを行います。検索クエリとドキュメントの一致度や重要度、人気度、更新日などの要素を組み合わせて、ユーザーにもっとも関連性の高い情報を上位に表示します。
シノニム検索
Kendra は、入力された検索語のシノニム (同義語) を自動的に検索に用いることで、検索漏れを防ぐことができます。例えば、「car」という英語の検索語に対して、「automobile」「vehicle」などの言い換えを自動的に検索します。
※ 2024 年 3 月現在、英語のみ対応
シノニム検索は現在英語のみに対応していますが、日本語のシノニム辞書を登録することで、Kendra を使ったシノニム検索を実現できます。詳しくは 、AWS ブログ「Amazon Kendra で日本語の類義語検索を実現する方法」をご覧ください。
AWS サービスとの連携
Amazon S3 や Amazon RDS などのサービスをデータソースとして連携する以外にも、多彩な AWS サービスと組み合わせることで、Kendra の検索機能をさらに強化、拡張することができます。
連携可能なサービス例
Kendra は、以下のような AI/ML サービスと連携することで、検索機能を拡張できます。連携のメリットと代表的な使用例を紹介します。
|
サービス |
機能 |
連携のメリット |
|
自然言語処理 |
自然言語処理により、エンティティやセンチメントをメタデータとして追加 |
|
|
画像認識 |
画像認識により、画像ファイルのラベルをメタデータとして追加 |
|
|
機械翻訳 |
機械翻訳により、マルチリンガルなインデックスを構築 |
|
|
音声認識 |
音声テキスト化により、音声ファイルのテキストをインデックス化 |
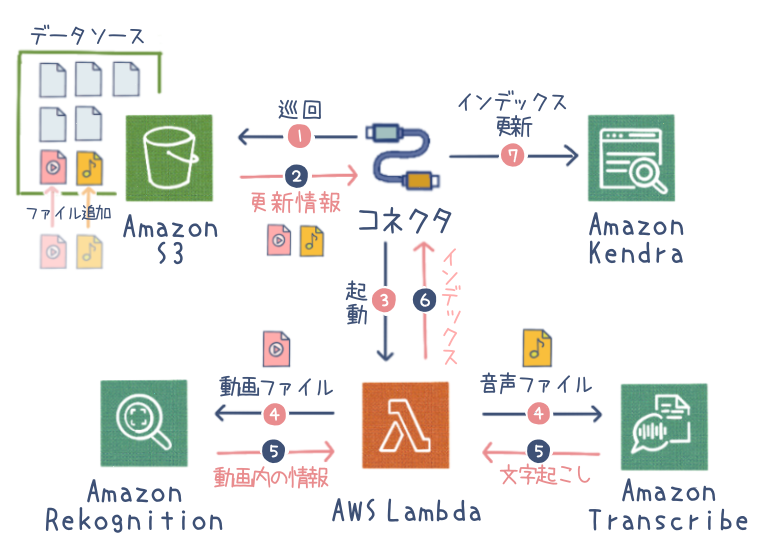
一般的な連携のフロー
以下のようなフローで、データソースの変更を検知してインデックスを自動更新するなどの連携が実現できます。
- データ更新 :
S3 や RDS 等のデータソースで更新イベントが発生したら Lambda 関数をトリガーする。 - データ前処理 :
Lambda 関数から Comprehend や Rekognition 等の API を呼び出し、データの前処理を実行する。 - インデックス登録 :
Lambda 関数から Kendra API を呼び出し、解析結果をインデックスに登録する。
他の AWS サービスとの連携は Kendra の大きな強みです。アーキテクチャ上のメリットを最大限に活用することで、ニーズに合わせた最適な検索インフラを構築できます。
Kendra と Amazon Transcribe を連携してメディアファイルを検索可能にする方法について詳しくは、AWS ブログの「Amazon Transcribe と Amazon Kendra を使って、音声ファイルや動画ファイルを検索可能にする」をご覧ください。
信頼性の高い生成 AI の構築
生成 AI の課題と対策
近年、生成 AI は大量のデータを統計的に学習することで、人間レベルの文章や画像を生成できるようになりました。しかし、生成 AI が非常に高度なコンテンツの生成にする一方で、時に虚偽の情報を生成してしまう「ハルシネーション」を起こすことが知られています。
誤った情報の生成
「ハルシネーション」は、生成 AI の信頼性を損なう重大な問題です。存在しない人名や事件、事実と異なる虚偽の情報を含む文章を生成するケースがあるため、生成 AI の生成結果についてはサービスの提供者側も利用者側も十分に注意する必要があります。この情報の信頼性の課題は、生成 AI の導入を妨げる大きな要因の一つになっています。
RAG による信頼性の向上
誤った情報の生成を抑制するために、現在 RAG (検索拡張生成) と呼ばれるアプローチが注目を集めています。RAG を使った検索では、生成 AI が応答を生成する前に信頼のおける特定のデータを参照し、事実に基づくコンテキストを与えることで、以下のようなメリットを得られます。
- ハルシネーションを抑え事実に基づく信頼性の高い回答を生成できる
- 任意の外部情報を使って LLM を拡張できる
- 開発者が LLM の情報ソースを制御できる
RAG について詳しくは、「RAG とは何ですか ?」をご覧ください。
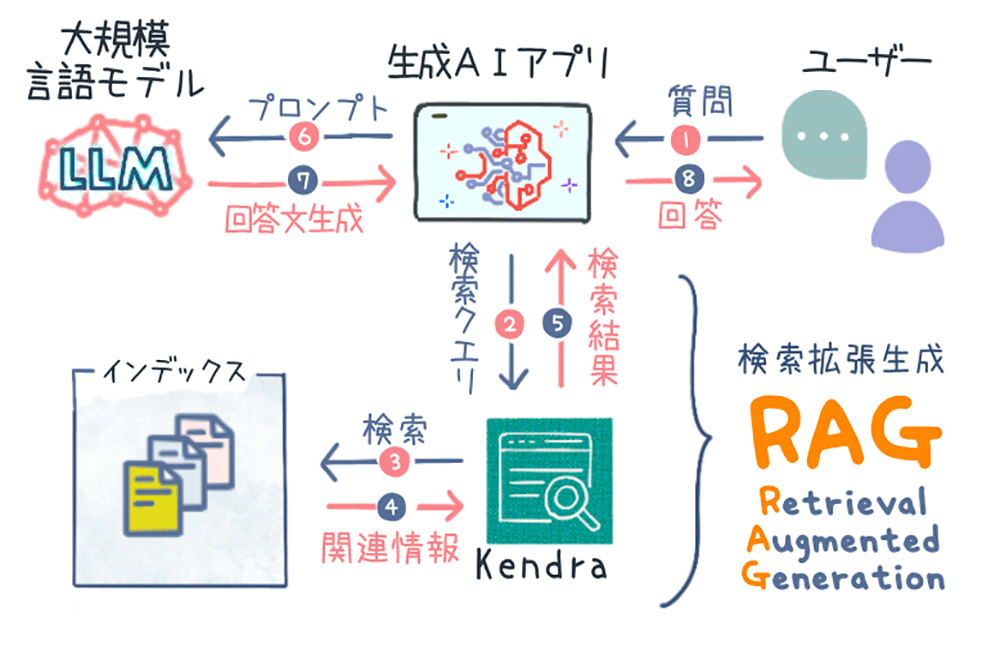
Kendra による RAG の構築
Kendra を使うことで、RAG 検索のフローを生成 AI アプリに組み込むことができます。以下のように、これにより、ユーザーが直接 LLM に投げかけた質問から回答文を生成するよりも、回答の精度を向上させます。
- ユーザーが生成 AI アプリに質問を入力する。
- 生成 AI アプリが Retrieve API を呼び出して、Kendra へ検索クエリを発行する。
- Kendra インデックスの中から関連性の高いドキュメントを検索する。
- Kendra が関連性順でランキングされた情報を取得する。
- Kendra が生成 AI アプリに検索結果を送信する。
- 生成 AI アプリがユーザーの質問と検索結果のドキュメントを LLM に送信する。
- LLM が送信された情報を基づいて回答文を生成する。
- 生成 AI アプリが回答文をユーザーに表示する。
Kendra を使った生成 AI アプリケーションの構築について詳しくは、AWS ブログの「高精度な生成系 AI アプリケーションを Amazon Kendra、LangChain、大規模言語モデルを使って作る」や builders.flash の「Amazon Kendra と大規模言語モデル (LLM) を使って生成 AI コンシェルジュを作ってみた !」をご覧ください。
セキュリティとデータ保護
データの暗号化
Kendra にデータソースを登録すると、データがインデックス化されて Kendra の検索エンジンで利用できるようになります。この機密情報を含むインデックスデータを保護するため、Kendra では、転送時と保存時の両方で暗号化を実施しています。
- 転送時 :
クライアントと Kendra 間の通信は、HTTPS プロトコルと TLS 1.2以上の暗号化によって保護されます。これによりデータの機密性が確保され、通信傍受のリスクが低減します。 - 保存時 :
デフォルトでは、インデックスデータは AWS KMS による SSE-KMS 暗号化が自動的に適用されます。これにより、保存されたデータが未承認のアクセスから保護されます。さらに細かい制御が必要な場合は、AWS のマネージドキーまたはユーザー独自のカスタマーマネージドキーを指定して暗号化を行うことも可能です。
Kendra のデータ保護について詳しくは、「Amazon Kendra のデータ保護」をご覧ください。
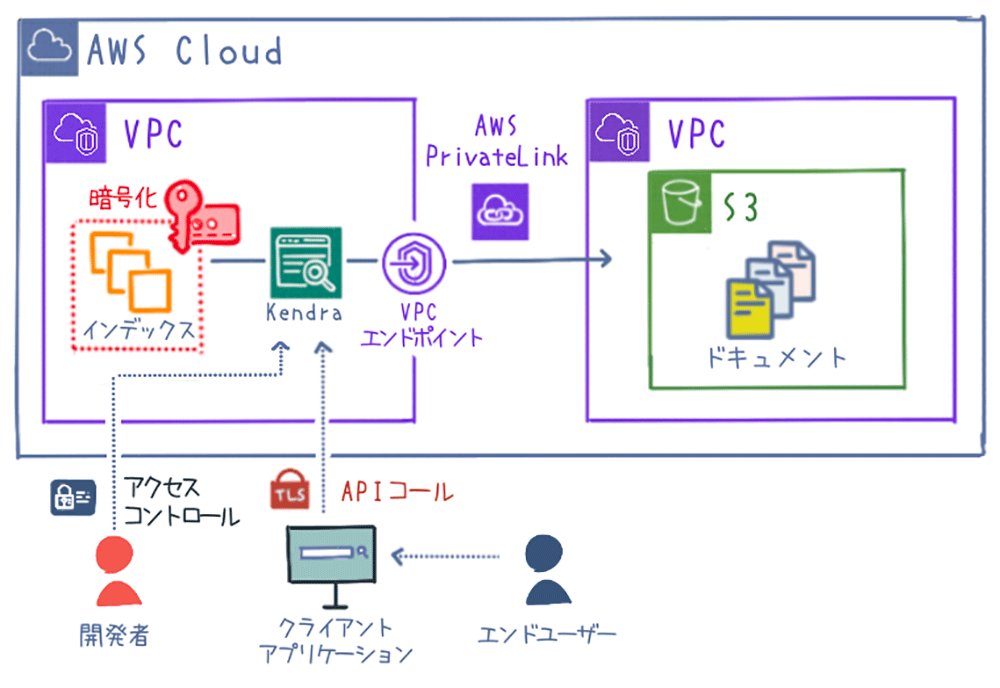
アクセス制御
AWS Identity and Access Management (IAM) によってユーザーとアクセス権限を紐付けた上で、認証基盤から発行されるセキュリティトークンを使うことで、より細かなアクセス制御が可能です。これにより、Kendra のユーザーは、自身の役割に応じて必要な情報にのみアクセスでき、不要な情報へのアクセスは制限されます。また、多要素認証 (MFA) やアクセスキーのローテーションなどセキュリティベストプラクティスを採用することで、さらにセキュアな環境を構築できます。
IAM を使ったアクセス制御について詳しくは、「Amazon Kendra 用の Identity and Access Management」をご覧ください。
ネットワーク分離
インターネットゲートウェイを持たない Amazon VPC 内のリソースから Kendra へプライベートにアクセスするには、インターフェイス VPC エンドポイントを作成します。VPC エンドポイントと Kendra の通信には AWS PrivateLink が使用され、セキュアなプライベート接続が確立されます。これにより、VPC 内のリソースをパブリックインターネットに晒すことなく、Kendra との通信を実現できます。
VPC エンドポイント とのプライベート接続について詳しくは、「Amazon Kendra とインターフェイス VPC エンドポイント (AWS PrivateLink)」をご覧ください。
上記以外にも、Amazon CloudWatch や AWS CloudTrail を使って Kendra の API 呼び出しやアクティビティを監視することで、セキュリティイベントの検知と対応を行うことができます。
Kendra のセキュリティ対策について詳しくは、「Amazon Kendra でのセキュリティ」をご覧ください。
Kendra の料金体系
課金対象
Kendra は、主に以下の項目に対して利用料金が発生します。
- インデックスの利用時間 :
インデックスの作成から削除までの時間に対して、1 秒単位で課金されます。料金は、インデックスのエディションにより異なります。 - コネクタ経由で取り込まれたドキュメント :
コネクタを使用して Kendra に取り込んだドキュメントごとに 0.000001 USD が発生します。 - コネクタの利用時間 :
インデックスの同期を実行する際、利用しているコネクタごとに 0.35 USD/時間が発生します。
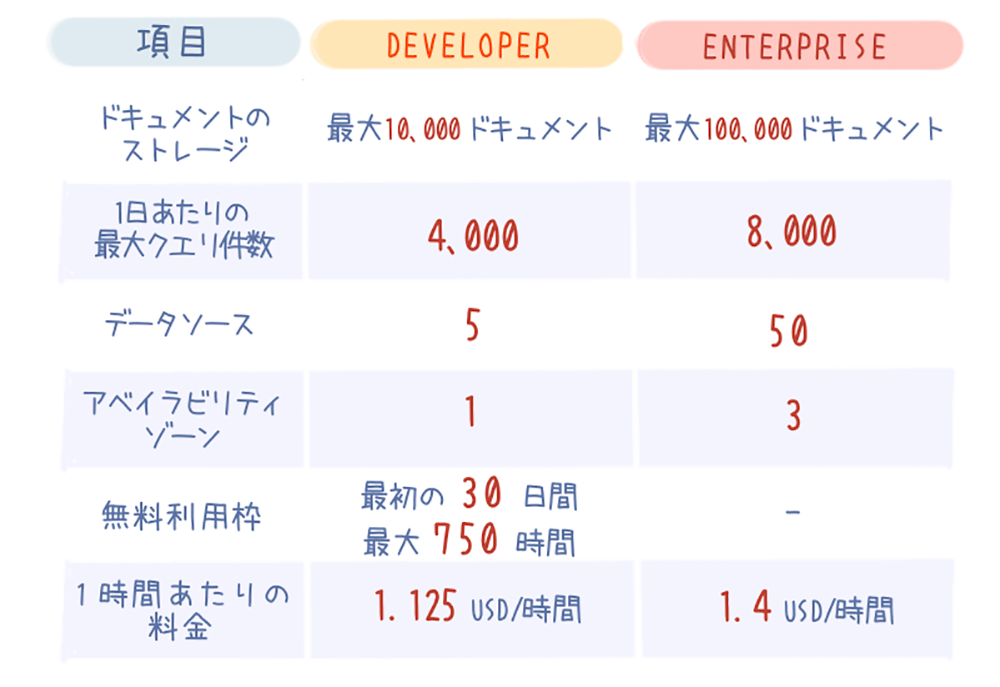
料金プラン
Kendra には Developer Edition と Enterprise Edition の 2 つのエディションが提供されています。
- Developer Edition :
機能検証やテスト目的で使用するエディションで、最初の 30 日間は月 750 時間まで無料で使用できます。無料期間後のインデックスの利用料金は、1.125 USD/時間です。 - Enterprise Edition :
本番運用向けのエディションで、大規模なインデックスを管理できます。インデックスの利用料金は、1.4 USD/時間です。
どちらのエディションもドキュメント数、クエリ数、データソース数、アベイラビリティゾーンの利用数などに上限が定められています。ただし、Enterprise Edition の場合は、追加料金を支払うことでリソースの上限を超えてスケールさせることができます。
Kendra の料金体系について詳しくは、「Amazon Kendra の料金」をご覧ください。
まとめ
最後に、本記事で紹介した機能の全体図を見てみましょう。
この記事では、AWS のエンタープライズ向けインテリジェント検索サービス Amazon Kendra の機能と特徴について解説しました。Kendra は、自然言語検索、大規模言語モデルとの連携、データソースの柔軟な連携など、エンタープライズ向けの知識検索を強力に支援する機能を提供しています。組織の情報を一元化し、ナレッジの再利用と業務効率化を実現する Kendra は、DX 時代における企業の知的資産の管理と活用を強力にバックアップするソリューションといえます。
本記事を読んで Kendra に興味を持たれた方、実際に使ってみたいと思われた方は、ぜひ製品ページの「Amazon Kendra」も合わせてご覧ください。
全体図
筆者・監修者プロフィール

筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
関谷 侑希 (せきや ゆうき)
アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト
交通・建設などの業界のソリューションアーキテクトです。個社向けの技術支援をする傍ら、Amazon Kendra を日本で普及させる活動も行っています。
趣味はバドミントンで YouTube や Netflix も時間があればよく見ています。

監修者プロフィール
本橋 和貴
アマゾン ウェブ サービス ジャパン合同会社
パートナーアライアンス統括本部 機械学習パートナーソリューションアーキテクト
AWS 上で機械学習関連のソフトウェアを開発しているパートナー企業の技術支援を担当をしています。好きなサービスは Amazon SageMaker です。週末は昔の RPG リメイクゲームの攻略に勤しんでいます。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages