Amazon Web Services ブログ
Amazon Transcribe と Amazon Kendra を使って、音声ファイルや動画ファイルを検索可能にする
このブログは “Make your audio and video files searchable using Amazon Transcribe and Amazon Kendra” を翻訳したものです。
音声と動画のメディアコンテンツに対する需要は、かつてないほど高まっています。組織は、かつてないほどメディアを活用して聴衆と関わっています。製品マニュアルはますます動画形式で発行されるようになり、ブログ記事の代わりにポッドキャストが制作されることも多くなっています。最近では、バーチャルな職場の利用が爆発的に増え、会議、通話、ボイスメールの録音という形でコンテンツが保存されるようになりました。また、コンタクトセンターでは、サポートコール、画面共有の記録、コール後のアンケートなどのメディアコンテンツが生成されます。
Amazon 機械学習サービスは、音声ファイルや動画ファイル、テキストファイルのコンテンツから答えを見つけ、価値あるインサイトを抽出することを支援します。
この記事では、メディアファイルを検索可能にし、検索結果として利用できるように構築された、新しいオープンソースソリューションの MediaSearch を紹介します。MediaSearch は、Amazon Transcribe を使用してメディアの音声をテキストに変換し、Amazon Kendra を使用してインテリジェントな検索を提供します。ユーザーは、音声ファイルや動画ファイルのサウンドトラックに埋め込まれたコンテンツでも、探しているコンテンツを見つけることができます。また、このソリューションでは、Amazon Kendra の検索アプリケーションが強化されており、ユーザーは検索結果ページから直接、元のメディアファイルの関連部分を再生することができます。
ソリューションの概要
MediaSearch は簡単にインストールでき、試すことができます。MediaSearch を使用すると、顧客がポッドキャストの録音やプレゼンテーションから質問に対する回答を見つけたり、学生がテキスト文書だけでなく、教育用動画や講義の録音から回答を見つけたりすることができます。
MediaSearch ソリューションは、次の図に示すように、2つのコンポーネントで構成されています。
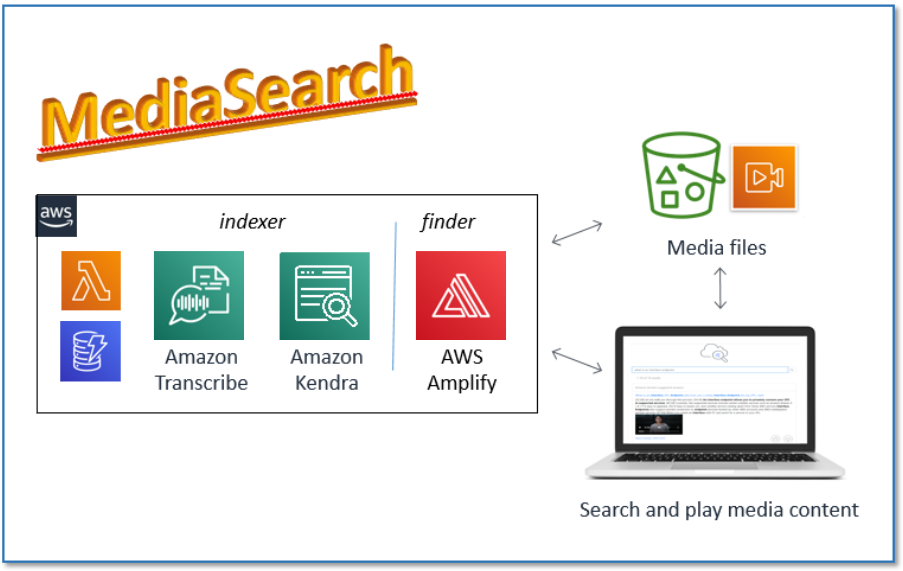
最初のコンポーネントである MediaSearch indexer は、Amazon Simple Storage Service (Amazon S3) のバケットに保存されている音声ファイルや動画ファイルを取り込み、文字起こしを行うものです。各文章の先頭にタイムマーカーを埋め込むことで文字起こしを準備し、準備した文字起こしを新規または既存の Amazon Kendra インデックスにインデックス付けします。インストール時に初めて実行され、その後は指定した間隔で実行され、新規ファイル、変更ファイル、削除ファイルがインデックスに反映されます。
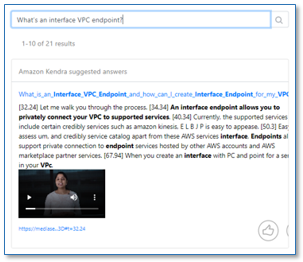
2番目のコンポーネントである MediaSearch finder は、Amazon Kendra インデックス内のコンテンツを検索するために使用する Web 検索クライアントのサンプルです。これは、標準的な Amazon Kendra 検索ページのすべての機能を備えていますが、検索結果にインラインで埋め込まれたメディア プレーヤーを含むため、トランスクリプトの関連セクションを表示するだけでなく、検索ページからページを移動せずに元のメディアから該当セクションを再生できます (次のスクリーンショットを参照してください)。
この後のセクションで、いくつかのトピックについて説明します。
- AWS アカウントへのソリューションのデプロイ方法
- サンプルのメディアファイルのインデックスと検索を行う方法
- 独自のメディアファイルを使用したソリューションの使用方法
- ソリューションがどのように機能するか
- 必要なコスト
- 使用状況を監視し、トラブルシュートする方法
- ソリューションのカスタマイズとチューニングのオプション
- 検証後にアンインストールとクリーンアップを実行する方法
MediaSearch ソリューションのデプロイ
このセクションでは、2つのソリューションコンポーネントである indexer と finder のデプロイを説明します。AWS CloudFormation スタックを使用して、us-east-1 (N. Virginia) AWS リージョンに必要なリソースを配置します。
ソースコードは GitHub リポジトリで公開されています。Amazon Kendra がサポートする追加のリージョンに MediaSearch をデプロイするには、README の指示に従います。
Indexer コンポーネントのデプロイ
indexer コンポーネントをデプロイするには、次の手順を実行します。
- Launch Stack を選択します。

- 必要に応じてスタック名を変更し、一意であることを確認します。
- ExistingIndexId については、新しい Amazon Kendra インデックス(Developer Edition)を作成する場合は空白のままにし、そうでない場合はアカウントとリージョン内の既存のインデックス(Amazon Kendra Enterprise Edition は本番ワークロード向け)の
IndexId(インデックス名ではない)を指定します。 - MediaBucket と MediaFolderPrefix については、最初はデフォルト値を使用して、サンプル音声と動画ファイルの文字起こしとインデックスを作成します。
- その他のパラメータは、デフォルト値を使用してください。
- 確認チェックボックスを選択し、スタックを作成 を選択します。
- スタックが作成されたら(約 15 分後)、Outputs タブを選択し、
IndexIdの値をコピーします – 次のステップで finder コンポーネントをデプロイするために必要です。
新しくインストールされた indexer が自動的に実行され、サンプルの音声ファイルや動画ファイルの探索、文字起こし、インデックス作成が行われます。後で、別のバケット名とプレフィックスを指定して、独自のメディアファイルのインデックスを作成することができます。複数のバケットにメディアファイルがある場合、indexer の複数のインスタンスを、それぞれ固有のスタック名で配置することができます。
finder コンポーネントのデプロイ
finder Web アプリケーション コンポーネントをデプロイするには、次の手順を実行します。
- Launch Stackを選択します。

- IndexId には、MediaSearch indexer スタック出力からコピーされた Amazon Kendra インデックスを使用します。
- MediaBucketNames には、検索ページがサンプルファイルバケットからメディアファイルにアクセスできるようにするために、最初はデフォルトを使用します。
- AdminEmail には、有効な電子メール アドレスを使用するか、または認証を有効にしないことを選択した場合は空のままにします。
- EnableAccessTokens と EnableGuestUser には、デフォルト値である false を使用します。
- スタックが作成されたら(約5分後)、Outputs タブを選択し、
MediaSearchFinderURLのリンクを使用して、新しいメディア検索アプリケーションのページをブラウザで開きます。
認証を有効にすることを選択した場合、入力した電子メールアドレス宛に「Welcome to Finder Web App」という件名の電子メールが送信されます。このメールには、生成された仮のパスワードが含まれており、これを使用してログインし、自分のパスワードを作成することができます。あなたのユーザー名は admin です。新しいパスワードは、8文字以上で、大文字と小文字、数字、特殊文字を含む必要があります。
最初にこのページを開いたときに、アプリケーションの準備ができていなくても、心配しないでください。最初のアプリケーションのビルドとデプロイ(AWS Amplify を使用)は約10分かかるので、少し後に再試行すると動作するようになります。何らかの理由でアプリケーションが開かない場合は、GitHub リポジトリの README を参照して、トラブルシューティングの手順を確認してください。
これでデプロイは完了です。次に、いくつかの検索クエリを実行して、その動作を確認してみましょう。
サンプルメディアファイルでのテスト
MediaSearch finder アプリケーションをデプロイして使用できるようになるまでに、indexer はサンプルメディアファイル(選択した AWS Podcast エピソードと AWS Knowledge center videos)の処理を完了させているはずです。これで、最初の MediaSearch クエリを実行することができます。
- 前のセクションで説明したように、ブラウザで MediaSearch finder アプリケーションを開いてください。
- クエリボックスに、
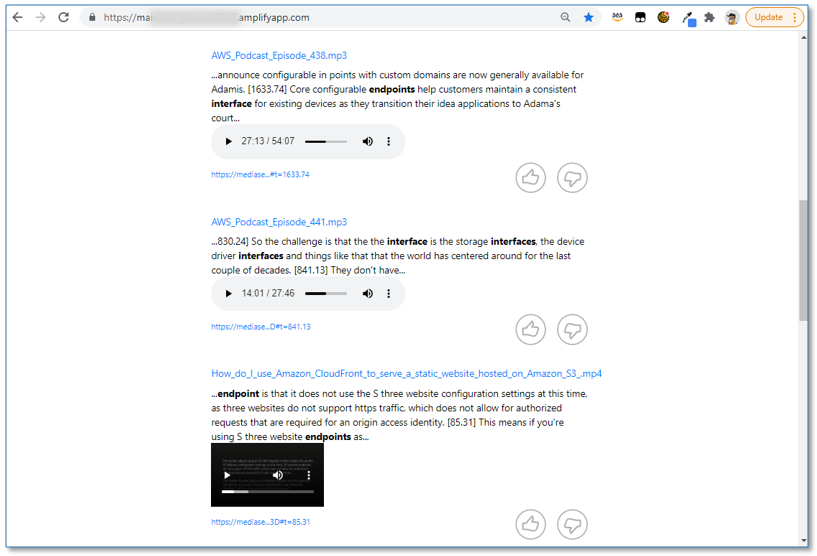
What's an interface VPC Endpoint?と入力します
このクエリーは、サンプル メディア ファイルの文字起こしをソースとして、複数の結果を返します。 - 回答テキストの各文章の冒頭にあるタイムマーカーを確認してください。これは、元のメディアファイルのどこに答えがあるのかを示しています。
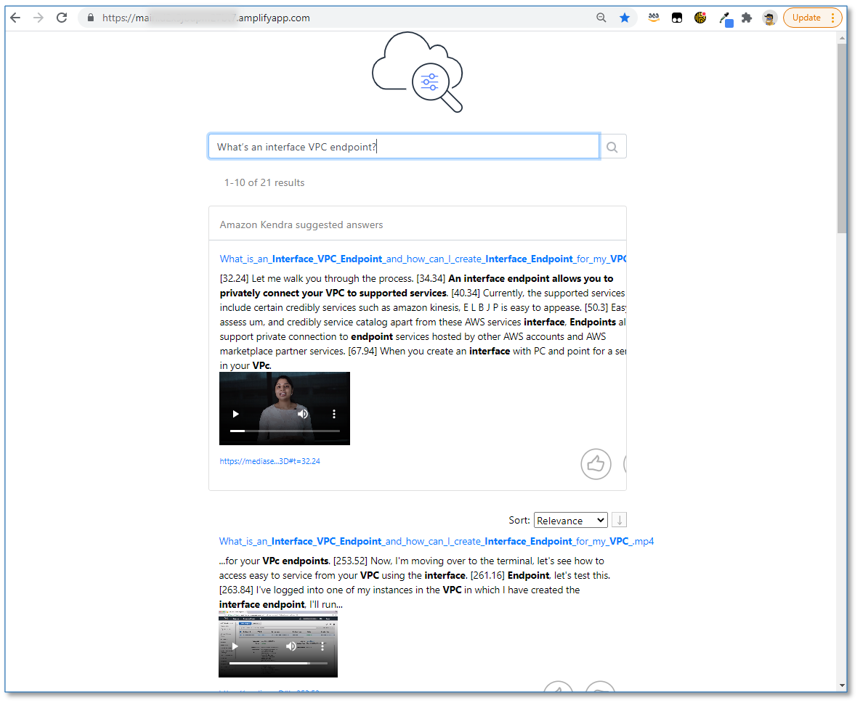
- 埋め込み動画プレーヤーを使って、オリジナルの動画をインラインで再生してください。メディア再生は、タイムマーカーに基づく動画の関連するセクションで開始されることを確認してください。
- 新しいブラウザのタブで動画をフルスクリーン再生するには、プレーヤーのフルスクリーンメニューオプションを使用するか、回答文の上に表示されているメディアファイルのハイパーリンクを選択します。
- 動画ファイルのハイパーリンクを選択し(右クリック)、URL をコピーして、テキストエディターに貼り付けます。以下のようになります
これは、署名済みの S3 URL で、検索結果で参照されたメディアファイルへの一時的な読み取りアクセスをブラウザに提供します。署名付き URL を使用するとインデックスされたすべてのメディアファイルへの永続的なパブリックアクセスを許可せずにすみます。
- ページをスクロールして、音声(MP3)ファイルと動画(MP4)ファイルの検索結果があることを確認してください。
同じインデックスの中で、メディアタイプを混在させることができます。ドキュメント、ウェブページ、その他 Amazon Kendra のデータソースでサポートされているファイルタイプなど、他のデータソースタイプも含めることができ、それらすべてを検索して、Amazon Kendra がクエリに答えるために最適なコンテンツを見つけることができるのです。
ソリューションアーキテクトは何をするのか、Kendra とは何かなど、他のクエリも試してみたり、独自の質問を試してみたりしてください。
独自のメディアファイルのインデックス作成と検索
独自の S3 バケットに保存されたメディアファイルをインデックスするには、indexer コンポーネントスタックをインストールまたは更新するときに、MediaBucket と MediaFolderPrefix パラメータを独自のバケット名とプレフィックスに置き換え、finder コンポーネントスタックをインストールまたは更新するときに MediaBucketNames パラメータを独自のバケット名で変更します。
- 既存の Amazon Kendra
IndexIdを使用して新しい MediaSearch インデックススタックを作成し、新しい場所に保存されているファイルを追加します。新しい indexer をデプロイするには、この記事の indexer コンポーネントのデプロイセクションの指示に従いますが、今回はデフォルトを置き換えて、独自のメディアファイル用のメディアバケット名とプレフィックスを指定します。 - または、既存の MediaSearch indexer スタックを更新して、以前にインデックスされたファイルを新しい場所からのファイルに置き換えます。
- CloudFormation コンソールでスタックを選択し、Update、Use current template、Next の順に選択します。
- 必要に応じて、メディアバケット名とプレフィックスパラメータ値を変更します。
- Next を 2 回選択し、acknowledgement チェックボックスを選択し、Update stack を選択します。
- 既存の MediaSearch finder スタックを更新して、バケット名を変更するか、
MediaBucketNamesパラメータに追加のバケット名を追加します。
MediaSearch indexer スタックが正常に作成または更新されると、indexer は自動的に S3 バケットに保存されているメディアファイルを見つけ、文字起こしし、インデックスを付けます。それが完了すると、クエリを送信して、自分の音声ファイルや動画ファイルのオーディオトラックから答えを見つけることができます。
メディアファイルの一部または全部にメタデータを提供することも可能です。メタデータを使用して、インデックス属性に値を割り当てて検索結果のソート、フィルタリング、ファセット化(訳注:分類。Kendra では属性でグルーピングすることが可能)を行ったり、アクセス制御リストを指定してファイルへのアクセスを管理することができます。メタデータファイルは、メディアファイルと同じ S3 フォルダー(デフォルト)、またはオプションの indexer パラメーター MetadataFolderPrefix で指定される並列フォルダーに格納されます。メタデータファイルの作成方法の詳細については、S3 ドキュメントメタデータを参照してください。
また、メディアファイルの一部または全部に対して、カスタマイズされた文字起こしオプションを適用することができます。これにより、カスタム語彙、自動秘匿化(訳注:翻訳時点では日本語未対応)、およびカスタム言語モデルなどの Amazon Transcribe 機能をフルに活用することができます。詳細については、GitHub リポジトリの README を参照してください。
MediaSearch ソリューションの仕組み
次の図では、ソリューションがどのように機能するか、中身の構成を示しています。

MediaSearch ソリューションは、イベント駆動型のサーバーレスコンピューティングアーキテクチャを採用しており、次のような手順で実行されます。
- インデックスを作成して検索したい音声ファイルや動画ファイルが入った S3 バケットを提供します。
- Amazon EventBridge は、繰り返しの間隔でイベントを生成します(2時間ごと、6時間ごと、など)。
- これらのイベントは、AWS Lambda 関数を呼び出します。この関数は、CloudFormation スタックが最初にデプロイされたときに最初に呼び出され、その後、EventBridge からのスケジュールされたイベントによって呼び出されます。Amazon Kendra データソースの同期ジョブが開始されます。Lambda 関数は、サポートされているすべてのメディアファイル(FLAC、MP3、MP4、Ogg、WebM、AMR、または WAV)と、関連するメタデータおよびユーザーが提供する S3 バケットに格納されている Transcribe オプションを一覧表示します。
- 各新規ファイルは、Amazon DynamoDB のトラッキングテーブルに追加され、Transcribe ジョブによって文字起こしされるよう送信されます。以前に文字起こしされたファイルは、そのファイルが以前に文字起こしされた後に変更された場合、または関連する Transcribe のオプションが更新された場合にのみ、再度文字起こしのために送信されます。DynamoDB のテーブルは、各ファイルの文字起こしの状態と最終更新時刻を反映するように更新されます。S3 バケットに存在しなくなった追跡済みのファイルは、DynamoDB テーブル と Amazon Kendra インデックスから削除されます。新規または更新されたファイルが発見されない場合、Amazon Kendra データソース同期ジョブは直ちに停止されます。DynamoDB テーブルは、各メディアファイルのレコードを保持し、Transcribe ジョブ名とステータス、および最終更新タイムスタンプを追跡するための属性を持ちます。
- 各 Transcribe ジョブが完了すると、EventBridge は Job Complete イベントを生成し、別の Lambda 関数のインスタンスを呼び出します。
- Lambda 関数は、Transcribe ジョブの出力を処理し、各文の先頭にタイムマーカーが挿入された修正済み文字起こしを生成します。この修正された文字起こしは、Amazon Kendra でインデックス化され、ファイルのジョブステータスが DynamoDB テーブルで更新されます。最後のファイルが転記され、インデックスが作成されると、Amazon Kendra データソースの同期ジョブが停止されます。
- インデックスは、MediaSearch indexer コンポーネントによって監視される S3 バケット内のすべてのメディアファイルの文字起こしと、他のプロビジョニングされたデータソースからの任意の追加コンテンツと統合され、同期された状態に保たれます。メディアの文字起こしは、Amazon Kendra のインテリジェントなクエリー処理によって使用され、ユーザーはコンテンツや質問に対する答えを見つけることができます。
- サンプル finder クライアントアプリケーションは、Amazon Kendra の各回答にインラインメディアプレーヤーを埋め込み、文字起こしされたメディアファイルに基づくユーザーの検索体験を向上させます。クライアントは、トランスクリプトに埋め込まれたタイムマーカーを使用して、オリジナルのメディアファイルの関連するセクションでメディアの再生を開始します。
- オプションとして、Cognito ユーザープールを使用してユーザーを認証し、OpenID トークンによるアクセス制御をサポートします(finder クライアントアプリケーションスタックがデプロイされたときに提供される認証およびアクセス制御パラメーターによって決定されます)。
コストの見積もり
MediaSearch ソリューションでは、メディアの保存に関連する Amazon S3 のコストに加えて、Amazon Kendra および Transcribe の使用料が発生します。無料利用枠が使用された後、その他のサービスによって、追加のマイナーな(通常は重要ではない)コストが発生します。詳細については、Amazon Kendra、Transcribe、Lambda、DynamoDB、および EventBridge の価格に関するドキュメントを参照してください。
価格設定の例: サンプルのメディアファイルのインデックス
サンプルデータセットには、13 の音声ポッドキャストと12の動画ファイル、合計約480分または29,000秒の音声を含む25のメディアファイルが含まれています。
MediaSearch のインストール時に既存の Amazon Kendra IndexId を提供しない場合、新しい Amazon Kendra Developer Edition のインデックスが自動的に作成され、ソリューションをテストすることができます。無料利用枠(最初の30日間で750時間まで)を使用した後、インデックスには1時間あたり1.125ドルの費用がかかります。
Transcribe の価格は、文字起こしされた音声の秒数に基づいており、最初の 12 ヶ月間は、1 ヶ月あたり 60 分の音声を無料 Tier の許容範囲としています。無料レベルを使い切った後は、書き起こした音声の 1 秒ごとに $0.00040 の費用がかかります。無料利用枠対象外となった場合、サンプルファイルの書き起こしにかかる費用は以下の通りです。
- 音声の合計秒数 = 29,000
- 1秒あたりのトランスクライブの価格 = $0.00040
- トランスクライブの合計コスト = [秒数] x [秒あたりのコスト] = 29,000 x $0.00040 = $11.60
モニターとトラブルシューティング
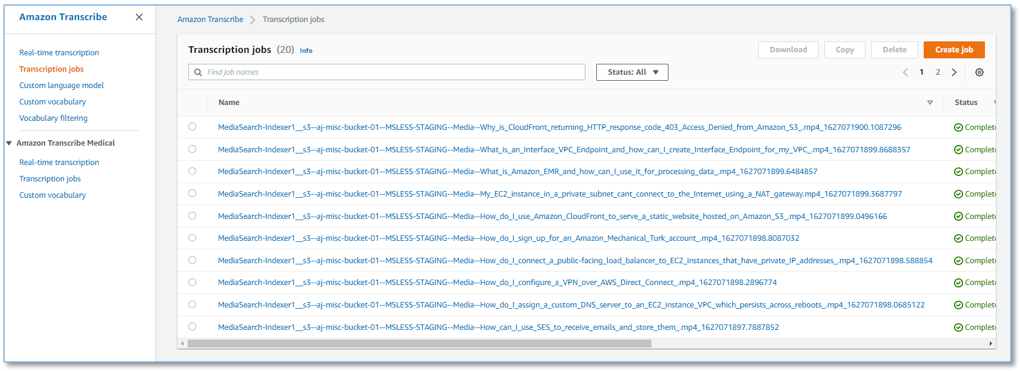
各メディアファイルの文字起こしジョブの詳細を見るには、Transcribe コンソールの Transcription jobs ページに移動してください。
各メディア ファイルは、ファイルが変更されない限り、1 回のみ文字起こしされます。変更されたファイルは、再度文字起こしされ、変更を反映するためにインデックスが付け直されます。
文字起こしを確認し、ジョブの詳細を調べるには、任意の文字起こしジョブを選択します。
Amazon Kendra コンソールの Indexes ページで、MediaSearch が使用するインデックスを選択して、インデックスの詳細を確認します。
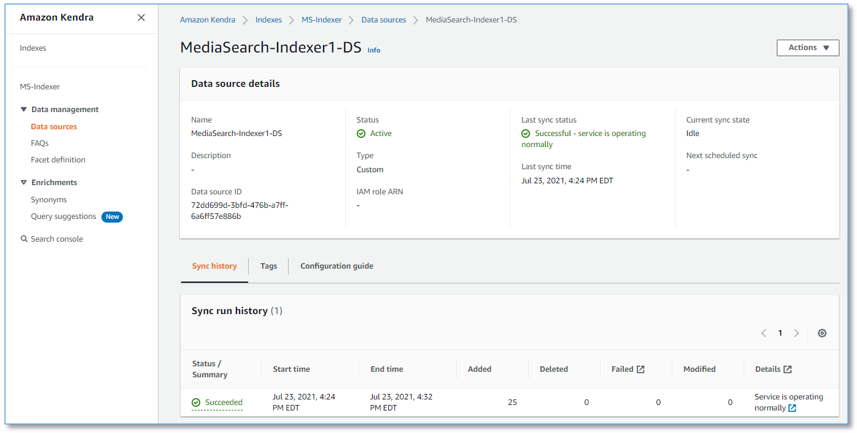
ナビゲーションペインで Data sources を選択して、MediaSearch indexer データソースを調べ、データソース同期実行履歴を観察します。ソリューションのデプロイ時または最終更新時に CloudFormation スタックパラメーターで指定された間隔ごとに indexer が実行されると、データソースが同期されます。
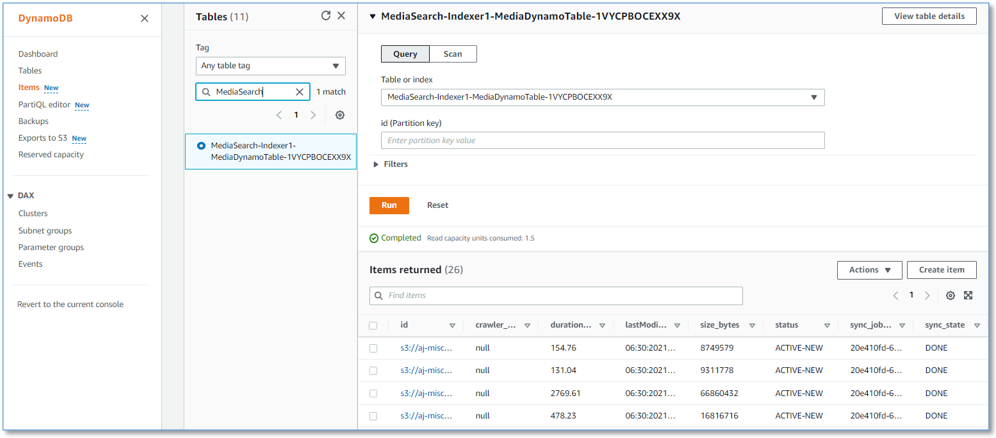
DynamoDB コンソールで、ナビゲーションペインの Tables を選択します。MediaSearch スタック名をフィルターとして使用して MediaSearch DynamoDB テーブルを表示し、インデックスされた各メディアファイルと対応するステータスを示す項目を確認します。テーブルには、メディアファイルごとに1つのレコードがあり、ファイルやその処理状況に関する情報を持つ属性が含まれています。
Lambda コンソールの Functions ページで、MediaSearch スタック名をフィルターとして使用して、前述の 2 つの MediaSearch indexer 関数を一覧表示します。
いずれかの関数を選択すると、環境変数やソースコードなど、関数の詳細を確認することができます。CloudWatch の Monitor & View logs を選択して、各関数呼び出しの出力を調べ、問題があればトラブルシュートします。
ソリューションのカスタマイズと強化
また、あなたは MediaSearch GitHub リポジトリをフォークして、コードを拡張し、プルリクエストを送信することが可能です。それにより私たちは、あなたの改善をシェアすることができます。
以下は、あなたが実装したいかもしれない機能のためのいくつかの提案です。
- Amazon Kendra メタデータを追加して、フィルタとファセットを使用して検索を強化するか、または Amazon Comprehend を MediaSearch indexer と統合して、検出されたエンティティを使用してフィルタとファセットを自動的に作成することでさらに踏み込みます。詳細については、自動コンテンツエンリッチメントによるインテリジェントな検索ソリューションを構築するを参照してください。
- 例えば、QnABot を MediaSearch インデックスと統合し、ユーザーがウェブページ、Slack、または Amazon Connect コンタクトセンターのチャットボットを介してメディアソースアンサーを取得できるようにします。
- Amazon CloudWatch のメトリクスとダッシュボードを構築して、MediaSearch の管理性を向上させる。
クリーンアップ
このソリューションの実験が終わったら、AWS CloudFormation コンソールを使用して、デプロイした indexer と finder スタックを削除することによって、リソースをクリーンアップしてください。これは、ソリューションのデプロイによって作成された Amazon Kendra インデックスを含む、すべてのリソースを削除します。既存のインデックスは削除されません。しかし、ソリューションによってインデックスされたメディアファイルは、indexer スタックを削除すると、既存のインデックスから削除されます。
結論
Amazon Transcribe と Amazon Kendra の組み合わせは、メディアファイルを発見可能にするためのスケーラブルでコスト効率の良いソリューションを実現します。メディアファイルの内容を利用して、ユーザーの質問に対する正確な答えを、テキスト文書からでもメディアファイルからでも見つけ出し、そのネイティブフォーマットで消費することができます。つまり、このソリューションは、メディアファイルを情報の入れ物としてテキスト文書と同等にするための飛躍的な進歩なのです。
MediaSearch アプリケーションのサンプルは、オープンソースとして提供されています。これを出発点として独自のソリューションを構築し、GitHub のプルリクエストを通じて修正や機能追加を行うことで、より良いものにすることができます。専門家によるサポートについては、AWS プロフェッショナルサービスや他の Amazon パートナーによる支援が可能です。
私たちはあなたの意見を聞きたいと思っています。MediaSearch GitHub リポジトリ内の issue フォーラムでご意見をお聞かせください。
執筆者について
 Bob Strahan は、AWS Language AI Services チームのプリンシパルソリューションアーキテクトです。
Bob Strahan は、AWS Language AI Services チームのプリンシパルソリューションアーキテクトです。
 Abhinav Jawadekar は、Amazon Web Services のシニアパートナーソリューションアーキテクトとして AWS パートナーのクラウドジャーニーを支援しています。
Abhinav Jawadekar は、Amazon Web Services のシニアパートナーソリューションアーキテクトとして AWS パートナーのクラウドジャーニーを支援しています。
翻訳はソリューションアーキテクト 前川 泰毅 が担当しました。原文はこちらです。