安全なハンズオフデプロイの自動化
ソフトウェアの配信と運用 | レベル 300
はじめに
私は Amazon の就職面接を受けたとき、面接官の 1 人に必ず「どれくらいの頻度で本番環境にデプロイしていますか?」と尋ねました。 当時、私は年に 1〜2 回メジャーリリースを公開する製品に取り組んでいましたが、大きなリリースの間に小さな修正を公開しなければならないこともありました。私は修正を公開するたびに、何時間もかけて慎重に展開しました。次に、ログとメトリックを必死にチェックして、デプロイ後に壊れているものがあるか、それをロールバックする必要があるかどうかを確認しました。
Amazon が継続的なデプロイメントを実践しているという話を目にしたので、面接を受けたとき、Amazon のデベロッパーとしてデプロイメントの管理と監視にどれだけの時間を費やしているかを知りたいと思いました。面接官は、変更は継続的なデプロイメントパイプラインによって 1 日に複数回、本番環境に自動的にデプロイされると言っていました。彼が 1 日中どれだけ慎重にそれらの各デプロイを導き、私が行っていたように、ログとメトリックの影響を監視するのにどれだけの時間を費やされたのか尋ねたところ、通常は何もしていないという答えが返ってきました。パイプラインがチームのためにこの作業を行ったので、ほとんどのデプロイメントは積極的に監視されていませんでした。「素晴らしいですね」 私はそう言いました。私が Amazon に入社した後、私はこれらの「ハンズオフ」自動デプロイの仕組みを正確に知ることができると思い、とても嬉しかったです。
Amazon での安全な継続的デプロイメント
それ以来、Amazon が継続的なデプロイパイプラインをセットアップして、迅速かつ安全にデプロイできるようにする方法を直接目にしてきました。私たちの継続的なデプロイメントにおける安全対策により、デベロッパーがデプロイメントの作業から解放されることに感謝しています。運用コードをサービスのソースコードリポジトリのメインブランチにプッシュすると、通常はプッシュしたことを忘れて次のタスクに進み、チームのパイプラインがその変更について本番環境に引き継ぎます。本番サービスへのコード変更のリリースはパイプラインによって完全に自動化されています。つまり、私や他のデベロッパーが最後にコードに触れたりレビューしたりするのは、ソースコードリポジトリにマージされたときです。
私のチームは、変更を本番環境に安全にデプロイする自動化ステップを使用してそのパイプラインを設定したため、各デプロイメントを監視する必要はありません。パイプラインは、一連のテストとデプロイメントの安全性チェックを通じて最新の変更を実行します。これらの自動化されたステップは、顧客に影響を与える欠陥が生産にまで至るのを避け、顧客が生産に達した場合は欠陥が顧客に及ぼす影響を制限します。デベロッパーとして、私は積極的に監視する必要なく、パイプラインが私の変更を慎重かつ安全に本番環境にデプロイするであろうと信頼できます。
継続的デリバリーへの道のり
Amazon は継続的デリバリーの実践を始めていませんでした。ここのデベロッパーは、本番環境へのコードデプロイメントの管理に何時間も何日も費やしていました。ソフトウェアのデプロイ方法を自動化および標準化し、変更が本番環境に到達するまでの時間を短縮する方法として、全社的に継続的デリバリーを採用しました。時間の経過とともに段階的に構築されたリリースプロセスの改善。デプロイのリスクを特定し、パイプラインの新しい安全自動化を通じてリスクを軽減する方法を見つけました。新しいリスクを特定し、デプロイの安全性を向上させる新しい方法を特定することにより、リリースプロセスを繰り返します。継続的デリバリーへの道のりと、継続的に改善する方法については、Builders’ Library の記事継続的デリバリーによる高速化を参照してください。
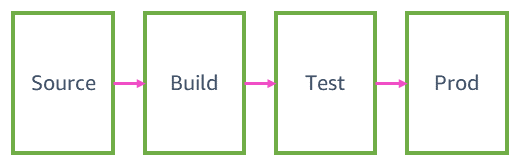
4 つのパイプライン段階
この記事では、Amazon のパイプラインでコードの変更が本番環境に移行するまでの手順を説明します。一般的な継続的デリバリーパイプラインには、ソース、ビルド、テスト、本番 (生産) の 4 つの主要な段階があります。一般的な AWS サービスにおいてこれらの各パイプライン段階で行われる処理について説明し、一般的な AWS サービスチームがパイプラインの 1 つをセットアップする方法の例を示します。
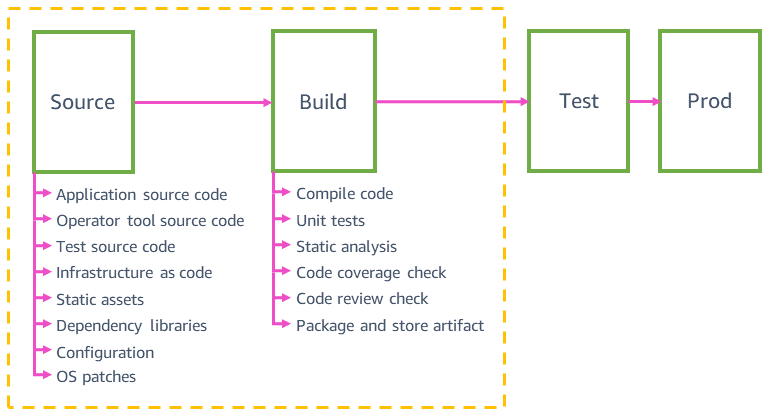
ソースとビルド
次の図は、一般的な AWS サービスチームパイプラインで見つかる可能性があるソースとビルドステップの概要を示しています。
パイプラインソース
Amazon のパイプラインは、アプリケーションコードへの変更だけでなく、あらゆる種類のソース変更を自動的に検証して安全に本番環境にデプロイします。ウェブサイトの静的アセット、ツール、テスト、インフラストラクチャ、構成、およびアプリケーションの基盤となるオペレーションシステム (OS) などのソースへの変更を検証およびデプロイできます。これらの変更はすべて、個々のソースコードリポジトリでバージョン管理されています。ライブラリ、プログラミング言語、AMI ID などのパラメータソースコードの依存関係は、少なくとも毎週、自動的に最新バージョンにアップグレードされます。
これらのソースは、アプリケーションコードのデプロイに使用するのと同じ安全メカニズム (自動ロールバックなど) を使用して個々のパイプラインにデプロイされます。たとえば、実行時に変更できるサービスの構成値 (API レート制限の増加や機能フラグなど) は、専用の構成パイプラインに自動的にデプロイされます。ソースの変更は、サービスの本番環境で問題 (構成ファイルの解析の失敗など) が発生した場合、自動的にロールバックされます。
従来のマイクロサービスには、アプリケーションコードパイプライン、インフラストラクチャパイプライン、OS パッチパイプライン、構成/機能フラグパイプライン、およびオペレーターツールパイプラインがあります。同じマイクロサービスに複数のパイプラインがあると、変更を本番環境に迅速にデプロイする際に役立ちます。統合テストに失敗してアプリケーションパイプラインをブロックするアプリケーションコードの変更は、他のパイプラインに影響を与えません。たとえば、インフラストラクチャパイプラインでの本番環境へのインフラストラクチャコードの変更を阻止しません。同じマイクロサービスのすべてのパイプラインは非常に似ている傾向があります。たとえば、機能フラグパイプラインは、アプリケーションコードパイプラインと同じ安全なデプロイメント手法を使用します。これは、機能フラグの構成の変更が悪いと、アプリケーションコードの変更のように、本番環境に影響を与える可能性があるのが理由です。
コードレビュー
本番環境への変更はすべてコードレビューから始まります。自動的にパイプラインを開始するメインラインブランチ (「メイン」または「トランク」バージョン) にマージする前に、チームメンバーの承認が必要です。パイプラインでは、メインラインブランチでのすべてのコミットをコードで確認し、そのパイプラインのサービスチームのメンバーが承認しなければならないといった要件が適用されます。パイプラインは、レビューされていないコミットのデプロイをブロックします。
完全に自動化されたパイプラインを使用する場合、コードレビューは、コード変更が本番環境にデプロイされる前にエンジニアから受け取る最後の手動レビューと承認であるため、重要なステップになります。コードレビュー担当者は、コードの正確度を評価し、変更を本番環境に安全にデプロイできるかどうかも評価します。また、コードに十分なテスト (単体テスト、統合テスト、カナリアテスト) があるかどうか、デプロイ監視のために十分に装備されているかどうか、そして安全にロールバックできるかどうかを評価します。一部のチームは、次のサンプルのようなカスタムチェックリストを使用します。このリストは、チームの各コードレビューに自動的に追加され、デプロイの安全性懸念を明示的にチェックします。
コードレビューチェックリストの例
## テスト
[ ] この変更のための新しいユニットテストを作成しましたか?
[ ] この変更のための新しい統合テストを作成しましたか?
この変更をテストするためにローカルで実行したテストコマンドを含めてください:
```
mvn テスト & mvn 検証
```
## モニタリング
[ ] この変更は既存のモニタリングの対象になりますか?
(新しい Canary/メトリクス/ダッシュボード/アラームは不要)
[ ] この変更は、リソースや制限に影響を与えない (またはプラスの影響を与える) ですか?
(CPU、メモリ、AWS リソース、他のサービスへの呼び出しを含む)
[ ] この変更をアラームを発生させずに本番環境にデプロイできますか?
## ロールアウト
[ ] 承認後、この変更をすぐにパイプラインにマージできますか?
[ ] すべての依存する変更は既に本番環境にデプロイされていますか?
[ ] この変更を本番環境へのデプロイ後に問題なくロールバックできますか?
ビルドとユニットテスト
ビルド段階では、コードがコンパイルされ、ユニットテストが行われます。ビルドツールとビルドロジックは、言語別やチーム別に異なる場合があります。たとえば、チームは、自分に最適なユニットテストフレームワーク、リンター、および静的分析ツールを選択できます。さらに、チームは、ユニットテストフレームワークにおけるコードカバレッジの最小許容値など、これらのツール構成を選択できます。実行されるテストのツールとタイプも、パイプラインによってデプロイされるコードのタイプによって異なります。たとえば、ユニットテストはアプリケーションコードに使用され、リンターはインフラストラクチャにコードテンプレートとして使用されます。すべてのビルドはネットワークアクセスなしで実行され、ビルドを分離し、ビルドの再現性を高めます。通常、ユニットテストでは、他の AWS サービスなど、依存関係へのすべての API 呼び出しをモック (シミュレーション) します。「ライブ」でモックされていない依存関係とのやりとりは、統合テストのパイプラインで後からテストが行われます。統合テストと比較して、依存関係がモックされたユニットテストは、API 呼び出しから返された予期しないエラーなどのエッジケースを実行し、コードで最適なエラー処理を行うことができます。ビルドが完了すると、コンパイルされたコードがパッケージ化され、署名が行われます。
本番前環境でのデプロイのテスト
パイプラインは、本番環境にデプロイする前に、アルファ、ベータ、ガンマなどの複数の本番前環境で変更をデプロイして検証します。アルファ版とベータ版は、機能的な API テストとエンドツーエンドの統合テストを実行することにより、最新のコードが期待どおりに機能することを検証します。ガンマは、コードが機能していること、およびコードが運用環境に安全にデプロイできることを検証します。ガンマは可能な限り本番環境に似せているため、本番環境と同じデプロイメント構成、同じ監視とアラーム、および同じ継続的なカナリアテストを実施できます。また、ガンマは複数の AWS リージョンにもデプロイされており、リージョンの違いによる潜在的な影響を捉えています。
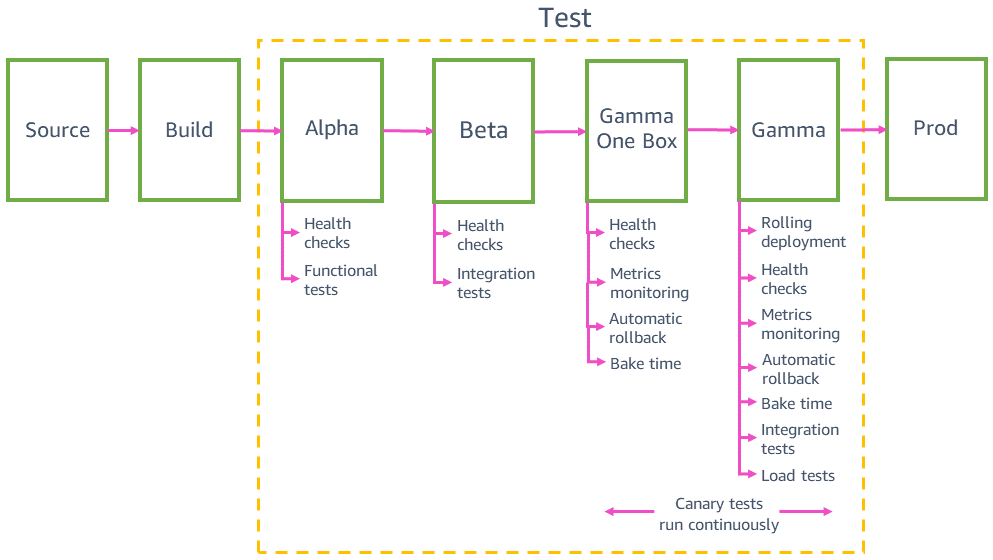
統合テスト
統合テストは、顧客がパイプラインの一部として行うように、サービスを自動的に使用することができます。これらのテストは、すべての有意義な顧客シナリオに対して、本番前の各段階で実際のインフラストラクチャで実行されている実際の API を呼び出すことにより、完全なスタックをエンドツーエンドで実行します。統合テストは、本番環境にデプロイする前に、サービスの予期しない動作または不正な動作を検出することを目的としています。
ユニットテストはモックされた依存関係に対して実行されますが、統合テストは実際の依存関係を呼び出す実動前のシステムに対して実行されるため、これらの依存関係の動作に関するモックの前提を検証します。統合テストでは、さまざまな入力にわたる個々の API 動作を検証します。さらに、新しいリソースの作成、準備が整うまでの新しいリソースの説明、リソースの使用など、複数の API に参加する完全なワークフローを検証します。
統合テストでは、API に無効な入力を提供したり、「無効な入力」エラーが期待どおりに返されることを確認したりするなど、正と負の両方のテストケースを実行します。一部のパイプラインは、ファズテストを実行して可能な API 入力を多く生成し、それらがサービスの内部エラーを引き起こさないことを検証します。一部のパイプラインは、実際の負荷レベルで最新の変更がレイテンシーやスループットのリグレッションを引き起こさないことを確認するために、本番前の段階で短い負荷テストを実行します。
下位互換性とワンボックステスト
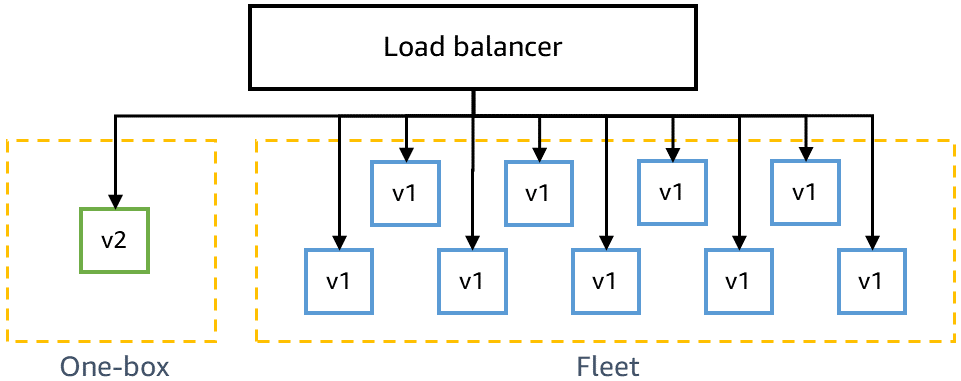
本番環境にデプロイする前に、最新のコードに下位互換性があり、現在のコードと一緒に安全にデプロイできることを確認する必要があります。たとえば、最新のコードが現在のコードで解析できない形式でデータを書き込んでいるかどうかを検出する必要があります。ガンマのワンボックスステージでは、最新のコードを単一の仮想マシンや単一のコンテナなどのデプロイメントの最小単位や、AWS Lambda 関数呼び出しのごく一部にデプロイします。このワンボックスデプロイでは、しばらくの間 (30 分や 1 時間など) 残りのガンマ環境に現在のコードがデプロイされたままになります。トラフィックを特別に 1 つのボックスに誘導する必要はありません。他のガンマ環境と同じロードバランサーに追加したり、同じキューをポーリングしたりできます。たとえば、ロードバランサーの背後にある 10 個のコンテナを備えたガンマ環境では、1 つのボックスが、継続的なカナリアテストによって生成されたガンマトラフィックの 10% を受け取ります。ワンボックスデプロイメントモニターは、カナリアテストの成功率とサービスメトリックを監視して、デプロイメントまたは「混合」フリートを並べて配置することで生じる影響を検出します。
次の図は、新しいコードがワンボックスステージにデプロイされたが、残りのガンマフリートにはまだデプロイされていないガンマ環境の状態を示しています。
また、特定の順序でマイクロサービス全体に変更を加える必要がある場合など、最新のコードにおける依存関係との下位互換性を確保する必要もあります。運用前環境のマイクロサービスは、通常、Amazon Simple Storage Service (S3) や Amazon DynamoDB など、別のチームが所有するサービスの運用エンドポイントを呼び出しますが、同じ段階でサービスチームの他のマイクロサービスの運用前エンドポイントを呼び出します。たとえば、ガンマチームのマイクロサービス A は、同じガンマチームのマイクロサービス B を呼び出しますが、Amazon S3 の本番エンドポイントを呼び出します。
一部のパイプラインは、ゼータと呼ばれる個別の下位互換性の段階で統合テストを再実行します。これは、各マイクロサービスが本番エンドポイントのみを呼び出す個別の環境であり、本番環境への変更が、複数のマイクロサービス全体で本番環境に現在デプロイされているコードと互換性があることをテストします。たとえば、ゼータ内のマイクロサービス A は、マイクロサービス B の製品エンドポイントと Amazon S3 の本番エンドポイントを呼び出します。
下位互換性のある変更を作成してデプロイする方法については、Builders’ Library の記事のデプロイ時におけるロールバックの安全性の確保を参照してください。
本番デプロイ
AWS での本番環境デプロイの最大の目的は、同時に複数のリージョンと同じリージョン内の複数のアベイラビリティーゾーンへの悪影響を防ぐことです。個別デプロイメントの範囲を制限することで、本番デプロイメントの失敗による顧客への潜在的な影響を制限し、マルチアベイラビリティーゾーンまたはマルチリージョンへの影響を防ぎます。自動デプロイの範囲を制限するために、パイプラインの本番段階を多くのステージと個別リージョンへの多くのデプロイに分割します。チームは、パイプライン内の個別アベイラビリティーゾーンまたはサービスの個別内部シャード (セルと呼ばれる) にデプロイすることで、リージョンのデプロイをさらに小規模のデプロイに分割し、失敗した本番デプロイによる潜在的な影響が及ぼす範囲をさらに制限します。
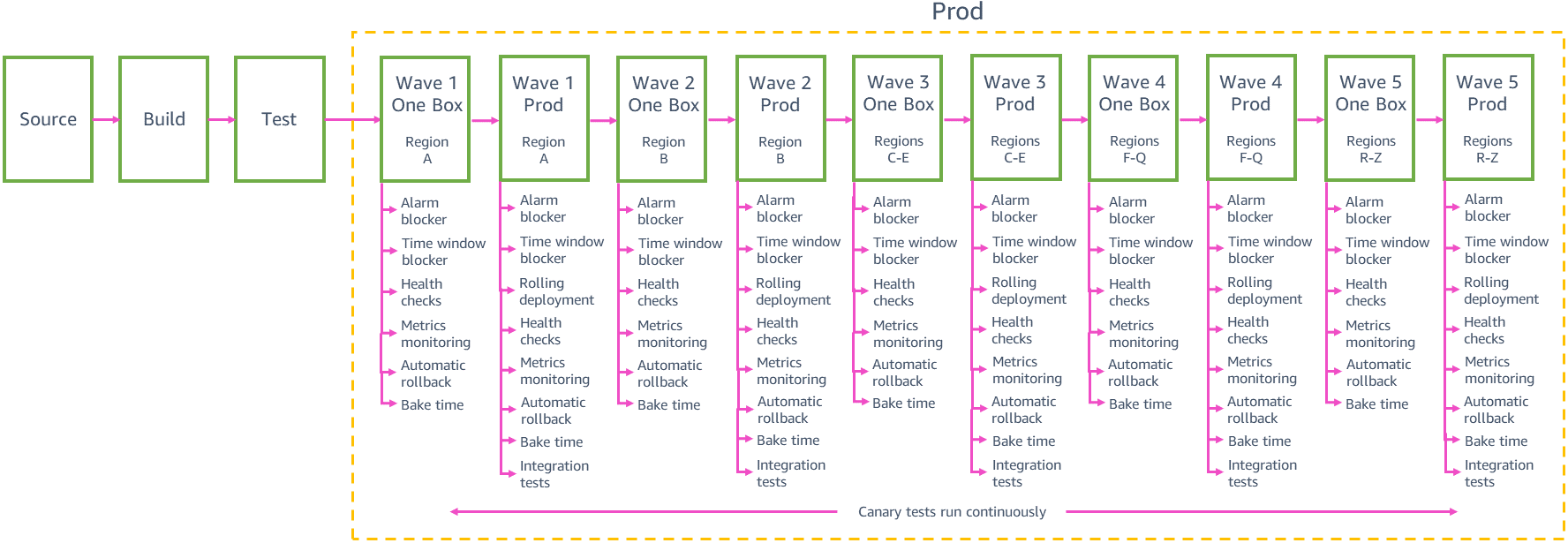
時差デプロイ
各チームは、小規模デプロイの安全性を確保し、すべてのリージョンのお客様に変更を提供できるように速度とのバランスをとる必要があります。パイプラインを介して 24 のリージョンまたは 76 のアベイラビリティーゾーンに変更を 1 つずつデプロイすると、広範囲に影響を与えるリスクが最も低くなりますが、パイプラインがグローバルな顧客に変更を提供するまでに数週間かかる場合があります。前のサンプルの製品パイプラインで、デプロイメントをサイズが増える「ウェーブ」にグループ化すると、デプロイメントのリスクと速度のバランスをとれることがわかりました。パイプラインの各ウェーブステージは、リージョンのグループへのデプロイメントを調整し、ウェーブからウェーブに変更が昇格されます。新しい変更はいつでもパイプラインの本番段階に入る可能性があります。一連の変更がウェーブ 1 の最初のステップから 2 番目のステップに昇格された後、ガンマからの次の一連の変更がウェーブ 1 の最初のステップに昇格されます。したがって、大きなバンドル変更において本番環境へのデプロイを待機中のまま終わることはありません。
パイプラインの最初の 2 つのウェーブは、変更の信頼性を最も高めます。最初のウェーブは、リクエスト数の少ないリージョンにデプロイされ、新しい変更の最初の本番環境デプロイによる影響を制限します。ウェーブは、そのリージョン内で一度に 1 つのアベイラビリティーゾーン (またはセル) のみにデプロイされ、リージョン全体にわたり慎重に変更をデプロイします。次に、2 番目のウェーブは、多数のリクエストがあるリージョンで一度に 1 つのアベイラビリティーゾーン (またはセル) にデプロイされます。この場合、顧客がすべての新しいコードパスを実行する可能性が高く、変更が適切に検証されます。
最初のパイプラインウェーブのデプロイから変更の安全性に対する信頼が高まった後は、同じウェーブでより多くのリージョンに並行してデプロイできます。たとえば、前のサンプルで本番環境パイプラインは、ウェーブ 3 の 3 つのリージョンにデプロイされ、ウェーブ 4 の最大 12 のリージョンにデプロイされ、ウェーブ 5 の残りのリージョンにデプロイされます。これらの各ウェーブにおけるリージョンの正確な数と選択、およびサービスチームのパイプラインにおけるウェーブの数は、個別サービスの使用パターンと規模によって異なります。パイプラインの後半のウェーブは、同じリージョンの複数のアベイラビリティーゾーンへの悪影響を防ぐという目標に役立ちます。ウェーブが複数のリージョンに同時にデプロイされると、最初のウェーブで使用された各リージョンの同じロールアウト動作に慎重に従います。ウェーブの各ステップは、ウェーブの各リージョンでの単一のアベイラビリティーゾーンまたはセルにのみデプロイされます。
ワンボックスデプロイとローリングデプロイ
各運用ウェーブへのデプロイメントは、ワンボックスステージから始まります。ガンマのワンボックスステージと同様に、各運用環境のワンボックスステージは、各ウェーブのリージョンまたはアベイラビリティーゾーンの 1 つのボックス (単一の仮想マシン、単一のコンテナ、または Lambda 関数呼び出しのごく一部) に最新のコードをデプロイします。本番のワンボックスデプロイメントは、最初にそのウェーブの新しいコードによって提供されるリクエストを制限することで、変更によるウェーブへの潜在的な影響を最小限に抑えます。通常、1 つのボックスは、リージョンまたはアベイラビリティーゾーンに対する全体的なリクエストの最大 10% を処理します。変更が 1 つのボックスに悪影響を与える場合、パイプラインは変更を自動的にロールバックし、残りの製品ステージにはプロモートしません。
ワンボックスステージの後、ほとんどのチームはローリングデプロイメントを使用して、ウェーブの本番メインフリートにデプロイします。ローリングデプロイでは、デプロイ全体で本番環境の負荷に対応できる十分な容量がサービスに確保されます。変更による影響を制限するために、新しいコードがサービスに投入される速度 (つまり、本番トラフィックの提供を開始するタイミング) を制御します。リージョンへの従来のローリングデプロイでは、そのリージョン内サービスのボックスの最大 33% (コンテナ、Lambda 呼び出し、または仮想マシンで実行されているソフトウェア) が新しいコードに置き換えられます。
デプロイ中、デプロイシステムは最初にボックスの最大 33% の初期バッチを選択して、新しいコードに置き換えます。交換中は、全体容量の 66% 以上になるのが正常で、リクエストに対応しています。すべてのサービスは、リージョン内のアベイラビリティーゾーンがなくなっても耐えられるようにスケーリングされているため、本サービスはこの容量でも本番環境の負荷に対応できることがわかっています。最初のバッチのボックスが正常性チェックに合格しているとデプロイメントシステムが判断した後、残りのボックスフリートを新しいコードに置き換えることができます。その間も、常にリクエストに対応する容量の最低 66% を維持しています。変更の影響をさらに制限するために、一部チームのパイプラインは、一度に 5% のボックスしかデプロイしません。ただし、それらは高速ロールバックを実行し、システムは一度に 33% のボックスを以前のコードに置き換えて、ロールバックを高速化します。
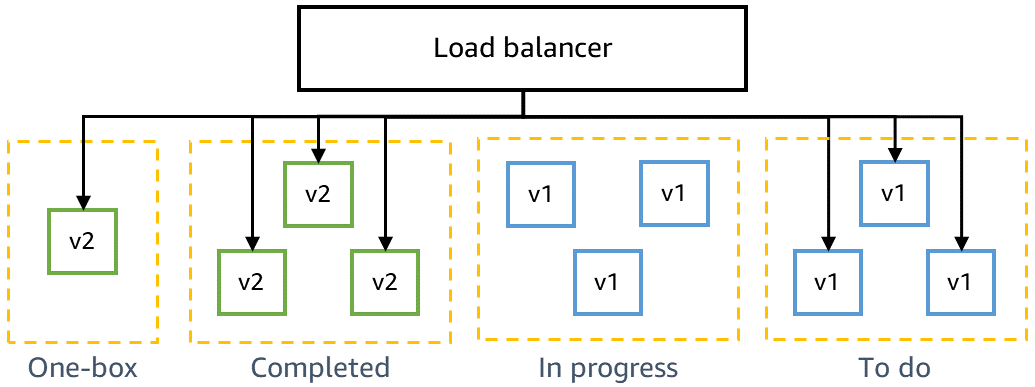
次の図は、ローリングデプロイ中の本番環境の状態を示しています。新しいコードは、ワンボックスステージとメイン製品群の最初のバッチにデプロイされました。別のバッチがロードバランサーから削除され、交換のためシャットダウンされています。
メトリックの監視と自動ロールバック
パイプライン内の自動デプロイメントには、通常、開発のために各デプロイメントを積極的に監視し、指標を確認し、問題が発生したときに手動でロールバックするデベロッパーがいません。これらのデプロイは完全にハンドオフです。デプロイメントシステムは、アラームをアクティブに監視して、デプロイメントを自動的にロールバックする必要があるかどうかを判断します。ロールバックは、以前にデプロイされたコンテナイメージ、AWS Lambda 関数デプロイメントパッケージ、または内部デプロイメントパッケージに環境を切り替えます。パッケージは不変であり、チェックサムを使用して整合性を検証するため、内部デプロイパッケージはコンテナイメージに似ています。
次の例に示すように、各リージョンの各マイクロサービスには、通常、サービスのお客様に影響を与える指標 (障害率や高レイテンシーなど) とシステム正常性指標 (CPU 使用率など) のしきい値でトリガーされる重要度の高いアラームがあります。重要度の高いこのアラームは、待機エンジニアを呼び出し、デプロイが進行中の場合にサービスを自動的にロールバックするために使用されます。多くの場合、待機エンジニアが呼び出されて関与を開始するまでに、ロールバックはすでに進行中です。
重要度の高いマイクロサービスアラームの例
ALARM("FrontEndApiService_High_Fault_Rate") OR
ALARM("FrontEndApiService_High_P50_Latency") OR
ALARM("FrontEndApiService_High_P90_Latency") OR
ALARM("FrontEndApiService_High_P99_Latency") OR
ALARM("FrontEndApiService_High_Cpu_Usage") OR
ALARM("FrontEndApiService_High_Memory_Usage") OR
ALARM("FrontEndApiService_High_Disk_Usage") OR
ALARM("FrontEndApiService_High_Errors_In_Logs") OR
ALARM("FrontEndApiService_High_Failing_Health_Checks")
デプロイによって導入された変更は、アップストリームとダウンストリームのマイクロサービスに影響を与える可能性があるため、デプロイメントシステムは、デプロイ中のマイクロサービスで重要度の高いアラームを監視し、チームの他のマイクロサービスの重要度の高いアラームを監視して、いつロールバックするかを決定する必要があります。デプロイされた変更は継続的なカナリアテストの指標にも影響を与える可能性があるため、デプロイシステムはさらに、失敗したカナリアテストを監視する必要があります。影響を受ける可能性のあるこれらの領域すべてを自動的にロールバックするために、チームは、デプロイシステムが監視する重要度の高い集約アラームを作成します。重要度の高い集約アラームは、次のサンプルのように、チームの個別マイクロサービスで重要度の高いアラームのすべての状態とカナリアアラームの状態を 1 つの集約状態にロールアップします。チームのマイクロサービスで重要度の高いアラームのいずれかがアラーム状態になると、そのリージョン内のすべてのマイクロサービスにわたりチームが進行中のデプロイすべてが自動的にロールバックされます。
重要度の高い集約ロールバックアラームの例
ALARM("FrontEndApiService_High_Severity") OR
ALARM("BackendApiService_High_Severity") OR
ALARM("BackendWorkflows_High_Severity") OR
ALARM("Canaries_High_Severity")
ワンボックスステージは全体的なトラフィックのごく一部を処理するため、ワンボックスデプロイメントによって引き起こされる問題は、サービス重要度の高いロールバックアラームをトリガーしない可能性があります。残りの製品ステージに達する前に、ワンボックスステージで問題の原因となる変更をとらえてロールバックするために、ワンボックスステージはさらに、1 つのボックスのみをスコープとするメトリックをロールバックします。たとえば、1 つのボックスによって具体的に処理されたリクエストの障害率にロールバックします。これは、全体のリクエスト数のわずか一部の割合を占めます。
ワンボックスロールバックアラームの例
ALARM("High_Severity_Aggregate_Rollback_Alarm") OR
ALARM("FrontEndApiService_OneBox_High_Fault_Rate") OR
ALARM("FrontEndApiService_OneBox_High_P50_Latency") OR
ALARM("FrontEndApiService_OneBox_High_P90_Latency") OR
ALARM("FrontEndApiService_OneBox_High_P99_Latency") OR
ALARM("FrontEndApiService_OneBox_High_Cpu_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Memory_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Disk_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Errors_In_Logs") OR
ALARM("FrontEndApiService_OneBox_Failing_Health_Checks")
サービスチームが定義したアラームをロールバックするだけでなく、デプロイシステムは、内部のウェブサービスフレームワークが発行する一般的なメトリクスの異常を検出して自動的にロールバックすることもできます。ほとんどのマイクロサービスは、リクエスト数、リクエストレイテンシー、障害数などのメトリックを標準形式で送信します。これらの標準メトリックを使用すれば、デプロイメント中にメトリックに異常がある場合、デプロイメントシステムは自動的にロールバックできます。この例としては、リクエスト数が突然ゼロになった場合や、レイテンシーや障害の数が通常よりも大幅に増加した場合などです。
ベイク時間
デプロイによって引き起こされる悪影響がすぐに明らかにならない場合があります。ゆっくり待ちます。特にその時点でサービスの負荷が低い場合は、デプロイ中にすぐには表示されません。デプロイが完了した直後に次のパイプラインステージに変更を昇格すると、最初のリージョンに影響が現れるまでに、複数のリージョンに影響が及ぶ可能性があります。次の本番ステージへの変更を促進する前に、パイプラインの各製品ステージには待機時間があります。これは、デプロイが完了した後、次のステージに進む前に、パイプラインが重要度の高いチームの集約アラームを監視して、書き込み速度の低下による影響がないかどうかを確認するために設けられます。
デプロイメントの待機に費やす時間を計算するには、複数のリージョンへの変更を早急に促進した場合に広範囲にわたる影響を引き起こすリスクと、グローバルに顧客に変更を提供する速度のバランスをとる必要があります。これらのリスクのバランスをとるためには、変更の安全性に対する信頼を築きながら、パイプラインの初期ウェーブの待機時間を延長し、その後のウェーブの待機時間を短縮します。当社の目標は、複数のリージョンに影響を与えるリスクを最小限に抑えることです。ほとんどのデプロイはチームメンバーによって積極的に監視されていないため、通常のパイプラインでのデフォルトの待機時間は控えめで、約 4〜5 営業日ですべてのリージョンに変更をデプロイします。より大規模なサービスや非常に重要なサービスでは、パイプラインがグローバルに変更をデプロイする際に、控えめにとらえた待機時間がさらに長くなります。
従来のパイプラインでは、各ワンボックスステージの後から 1 時間以上、最初のリージョンウェーブの後から 12 時間以上、および残りの各リージョンウェーブの後から 2〜4 時間以上待機し、個々のリージョンやアベイラビリティーゾーン、および各ウェーブ内のセルでの待機時間をさらに伴います。待機時間には、チームのメトリックスで特定数のデータポイントを待機するための要件が含まれ (例: 「API 作成まで 100 件以上のリクエストを待機する」)、新しいコードが完全に実行された可能性が高いほど十分なリクエストが発生しました。全体の待機時間中、重要度の高いチームの集約アラームがアラーム状態になると、デプロイメントは自動的にロールバックされます。
非常にまれですが、緊急の変更 (サービスの可用性に影響する大規模なイベントのセキュリティ修正や緩和策など) は、パイプラインが変更を待機して通常デプロイにかかる時間よりも早く顧客に配信する必要があります。この場合、パイプラインの待機時間を控えめにしてデプロイを加速できますが、これを行うには、変更についての高度な調査が必要です。これらのケースでは、組織の主任エンジニアの検査が必要です。チームは、運用安全性の専門家として非常に豊富な経験を積んでいるデベロッパーと共に、コードの変更、およびその緊急性と影響によるリスクを確認する必要があります。変更は通常どおりパイプラインの同じステップを通過しますが、より迅速に次のステージに昇格されます。現在の問題に対処するために必要な最小限のコード変更のみを許可し、積極的にデプロイメントを監視することで、この期間中のパイプラインで飛行中の変更を制限することにより、デプロイメントを高速化するリスクを管理します。
アラームおよび時間枠ブロッカー
パイプラインは、否定的な影響を引き起こすリスクが高い場合に、本番環境への自動デプロイメントを防止します。パイプラインは、デプロイのリスクを評価する一連の「ブロッカー」を使用します。たとえば、現在の環境で問題が発生しているときに、本番環境に新しい変更を自動的にデプロイすると、影響が悪化したり、長期化したりする可能性があります。本番ステージへの新しいデプロイメントを開始する前に、パイプラインは重要度の高いチームの集約アラームをチェックして、アクティブな問題があるかどうかを判断します。アラームが現在アラーム状態にある場合、パイプラインは変更が先に進むのを防ぎます。パイプラインはまた、別のチームのシステムに広範囲の影響があるかどうかを示す大規模なイベントアラームなど、組織全体のアラームをチェックし、全体的な影響につながる可能性のある新しいデプロイメントの開始を防止できます。重要度の高い問題を解決するために本番環境に変更をデプロイする必要がある場合、デベロッパーはこれらのデプロイメントブロッカーを上書きできます。
パイプラインは、デプロイメントの開始をいつ許可するかを定義する一連の時間枠で構成されます。時間枠を設定する場合、デプロイリスクの 2 つの原因のバランスをとる必要があります。一方、時間枠が非常に小さく指定されていると、時間枠外にパイプラインに変更が山積みになる可能性があります。この場合、時間枠内に次のデプロイでこれらの変更のいずれかが影響を与える可能性が高くなります。一方、通常の営業時間を超えるほど時間枠が非常に長い場合は、デプロイの失敗による影響が長引くリスクが高まります。営業時間外は、待機エンジニアと他のチームメンバーが作業している日中よりも、待機エンジニアと契約する際に時間がかかります。通常の営業時間中は手動での回復手順が必要な場合に備えて、デプロイが失敗した後、チームがより迅速に関与できます。
ほとんどのデプロイはチームメンバーが積極的に監視していません。そのため、デプロイのタイミングを最適化して、自動ロールバック後の復旧に手動アクションが必要な場合に、待機エンジニアの介入にかかる時間を最小限に抑えます。待機エンジニアが通常、夜間、祝日、週末に勤務する場合は時間がかかるため、これらの時間は時間枠から除外されます。サービスの使用パターンによっては、デプロイ後の数時間内に問題が表面化されない場合があります。そのため、多くのチームは、金曜日の午後遅くのデプロイを時間枠から除外して、デプロイ後の夜間または週末に待機エンジニアを雇う必要があるリスクを軽減しています。この一連の時間枠により、手動での対応が必要な場合でも復旧を迅速に行えるようになり、通常の勤務時間外の待機エンジニアとのやり取りが少なくなります。これにより、時間枠外でも少数の変更が確実にまとめられます。
コードとしてのパイプライン
従来の AWS サービスチームは、チームの複数のマイクロサービスとソースタイプ (アプリケーションコード、インフラストラクチャコード、OS パッチなど) をデプロイするための多くのパイプラインを所有しています。各パイプラインには、増え続けるリージョンとアベイラビリティーゾーンのための多くのデプロイステージがあります。これは、チームがパイプラインシステム、デプロイシステム、およびアラームシステムで管理を行うための多くの構成、および最新のベストプラクティス、そして新しいリージョンとアベイラビリティーゾーンを最新に保つための多くの努力につながります。過去数年間、私たちはこの構成をコードでモデル化することにより、安全な最新パイプラインをより簡単かつ一貫して構成する方法として、「コードとしてのパイプライン」を実践することを導入してきました。当社のコードツールとしての内部パイプラインは、リージョンとアベイラビリティーゾーンの集中リストからプルし、AWS 全体のパイプラインに新しいリージョンとアベイラビリティーゾーンを簡単に追加します。また、このツールを使用すれば、チームは継承を使ってパイプラインをモデル化し、親クラスのチームのパイプライン全体に共通の構成 (各ウェーブで、実行するリージョンや各ウェーブのベイク時間など) を定義し、すべての共通構成を継承するサブクラスとしてすべてのマイクロサービスパイプライン構成を定義できます。
まとめ
Amazon では、デプロイの安全性とデプロイ速度のバランスをとることに基づいて、自動化されたデプロイ方法を構築してきました。同時に、デベロッパーがデプロイについて費やす時間を最小限に抑えたいと考えています。運用前の広範囲テスト、自動ロールバック、および段階的な運用デプロイを使用し、リリースプロセスに自動デプロイの安全性を組み込むことで、デプロイによる運用上の潜在的な影響を最小限に抑えることができます。つまり、デベロッパーは本番環境へのデプロイを積極的に監視する必要はありません。
完全に自動化されたパイプラインにより、デベロッパーはコードレビューを使用してコードをチェックし、変更が本番環境に移行する準備ができていることを承認します。変更がソースコードリポジトリにマージされた後、デベロッパーは次のタスクに進み、デプロイメントを忘れて、パイプラインを信頼して本番環境への変更を安全かつ慎重に行うことができます。自動化されたパイプラインは、安全性と速度のバランスを取りながら、1 日に数回連続して本番環境にデプロイする処理を行います。コードで継続的デリバリーをモデル化することにより、AWS サービスチームがパイプラインをセットアップして、コードの変更を自動かつ安全にデプロイすることがこれまでになく簡単になりました。
参考文献
Amazon がどのようにしてサービスのセキュリティと可用性を向上させながら、お客様の満足度とデベロッパーの生産性を高めているかについての詳細は、継続的デリバリーによる高速化を参照してください
下位互換性のある変更を作成してデプロイする方法については、Builders’ Library の記事のデプロイ時におけるロールバックの安全性の確保を参照してください
著者について
Clare Liguori は AWS のプリンシパルソフトウェアエンジニアです。Clare は現在 AWS コンテナサービスのデベロッパーエクスペリエンスに焦点を当てており、コンテナの挿入と、ローカル開発、Infrastructure as Code (IaC)、CI/CD、オブザーバビリティ、および運用といったソフトウェア開発ライフサイクルにおけるツールを構築しています。

関連コンテンツ
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください