分散システムの課題
アーキテクチャ | レベル 200
はじめに
Amazon が 2 台目のサーバーを追加した時から、分散システムは Amazon で馴染み深いものになりました。私が 1999 年に Amazon に入社したとき、サーバーの数が非常に少なかったため、「fishy」や「online-01」などのわかりやすい名前を付けることができました。けれども、1999 年であっても、分散コンピューティングは容易ではありませんでした。また現時点で、分散システムの課題には、レイテンシー、スケーリング、ネットワーキング API の理解、データのマーシャリングとアンマーシャリング、および Paxos などのアルゴリズムの複雑さが含まれます。システムが急速に大きくなり、分散するにつれて、理論的なエッジケースであったものが定期的に発生しました。
信頼できる長距離電話ネットワークや Amazon Web Services (AWS) のサービスといった分散ユーティリティコンピューティングサービスの開発は困難です。分散コンピューティングは、相互に関連する 2 つの問題があるため、他の形式のコンピューティングよりも奇妙で、それほど直感的ではありません。 独立した障害および非決定性は、分散システムで最も影響の大きい問題を引き起こします。ほとんどのエンジニアが慣れている典型的なコンピューティング障害に加えて、分散システムの障害は他の多くの方法で発生する可能性があります。さらに悪いことに、何かが失敗したかどうかを常に知ることは不可能です。
Amazon Builders のライブラリ全体で、分散システムから生じる複雑な開発および運用の問題を AWS がどのように処理するかについて説明しています。他の記事でこれらの技法を詳しく説明する前に、分散コンピューティングがなぜそれほど奇妙なのかを説明する概念を確認するのがよいでしょう。まず、分散システムのタイプを確認しましょう。
分散システムのタイプ
分散システムは実際に実装の難しさが異なります。スペクトルの一端に、オフライン分散システムがあります。これには、バッチ処理システム、ビッグデータ分析クラスター、映画シーンレンダリングファーム、タンパク質フォールディングクラスターなどが含まれます。オフライン分散システムは、実装するのは簡単ではありませんが、分散コンピューティングの利点 (スケーラビリティと耐障害性) のほとんどすべてを享受し、欠点 (複雑な障害モードと非決定性) はほとんどありません。
スペクトルの中央には、ソフトリアルタイム分散システムがあります。これは継続的に結果を生成または更新する必要がある重要なシステムですが、そのためには比較的寛大な時間枠があります。このシステムの例には、検索インデックスビルダー、障害のあるサーバーを探すシステム、Amazon Elastic Compute Cloud (Amazon EC2) のロールなどが含まれます。検索インデクサーは、お客様に過度の影響を与えることなく、アプリケーションに応じて 10 分から数時間オフラインになる場合があります。Amazon EC2 のロールは、更新された資格情報を (ほぼ) すべての EC2 インスタンスにプッシュする必要がありますが、古い資格情報はしばらく期限切れにならないため、そうする時間があります。
最も遠く、最も困難なスペクトルの終わりには、ハードリアルタイム分散システムがあります。これは多くの場合、要求/応答サービスと呼ばれます。Amazon では、分散システムの構築について考えるとき、ハードリアルタイムシステムが最初に考えられるタイプです。残念ながら、ハードリアルタイムの分散システムは適切に運用するのが最も困難な分散システムです。困難にしているのは、要求が予期せず到着し、応答を迅速に提供する必要があることです (たとえば、顧客が応答を積極的に待っているため)。例としては、フロントエンドウェブサーバー、注文パイプライン、クレジットカードトランザクション、すべての AWS API、テレフォニーなどが挙げられます。この記事は、主にハードリアルタイム分散システムに焦点を当てます。
ハードリアルタイムシステムは奇妙です
コミックの『スーパーマン』のあるストーリーでは、スーパーマンは、すべてが常軌を逸している惑星 (Bizarro World) に住んでいる Bizarro という名の分身に出会います。Bizarro はスーパーマンに見た目は似ていますが、実際は悪者です。ハードリアルタイム分散システムもその例にならいます。ハードリアルタイム分散システムは通常のコンピューティングのように見えますが、実際には異なっており、率直に言って、少し悪側にあります。
ハードリアルタイム分散システムの開発は、要求/応答ネットワークの点で奇妙です。TCP/IP、DNS、ソケット、またはその他のそのようなプロトコルの核心的な詳細のことを指しているのではありません。これらの主題は理解するのが難しい可能性がありますが、コンピューティングの他の難しい問題に似ています。
ハードリアルタイム分散システムを困難にしているのは、ネットワークが障害ドメインから別のドメインへのメッセージ送信を可能にしていることです。メッセージの送信は無害に見えるかもしれません。実際は、メッセージを送信すると、すべてが通常よりも複雑になり始めます。
簡単な例を見るには、Pac-Man の実装からの次のコードスニペットを見てください。単一のマシンで実行することを目的としており、どのネットワークを介してもメッセージを送信しません。
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
次に、このコードのネットワークバージョンを開発することを考えてみましょう。この場合、ボードオブジェクトの状態は別のサーバーで維持されます。findAll() などのボードオブジェクトを呼び出すたびに、2 つのサーバー間でメッセージが送受信されます。
要求/応答メッセージが 2 つのサーバー間で送信されるたびに、少なくとも 8 つのステップの同じセットがいつも発生する必要があります。ネットワーク化された Pac-Man コードを理解するために、要求/応答メッセージングの基本を確認しましょう。
ネットワークを介したメッセージ送信
ネットワークを介したメッセージの要求/応答
1 回の往復の要求/応答アクションには、常に同じ手順が含まれます。次の図に示すように、クライアントマシン CLIENT は、ネットワーク NETWORK を介してサーバーマシン SERVER に要求 MESSAGE を送信します。サーバーマシン SERVER は、ネットワーク NETWORK を介してメッセージ REPLY で応答します。
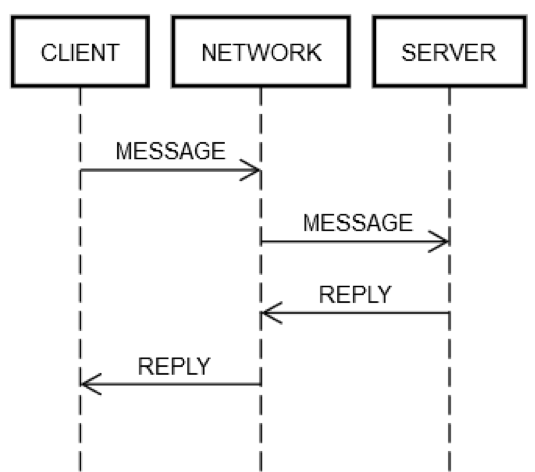
すべてが正常に機能している場合、次の手順が実行されます。
-
POST REQUEST: CLIENT は要求 MESSAGE を NETWORK に置きます。
-
DELIVER REQUEST: NETWORK は、SERVER に MESSAGE を配信します。
-
VALIDATE REQUEST: SERVER は MESSAGE を検証します。
-
UPDATE SERVER STATE: SERVER は、必要に応じて、MESSAGE に基づいてその状態を更新します。
-
POST REPLY: SERVER は、NETWORK に応答 REPLY を送信します。
-
DELIVER REPLY: NETWORK は CLIENT に REPLY を配信します。
-
VALIDATE REPLY: CLIENT は REPLY を検証します。
-
UPDATE CLIENT STATE: CLIENT は、必要に応じて、REPLY に基づいて状態を更新します。
1 回のささいな往復に、上記の数多くのステップを伴います! それでも、これらのステップは、ネットワークを介した要求/応答通信の定義です。それらのいずれもスキップできません。たとえば、ステップ 1 をスキップすることはできません。クライアントは、何らかの方法で MESSAGE をネットワーク NETWORK に配置する必要があります。物理的には、これはネットワークアダプターを介してパケットを送信することを意味します。これにより、CLIENT と SERVER 間のネットワークを構成する一連のルーターを介して電気信号がワイヤ上を移動します。これは、SERVER が突然電源を失い、着信パケットを受け入れることができないなどの独立した理由でステップ 2 が失敗する可能性があるため、ステップ 2 とは別です。同じロジックを残りのステップに適用できます。
したがって、ネットワークを介した単一の要求/応答は、1 つのもの (メソッドの呼び出し) を 8 つのものにします。さらに悪いことに、上記のように、CLIENT、SERVER と NETWORK はお互いに独立して失敗する可能性があります。エンジニアのコードは、前述のステップで失敗したいずれのステップにも対処する必要があります。これは、典型的なエンジニアリングにはほとんど当てはまりません。理由を確認するために、単一マシンバージョンのコードから次の式を確認してみましょう。
board.find("pacman")
技術的には、board.find の実装自体にバグがない場合でも、ランタイム時にこのコードが失敗する可能性のある奇妙な方法がいくつかあります。たとえば、CPU は実行時に自然にオーバーヒートする可能性があります。マシンの電源も自発的に故障する可能性があります。カーネルがパニックに陥る可能性もあります。メモリがいっぱいになり、board.find が作成しようとしたオブジェクトが作成できない可能性があります。または、実行しているマシンのディスクが一杯になり、board.find が統計ファイルの更新に失敗して、エラーが返される可能性があります。ガンマ線がサーバーに衝突し、RAM のビットを反転させる可能性があります。けれども、ほとんどの場合、エンジニアはそれらのことを心配しません。たとえば、ユニットテストは「CPU に障害が発生した場合」のシナリオをカバーせず、メモリ不足のシナリオをカバーすることはほとんどありません。
通常のエンジニアリングでは、これらのタイプの障害は単一のマシンで発生します (つまり、単一の障害ドメイン)。たとえば、CPU が自発的にフライするために board.find メソッドが失敗した場合、マシン全体がダウンしていると想定した方が安全です。そのエラーを処理することは概念的にも不可能です。前述のその他のタイプのエラーについても、同様の仮定を立てることができます。これらのケースのいくつかについてテストを作成することもできますが、通常のエンジニアリングにはほとんど意味がありません。これらの障害が発生した場合、他のすべても失敗すると想定しても安全です。業界用語では、マシン全体で運命を共有すると言います。運命の共有は、エンジニアが処理しなければならないさまざまな障害モードを大幅に削減します。
処理の失敗
ハードリアルタイム分散システムでの障害モードの処理
サーバーとネットワークは運命を共有していないため、ハードリアルタイム分散システムで作業するエンジニアは、ネットワーク障害のあらゆる側面をテストする必要があります。単一マシンの場合とは異なり、ネットワークに障害が発生しても、クライアントマシンは動作し続けます。リモートマシンに障害が発生した場合でも、クライアントマシンは動作し続けます。
前述の要求/応答ステップの失敗事例を徹底的にテストするには、エンジニアは各ステップが失敗する可能性があると想定する必要があります。また、これらの障害に照らして、 (クライアントとサーバーの両方の) コードが常に正しく動作することを保証する必要があります。
物事が機能していない場合の往復要求/応答アクションを見てみましょう。
-
POST REQUEST が失敗: NETWORK がメッセージの配信に失敗した (たとえば、中間ルーターが間が悪い時にクラッシュした) か、SERVER が明示的に拒否した。
-
DELIVER REQUEST が失敗: NETWORK は MESSAGE を SERVER に正常に配信したが、SERVER が MESSAGE を受信した直後にクラッシュした。
-
VALIDATE REQUEST が失敗: SERVER は、MESSAGE が無効であると判断した。原因はほとんど何でもあり得ます。たとえば、破損したパケット、互換性のないソフトウェアバージョン、またはクライアントまたはサーバーのバグなどがあります。
-
UPDATE SERVER STATE が失敗: SERVER はその状態を更新しようとしたが、機能しない。
-
POST REPLY が失敗: 成功または失敗で応答しようとしていたかどうかに関係なく、SERVER は応答の投稿に失敗する可能性があります。たとえば、そのネットワークカードが間が悪い時にフライする場合があります。
-
DELIVER REPLY が失敗: NETWORK が以前のステップで機能していたとしても、NETWORK は前述のように CLIENT に REPLY を配信できない可能性があります。
-
VALIDATE REPLY が失敗: CLIENT が、REPLY が無効であると判断した。
-
クライアント状態の更新に失敗した: CLIENT はメッセージの REPLY を受信できますが、自身の状態の更新に失敗したり、メッセージを理解できなかったり (互換性がないため)、他の何らかの理由で失敗したりします。
これらの障害モードは、分散コンピューティングを非常に困難にするものです。私はそれらを黙示録の 8 つの故障モードと呼んでいます。これらの失敗モードに照らして、Pac-Man コードからこの式をもう一度見てみましょう。
board.find("pacman")
この式は、次のクライアント側アクティビティに展開されます。
-
{action: "find", name: "pacman", userId: "8765309"} などのメッセージをボードマシン宛てのネットワーク上に投稿します。
-
ネットワークが利用できない場合、またはボードマシンへの接続が明示的に拒否されている場合は、エラーが発生します。クライアントは、サーバーマシンが要求を受信できないだろうことを決定論的に知っているため、このケースはやや特殊です。
-
応答を待ちます。
-
応答がない場合は、タイムアウトします。このステップでは、タイムアウトは、要求の結果が UNKNOWN であることを意味します。起こったかもしれないし、起きなかったかもしれません。クライアントは UNKNOWN を正しく処理する必要があります。
-
応答を受信した場合、成功の応答、エラーの応答、または理解できない/破損した応答であるかどうかを判断します。
-
エラーでない場合は、応答を非整列化し、コードが理解できるオブジェクトに変換します。
-
エラーまたは理解できない応答である場合は、例外を発生させます。
-
例外を処理するものはすべて、要求を再試行するか、ゲームをあきらめて停止するかを決定する必要があります。
この式は、次のサーバー側アクティビティも開始します。
-
要求を受信します (これはまったく発生しない場合があります)。
-
要求を検証します。
-
ユーザーを検索して、ユーザーがまだアライブかどうかを確認します。(サーバーは、あまりにも長い間メッセージを受信しなかったため、ユーザーをいないものとして扱った可能性があります)。
-
サーバーが (おそらく) ユーザーがまだいることを認識できるように、ユーザーのキープアライブテーブルを更新します。
-
ユーザーの位置を調べます。
-
{xPos: 23, yPos: 92, clock: 23481984134} のようなものを含む応答を投稿します。
-
それ以降のサーバーロジックは、クライアントの将来の影響を正しく処理する必要があります。たとえば、メッセージの受信に失敗した、受信したが理解できなかった、受信してクラッシュした、または正常に処理したなどです。
要約すると、通常のコードの 1 つの式は、ハードリアルタイム分散システムコードの 15 の追加ステップになります。この拡張は、クライアントとサーバー間の各ラウンドトリップ通信が失敗する可能性がある 8 つの異なるポイントによるものです。board.find (「pacman」) など、ネットワーク上の往復を表す式は、次のようになります。
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
この複雑さは避けられません。コードがすべてのケースを正しく処理しない場合、サービスは最終的に奇妙な方法で失敗します。Pac-Man の例などのクライアント/サーバーシステムが経験する可能性のあるすべての障害モードのテストを作成しようとすることを想像してください。
テスト
ハードリアルタイム分散システムのテスト
Pac-Man コードスニペットの単一マシンバージョンのテストは比較的簡単です。いくつかの異なる Board オブジェクトを作成し、それらを異なる状態に配置し、異なる状態にある User オブジェクトを作成します。エンジニアは、エッジ条件について最も熱心に考え、おそらく生成テストまたはファザーを使用します。
Pac-Man コードには、ボードオブジェクトが使用される場所が 4 つあります。分散 Pac-Man では、コードに 4 つのポイントがあり、前述の 5 つの異なる結果があります (POST_FAILED、RETRYABLE、FATAL、UNKNOWN、または SUCCESS)。これらはテストの状態空間を非常に大きくします。たとえば、ハードリアルタイム分散システムのエンジニアは、多くの順列を処理する必要があります。board.find() の呼び出しが POST_FAILED で失敗したとしましょう。次に、RETRYABLE で失敗したときに何が起こるかをテストし、FATAL で失敗した場合に何が起こるかをテストする必要があります。
しかし、そのテストでさえ不十分です。典型的なコードでは、エンジニアは、board.find() が機能する場合、ボードへの次の呼び出しである board.move() も機能すると想定します。ハードリアルタイム分散システムエンジニアリングでは、そのような保証はありません。サーバーマシンは、いつでも独立して故障する可能性があります。その結果、エンジニアは、ボードへの呼び出しごとに 5 つのケースすべてについてテストを作成する必要があります。エンジニアが Pac-Man の単一マシンバージョンでテストする 10 のシナリオを考えたとしましょう。ただし、分散システムバージョンでは、これらのシナリオのそれぞれを 20 回テストする必要があります。つまり、テストマトリックスは 10 から 200 まで膨れ上がります!
しかし、待ってください、まだあります。エンジニアがサーバーコードを所有している可能性もあります。クライアント、ネットワーク、およびサーバー側のエラーがどのような組み合わせで発生したとしても、クライアントとサーバーが破損状態に陥らないようにテストする必要があります。サーバーコードは次のようになります。
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
テストするサーバー側の関数は 4 つあります。単一のマシン上の各機能にそれぞれ 5 つのテストがあると仮定しましょう。これは 20 のテストです。クライアントは同じサーバーに複数のメッセージを送信するため、テストでは異なる要求のシーケンスをシミュレートして、サーバーが堅牢であることを確認する必要があります。要求の例には、検索、移動、削除、および findAll が含まれます。
1 つの構造に 10 の異なるシナリオがあり、各シナリオに平均 3 つの呼び出しがあるとします。そうすると 30 のテストがさらにあることになります。ただし、1 つのシナリオでは、障害のケースをテストする必要もあります。これらのテストのそれぞれについて、クライアントが 4 つの障害タイプ (POST_FAILED、RETRYABLE、FATAL、および UNKNOWN) のいずれかを受信し、無効な要求でサーバーを再度呼び出した場合に何が起こるかをシミュレートする必要があります。たとえば、クライアントは find を正常に呼び出すことができますが、move を呼び出すと UNKNOWN が返されることがあります。その後、何らかの理由で再度 find を呼び出す可能性があります。サーバーはこのケースを正しく処理するでしょうか? おそらく、けれどもそれをテストしない限りわかりません。そのため、クライアント側のコードと同様に、サーバー側のテストマトリックスも複雑になります。
未知のものを未知のものとして扱う
未知のものを未知のものとして扱う
分散システムで発生する可能性のある障害のすべての順列、特に複数の要求で発生する順列を考慮するのは気が遠くなります。分散エンジニアリングにアプローチする 1 つの方法は、すべてに不信感を抱くことです。コードのすべての行は、ネットワーク通信を引き起こさない可能性がある場合を除き、本来の動作をしない場合があります。
おそらく最も難しいのは、前のセクションで説明した UNKNOWN エラータイプです。クライアントは、要求が成功したかどうかを常に把握しているわけではありません。Pac-Man を移動させた (または、銀行サービスでは、ユーザーの銀行口座からお金を引き出した) かもしれず、また移動させなかったかもしれません。エンジニアはそれをどう処理したらよいのでしょうか? エンジニアは人間であり、人間は真の不確実性と戦う傾向があるため、それは困難です。人間は次のようなコードを見ることに慣れています。
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
人間がこのコードを理解するのは、動作するように見える動作をするからです。人間は、コードの分散バージョンに苦労します。これにより、一部の作業をサービスに分散します。
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
人間が UNKNOWN を正しく処理する方法を理解することはほとんど不可能です。UNKNOWN とはどういう意味でしょうか? コードを再試行する必要があるでしょうか? もしそうなら、何回再試行すればよいのでしょうか? 再試行の間隔は? コードに副作用があると、さらに悪化します。次の例に示すように、1 台のマシンで実行されている予算作成アプリケーションの内部では、口座からお金を引き出すのは簡単です。
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
ただし、そのアプリケーションの分散バージョンは UNKNOWN であるため奇妙です。
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
UNKNOWN エラータイプの処理方法を理解することが、分散エンジニアリングにおいて、ものが常に見かけどおりであるとは限らない 1 つの理由です。
群れ
ハードリアルタイム分散システムの群れ
黙示録の 8 つの障害モードは、分散システム内の任意の抽象化レベルで発生する可能性があります。前の例は、単一のクライアントマシン、ネットワーク、および単一のサーバーマシンに限定されていました。その単純なシナリオでさえ、障害状態マトリックスは複雑になりました。実際の分散システムには、単一のクライアントマシンの例よりも複雑な障害状態マトリックスがあります。実際の分散システムは、複数の抽象化レベルで表示できる複数のマシンで構成されています。
-
個々の機械
-
マシンのグループ
-
マシンのグループのグループ
-
その他 (潜在的に)
たとえば、AWS で構築されたサービスは、特定のアベイラビリティーゾーン内のリソースの処理専用のマシンをグループ化する可能性があります。他の 2 つのアベイラビリティーゾーンを処理するマシンのグループがさらに 2 つある場合もあります。次に、それらのグループは AWS リージョングループにグループ化される場合があります。そして、そのリージョングループは他のリージョングループと (論理的に) 通信する可能性があります。残念ながら、このより高い、より論理的なレベルでさえ、すべて同じ問題が起こり得ます。
サービスがいくつかのサーバーを単一の論理グループ GROUP1 にグループ化したとします。グループ GROUP1 は、別のサーバーグループ GROUP2 にメッセージを送信する場合があります。これは、再帰的分散エンジニアリングの例です。前述のすべての同じネットワーク障害モードがここで適用できます。GROUP1 が GROUP2 に要求を送信するとします。次の図に示すように、2 台のマシンの要求/応答のやり取りは、前述の単一のマシンのやり取りとまったく同じです。
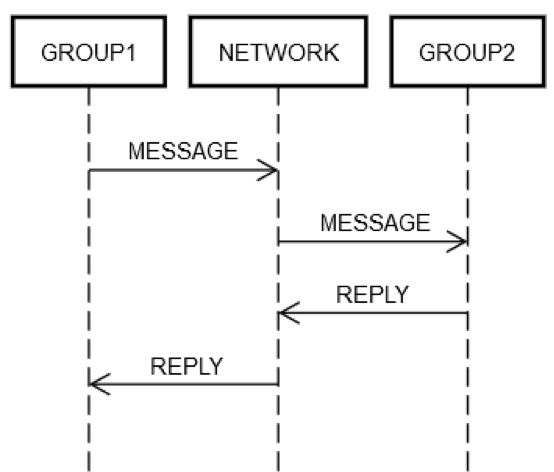
何らかの方法で、GROUP1 内の一部のマシンは、ネットワーク (NETWORK) 上にメッセージ を (論理的に) GROUP2 に送信する必要があります。GROUP2 内の一部のマシンは要求を処理等する必要があります。GROUP1 と GROUP2 がマシンのグループで構成されているという事実により、基本は変わりません。GROUP1、GROUP2、および NETWORK は、互いに独立して失敗する可能性があります。
ただし、それは単なるグループレベルのビューです。また、各グループ内でマシン間レベルの相互作用があります。例えば、GROUP2 は、次の図に示すように構成できます。
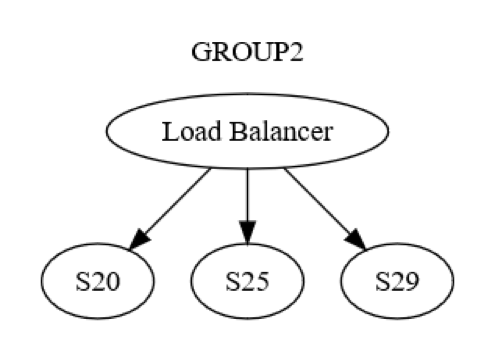
最初に、GROUP2 へのメッセージが、ロードバランサーを介して、グループ内の 1 台のマシン (おそらく S20) に送信されます。システムの設計者は、UPDATE STATE フェーズ中に S20 が失敗する可能性があることを知っています。その結果、S20 はメッセージを少なくとも 1 つの他のマシン (ピアの 1 つまたは異なるグループのマシン) に渡す必要がある場合があります。S20 は実際にどのようにこれを行うのでしょうか? 次の図に示すように、たとえば S25 に要求/応答メッセージを送信します。
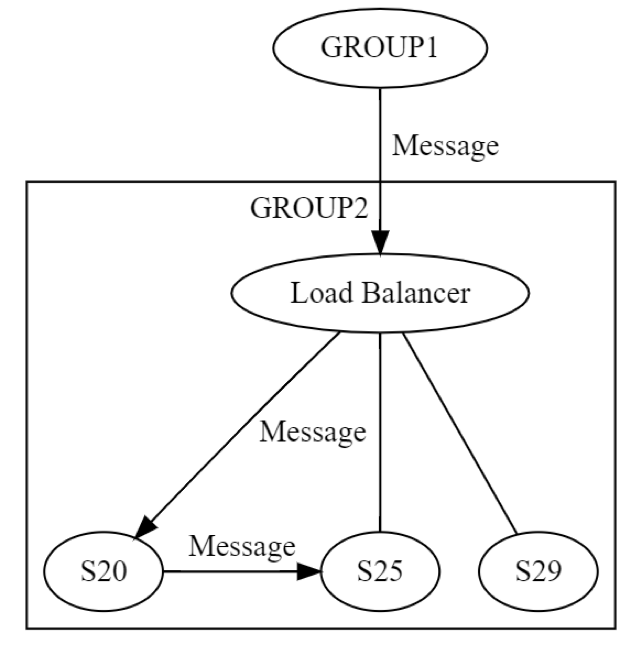
したがって、S20 はネットワークを再帰的に実行しています。同じ 8 つの障害がすべて、独立して再び発生する可能性があります。分散エンジニアリングは 1 回ではなく 2 回行われています。論理レベルでの GROUP1 から GROUP2 へのメッセージは、8 つの方法すべてで失敗する可能性があります。そのメッセージの結果、別のメッセージが生成されます。これは、前述の 8 つの方法すべてで、独立して失敗する可能性があります。このシナリオのテストには、少なくとも以下が含まれます。
-
GROUP1 から GROUP2 へのグループレベルのメッセージングの 8 つの方法すべてのテストは失敗する可能性があります。
-
S20〜S25 のサーバーレベルのメッセージングが失敗する 8 つの方法すべてのテスト。
この要求/応答メッセージングの例は、分散システムのテストが 20 年以上の経験を積んだ後でも、特に厄介な問題であり続ける理由を示しています。エッジケースの広大さを考えると、テストは困難ですが、これらのシステムでは特に重要です。バグは、システムがデプロイされてから表面化するまでに時間がかかる場合があります。また、バグは、システムおよびその隣接システムに予測できないほど広範な影響を与える可能性があります。
分散型のバグ
分散バグはしばしば潜んでいます
障害が最終的に発生する場合、一般的な常識は、それが後で発生するよりも早く発生する場合が良いということです。たとえば、サービスのスケーリングの問題を発見することをお勧めします。これには、修正に 6 か月、少なくともそのサービスがそのようなスケールを達成しなければならない 6 か月前が必要です。同様に、本番稼働前にバグを発見することをお勧めします。バグが本番稼働に影響を与える場合、多くの顧客に影響を与えたり、その他の悪影響を及ぼす前に、バグを迅速に発見することをお勧めします。
分散バグ、つまり、黙示録の 8 つの障害モードのすべての順列を処理できなかったために発生するバグは、しばしば深刻です。テレコミュニケーションシステムからコアインターネットシステムまで、大規模な分散システムには時間の経過とともに多くの例が蓄積されます。停止は、広範囲でコストが高額になるだけでなく、数か月前に本番環境にデプロイされたバグによって引き起こされる可能性もあります。これらのバグが実際に発生する (そしてシステム全体に広がる) シナリオの組み合わせをトリガーするには、しばらく時間がかかります。
分散バグの流行
分散バグの基本である別の問題について説明しましょう。
-
分散バグには必ずネットワークの使用が関係します。
-
そのため、分散バグは他のマシン (またはマシンのグループ) に広がる可能性が高くなります。「分散バグ」の名のとおり、バグはマシンをリンクする唯一のものを巻き込むからです。
Amazon もこれらの分散バグを経験しています。古いけれども関連性のある例としては、www.amazon.com のサイト全体で発生した障害があります。この障害は、ディスクがいっぱいになったときにリモートカタログサービス内で 1 つのサーバーに障害が発生したことが原因でした。
そのエラー条件の処理を誤ったため、リモートカタログサーバーは、受信したすべての要求に対して空の応答を返し始めました。また、何かを返すよりもはるかに高速であるため、非常に迅速に返され始めました (少なくともこの場合はそうでした)。一方、ウェブサイトとリモートカタログサービス間のロードバランサーは、すべての応答がゼロ長であることを認識しませんでした。けれども、他のすべてのリモートカタログサーバーよりも非常に高速であることには気付きました。そのため、www.amazon.com から大量のトラフィックを、ディスクがいっぱいの 1 つのリモートカタログサーバーに送信しました。1 つのリモートサーバーが製品情報を表示できなかったため、事実上、ウェブサイト全体がダウンしました。
Amazon はすぐに不良サーバーを見つけ、サービスから削除してウェブサイトを復元しました。次に、根本原因を突き止め、問題を特定して状況が再発しないように通常のプロセスをフォローアップしました。他のシステムで同じ問題が発生するのを防ぐために、得られた教訓を Amazon 全体で共有しました。この障害モードに関する特定の教訓を学ぶことに加えて、このインシデントは、障害システムが分散システムで迅速かつ予測不能に伝播する方法の優れた例として役立ちました。
概要
分散システムの問題のまとめ
まとめると、次の理由により分散システムのエンジニアリングは困難です。
-
エンジニアはエラー状態を組み合わせることができません。代わりに、障害の多くの順列を考慮する必要があります。ほとんどのエラーは、他のエラー状態とは無関係に (したがって、潜在的に、組み合わせて) いつでも発生する可能性があります。
-
ネットワーク操作の結果は UNKNOWN になることがあります。この場合、要求は成功、失敗、または受信されたが、処理されなかった可能性があります。
-
分散問題は、低レベルの物理マシンだけでなく、分散システムのすべての論理レベルで発生します。
-
システムのレベルが高くなると、再帰により分散問題が悪化します。
-
分散バグは、多くの場合、システムにデプロイされてからずっと後に現れます。
-
分散バグはシステム全体に広がる可能性があります。
-
上記の問題の多くは、ネットワークの物理法則に由来するもので、変更することはできません。
分散コンピューティングが困難で奇妙だからといって、これらの問題に取り組む方法がないという意味ではありません。Amazon Builders 'Library 全体を通して、AWS が分散システムを管理する方法を掘り下げています。お客様が顧客のために構築する際に、この教訓から何か有意義なことをつかんでもらえればと思います。
著者について
Jacob Gabrielson は、アマゾン ウェブ サービスのシニアプリンシパルエンジニアです。彼は、Amazon に入社して 17 年になり、主に社内のマイクロサービスプラットフォームで勤務しています。過去 8 年間、彼はソフトウェアデプロイシステム、コントロールプレーンサービス、スポット市場、Lightsail、そして最近ではコンテナを含む、EC2 と ECS に取り組んでいます。Jacob の情熱は、システムプログラミング、プログラミング言語、および分散コンピューティングです。彼が最も嫌うのは、特に障害状態でのバイモーダルシステムの挙動です。彼はシアトルのワシントン大学でコンピューターサイエンスの学士号を取得しました。

関連コンテンツ
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください