개요
학습 목표
이 가이드에서는 다음을 수행합니다.
- 데이터를 시각화하고 분석하여 주요 관계를 파악
- 변환을 적용하여 데이터를 정리하고 새로운 특성을 생성
- 반복 가능한 데이터 준비 워크플로를 위한 노트북을 자동으로 생성
사전 요구 사항
이 자습서를 시작하기 전에 다음을 수행해야 합니다.
- AWS 계정: 아직 계정이 없는 경우 AWS 환경 설정 시작하기 가이드를 참조하여 만들 수 있습니다.
AWS 경험
초보자
소요 시간
30분
완료 비용
이 자습서의 예상 비용은 Amazon SageMaker 요금을 참조하세요.
필요 사항
AWS 계정에 로그인해야 합니다.
사용 서비스
Amazon SageMaker Data Wrangler
최종 업데이트 날짜
2022년 7월 1일
구현
1단계: Amazon SageMaker Studio 도메인 설정
Amazon SageMaker를 사용할 때는 콘솔에서 시각적으로 모델을 배포하거나 SageMaker Studio 또는 SageMaker 노트북에서 프로그래밍 방식으로 배포할 수 있습니다. 이 자습서에서는 SageMaker Studio 노트북을 사용하여 프로그래밍 방식으로 모델을 배포하며 SageMaker Studio 도메인이 필요합니다.
AWS 계정은 리전당 1개의 SageMaker Studio 도메인만 설정할 수 있습니다. 미국 동부(버지니아 북부) 리전에 이미 SageMaker Studio 도메인이 있는 경우 SageMaker Studio 설정 가이드에 따라 필요한 AWS IAM 정책을 SageMaker Studio 계정에 연결한 다음 1단계를 건너뛰고 2단계로 바로 넘어가세요.
기존 SageMaker Studio 도메인이 없는 경우 1단계를 계속 진행하여 AWS CloudFormation 템플릿을 실행합니다. 그러면 SageMaker Studio 도메인이 생성되고 이 자습서의 나머지 부분에 필요한 권한이 추가됩니다.
AWS CloudFormation 스택 링크를 선택합니다. 이 링크를 누르면 AWS CloudFormation 콘솔이 열리고 SageMaker Studio 도메인과 studio-user라는 이름의 사용자가 생성됩니다. 또한 필요한 권한이 SageMaker Studio 계정에 추가됩니다. CloudFormation 콘솔에서 미국 동부(버지니아 북부)(US East (N. Virginia))가 오른쪽 위에 표시된 리전인지 확인합니다. 스택 이름(Stack name)은 CFN-SM-IM-Lambda-catalog여야 하며 변경할 수 없습니다. 이 스택은 모든 리소스를 생성하는 데 약 10분이 걸립니다.
이 스택은 퍼블릭 VPC가 계정에 이미 설정되어 있는 것으로 가정합니다. 퍼블릭 VPC가 없는 경우 단일 퍼블릭 서브넷이 있는 VPC를 참조하여 퍼블릭 VPC 생성 방법에 대해 알아보세요.

AWS CloudFormation이 IAM 리소스를 생성할 수 있음을 동의합니다(I acknowledge that AWS CloudFormation might create IAM resources)를 선택하고 스택 생성(Create stack)을 선택합니다.

CloudFormation 창에서 스택(Stacks)을 선택합니다. 스택이 생성되는 데 약 10분이 걸립니다. 스택이 생성되면 스택 상태가 CREATE_IN_PROGRESS에서 CREATE_COMPLETE로 바뀝니다.

2단계: 새 SageMaker Data Wrangler 흐름 생성
SageMaker Data Wrangler는 Amazon S3, Amazon Athena, Amazon Redshift, Snowflake 및 Databricks를 포함한 다양한 소스의 데이터를 수락합니다. 이 단계에서는 Amazon S3에 저장된 UCI 독일 신용 위험 데이터 세트를 사용하여 새 SageMaker Data Wrangler 흐름을 생성합니다. 이 데이터 세트에는 개인에 대한 인구 통계 및 금융 정보와 개인의 신용 위험 수준을 나타내는 레이블이 포함되어 있습니다.
SageMaker Studio를 콘솔 검색 창에 입력하고 SageMaker Studio를 선택합니다.

SageMaker 콘솔의 오른쪽 위에 있는 리전(Region) 드롭다운 목록에서 미국 동부(버지니아 북부)(US East (N. Virginia))를 선택합니다. 앱 시작(Launch app)에서 Studio를 선택하고 studio-user 프로필을 사용하여 SageMaker Studio를 엽니다.

SageMaker Studio 인터페이스를 엽니다. 탐색 모음에서 파일(File), 새로 만들기(New), Data Wrangler 흐름(Data Wrangler Flow)을 선택합니다.

가져오기(Import) 탭의 데이터 가져오기(Import data)에서 Amazon S3를 선택합니다.
S3 URI 경로(S3 URI path) 필드에 s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv를 입력한 다음 이동(Go)을 선택합니다. 객체 이름(Object name) 아래에서 german_credit_data.csv를 클릭하고 가져오기(Import)를 선택합니다.

3단계: 데이터 프로파일링
이 단계에서는 SageMaker Data Wrangler를 사용하여 훈련 데이터 세트의 품질을 평가합니다. 빠른 모델(Quick Model) 기능을 사용하여 데이터 세트에 있는 특성의 예상 예측 품질과 예측 성능을 대략적으로 추정할 수 있습니다.
데이터 흐름(Data Flow) 탭의 데이터 흐름 다이어그램에서 + 아이콘 분석 추가(Add analysis)를 선택합니다.
분석 생성(Create analysis) 패널에서 분석 유형(Analysis type)에 대해 히스토그램(Histogram)을 선택합니다.
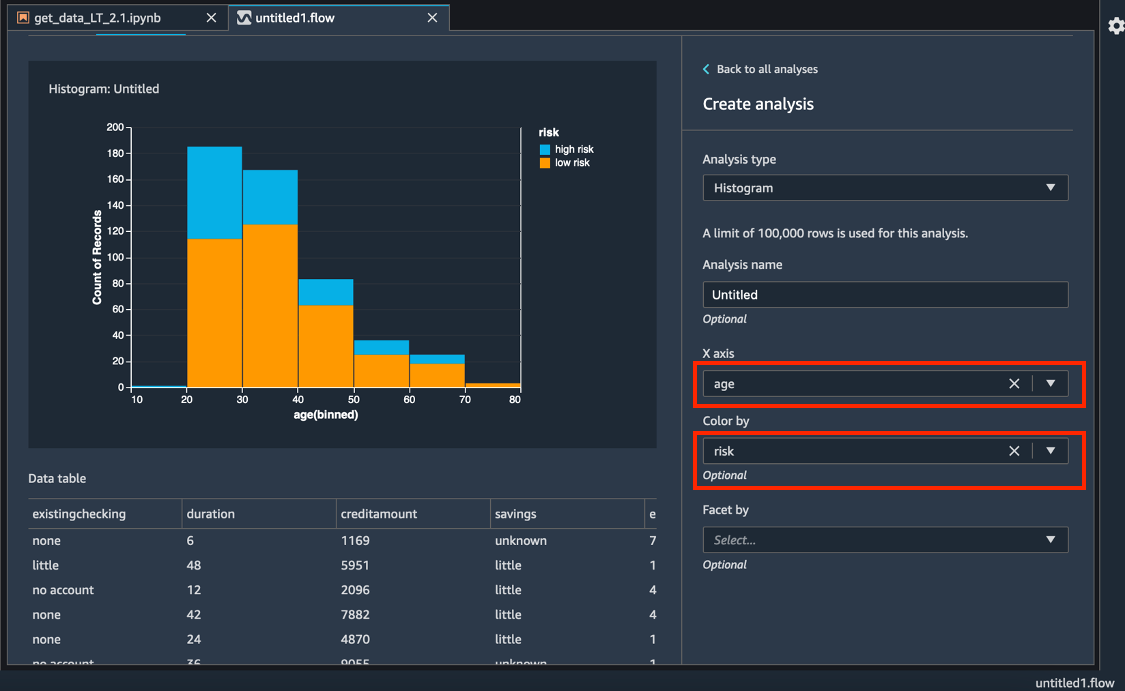
X 축(X axis)에 대해 연령(age)을 선택합니다.
색 지정 기준(Color by)에 대해 위험(risk)을 선택합니다.
미리 보기(Preview)를 선택하여 연령(age) 대괄호로 색상이 지정된 신용 위험(credit risk) 필드의 히스토그램을 생성합니다.
저장(Save)을 선택하여 이 분석을 흐름에 저장합니다.
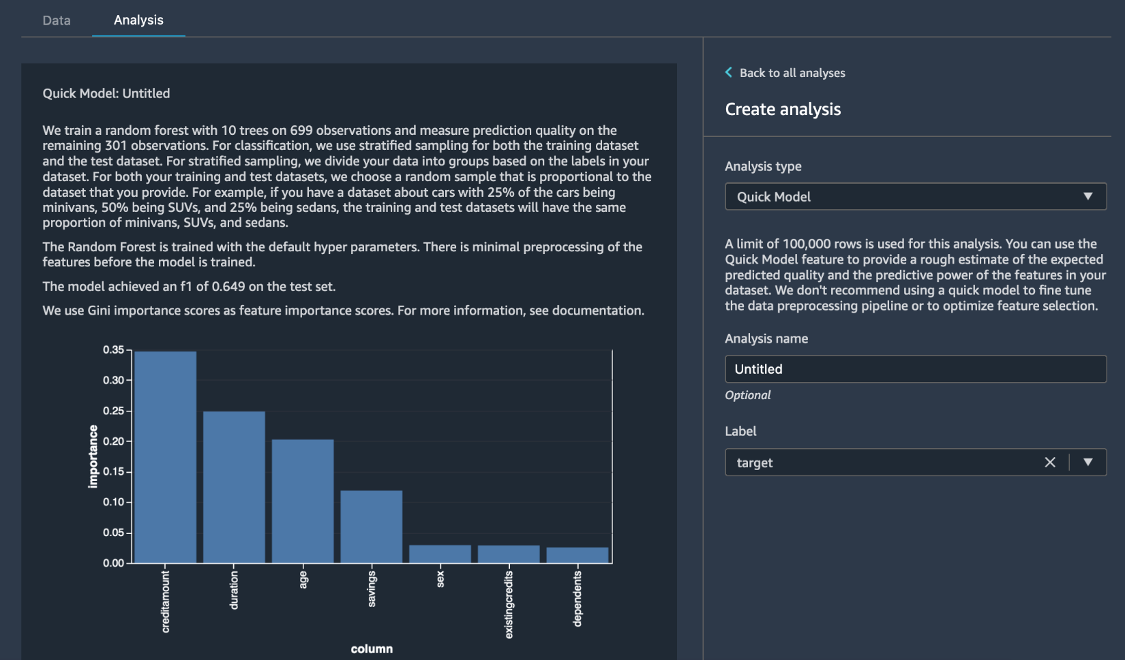
위험(risk) 대상 변수를 예측하는 모델을 훈련하는 데 이 데이터 세트가 얼마나 적합한지 파악하기 위해 빠른 모델(Quick Model) 분석을 실행합니다. 분석(Analysis) 탭에서 새 분석 생성(Create new analysis)을 선택합니다.
분석 생성(Create analysis) 창에서 분석 유형(Analysis type)에 대해 빠른 모델(Quick Model)을 선택합니다. 레이블(Label)에 대해 위험(risk)을 선택한 다음 미리 보기(Preview)를 선택합니다. 빠른 모델(Quick Model) 창에 사용된 모델과 데이터 세트의 품질을 평가하는 데 도움이 되는 기본적인 통계 일부(예: F1 점수 및 특성 중요도)가 표시됩니다. 저장(Save)을 선택합니다.
4단계: 데이터 흐름에 변환 추가
SageMaker Data Wrangler는 미리 작성된 다양한 변환을 추가할 수 있는 시각적 인터페이스를 제공하여 데이터 처리를 간소화합니다. SageMaker Data Wrangler를 사용하여 사용자 지정 변환을 작성할 수도 있습니다. 이 단계에서는 시각적 편집기를 사용하여 복잡한 문자열 데이터를 평면화하고 범주를 인코딩하고 열 이름을 바꾸고 불필요한 열을 삭제합니다. 그런 다음 status_sex 열을 marital_status와 sex라는 2개의 새로운 열로 분할합니다.
데이터 흐름 다이어그램으로 이동하려면 데이터 흐름(Data flow)을 선택합니다.

데이터 흐름 다이어그램에서 + 아이콘 변환 추가(Add transform)를 선택합니다.

모든 단계(ALL STEPS) 창에서 단계 추가(Add step)를 선택합니다.

변환 추가(ADD TRANSFORM) 목록에서 검색 및 편집(Search and edit)을 선택합니다. 이 변환은 문자열 데이터를 조작하는 데 사용됩니다.

검색 및 편집(SEARCH AND EDIT) 창에서 변환(Transform)에 대해 문자열을 구분 기호로 분할(Split string by delimiter)을 선택합니다. 입력 열(Input columns)에 대해 status_sex를 선택합니다. 구분 기호(Delimiter) 상자에 : 기호를 입력합니다. 출력 열(Output column)에 vec를 입력합니다. 미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.
이 변환은 status_sex 열을 분할하여 데이터프레임의 끝에 vec라는 이름의 새 열을 생성합니다. status_sex 열에는 콜론으로 구분된 문자열이 포함되고 새로운 vec 열에는 쉼표로 구분된 벡터가 포함됩니다.

vec 열을 분할하고 sex_split_0 및 sex_split_1이라는 2개의 새 열을 생성하려면
모든 단계(ALL STEPS) 아래에서 + 단계 추가(+ Add step)를 선택합니다.
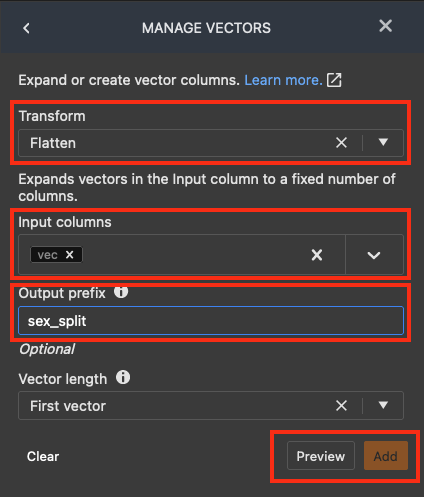
변환 추가(ADD TRANSFORM) 목록에서 벡터 관리(Manage vectors)를 선택합니다.
벡터 관리(MANAGE VECTORS) 창에서 변환(Transform)에 대해 평면화(Flatten)를 선택합니다. 입력 열(Input columns)에 대해 vec를 선택합니다. output_prefix에 대해 sex_split를 입력합니다.
미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.
분할 변환에 의해 생성된 열의 이름을 바꾸려면
모든 단계(ALL STEPS) 창에서 + 단계 추가(+ Add step)를 선택합니다.
변환 추가(ADD TRANSFORM) 목록에서 열 관리(Manage columns)를 선택합니다.
열 관리(MANAGE COLUMNS) 창에서 변환(Transform)에 대해 열 이름 바꾸기(Rename column)를 선택합니다. 입력 열(Input column)에 대해 sex_split_0를 입력합니다. 새 이름(New name) 상자에 sex를 입력합니다.
미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.
이 절차를 반복하여 sex_split_1을 marital_status로 바꿉니다.

5단계: 범주별 인코딩 추가
이 단계에서는 모델링 대상을 생성하고 범주별 변수를 인코딩합니다. 범주별 인코딩은 문자열 데이터 유형 범주를 숫자 레이블로 변환합니다. 이는 일반적인 전처리 태스크인데, 숫자 레이블은 다양한 모델 유형에 사용될 수 있기 때문입니다.
이 데이터 세트에서 신용 위험 분류는 고위험(high risk) 및 저위험(low risk)이라는 문자열로 표현됩니다. 이 단계에서는 이 분류를 바이너리 표현인 0 또는 1로 변환합니다.
모든 단계(ALL STEPS) 창에서 + 단계 추가(+ Add step)를 선택합니다. 변환 추가(ADD TRANSFORM) 목록에서 범주별 인코딩(Encode categorical)을 선택합니다. SageMaker Data Wrangler는 서수 인코딩(Ordinal encode), 원핫 인코딩(One hot encode) 및 유사성 인코딩(Similarity encode)이라는 3가지 변환 유형을 제공합니다. 범주별 인코딩(ENCODE CATEGORICAL) 창에서 변환(Transform)에 대해 기본값인 서수 인코딩(Ordinal encode)을 유지합니다. 입력 열(Input columns)에 대해 risk를 선택합니다. 출력 열(Output column)에 target을 입력합니다. 이 자습서에서는 잘못된 처리 전략(Invalid handling strategy) 확인란을 무시합니다. 미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

범주별 인코딩(Encode categorical) 변환을 사용하여 나머지 열인 housing, job, sex 및 marital_status를 다음과 같이 인코딩합니다. 모든 단계(ALL STEPS)에서 + 단계 추가(+ Add Step)를 선택합니다. 변환 추가(ADD TRANSFORM) 목록에서 범주별 인코딩(Encode categorical)을 선택합니다. 범주별 인코딩(ENCODE CATEGORICAL) 창에서 변환(Transform)에 대해 기본값인 서수 인코딩(Ordinal encode)을 유지합니다. 입력 열(Input columns)에 대해 housing, job, sex 및 marital_status를 선택합니다. 인코딩된 값이 범주별 값을 대체할 수 있도록 출력 열(Output column)을 비워 둡니다. 미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.

숫자 열 creditamount를 조정하려면 신용 금액에 스케일러를 적용하여 이 열의 데이터 분포를 정규화합니다. 모든 단계(ALL STEPS) 창에서 + 단계 추가(+ Add Step)를 선택합니다. 변환 추가(ADD TRANSFORM) 목록에서 숫자 처리(Process numeric)를 선택합니다. 스케일러(Scaler)에 대해 기본 옵션인 표준 스케일러(Standard scaler)를 선택합니다. 입력 열(Input columns)에 대해 creditamount를 선택합니다. 미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.


변환한 원래 열을 삭제하려면 모든 단계(ALL STEPS) 창에서 + 단계 추가(+ Add step)를 선택합니다. 변환 추가(ADD TRANSFORM) 목록에서 열 관리(Manage columns)를 선택합니다. 열 관리(MANAGE COLUMNS) 창에서 변환(Transform)에 대해 열 삭제(Drop column)를 선택합니다. 삭제할 열(Columns to drop)에 대해 status_sex, existingchecking, employmentsince, risk 및 vec를 선택합니다. 미리 보기(Preview)를 선택한 다음 추가(Add)를 선택합니다.

6단계: 데이터 바이어스 확인 실행
이 단계에서는 훈련 데이터 및 모델에 대한 가시성을 개선하여 바이어스를 식별 및 제한하고 예측을 설명할 수 있는 서비스인 Amazon SageMaker Clarify를 사용하여 데이터의 바이어스를 확인합니다.
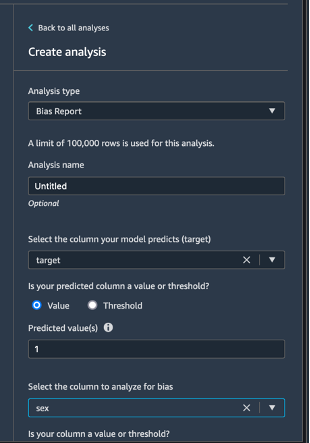
왼쪽 위에서 데이터 흐름(Data flow)을 선택하여 데이터 흐름 다이어그램을 반환합니다. + 아이콘 분석 추가(Add analysis)를 선택합니다. 분석 생성(Create analysis) 창에서 분석 유형(Analysis type)에 대해 바이어스 보고서(Bias Report)를 선택합니다. 분석 이름(Analysis name)에 아무 이름을 입력합니다. 모델로 예측할 열 선택(대상)(Select the column your model predicts (target))에 대해 target을 선택합니다. 값(Value) 확인란을 선택한 상태로 둡니다. 예측 값(Predicted value(s)) 상자에 1을 입력합니다. 바이어스를 분석할 열 선택(Select the column to analyze for bias)에 대해 sex를 선택합니다. 바이어스 지표 선택(Choose bias metrics)에 대해 기본 선택 사항을 유지합니다. 바이어스 확인(Check for bias)을 선택합니다.
몇 초 후에 SageMaker Clarify에서 보고서가 생성됩니다. 이 보고서는 클래스 불균형(CI) 및 레이블의 양수 비율 차이(DPL)와 같은 바이어스 관련 지표 수에 대한 target 및 test 열의 점수를 보여줍니다. 이 예에서 데이터에는 sex(-0.38) 측면에서 약간의 바이어스가 있고 labels(0.075) 측면에서는 바이어스가 많지 않습니다. 이 보고서에 따르면 SageMaker Data Wrangler의 기본 제공 SMOTE 변환과 같은 바이어스 교정 방법을 고려할 수 있습니다. 이 자습서에서는 교정 단계를 건너뜁니다. 저장(Save)을 선택하여 바이어스 보고서를 데이터 흐름에 저장합니다.

7단계: 데이터 흐름 내보내기
데이터 흐름을 Jupyter Notebook으로 내보내 SageMaker 처리 작업으로 단계를 실행합니다. 이러한 단계는 정의된 데이터 흐름에 따라 데이터를 처리하고 Amazon S3 또는 Amazon SageMaker 특성 저장소에 출력을 저장합니다.
데이터 흐름 다이어그램에서 + 아이콘, 내보낼 위치(Export to), Amazon S3(Jupyter Notebook 사용)Amazon S3 (via Jupyter Notebook)를 차례로 선택합니다. 그러면 SageMaker Studio에 노트북이 생성됩니다. 생성된 SageMaker 처리 작업을 이 노트북에서 실행하여 변환된 데이터 세트를 만들 수 있습니다. 이 노트북을 실행하여 기본 S3 버킷에 결과를 저장합니다.



8단계: 리소스 정리
사용하지 않는 리소스를 삭제하여 의도하지 않은 비용이 부과되지 않도록 하는 것이 모범 사례입니다.
S3 버킷을 삭제하려면 다음을 수행합니다.
- Amazon S3 콘솔을 엽니다. 탐색 모음에서 버킷(Buckets), sagemaker-<your-Region>-<your-account-id>를 선택한 다음 data_wrangler_flows 옆의 확인란을 선택합니다. 그런 다음 삭제(Delete)를 선택합니다.
- 객체 삭제(Delete objects) 대화 상자에서 삭제할 객체를 올바르게 선택했는지 확인하고 이 객체를 영구적으로 삭제(Permanently delete objects) 확인 입력란에 영구 삭제(permanently delete)를 입력합니다.
- 완료되면 버킷이 비워지고 동일한 절차를 다시 사용하여sagemaker-<your-Region>-<your-account-id> 버킷을 삭제할 수 있습니다.

이 자습서에서 노트북 이미지를 실행하는 데 사용된 데이터 과학(Data Science) 커널은 커널을 중지하거나 다음 단계를 수행하여 앱을 삭제할 때까지 변경 사항을 누적합니다. 자세한 내용은 Amazon SageMaker 개발자 안내서에서 리소스 종료를 참조하세요.
SageMaker Studio 앱을 삭제하려면 다음을 수행합니다. SageMaker Studio 콘솔에서 studio-user를 선택한 다음 앱 삭제(Delete app)를 선택하여 앱(Apps)에 나열된 모든 앱을 삭제합니다. 상태(Status)가 삭제됨(Deleted)으로 변경될 때까지 기다립니다.

1단계에서 기존 SageMaker Studio 도메인을 사용한 경우 8단계로 건너뛰고 결론 섹션으로 바로 진행합니다.
1단계에서 CloudFormation 템플릿을 실행하여 새 SageMaker Studio 도메인을 생성한 경우 다음 단계로 계속하여 CloudFormation 템플릿으로 생성된 도메인, 사용자 및 리소스를 삭제합니다.
CloudFormation 콘솔을 열려면 AWS Console 검색 창에 CloudFormation을 입력하고 검색 결과에서 CloudFormation을 선택합니다.

CloudFormation 창에서 스택(Stacks)을 선택합니다. 상태 드롭다운 목록에서 활성(Active)을 선택합니다. 스택 이름(Stack name) 아래에서 CFN-SM-IM-Lambda-catalog를 선택하여 스택 세부 정보 페이지를 엽니다.

CFN-SM-IM-Lambda-catalog 스택 세부 정보 페이지에서 삭제(Delete)를 선택하여 스택과 함께 1단계에서 생성된 리소스를 삭제합니다.

결론
Amazon SageMaker Data Wrangler를 사용하여 기계 학습 모델 훈련을 위한 데이터를 성공적으로 준비했습니다. SageMaker Data Wrangler에서는 300개가 넘는 미리 구성된 데이터 변환(예: 열 유형 변환, 단일 핫 인코딩, 누락된 데이터를 평균값 또는 중앙값으로 전가, 열 크기 조정, 데이터/시간 임베드)을 제공하므로, 코드를 전혀 작성하지 않고도 모델에 대해 효과적으로 사용할 수 있는 형식으로 데이터를 변환할 수 있습니다.