개요
작동 방식
Well-Architected 원칙
위의 아키텍처 다이어그램은 Well-Architected 모범 사례를 고려하여 생성된 솔루션의 예시입니다. Well-Architected를 완전히 충족하려면 가능한 많은 Well-Architected 모범 사례를 따라야 합니다.
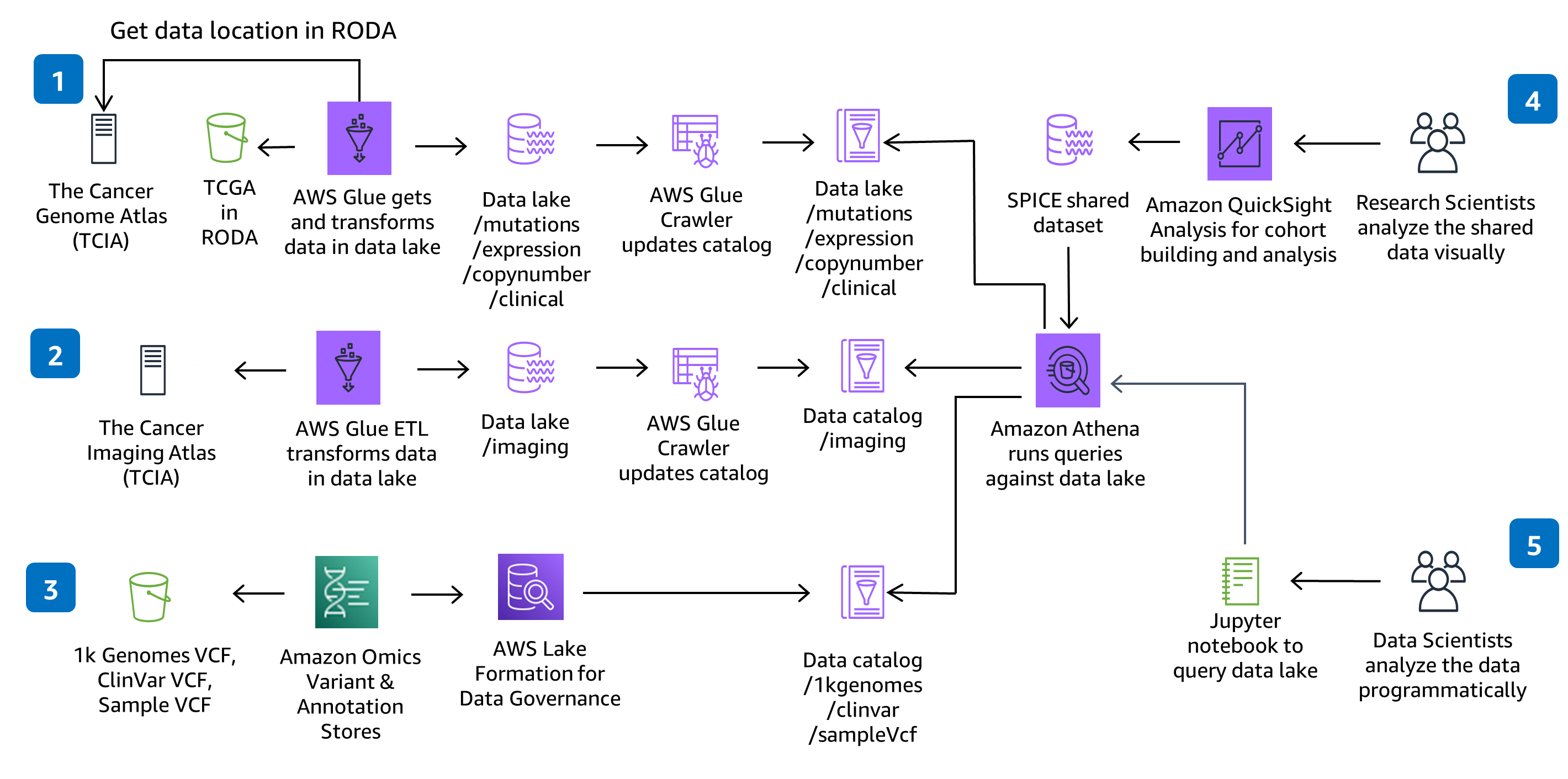
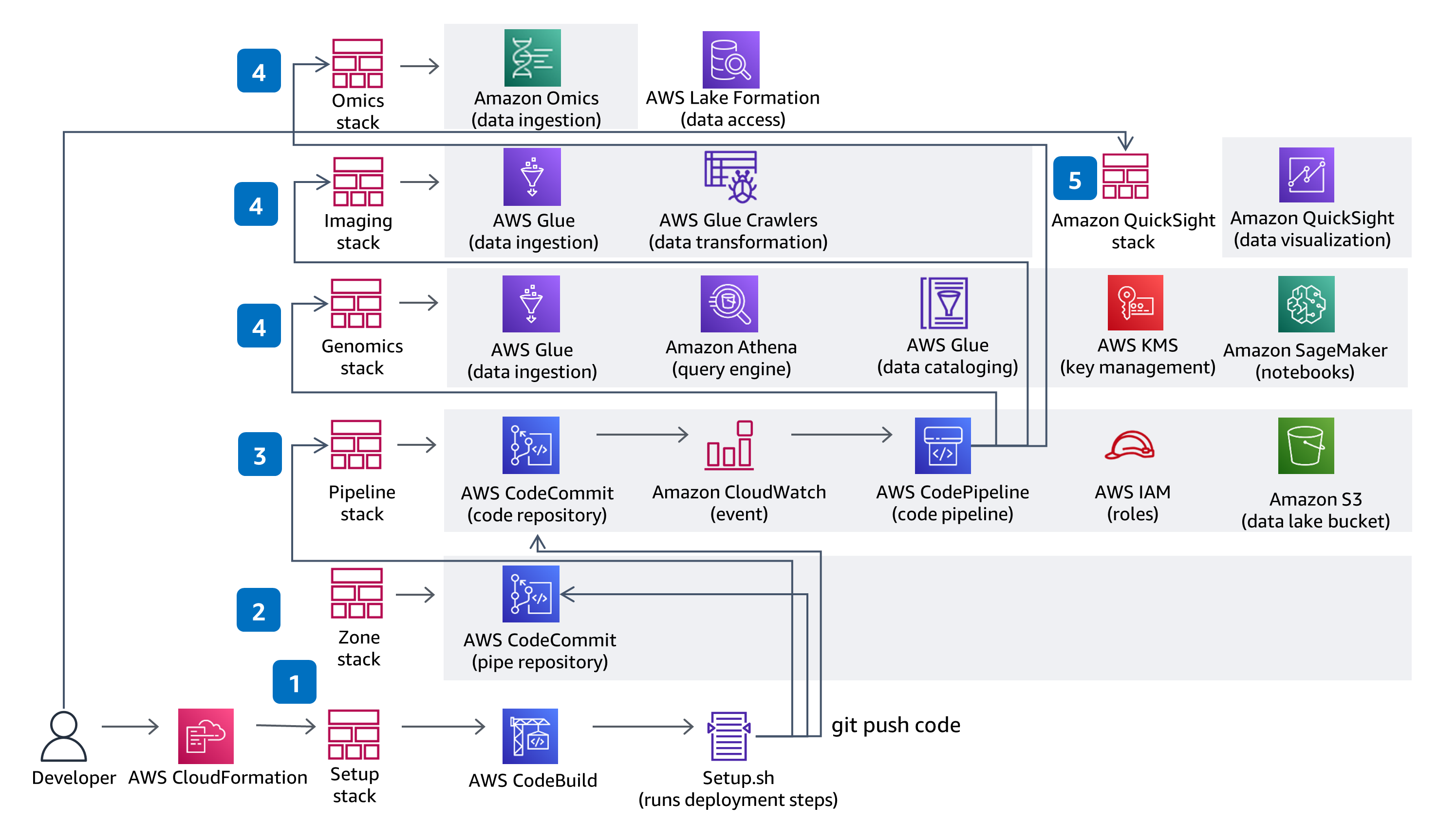
이 지침은 CodeBuild와 CodePipeline을 사용하여 Variant Call File(VCF)을 모아서 저장하고 The Cancer Genome Atlas(TCGA) 및 The Cancer Imaging Atlas(TCIA) 데이터 세트의 다중 모달 및 멀티오믹 데이터로 작업하는 솔루션에 필요한 모든 것을 구축, 패키지, 배포합니다. 서버리스 유전체학 데이터 수집 및 분석은 완전관리형 서비스 Amazon Omics를 사용해 시연합니다. 솔루션 CodeCommit 리포지토리에서 적용된 코드 변경 사항은 제공된 CodePipeline 배포 파이프라인을 통해 배포됩니다.
이 지침은 IAM의 역할 기반 액세스를 사용하며 모든 버킷은 암호화가 활성화되어 있고, 비공개이며 퍼블릭 액세스를 차단합니다. AWS Glue의 데이터 카탈로그는 암호화를 사용하며 AWS Glue가 Amazon S3에 쓰는 모든 메타데이터는 암호화됩니다. 모든 역할은 최소 권한을 사용하여 정의되고 서비스 간의 모든 통신은 고객 계정 안에 유지됩니다. 관리자는 Jupyter Notebook를 제어할 수 있고, Amazon Omics 변이 저장소의 데이터 및 AWS Glue Catalog 데이터는 Lake Formation을 사용해 완전히 관리되며 Athena, SageMaker Notebook 및 QuickSight 데이터 액세스는 제공된 IAM 역할을 통해 관리됩니다.
AWS Glue, Amazon S3, Amazon Omics, Athena는 모두 서버리스이며 데이터 볼륨이 증가하면 데이터 액세스 성능을 확장합니다. AWS Glue는 데이터 통합 작업을 실행하는 데 필요한 리소스를 프로비저닝, 구성, 확장합니다. Athena는 서버리스이므로 서버나 데이터 웨어하우스를 설정하고 관리할 필요 없이 신속하게 데이터를 쿼리할 수 있습니다. QuickSight SPICE 인 메모리 스토리지는 데이터 탐색을 사용자 수천 명 규모로 확장합니다.
서버리스 기술을 사용하면 정확히 사용할 리소스만 프로비저닝할 수 있습니다. 각 AWS Glue 작업은 Spark 클러스터를 온디맨드로 프로비저닝하여 데이터를 변환하고 작업이 완료되면 리소스 프로비저닝을 해제합니다. 새 TCGA 데이터 세트를 추가하려는 경우 마찬가지로 온디맨드로 리소스를 프로비저닝하는 새로운 AWS Glue 작업과 AWS Glue 크롤러를 추가할 수 있습니다. Athena는 병렬 방식으로 쿼리를 자동 실행하기 때문에 대부분 결과가 수 초 만에 반환됩니다. Amazon Omics는 파일을 Apache Parquet로 변환하여 규모에 맞게 변이 쿼리 성능을 최적화합니다.
온디맨드로 조정되는 서버리스 기술을 사용하면 사용한 리소스에 대한 요금만 지불하면 됩니다. 비용을 추가로 최적화하려면 SageMaker에서 사용하지 않는 노트북 환경을 중지합니다. QuickSight 대시보드도 개별 CloudFormation 템플릿을 통해 배포됩니다. 따라서 시각화 대시보드를 사용하지 않으려는 경우에는 배포하지 않도록 선택하여 비용을 절감할 수 있습니다. Amazon Omics는 변이 데이터 스토리지 비용을 규모에 맞게 최적화합니다. 쿼리 비용은 Athena에서 스캔한 데이터의 양에 의해 결정되며, 적절한 쿼리를 작성하면 이를 최적화할 수 있습니다.
관리형 서비스와 동적 크기 조정을 광범위하게 사용하면 백엔드 서비스가 환경에 미치는 영향을 최소화할 수 있습니다. 지속 가능성의 중요한 구성 요소는 노트북 서버 인스턴스의 사용을 최대화하는 것입니다. 사용하지 않을 때는 노트북 환경을 중지해야 합니다.
추가 고려 사항
데이터 변환
이 아키텍처는 쿼리 및 성능을 위해 솔루션에서 데이터세트를 수집, 준비 및 카탈로그화하는 데 필요한 추출, 전환, 적재(ETL)에 AWS Glue를 선택했습니다. 사용자는 필요에 따라 새 AWS Glue 작업과 AWS Glue 크롤러를 추가하여 새로운 The Cancer Genome Atlas(TCGA) 및 The Cancer Image Atlas(TCIA) 데이터세트를 수집할 수 있습니다. 또한 새 작업과 크롤러를 추가하여 자체 독점 데이터 세트를 수집하고, 준비하고, 카탈로그화할 수 있습니다.
데이터 분석
이 아키텍처는 분석용 Jupyter Notebook 환경을 제공하기 위해 SageMaker 노트북을 선택했습니다. 사용자는 기존 환경에 새 노트북을 추가하거나 새 환경을 생성할 수 있습니다. Jupyter Notebook보다 RStudio를 선호하는 경우 RStudio on Amazon SageMaker를 사용할 수 있습니다.
데이터 시각화
이 아키텍처는 데이터 시각화 및 탐색을 위한 대화형 대시보드를 제공하기 위해 QuickSight를 선택했습니다. QuickSight 대시보드는 개별 CloudFormation 템플릿을 통해 설정되므로 대시보드를 사용할 계획이 없다면 프로비저닝하지 않아도 됩니다. QuickSight에서 자체 분석을 생성하고 추가 필터 또는 시각화를 탐색하며 데이터세트 및 분석을 동료와 공유할 수 있습니다.
자신감 있게 배포
이 리포지토리는 대규모 분석을 위해 게놈, 임상, 돌연변이, 발현 및 이미징 데이터를 준비하고 데이터 레이크에 대해 대화형 쿼리를 수행할 수 있는 확장 가능한 환경을 AWS에 생성합니다. 이 솔루션은 1) HealthOmics 변이 저장소 및 주석 저장소에 유전체 변이 데이터 및 주석 데이터를 저장하는 방법, 2) 다중 모달 데이터 준비 및 카탈로그화를 위한 서버리스 데이터 수집 파이프라인을 프로비저닝하는 방법, 3) 대화형 인터페이스를 통해 임상 데이터를 시각화 및 탐색하는 방법, 4) Amazon Athena 및 Amazon SageMaker를 사용하여 다중 모달 데이터 레이크를 대상으로 대화형 분석 쿼리를 실행하는 방법을 보여줍니다.
실험 및 사용을 위한 자세한 안내는 AWS 계정 내에서 제공됩니다. 배포, 사용, 정리를 포함한 지침 구축의 각 단계는 검토되어 배포를 위해 준비됩니다.
시작점으로서 샘플 코드를 제공합니다. 이 샘플 코드는 업계에서 검증되었고 규범적이지만 최종적인 것은 아니며, 시작하는 데 도움을 줄 것입니다.
관련 콘텐츠
지침
Guidance for Multi-Modal Data Analysis with Health AI and ML Services on AWS(AWS에서 Health AI와 기계 학습 서비스를 통해 다중 모달 데이터 분석을 위한 지침)
이 지침은 복합 의료 및 생명 과학(HCLS) 데이터를 분석하기 위한 종합적인 프레임워크를 설정하는 방법을 보여줍니다.
기고자
고지 사항
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내주세요.