Bagaimana konten ini?
- Pelajari
- Membangun aplikasi AI generatif untuk perusahaan rintisan Anda
Membangun aplikasi AI generatif untuk perusahaan rintisan Anda
Kemajuan AI generatif baru-baru ini meningkatkan standar alat yang dapat membantu perusahaan rintisan untuk membangun, menskalakan, dan berinovasi dengan cepat. Adopsi serta demokratisasi machine learning (ML) yang meluas, khususnya dengan arsitektur jaringan neural transformator, merupakan titik perubahan yang menarik dalam teknologi. Dengan alat yang tepat, perusahaan rintisan dapat membangun berbagai ide baru atau mengubah produk yang sudah ada untuk memanfaatkan keunggulan AI generatif bagi pelanggan mereka.
Apakah Anda siap membangun aplikasi AI generatif untuk perusahaan rintisan Anda? Pertama-tama, mari kita tinjau konsep, ide inti, dan pendekatan umum untuk membangun aplikasi AI generatif.
Apa itu aplikasi AI generatif?
Aplikasi AI generatif adalah program yang didasarkan pada tipe AI yang dapat membuat konten dan ide baru, termasuk percakapan, cerita, gambar, video, kode, dan musik. Seperti semua aplikasi AI, aplikasi AI generatif didukung oleh model ML yang telah dilatih sebelumnya pada sejumlah besar data, dan biasa disebut sebagai model fondasi (FM).
Contoh aplikasi AI generatif adalah Amazon CodeWhisperer, pendamping pengodean AI yang membantu developer membangun aplikasi secara lebih cepat dan aman dengan memberikan saran kode seluruh baris dan fungsi penuh di lingkungan pengembangan terintegrasi (IDE) Anda. CodeWhisperer dilatih pada miliaran baris kode, dan dapat menghasilkan saran kode, mulai dari cuplikan hingga fungsi lengkap secara instan, berdasarkan komentar Anda dan kode yang ada. Perusahaan rintisan dapat menggunakan kredit AWS Activate dengan CodeWhisperer Tingkat Profesional, atau memulai dengan Tingkat Individual yang dapat digunakan secara gratis.
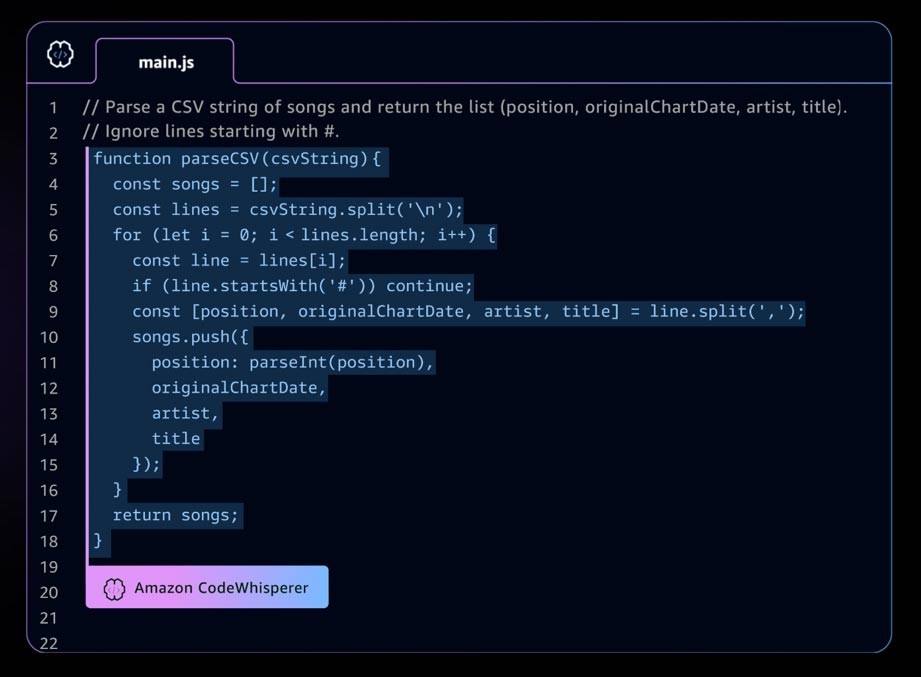
Lanskap AI generatif yang berkembang pesat
Terdapat pertumbuhan pesat yang terjadi pada perusahaan rintisan AI generatif, dan juga pada perusahaan rintisan yang membangun alat untuk menyederhanakan adopsi AI generatif. Alat, seperti LangChain—kerangka kerja sumber terbuka untuk mengembangkan aplikasi yang didukung model bahasa—memungkinkan AI generatif lebih mudah diakses oleh lebih banyak organisasi, sehingga akan mempercepat adopsi. Alat-alat ini juga mencakup rekayasa perintah, layanan augmentasi (seperti alat penyematan atau basis data vektor), pemantauan model, pengukuran kualitas model, pagar pembatas, anotasi data, pembelajaran penguatan dari umpan balik manusia (RLHF), dan banyak lagi.
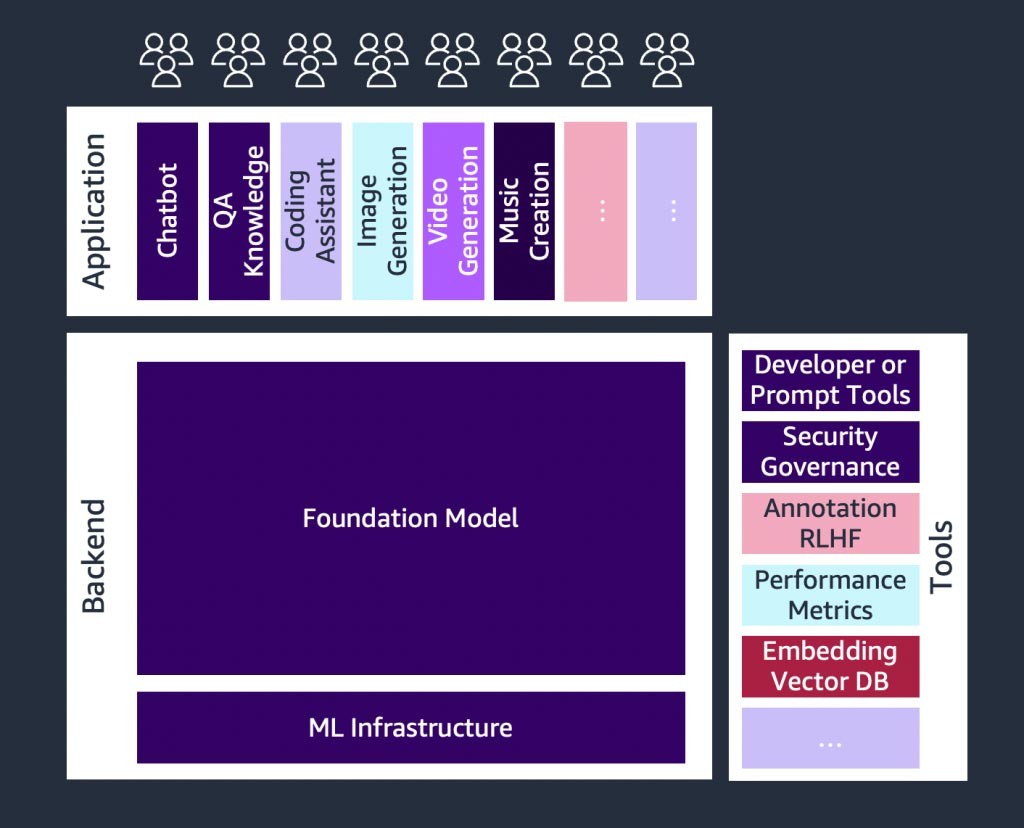
Pengantar model fondasi
Untuk aplikasi atau alat AI generatif, model fondasi adalah intinya. Model fondasi adalah kelas model machine learning canggih yang dibedakan berdasarkan kemampuannya untuk dilatih terlebih dahulu pada sejumlah besar data untuk melakukan berbagai tugas downstream. Tugas-tugas ini mencakup pembuatan teks, ringkasan, ekstraksi informasi, tanya jawab, dan/atau chatbot. Sebaliknya, model ML tradisional dilatih untuk melakukan tugas tertentu dari set data.
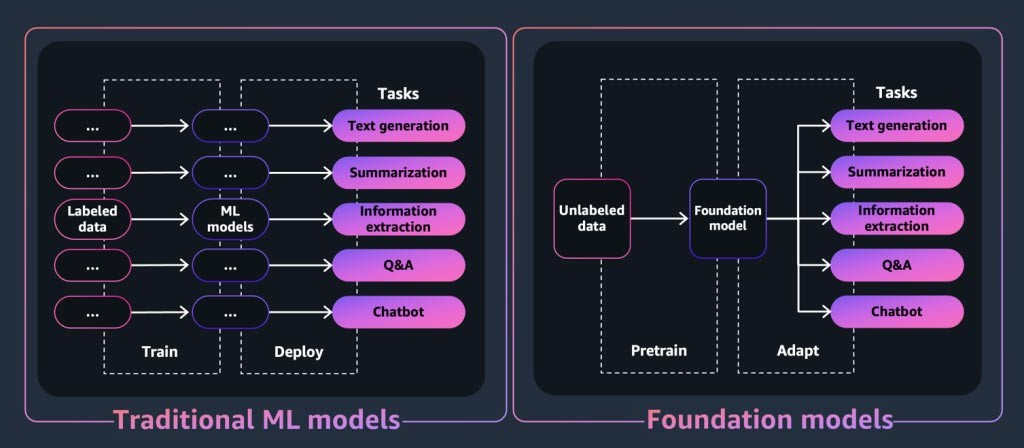
Jadi, bagaimana model fondasi “menghasilkan” output yang dikenal dengan aplikasi AI generatif? Kemampuan ini dihasilkan dari pola pembelajaran dan hubungan yang memungkinkan FM memprediksi item berikutnya atau item secara berurutan, atau menghasilkan item baru:
- Dalam model pembuatan teks, FM menghasilkan kata berikutnya, frasa berikutnya, atau jawaban atas sebuah pertanyaan.
- Untuk model pembuatan gambar, FM menghasilkan gambar berdasarkan teks.
- Ketika sebuah gambar dijadikan input, FM menghasilkan gambar, animasi, atau gambar 3D berikutnya yang relevan atau ditingkatkan.
Dalam setiap kasus, model dimulai dengan vektor awal yang berasal dari “perintah”: Perintah menggambarkan tugas yang harus dilakukan model. Kualitas dan detail (juga dikenal sebagai “konteks”) dari perintah menentukan kualitas serta relevansi output.
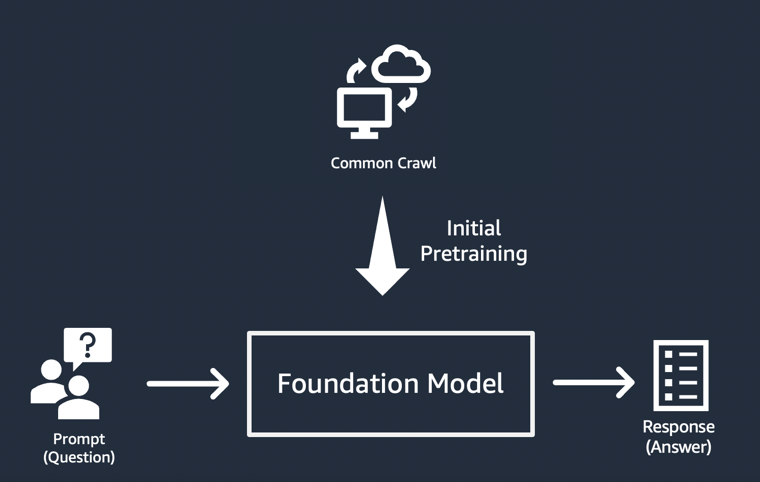
Implementasi paling sederhana dari aplikasi AI generatif
Pendekatan paling sederhana untuk membangun aplikasi AI generatif adalah dengan menggunakan model fondasi yang disesuaikan dengan instruksi, dan memberikan perintah yang bermakna (“rekayasa perintah”) menggunakan pembelajaran zero-shot atau few-shot. Model yang disempurnakan dengan instruksi (seperti FLAN T5 XXL, Open-Llama, atau Falcon 40B Instruct) menggunakan pemahamannya tentang tugas atau konsep terkait untuk menghasilkan prediksi terhadap perintah. Berikut adalah beberapa contoh perintah:
Pembelajaran zero-shot
Judul: \”Universitas akan memiliki fasilitas baru pada waktu mendatang“\\n Mengingat judul artikel imajiner di atas, bayangkan artikel tersebut.\n
Pembelajaran few-shot
Ini mengagumkan! // Positif
Ini buruk! // Negatif
Sia-sia sekali menonton film itu! // Negatif
Pertunjukan yang mengerikan! //
RESPONS: Negatif
Perusahaan rintisan, khususnya, bisa mendapatkan keuntungan dari deployment yang cepat, kebutuhan data yang minimal, dan optimisasi biaya yang dihasilkan dari penggunaan model yang disesuaikan dengan instruksi.
Untuk mempelajari selengkapnya tentang pertimbangan dalam memilih model fondasi, lihat Memilih model fondasi yang tepat untuk perusahaan rintisan Anda.
Mengustom model fondasi
Tidak semua kasus penggunaan dapat dipenuhi dengan menggunakan rekayasa perintah pada model yang disesuaikan dengan instruksi. Alasan untuk mengustom model fondasi untuk perusahaan rintisan Anda mungkin termasuk:
- Menambahkan tugas tertentu (seperti pembuatan kode) ke model fondasi
- Menghasilkan respons berdasarkan set data milik perusahaan Anda
- Mencari respons yang dihasilkan dari set data berkualitas lebih tinggi dibandingkan set data yang telah melatih model sebelumnya
- Mengurangi “halusinasi”, yaitu merupakan output yang tidak benar atau tidak masuk akal secara faktual
Ada tiga teknik umum untuk mengustom model fondasi.
Penyempurnaan berbasis instruksi
Teknik ini melibatkan pelatihan model fondasi untuk menyelesaikan tugas tertentu, berdasarkan set data berlabel khusus tugas. Set data berlabel terdiri dari pasangan perintah dan respons. Teknik kustomisasi ini bermanfaat bagi perusahaan rintisan yang ingin mengustom FM mereka dengan cepat dan dengan set data minimal: Diperlukan lebih sedikit set data dan langkah untuk melatihnya. Bobot model diperbarui berdasarkan tugas atau lapisan yang Anda sempurnakan.
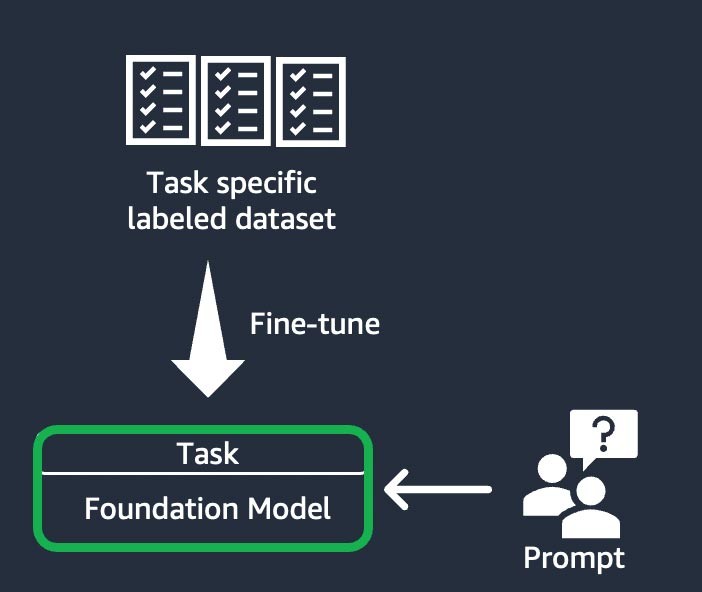
Adaptasi domain (juga dikenal sebagai “prapelatihan lebih lanjut”)
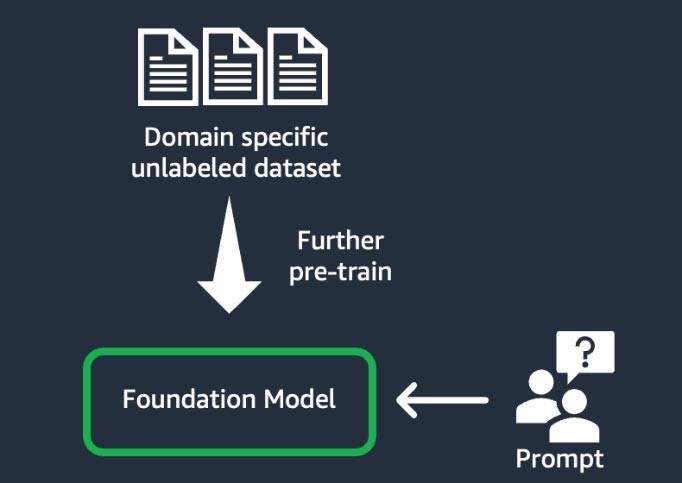
Teknik ini melibatkan pelatihan model fondasi menggunakan “korpus” besar—kumpulan materi pelatihan—data tidak berlabel khusus domain (dikenal sebagai “pembelajaran yang diawasi mandiri”). Teknik ini menguntungkan kasus penggunaan yang menyertakan jargon khusus domain dan data statistik yang belum pernah dilihat oleh model fondasi yang ada. Misalnya, perusahaan rintisan yang membangun aplikasi AI generatif untuk bekerja dengan data eksklusif di domain keuangan dapat memperoleh manfaat dari prapelatihan FM lebih lanjut mengenai kosakata kustom dan dari “tokenisasi”, sebuah proses memecah teks menjadi unit-unit lebih kecil yang disebut token.
Untuk mencapai kualitas yang lebih tinggi, beberapa perusahaan rintisan menerapkan teknik pembelajaran penguatan dari umpan balik manusia (RLHF) dalam proses ini. Selain itu, penyempurnaan berbasis instruksi akan diperlukan untuk menyempurnakan tugas tertentu. Ini adalah teknik yang mahal dan memakan waktu dibandingkan dengan teknik lainnya. Bobot model tersebut diperbarui di semua lapisan.
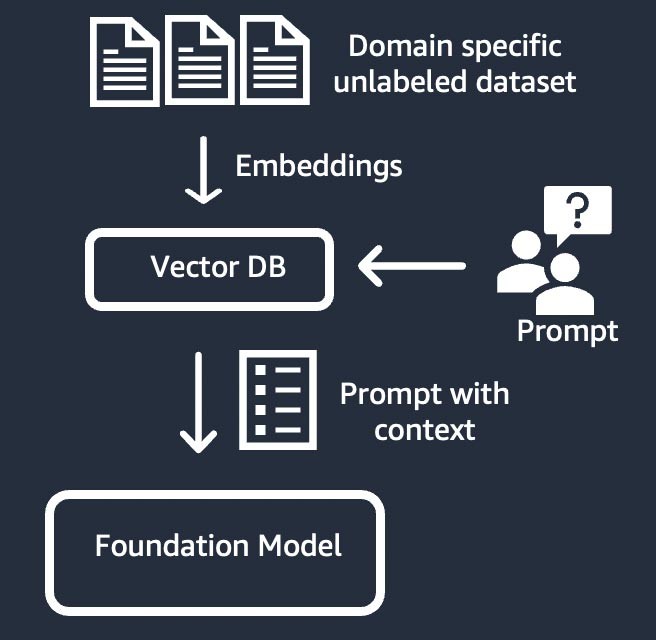
Pengambilan informasi (juga dikenal sebagai “retrieval-augmented generation” atau “RAG”)
Teknik ini menambah model fondasi dengan sistem pengambilan informasi yang didasarkan pada representasi vektor padat. Pengetahuan domain tertutup atau data eksklusif melewati proses penyematan teks untuk menghasilkan representasi vektor korpus, dan disimpan di basis data vektor. Hasil pencarian semantik yang berdasarkan permintaan pengguna menjadi konteks perintah. Model fondasi digunakan untuk menghasilkan respons berdasarkan perintah dengan konteks. Dalam teknik ini, bobot model fondasi tidak diperbarui.
Komponen aplikasi AI generatif
Pada bagian di atas, kita mempelajari berbagai pendekatan yang dapat diterapkan oleh perusahaan rintisan dengan model fondasi saat membangun aplikasi AI generatif. Sekarang, mari kita tinjau cara model fondasi ini menjadi bagian dari bahan atau komponen umum yang diperlukan untuk membangun aplikasi AI generatif.
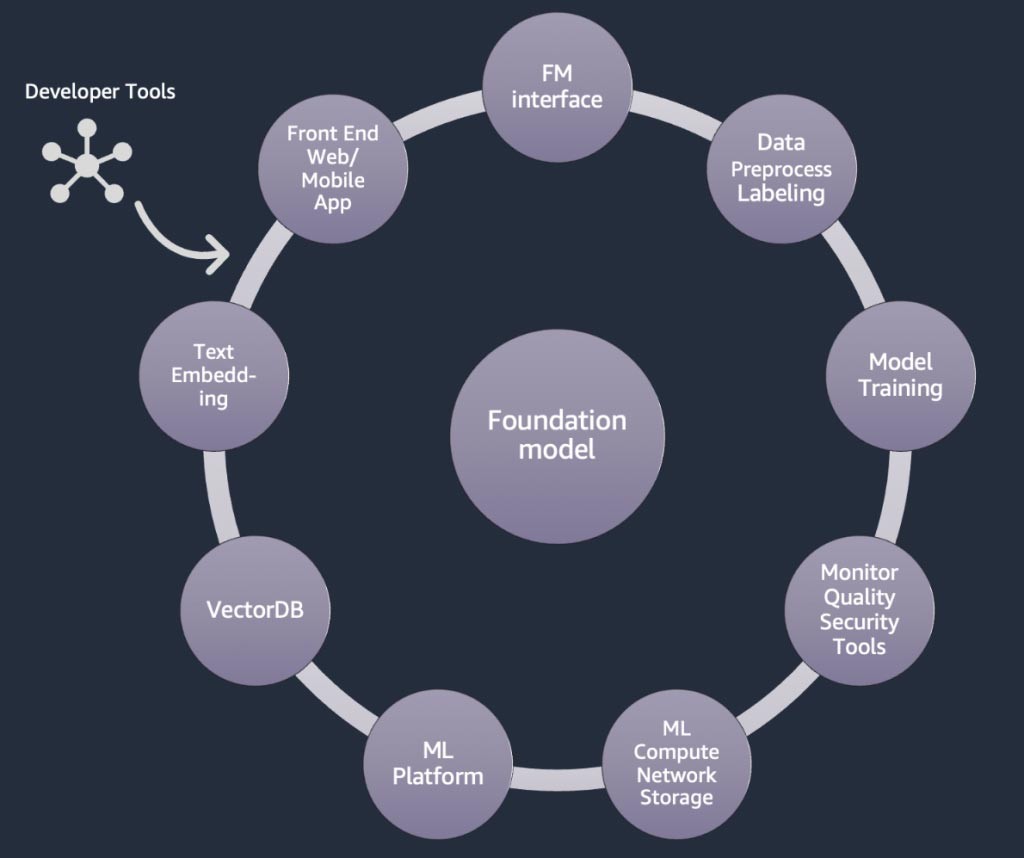
Pada intinya adalah model fondasi (tengah). Dalam pendekatan paling sederhana yang dibahas sebelumnya di blog ini, hal ini memerlukan aplikasi web atau aplikasi seluler (kiri atas) yang mengakses model fondasi melalui API (atas). API ini merupakan layanan terkelola melalui penyedia model atau di-hosting sendiri menggunakan model sumber terbuka atau eksklusif. Dalam kasus hosting mandiri, Anda mungkin memerlukan platform machine learning yang didukung oleh instans komputasi terakselerasi untuk meng-hosting model tersebut.
Dalam teknik RAG, Anda perlu menambahkan titik akhir penyematan teks dan basis data vektor (kiri dan kiri bawah). Keduanya disediakan sebagai layanan API atau di-hosting sendiri. Titik akhir penyematan teks didukung oleh model fondasi, dan pilihan model fondasi bergantung pada logika penyematan dan dukungan tokenisasi. Semua komponen ini dihubungkan bersama menggunakan alat developer, yang menyediakan kerangka kerja untuk mengembangkan aplikasi AI generatif.
Terakhir, saat Anda memilih teknik kustomisasi untuk menyempurnakan atau prapelatihan lebih lanjut model fondasi (kanan), Anda memerlukan komponen yang membantu prapemrosesan dan anotasi data (kanan atas), dan platform ML (bawah ) untuk menjalankan tugas pelatihan pada instans komputasi terakselerasi tertentu. Beberapa penyedia model mendukung penyempurnaan berbasis API, dan dalam kasus seperti itu, Anda tidak perlu khawatir tentang platform ML dan perangkat keras yang mendasarinya.
Terlepas dari pendekatan kustomisasinya, Anda mungkin juga ingin mengintegrasikan komponen yang menyediakan pemantauan, metrik kualitas, dan alat keamanan (kanan bawah).
Layanan AWS mana yang harus saya gunakan untuk membangun aplikasi AI generatif?
Diagram berikut, Gambar 9, memetakan setiap komponen ke layanan AWS yang sesuai. Perhatikan bahwa ini adalah rangkaian layanan AWS yang sering kali dimanfaatkan oleh perusahaan rintisan. Namun, ada layanan AWS lain yang tersedia.
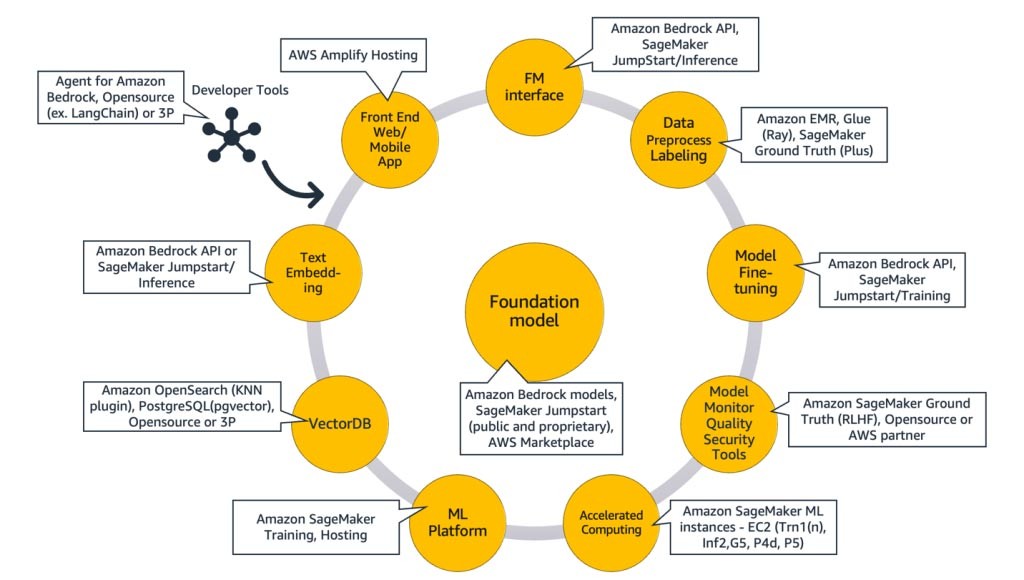
Untuk lebih jelasnya, saya akan mulai dengan memetakan layanan AWS ke komponen umum aplikasi AI generatif. Kemudian, saya akan menjelaskan layanan AWS yang dipetakan ke komponen lainnya pada Gambar 9, berdasarkan pendekatan yang Anda gunakan untuk mengimplementasikan aplikasi Anda.
Komponen umum
Komponen umum aplikasi AI generatif adalah model fondasi (FM), antarmukanya dan/atau platform machine learning (ML), serta komputasi yang dipercepat. Komponen-komponen ini dapat dipenuhi menggunakan penawaran terkelola yang tersedia dari AWS:
Amazon Bedrock (model fondasi dan komponen antarmukanya)
Amazon Bedrock, layanan terkelola penuh yang membuat model fondasi dari perusahaan rintisan AI terkemuka (Jurassic AI21, Claude Anthropic, Command and Embedding dari Cohere, model SDXL Stability) dan Amazon (model Titan Text dan Embeddings) tersedia melalui API, sehingga Anda dapat memilih dari berbagai macam FM untuk menemukan model yang paling sesuai dengan kasus penggunaan Anda. Amazon Bedrock menyediakan akses API atau nirserver ke rangkaian model fondasi untuk menyediakan tiga kemampuan: penyematan teks, perintah/respons, dan penyempurnaan (pada model tertentu).
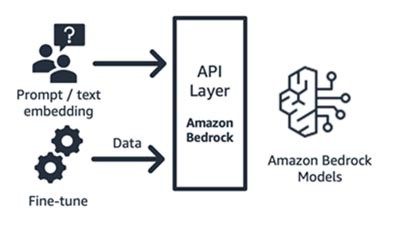
Amazon Bedrock sangat cocok untuk perusahaan rintisan konsumen aplikasi atau model yang membangun layanan bernilai tambah – rekayasa perintah, retrieval-augmented generation, dan banyak lagi – berdasarkan model fondasi pilihan mereka. Model penetapan harganya adalah bayar sesuai penggunaan, biasanya dalam satuan jutaan token yang diproses. Amazon Bedrock tersedia secara umum, tetapi beberapa fitur yang dibahas di blog ini ada di pratinjau pribadi. Pelajari selengkapnya di sini.
Amazon SageMaker JumpStart (model fondasi dan komponen antarmukanya)
AWS menawarkan kemampuan AI generatif ke Amazon SageMaker Jumpstart: hub model fondasi yang berisi model yang tersedia untuk umum dan eksklusif, solusi mulai cepat, serta contoh notebook untuk melakukan deployment dan menyempurnakan model. Saat model ini di-deploy, titik akhir inferensi waktu nyata yang dapat Anda akses secara langsung menggunakan SDK/API SageMaker akan dibuat. Atau, Anda dapat melakukan front-end titik akhir model fondasi SageMaker dengan Gateway API AWS dan logika komputasi ringan dalam fungsi AWS Lambda. Anda juga dapat memanfaatkan beberapa model ini untuk penyematan teks.
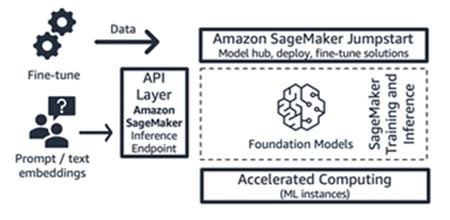
Titik akhir inferensi dan tugas pelatihan penyempunaan dijalankan pada instans ML terkelola pilihan Anda (lihat “Komputasi yang Dipercepat” pada Gambar 9) menggunakan SageMaker sebagai platform ML (lihat “Platform ML” pada Gambar 9). SageMaker Jumpstart sangat cocok bagi perusahaan rintisan konsumen aplikasi atau model yang menginginkan kontrol lebih atas infrastruktur mereka, serta yang memiliki keterampilan ML dan pengetahuan infrastruktur yang moderat. Model penetapan harganya adalah bayar sesuai penggunaan, biasanya dalam satuan instans-jam. Semua model dan solusi dalam penawaran ini tersedia secara umum.
Pelatihan dan inferensi Amazon SageMaker (platform ML)
Perusahaan rintisan dapat memanfaatkan fitur pelatihan dan inferensi Amazon SageMaker untuk kemampuan lanjutan, seperti pelatihan terdistribusi, inferensi terdistribusi, titik akhir multimodel, dan banyak lagi. Anda dapat membawa model fondasi dari hub model pilihan Anda – baik itu SageMaker JumpStart atau Hugging Face maupun AWS Marketplace, atau Anda dapat membangun model fondasi Anda sendiri dari awal.
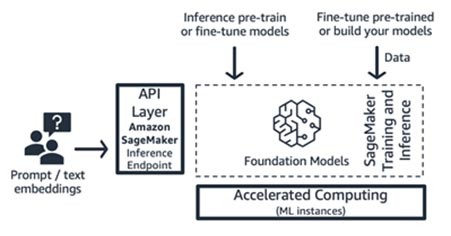
SageMaker sangat cocok untuk pembangun aplikasi AI generatif tumpukan penuh (dari penyedia model hingga konsumen model), atau untuk penyedia model dengan tim yang memiliki keterampilan prapemrosesan data dan ML lanjutan. SageMaker juga menawarkan model penetapan harga bayar sesuai penggunaan, biasanya dalam satuan instans-jam.
AWS Trainium dan AWS Inferentia (komputasi yang dipercepat)
Pada bulan April 2023, AWS mengumumkan ketersediaan umum Instans Trn1n Amazon EC2 yang didukung oleh AWS Trainium, dan Instans Inf2 Amazon EC2 yang didukung oleh AWS Inferentia2. Anda dapat memanfaatkan akselerator AWS yang dibuat khusus (AWS Trainium dan AWS Inferentia) menggunakan SageMaker sebagai platform ML.
Pengujian tolok ukur untuk beban kerja inferensi melaporkan performa instans Inf2 dengan biaya 52% lebih rendah dibandingkan instans Amazon EC2 yang dioptimalkan untuk inferensi serupa. Sebaiknya perhatikan siklus pengembangan yang cepat dari AWS Neuron SDK, di mana kira-kira setiap bulan AWS menambahkan arsitektur model baru dalam matriks dukungan mereka untuk pelatihan dan inferensi.
Pendekatan untuk membangun aplikasi AI generatif
Sekarang, mari kita bahas masing-masing komponen pada Gambar 9 dari perspektif implementasi.
Pendekatan inferensi pembelajaran zero-shot atau few-shot
Seperti yang telah kita bahas sebelumnya, pembelajaran zero-shot atau few-shot adalah pendekatan paling sederhana untuk membangun aplikasi AI generatif. Untuk membangun aplikasi berdasarkan pendekatan ini, yang Anda perlukan hanyalah layanan untuk empat komponen umum (model fondasi, antarmukanya, platform ML, dan komputasi), kode kustom untuk menghasilkan perintah, dan aplikasi web/seluler front-end.
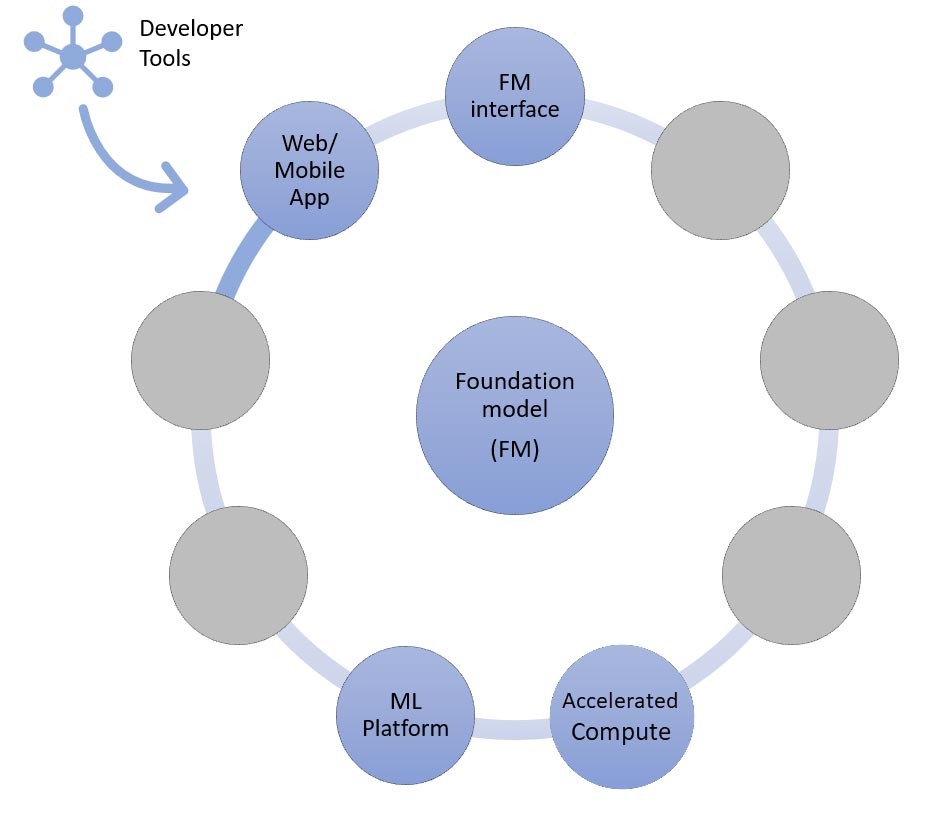
Untuk mempelajari selengkapnya tentang pemilihan model fondasi melalui Amazon Bedrock atau Amazon SageMaker JumpStart, lihat pedoman pemilihan model di sini.
Kode kustom dapat memanfaatkan alat developer, seperti LangChain untuk pembuatan dan templat perintah. Komunitas LangChain telah menambahkan dukungan untuk titik akhir Amazon Bedrock, Amazon API Gateway, dan SageMaker. Sekadar mengingatkan, Anda mungkin juga ingin memanfaatkanAWS Amazon CodeWhisperer, alat pendamping pengodean, untuk membantu meningkatkan efisiensi developer.
Perusahaan rintisan yang membangun aplikasi seluler atau aplikasi web front-end dapat dengan mudah memulai dan menskalakan menggunakan AWS Amplify, dan meng-hosting aplikasi web ini dengan cara yang cepat, aman, dan andal menggunakan AWS Amplify Hosting.
Lihat contoh pembelajaran zero-shot yang dibangun dengan SageMaker Jumpstart.
Pendekatan pengambilan informasi
Seperti yang telah dibahas, salah satu cara perusahaan rintisan Anda dapat menyesuaikan model fondasi adalah melalui augmentasi dengan sistem pengambilan informasi, yang paling dikenal sebagai retrieval-augmented generation (RAG). Pendekatan ini melibatkan semua komponen yang disebutkan dalam pembelajaran zero-shot dan few-shot, serta titik akhir penyematan teks dan basis data vektor.
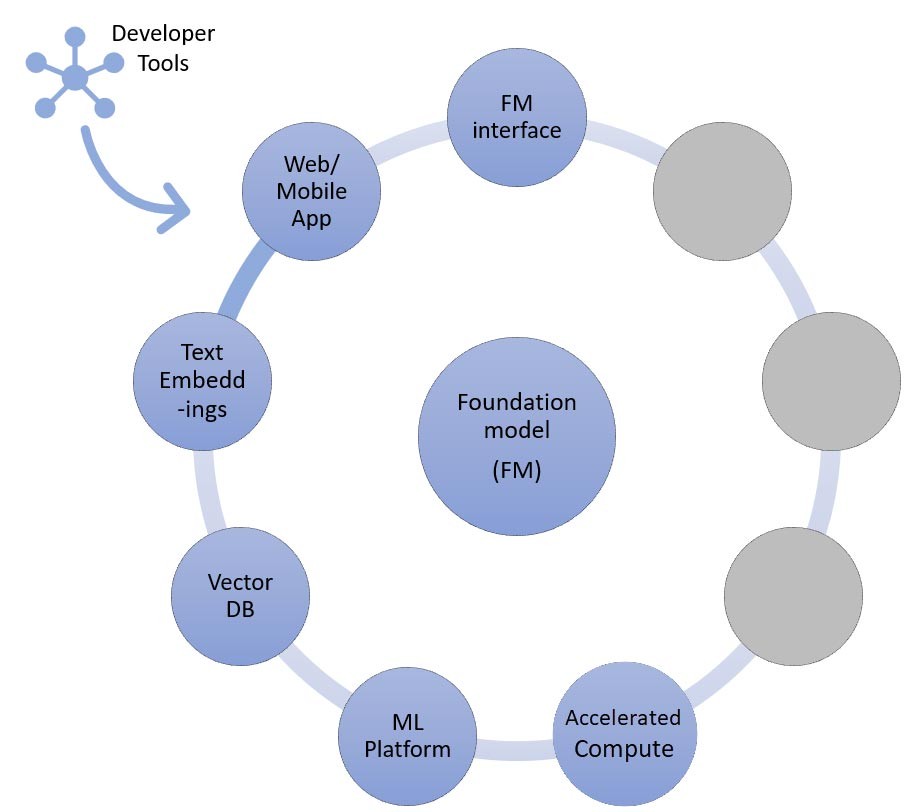
Opsi untuk titik akhir penyematan teks bervariasi, tergantung layanan terkelola AWS yang telah Anda pilih:
- Amazon Bedrock menawarkan model bahasa besar (LLM) penyematan yang menerjemahkan input teks (kata, frasa, atau mungkin unit teks besar) menjadi representasi numerik (dikenal sebagai penyematan) yang berisi makna semantik teks.
- Jika menggunakan SageMaker JumpStart, Anda dapat meng-hosting model penyematan, seperti GPT-J 6B atau LLM lain pilihan Anda dari hub model. Titik akhir SageMaker dapat diinvokasi oleh SageMaker SDK atau Boto3 untuk menerjemahkan input teks ke dalam penyematan.
Penyematan tersebut kemudian dapat disimpan dalam penyimpanan data vektor untuk melakukan pencarian semantik menggunakan ekstensi pgvector Amazon RDS for PostgreSQL atau plugin k-NN Amazon OpenSearch Service. Perusahaan rintisan lebih memilih salah satu layanan berdasarkan layanan yang biasanya paling nyaman mereka gunakan. Dalam beberapa kasus, perusahaan rintisan menggunakan basis data vektor asli AI dari partner AWS atau dari sumber terbuka. Untuk panduan mengenai pemilihan penyimpanan data vektor, sebaiknya lihat Peran penyimpanan data vektor dalam aplikasi AI generatif.
Dalam pendekatan ini juga, alat developer berperan penting. Alat developer menyediakan kerangka kerja plug-n-play yang mudah, templat perintah, dan dukungan luas untuk integrasi.
Ke depannya, Anda juga dapat memanfaatkan agen untuk Amazon Bedrock, sebuah kemampuan baru bagi developer yang dapat mengelola panggilan API ke sistem perusahaan Anda.
Lihat contoh penggunaan retrieval-augmented generation dengan model fondasi di Amazon SageMaker Jumpstart.
Pendekatan penyempurnaan atau prapelatihan lebih lanjut
Sekarang, mari kita petakan komponen ke layanan AWS yang diperlukan untuk pendekatan terakhir dalam mengimplementasikan aplikasi AI generatif: menyempurnakan atau melakukan prapelatihan lebih lanjut pada model fondasi. Pendekatan ini melibatkan semua komponen yang dibahas dalam pembelajaran zero-shot atau few-shot, serta prapemrosesan data dan pelatihan model.
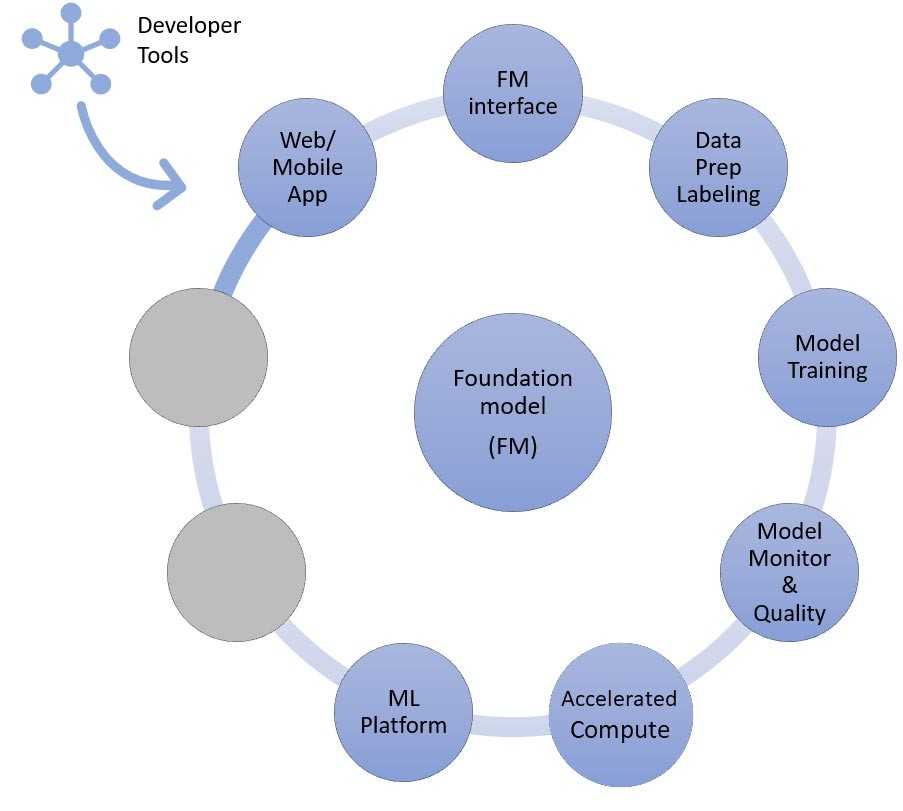
Persiapan data (terkadang disebut prapemrosesan atau anotasi) sangat penting selama penyempurnaan, ketika Anda memerlukan set data yang lebih kecil dan berlabel. Perusahaan rintisan dapat dengan mudah memulai menggunakan Amazon SageMaker Data Wrangler. Layanan ini membantu mengurangi waktu yang diperlukan untuk mengumpulkan serta menyiapkan data tabel dan gambar untuk machine learning dari hitungan minggu menjadi menit. Anda juga dapat memanfaatkan fitur pipeline inferensi layanan ini untuk menghubungkan alur kerja prapemrosesan ke pekerjaan pelatihan atau penyempurnaan.
Jika perusahaan rintisan Anda perlu melakukan prapemrosesan sejumlah besar set data yang tidak terstruktur dan tidak berlabel di danau data Anda pada Amazon S3, Anda memiliki beberapa opsi:
- Jika Anda menggunakan Python dan pustaka Python populer, ada gunanya memanfaatkan AWS Glue for Ray. AWS Glue menggunakan Ray, kerangka kerja komputasi terpadu sumber terbuka yang digunakan untuk menskalakan beban kerja Python
- Alternatifnya, Amazon EMR dapat membantu memproses data dalam jumlah besar menggunakan alat sumber terbuka, sepertiApache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, dan Presto.
Untuk komponen pelatihan model pendekatan ini, Amazon Bedrock memungkinkan Anda menyesuaikan FM secara privat dengan data Anda sendiri. Amazon Bedrock mengelola FM Anda dalam skala besar tanpa harus mengelola infrastruktur apa pun (ini adalah cara API untuk menyempurnakannya). Alternatifnya, pendekatan SageMaker Jumpstart memberikan solusi cepat untuk melakukan penyempurnaan secara privat (pada model tertentu) untuk instruksi atau adaptasi domain menggunakan data Anda sendiri. Anda dapat memodifikasi bundel skrip pelatihan SageMaker JumpStart untuk kebutuhan Anda, atau Anda dapat membawa skrip pelatihan Anda sendiri untuk model sumber terbuka, dan mengirimkannya sebagai tugas pelatihan SageMaker. Jika Anda harus melakukan prapelatihan lebih lanjut terhadap model (biasanya untuk model sumber terbuka), Anda dapat memanfaatkan pustaka pelatihan terdistribusi milik SageMaker untuk mempercepat dan memanfaatkan semua GPU dari instans ML secara efisien.
Selain itu, Anda juga dapat mempertimbangkan pembuatan data yang terkelola penuh, layanan anotasi data, dan pengembangan model dengan teknik Pembelajaran Penguatan dari Umpan Balik Manusia menggunakan Amazon SageMaker Ground Truth Plus.
Arsitektur contoh
Jadi, bagaimana tampilan semua komponen ini saat mewujudkan kasus penggunaan AI generatif? Meskipun setiap perusahaan rintisan memiliki kasus penggunaan yang berbeda, dan pendekatan unik untuk memecahkan masalah dunia nyata, satu tema umum atau titik awal yang saya lihat dalam membangun aplikasi AI generatif adalah pendekatan retrieval-augmented generation. Setelah menghubungkan semua layanan AWS yang dibahas di atas, arsitekturnya terlihat seperti ini:
Pipeline penyerapan – Data eksklusif atau khusus domain telah diproses sebelumnya sebagai data teks. Data ini diproses dalam batch (disimpan di Amazon S3) atau dialirkan (menggunakan Amazon Kinesis) saat dibuat atau diperbarui melalui proses penyematan, dan disimpan dalam representasi vektor padat.

Jalur pengambilan – Saat pengguna mengueri data eksklusif yang disimpan dalam representasi vektor, data tersebut akan diambil menggunakan k tetangga terdekat (kNN) atau pencarian semantik. Data ini kemudian didekode kembali menjadi teks yang jelas. Output-nya berfungsi sebagai konteks yang kaya dan padat terhadap perintah.

Pipeline pembuatan ringkasan – Konteks ditambahkan ke perintah dengan kueri pengguna asli untuk mendapatkan wawasan atau ringkasan dari dokumen yang diambil.

Semua lapisan ini dapat dibangun dengan beberapa baris kode dengan menggunakan alat developer, seperti LangChain.
Penutup
Ini adalah salah satu cara untuk membangun aplikasi AI generatif ujung ke ujung menggunakan layanan AWS. Layanan AWS yang Anda pilih akan bervariasi berdasarkan kasus penggunaan atau pendekatan penyesuaian yang Anda terapkan. Pantau terus rilis, solusi, dan blog AWS terbaru mengenai AI generatif dengan menandai tautan ini.
Mari bangun aplikasi AI generatif di AWS! Mulailah perjalanan AI generatif Anda dengan AWS Activate, program gratis yang dirancang khusus untuk perusahaan rintisan dan wirausaha tahap awal yang menawarkan sumber daya yang diperlukan untuk memulai di AWS.

Hrushikesh Gangur
Hrushikesh Gangur adalah Principal Solutions Architect untuk Startups AI/ML dengan keahlian, baik dalam machine learning maupun layanan jaringan AWS. Dia membantu Startups membangun AI generatif, kendaraan otonom, dan platform ML untuk menjalankan bisnis mereka secara efisien dan efektif di AWS.
Bagaimana konten ini?