Wie war dieser Inhalt?
- Lernen
- Generative KI-Anwendungen für Ihr Startup erstellen
Generative KI-Anwendungen für Ihr Startup erstellen
Durch die jüngsten Fortschritte im Bereich der generativen KI werden die Anforderungen an Tools, die Startups bei der schnellen Entwicklung, Skalierung und Innovation helfen können, immer höher. Diese weit verbreitete Akzeptanz und Demokratisierung von Machine Learning (ML), insbesondere im Zusammenhang mit der neuronalen Netzwerkarchitektur mit Transformatoren, ist ein spannender Wendepunkt in der Technologie. Mit den richtigen Tools können Startups neue Ideen entwickeln oder ihr bestehendes Produkt umgestalten, um die Vorteile generativer KI für ihre Kunden zu nutzen.
Sind Sie bereit, eine generative KI-Anwendung für Ihr Startup zu erstellen? Lassen Sie uns zunächst die Konzepte, Kernideen und gängigen Ansätze zur Entwicklung generativer KI-Anwendungen überprüfen.
Was sind generative KI-Anwendungen?
Generative KI-Anwendungen sind Programme, die auf einer Art von KI basieren und neue Inhalte und Ideen erstellen können, darunter Konversationen, Geschichten, Bilder, Videos, Code und Musik. Wie alle KI-Anwendungen basieren auch generative KI-Anwendungen auf ML-Modellen, die anhand riesiger Datenmengen vorab trainiert wurden und allgemein als Basismodells (FMs) bezeichnet werden.
Ein Beispiel für eine generative KI-Anwendung ist Amazon CodeWhisperer, ein KI-Codierungsbegleiter, der Entwicklern hilft, Anwendungen schneller und sicherer zu erstellen, indem er Vorschläge für ganze Zeilen- und Vollfunktionscode in Ihrer integrierten Entwicklungsumgebung (IDE) bereitstellt. CodeWhisperer ist an Milliarden von Codezeilen geschult und kann auf der Grundlage Ihrer Kommentare und des vorhandenen Codes sofort Codevorschläge generieren, die von Ausschnitten bis hin zu vollständigen Funktionen reichen. Startups können AWS-Activate-Guthaben im Rahmen der CodeWhisperer-Professional-Stufe nutzen oder mit dem kostenlosen Tarif Individual beginnen.
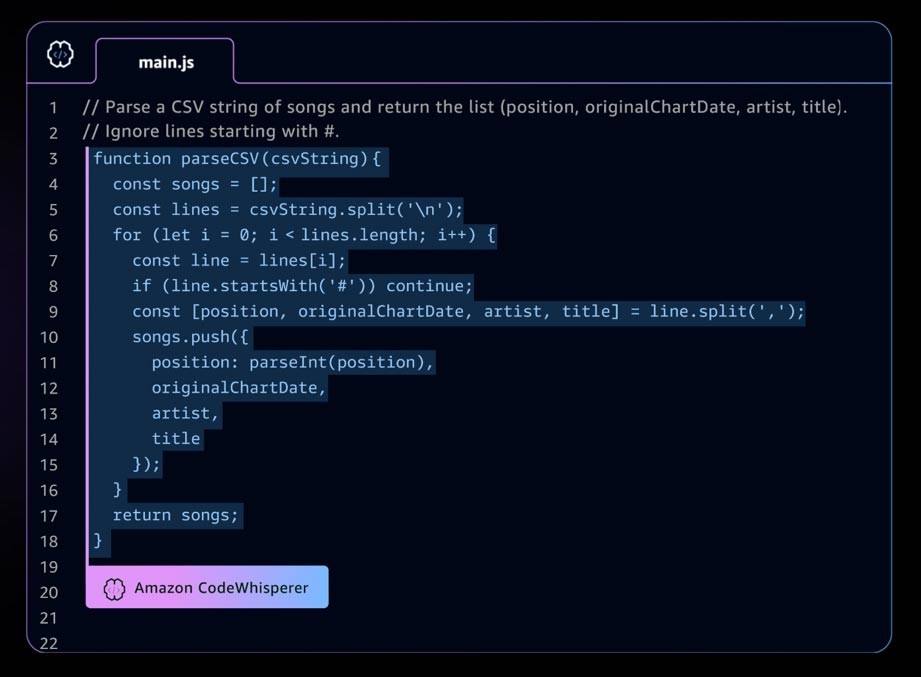
Die sich schnell entwickelnde generative KI-Landschaft
Es gibt ein schnelles Wachstum bei generativen KI-Startups und auch bei Startups, die Tools entwickeln, um die Einführung generativer KI zu vereinfachen. Tools wie LangChain– ein Open-Source-Framework für die Entwicklung von Anwendungen, die auf Sprachmodellen basieren – machen generative KI für ein breiteres Spektrum von Organisationen zugänglicher, was zu einer schnelleren Einführung führen wird. Zu diesen Tools gehören auch Promp-Engineering, erweiterte Dienste (wie Einbettungstools oder Vektordatenbanken), Modellüberwachung, Messung der Modellqualität, Leitplanken, Datenannotation, verstärktes Lernen aus menschlichem Feedback (RLHF) und vieles mehr.
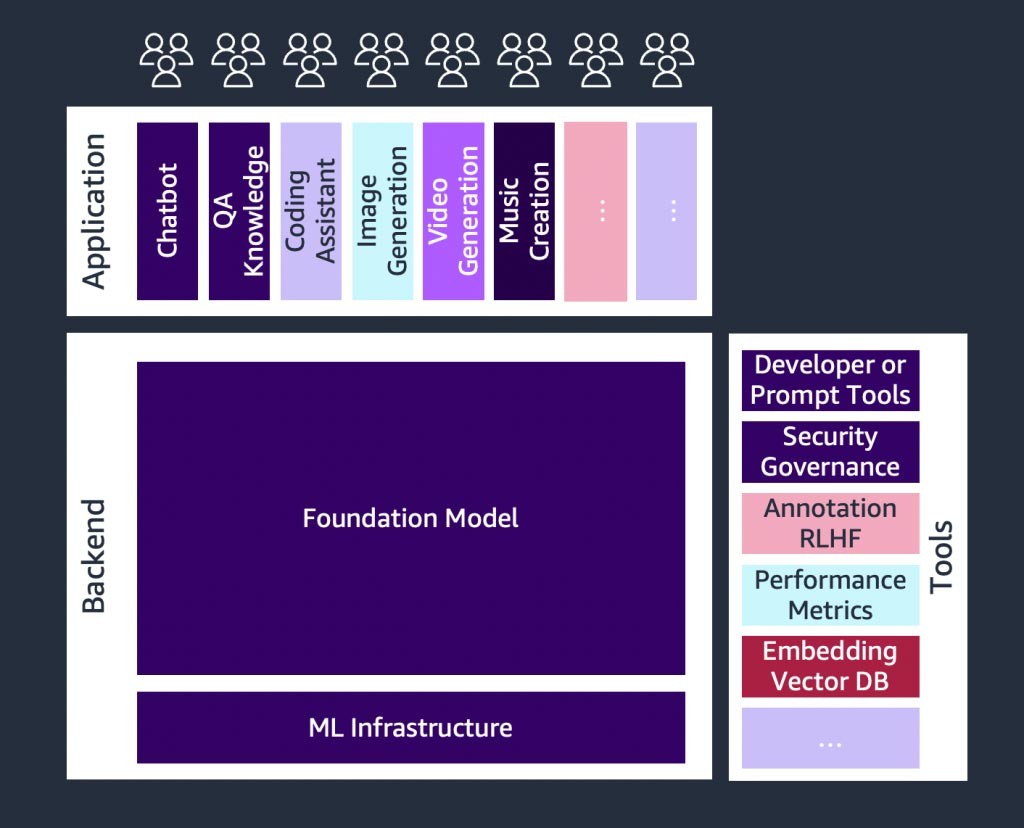
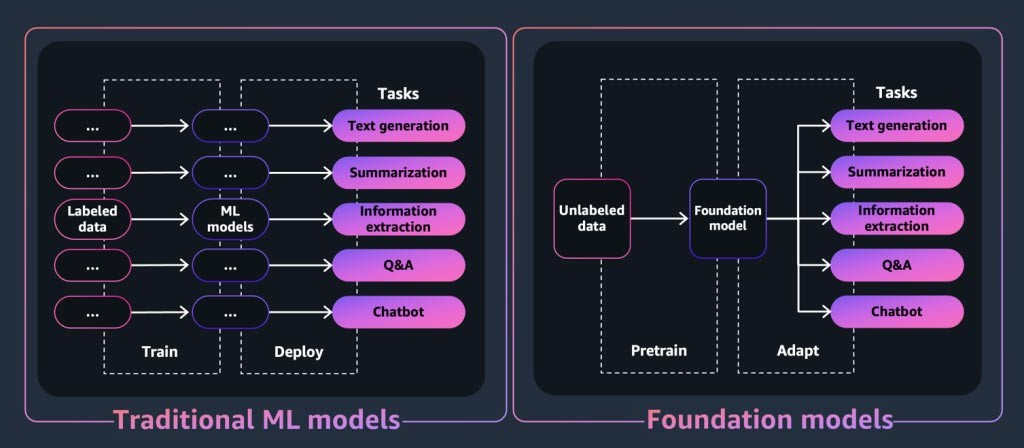
Eine Einführung in Basismodelle
Bei einer generativen KI-Anwendung oder einem Tool steht das Basismodell im Mittelpunkt. Bei Basismodellen handelt es sich um eine Klasse leistungsstarker Modelle für Machine Learning, die sich dadurch auszeichnen, dass sie anhand riesiger Datenmengen vorab trainiert werden können, um eine Vielzahl nachgelagerter Aufgaben auszuführen. Zu diesen Aufgaben gehören Textgenerierung, Zusammenfassung, Informationsextraktion, Fragen und Antworten und/oder Chatbots. Im Gegensatz dazu werden herkömmliche ML-Modelle darauf trainiert, eine bestimmte Aufgabe anhand eines Datensatzes auszuführen.
Wie „generiert“ also ein Basismodell die Ausgabe, für den generative KI-Anwendungen bekannt sind? Diese Fähigkeiten resultieren aus Lernmustern und Beziehungen, die es dem FM ermöglichen, das nächste Element oder die nächsten Elemente in einer Sequenz vorherzusagen oder ein neues zu generieren:
- In textgenerierenden Modellen geben FMs das nächste Wort, die nächste Phrase oder die Antwort auf eine Frage aus.
- Bei Modellen zur Bilderzeugung geben FMs ein Bild aus, das auf dem Text basiert.
- Wenn es sich bei einem Bild um eine Eingabe handelt, geben FMs das nächste relevante oder hochskalierte Bild, die Animation oder das nächste 3D-Bild aus.
In jedem Fall beginnt das Modell mit einem Seed-Vektor, der von einer „Aufforderung“ abgeleitet wird: Prompts beschreiben die Aufgabe, die das Modell ausführen muss. Die Qualität und Detailgenauigkeit (auch als „Kontext“ bezeichnet) der Aufforderung bestimmen die Qualität und Relevanz der Ausgabe.
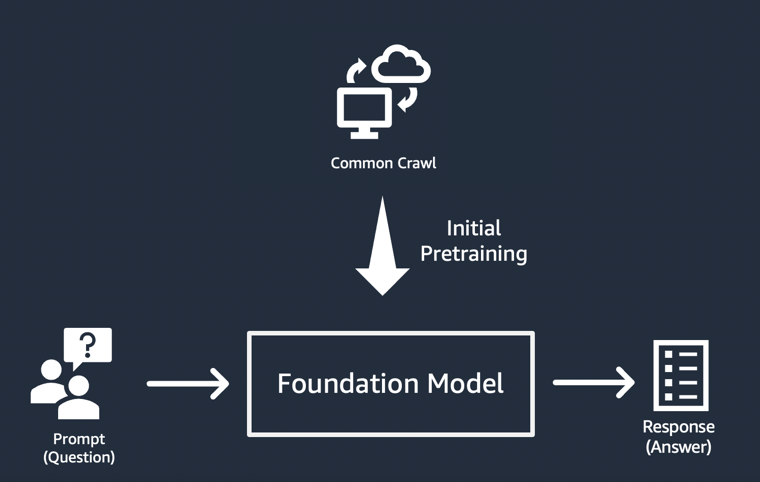
Die einfachste Implementierung generativer KI-Anwendungen
Der einfachste Ansatz für die Erstellung einer generativen KI-Anwendung besteht darin, ein auf Anweisungen abgestimmtes Basismodell zu verwenden und mithilfe von Zero-Shot Learning oder Few-Shot Learning eine aussagekräftige Aufforderung („Prompt-Engineering“) bereitzustellen. Ein auf Anweisungen abgestimmtes Modell (wie FLAN T5 XXL, Open-Llama oder Falcon 40B Instruct) nutzt sein Verständnis verwandter Aufgaben oder Konzepte, um Vorhersagen für Eingabeaufforderungen zu generieren. Hier sind einige Beispiele für Eingabeaufforderungen:
Zero-Shot-Lernen
Titel:\”Die Universität hat eine neue Einrichtung vor der Tür“\\nStellen Sie sich den Artikel vor, wenn Sie den obigen Titel eines imaginären Artikels sehen.\n
Few-Shot-Lernen
Das ist genial! //Positiv
Das ist schlimm! //Negativ
Dieser Film war hoffnungslos! //Negativ
Was für eine schreckliche Show! //
REAKTION: Negativ
Insbesondere Startups können von der schnellen Bereitstellung, dem minimalen Datenbedarf und der Kostenoptimierung profitieren, die sich aus der Verwendung eines auf Anweisungen abgestimmten Modells ergeben.
Weitere Informationen zu den Überlegungen bei der Auswahl eines Basismodells findest du unter Auswahl des richtigen Basismodells für Ihr Startup.
Anpassen von Basismodellen
Nicht alle Anwendungsfälle lassen sich durch die Nutzung von Prompt-Engineering an Anweisungssequenzen Modellen erfüllen. Gründe für die Anpassung eines Basismodells für Ihr Startup können sein:
- Hinzufügen einer bestimmten Aufgabe (z. B. Codegenerierung) zum Basismodell
- Generierung von Antworten auf der Grundlage des firmeneigenen Datensatzes
- Suche nach Antworten, die aus qualitativ hochwertigeren Datensätzen generiert wurden als denen, die das Modell vortrainiert haben
- Reduzierung der „Halluzination“, bei der es sich um Ergebnisse handelt, die nicht sachlich korrekt oder vernünftig sind
Es gibt drei gängige Techniken, um ein Fundamentmodell anzupassen.
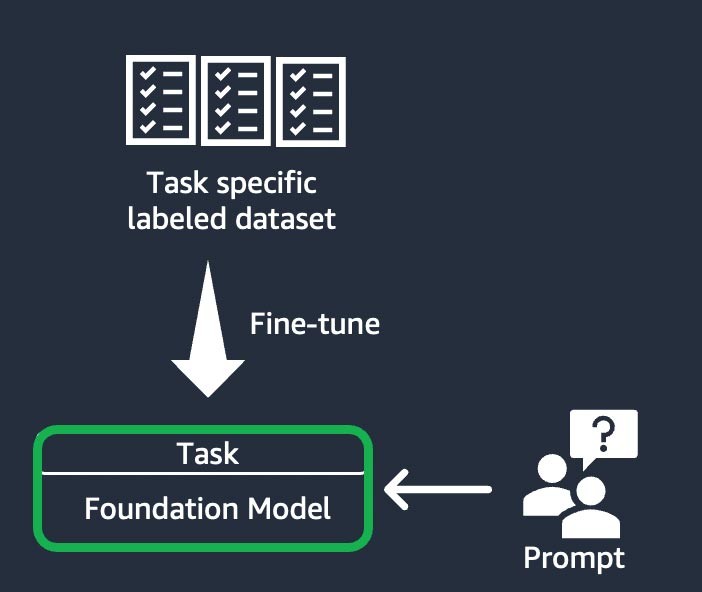
Instruktionsbasierte Feinabstimmung
Bei dieser Technik wird das Basismodell trainiert, um eine bestimmte Aufgabe auf der Grundlage eines aufgabenspezifisch beschrifteten Datensatzes zu erledigen. Ein beschrifteter Datensatz besteht aus Paaren von Eingabeaufforderungen und Antworten. Diese Personalisierungstechnik ist für Startups von Vorteil, die ihr FM schnell und mit einem minimalen Datensatz anpassen möchten: Das Training erfordert weniger Datensätze und Schritte. Die Aktualisierung der Modellgewichte basiert auf der Aufgabe oder der Ebene, an dem Sie die Feinabstimmung vornehmen.
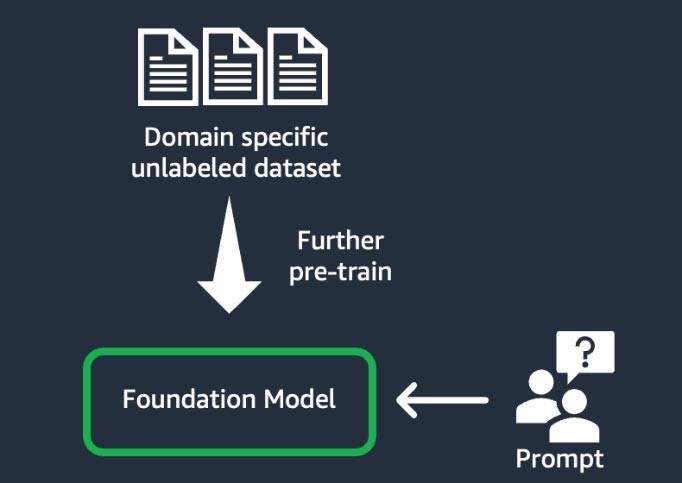
Domainanpassung (auch bekannt als „weitere Vorschulung“)
Bei dieser Technik wird das Basismodell mithilfe eines großen „Korpus“ – einer Sammlung von Trainingsmaterialien – aus domänenspezifischen, unbeschrifteten Daten trainiert (bekannt als „selbstüberwachtes Lernen“). Diese Technik eignet sich für Anwendungsfälle, die Domain-spezifischen Jargon und statistische Daten beinhalten, die das bestehende Basismodell noch nie zuvor gesehen hat. Zum Beispiel könnten Startups, die eine generative KI-Anwendung für die Arbeit mit eigenen Daten im Finanzbereich entwickeln, von einer weiteren Vorschulung des Finanzdienstleisters in Bezug auf benutzerdefiniertes Vokabular und von der „Tokenisierung“ profitieren, einem Prozess, bei dem Text in kleinere Einheiten, sogenannte Tokens, zerlegt wird.
Um eine höhere Qualität zu erreichen, setzen einige Startups in diesem Prozess Techniken des verstärkten Lernens aus menschlichem Feedback (RLHF) ein. Darüber hinaus wird eine anweisungsbasierte Feinabstimmung erforderlich sein, um eine bestimmte Aufgabe zu verfeinern. Dies ist im Vergleich zu den anderen eine teure und zeitaufwändige Technik. Die Modellgewichte werden auf allen Ebenen aktualisiert.
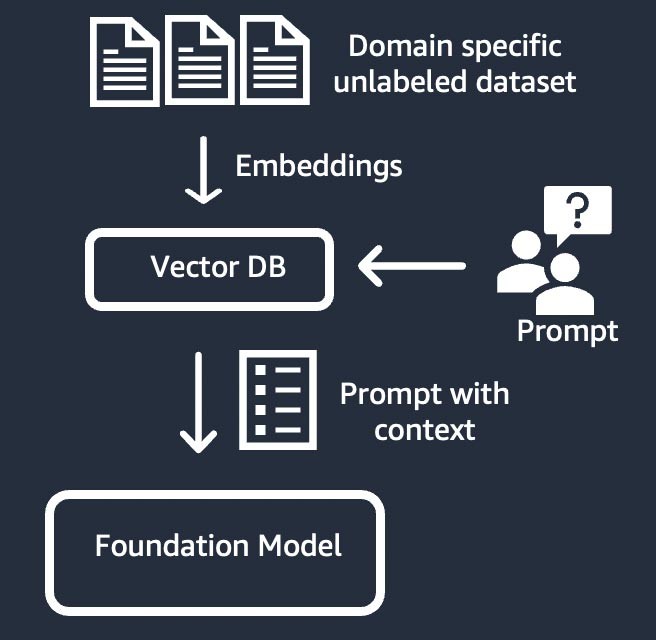
Informationsabruf (auch bekannt als „Retrieval-Augmented Generation“ oder „RAG“)
Diese Technik erweitert das Basismodell um ein Informationsabrufsystem, das auf einer dichten Vektordarstellung basiert. Das Wissen der geschlossenen Domain oder die proprietären Daten durchlaufen einen Texteinbettungsprozess, um eine Vektordarstellung des Korpus zu erzeugen, und werden in einer Vektordatenbank gespeichert. Ein auf der Benutzerabfrage basierendes semantisches Suchergebnis wird zum Kontext für die Aufforderung. Das Basismodell wird verwendet, um eine Antwort auf der Grundlage der Aufforderung mit Kontext zu generieren. Bei dieser Technik wird die Gewichtung des Basismodells nicht aktualisiert.
Komponenten einer generativen KI-Anwendung
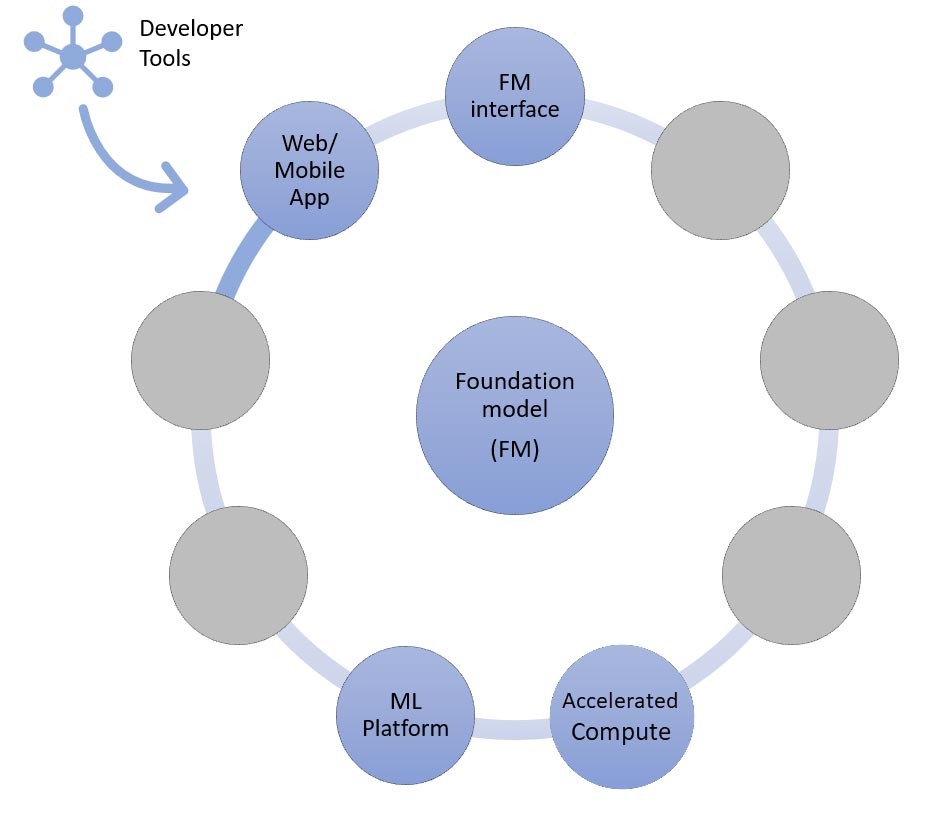
In den obigen Abschnitten haben wir verschiedene Ansätze kennengelernt, die Startups bei der Entwicklung generativer KI-Anwendungen mit Basismodellen verfolgen können. Schauen wir uns nun an, inwiefern diese Basismodelle Teil der typischen Bestandteile oder Komponenten sind, die für die Entwicklung einer generativen KI-Anwendung erforderlich sind.
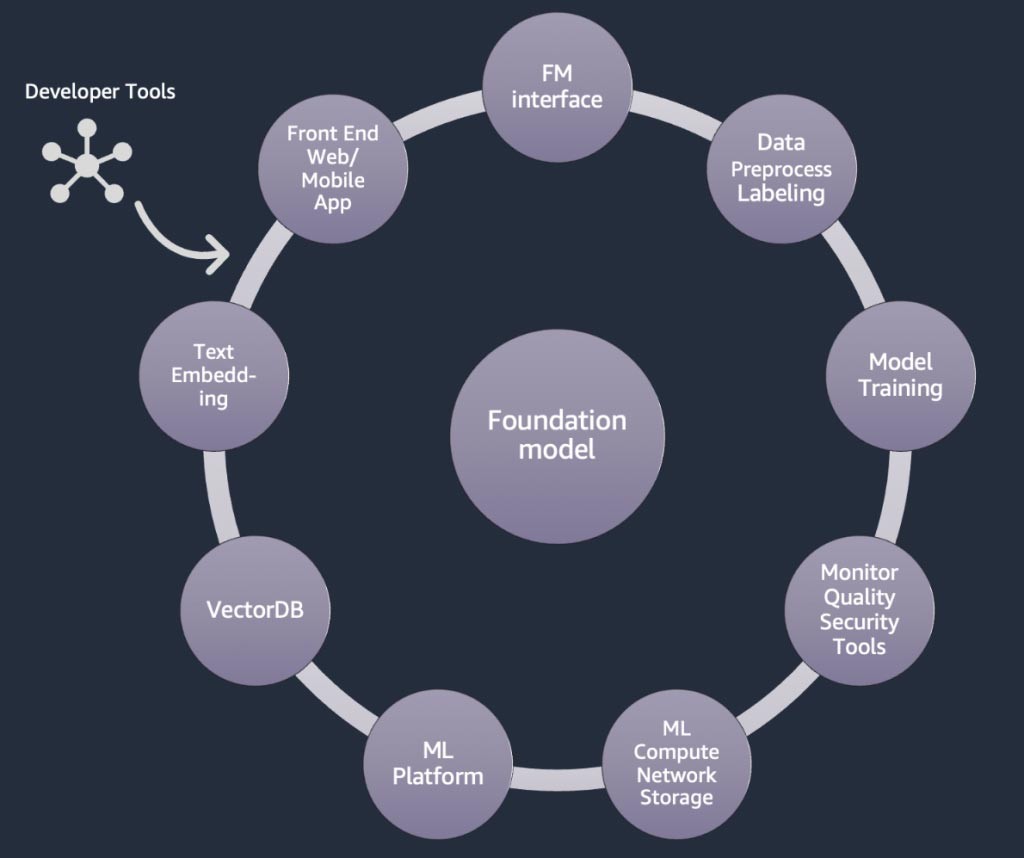
Im Mittelpunkt steht ein Basismodell (Mitte). Der einfachste Ansatz, der weiter oben in diesem Blog erörtert wurde, erfordert eine Webanwendung oder mobile App (oben links), die über eine API (oben) auf das Basismodell zugreift. Diese API ist entweder ein verwalteter Service über einen Modellanbieter oder wird mithilfe eines Open-Source-Modells oder eines proprietären Modells selbst gehostet. Im Fall des Self-Hostings benötigen Sie möglicherweise eine Plattform für Machine Learning, die von beschleunigten Computing-Instances unterstützt wird, um das Modell zu hosten.
Bei der RAG-Technik müssen Sie einen Endpunkt für die Texteinbettung und eine Vektordatenbank (links und unten links) hinzufügen. Beide werden entweder als API-Service bereitgestellt oder selbst gehostet. Der Endpunkt zur Texteinbettung wird durch ein Basismodell unterstützt, und die Wahl des Basismodells hängt von der Einbettungslogik und der Tokenisierungsunterstützung ab. All diese Komponenten sind mithilfe von Entwicklertools miteinander verbunden, die den Rahmen für die Entwicklung generativer KI-Anwendungen bilden.
Und schließlich, wenn Sie sich für die Anpassungstechniken der Feinabstimmung oder des weiteren Vortrainings eines Basismodells entscheiden (rechts), benötigen Sie Komponenten, die bei der Datenvorverarbeitung und Annotation helfen (oben rechts), und eine ML-Plattform (unten), um den Trainingsjob auf bestimmten beschleunigten Computing-Instances auszuführen. Einige Modellanbieter unterstützen API-basierte Feinabstimmung. In solchen Fällen müssen Sie sich keine Gedanken über die ML-Plattform und die zugrunde liegende Hardware machen.
Unabhängig vom Anpassungsansatz möchten Sie möglicherweise auch Komponenten integrieren, die Überwachungs-, Qualitätsmetriken- und Sicherheitstools bereitstellen (unten rechts).
Welche AWS-Services sollte ich verwenden, um meine generative KI-Anwendung zu erstellen?
Das folgende Diagramm, Abbildung 9, ordnet jede Komponente den entsprechenden AWS-Services zu. Beachten Sie, dass es sich dabei um eine kuratierte Reihe von AWS-Services handelt, von denen ich sehe, dass Startups davon profitieren. Es sind jedoch auch andere AWS-Services verfügbar.
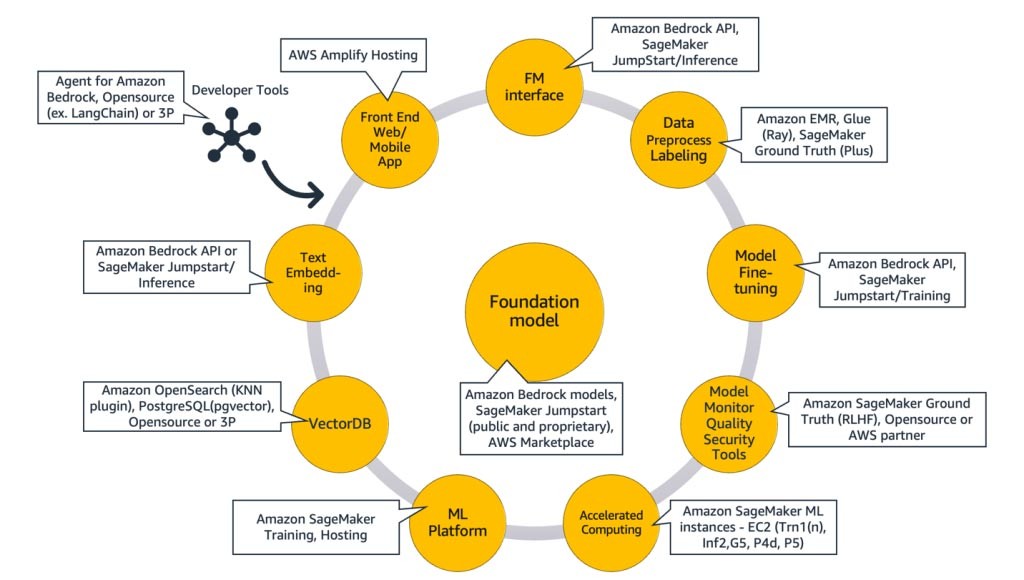
Um das näher zu erläutern, werde ich damit beginnen, AWS-Services den gemeinsamen Komponenten einer generativen KI-Anwendung zuzuordnen. Anschließend werde ich anhand der Ansätze, die Sie zur Implementierung Ihrer Anwendung verwenden, die AWS-Services erläutern, die den übrigen Komponenten in Abbildung 9 zugeordnet sind.
Gemeinsame Komponenten
Die gemeinsamen Komponenten einer generativen KI-Anwendung sind das Foundation Model (FM), seine Schnittstelle und optional die Plattform für Machine Learning (ML) und beschleunigtes Rechnen. Diese können mit verwalteten Angeboten von AWS erfüllt werden:
Amazon Bedrock (Basismodell und seine Schnittstellenkomponenten)
Amazon Bedrock, ein vollständig verwalteter Service, der Basismodelle von führenden KI-Startups (Jurassic von AI21, Claude von Anthropic, Command and Embedding von Cohere, SDXL-Modelle von Stability) und Amazon (Titan Text- und Embeddings-Modelle) über API verfügbar macht, sodass Sie aus einer Vielzahl von FMs wählen können, um das Modell zu finden, das für Ihren Anwendungsfall am besten geeignet ist. Amazon Bedrock bietet API- oder Serverless-Zugriff auf eine Reihe von Basismodellen mit drei Funktionen: Texteinbettung, Aufforderung/Antwort und Feinabstimmung (bei ausgewählten Modellen).
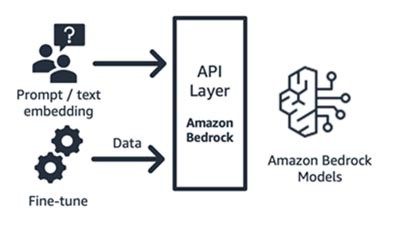
Amazon Bedrock eignet sich hervorragend für Anwendungs- oder Modell-Startups, die Mehrwertservices – Prompt-Engineering, erweiterte Generierung mit Abruf und mehr – auf der Grundlage eines Basismodells ihrer Wahl aufbauen. Das Preismodell basiert auf nutzungsbasierter Bezahlung, in der Regel in der Einheit von Millionen verarbeiteter Tokens. Amazon Bedrock ist allgemein verfügbar. Einige der in diesem Blog besprochenen Features befinden sich jedoch in der privaten Vorschauversion. Erfahren Sie hier mehr.
Amazon SageMaker JumpStart (Basismodell und seine Schnittstellenkomponenten)
AWS bietet generative KI-Funktionen für Amazon SageMaker Jumpstart: einen Hub für Basismodelle, der sowohl öffentlich verfügbare als auch proprietäre Modelle, Schnellstartlösungen und Beispiel-Notebooks für die Bereitstellung und Feinabstimmung von Modellen enthält. Wenn Sie diese Modelle einsetzen, wird ein Echtzeit-Inferenzendpunkt erstellt, auf den Sie direkt über das SageMaker SDK/API zugreifen können. Oder Sie können den Fundamentmodell-Endpunkt von SageMaker mit AWS API Gateway und einer einfachen Rechenlogik in einer AWS Lambda-Funktion als Frontend nutzen. Sie können einige dieser Modelle auch für die Texteinbettung nutzen.
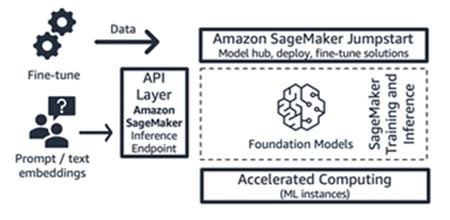
Sowohl der Inferenzendpunkt als auch die Schulungsaufgaben zur Feinabstimmung werden auf verwalteten ML-Instances Ihrer Wahl (siehe „Accelerated Computing“ in Abbildung 9) ausgeführt, wobei SageMaker als ML-Plattform verwendet wird (siehe „ML-Plattform“ in Abbildung 9). SageMaker Jumpstart eignet sich gut für Anwendungs- oder Modell-Startups, die mehr Kontrolle über ihre Infrastruktur wünschen und über mäßige ML-Kenntnisse und Infrastrukturkenntnisse verfügen. Das Preismodell basiert auf nutzungsbasierter Bezahlung, in der Regel in der Einheit der Instance-Stunden. Alle Modelle und Lösungen in diesem Angebot sind allgemein verfügbar.
Amazon-SageMaker-Schulung und Inferenz (ML-Plattform)
Startups können die Schulungs- und Inferenzfeatures von Amazon SageMaker für erweiterte Funktionen wie verteilte Schulungen, verteilte Inferenz, Multimodell-Endpunkt und mehr nutzen. Sie können die Basismodelle aus dem Model-Hub Ihrer Wahl beziehen – ob das nun SageMaker JumpStart, Hugging Face oder AWS Marketplace ist, oder Sie können Ihr eigenes Basismodell von Grund auf neu erstellen.
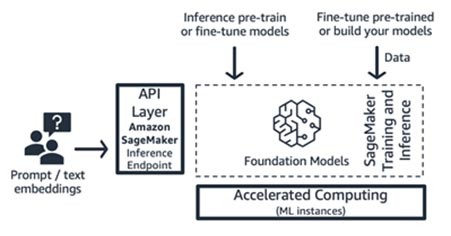
SageMaker eignet sich gut für Generative KI-Anwendungsentwickler mit umfassendem Stack (von Modellanbietern bis hin zu Modellnutzern) oder für Modellanbieter mit Teams, die über fortgeschrittene ML- und Datenvorverarbeitungskenntnisse verfügen. SageMaker bietet auch ein nutzungsabhängiges Preismodell, das in der Regel in der Einheit von Instance-Stunden berechnet wird.
AWS Trainium und AWS Inferentia (beschleunigte Datenverarbeitung)
Im April 2023 kündigte AWS die allgemeine Verfügbarkeit von Amazon-EC2-Trn1n-Instances, die von AWS Trainium betrieben werden, und von Amazon-EC2-Inf2-Instances , die von AWS Inferentia2 betrieben werden, an. Mit SageMaker als ML-Plattform können Sie speziell entwickelte AWS-Beschleuniger (AWS Trainium und AWS Inferentia) nutzen.
Der Benchmark-Test für Inferenz-Workloads ergab, dass Inf2-Instances im Vergleich zu einer vergleichbaren, für Inferenz optimierten Amazon EC2-Instance um 52 % kostengünstiger arbeiten. Ich schlage vor, die schnellen Entwicklungszyklen des AWS Neuron SDK im Auge zu behalten, bei denen AWS etwa jeden Monat eine neue Modellarchitektur in seine Support-Matrix sowohl für Schulungen als auch für Inferenzen aufnimmt.
Ansätze für den Aufbau generativer KI-Anwendungen
Lassen Sie uns nun jede der Komponenten in Abbildung 9 aus der Perspektive der Implementierung betrachten.
Der Zero-Shot- oder Few-Shot-Lerninferenzansatz
Wie wirbereits erwähnt haben, ist Zero-Shot- oder Few-Shot-Lernen der einfachste Ansatz für die Erstellung einer generativen KI-Anwendung. Um Anwendungen zu erstellen, die auf diesem Ansatz basieren, benötigen Sie lediglich die Dienste für die vier gemeinsamen Komponenten (Basismodell, dessen Schnittstelle, ML-Plattform und Datenverarbeitung), Ihren benutzerdefinierten Code zum Generieren von Eingabeaufforderungen und eine Frontend-Web-/Mobil-App.
Weitere Informationen zur Auswahl eines Basismodells über Amazon Bedrock oder Amazon SageMaker JumpStart finden Sie in den Richtlinien zur Modellauswahl hier.
Der benutzerdefinierte Code kann Entwicklertools wie LangChain für Vorlagen und Generierung von Eingabeaufforderungen nutzen. Die LangChain-Community hat bereits Unterstützung für Amazon Bedrock, Amazon API Gateway und SageMaker-Endpunkte hinzugefügt. Nur zur Erinnerung: Vielleicht möchten Sie auch AWS Amazon CodeWhisperer, ein Coding-Begleittool, nutzen, um die Effizienz von Entwicklern zu verbessern.
Startups, die eine Front-End-Web-App oder mobile App entwickeln, können mithilfe von AWS Amplify ganz einfach starten und skalieren und diese Web-Apps mit AWS Amplify Hosting schnell, sicher und zuverlässig hosten.
Schauen Sie sich dieses Beispiel für Zero-Shot-Lernen an , das mit SageMaker Jumpstart erstellt wird.
Der Ansatz zum Abrufen von Informationen
Wie bereits erwähnt, kann Ihr Startup Basismodelle unter anderem anpassen, indem es sie um ein Informationsabrufsystem erweitert, das allgemein als Retrieval-Augmented Generation (RAG) bekannt ist. Dieser Ansatz umfasst alle beim Zero-Shot- und Few-Shot-Lernen genannten Komponenten sowie die Texteinbettung, den Endpunkt und die Vektordatenbank.
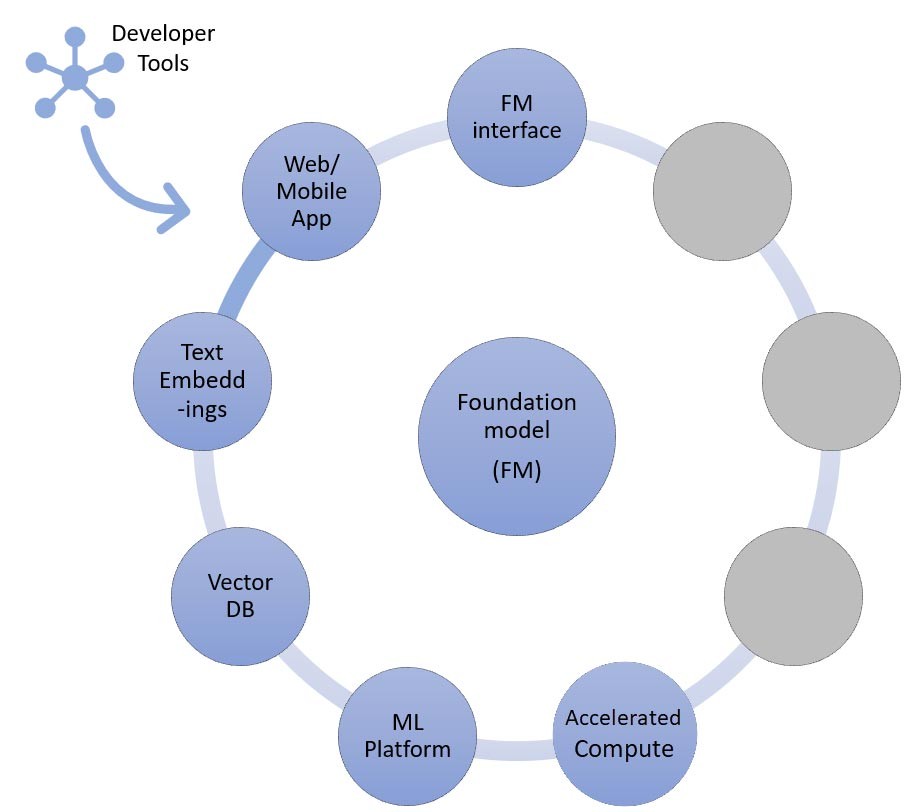
Die Optionen für den Endpunkt Texteinbettungen variieren je nachdem, welchen AWS Managed Service Sie ausgewählt haben:
- Amazon Bedrock bietet ein großes Sprachmodell (LLM) für Einbettungen, das Texteingaben (Wörter, Phrasen oder möglicherweise große Texteinheiten) in numerische Darstellungen (so genannte Einbettungen) übersetzt, die die semantische Bedeutung des Textes enthalten.
- Wenn Sie SageMaker JumpStart verwenden, können Sie ein Einbettungsmodell wie GPT-J 6B oder ein anderes LLM Ihrer Wahl vom Model Hub aus hosten. Der SageMaker-Endpunkt kann vom SageMaker SDK oder Boto3 aufgerufen werden, um Texteingaben in Einbettungen zu übersetzen.
Die Einbettungen können dann in einem Vektordatenspeicher gespeichert werden, um semantische Suchen entweder mit der Amazon RDS für PostgreSQL- pgvector-Erweiterung oder mit dem k-NN-Plugin von Amazon OpenSearch Service durchzuführen. Startups bevorzugen den einen oder anderen, je nachdem, mit welchem Service sie sich in der Regel am wohlsten fühlen. In einigen Fällen verwenden Startups native KI-Vektordatenbanken von AWS-Partnern oder von Open Source. Als Anleitung zur Auswahl von Vektordatenspeichern empfehle ich, den Artikel Die Rolle von Vektordatenspeichern in generativen KI-Anwendungen zu lesen.
Auch bei diesem Ansatz spielen Entwicklertools eine zentrale Rolle. Sie bieten ein einfaches Plug-and-Play-Framework, schnelle Vorlagen und umfassende Unterstützung für Integrationen.
In Zukunft können Sie auch Kundendienstmitarbeiter für Amazon Bedrock nutzen, eine neue Funktion für Entwickler, die API-Aufrufe an Ihre Unternehmenssysteme verwalten können.
Sehen Sie sich dieses Beispiel für die Verwendung der erweiterten Generierung von Retrieval mit Basismodellen in Amazon SageMaker Jumpstart an.
Der Ansatz zur Feinabstimmung oder zur weiteren Vorbereitung
Lassen Sie uns nun die Komponenten den AWS-Services zuordnen, die für den letzten Ansatz zur Implementierung einer generativen KI-Anwendung benötigt werden: Feinabstimmung oder weitere Vorschulung eines Basismodells. Dieser Ansatz umfasst alle Komponenten, die beim Zero-Shot- oder Few-Shot-Lernen behandelt wurden, sowie die Datenvorverarbeitung und das Modelltraining.
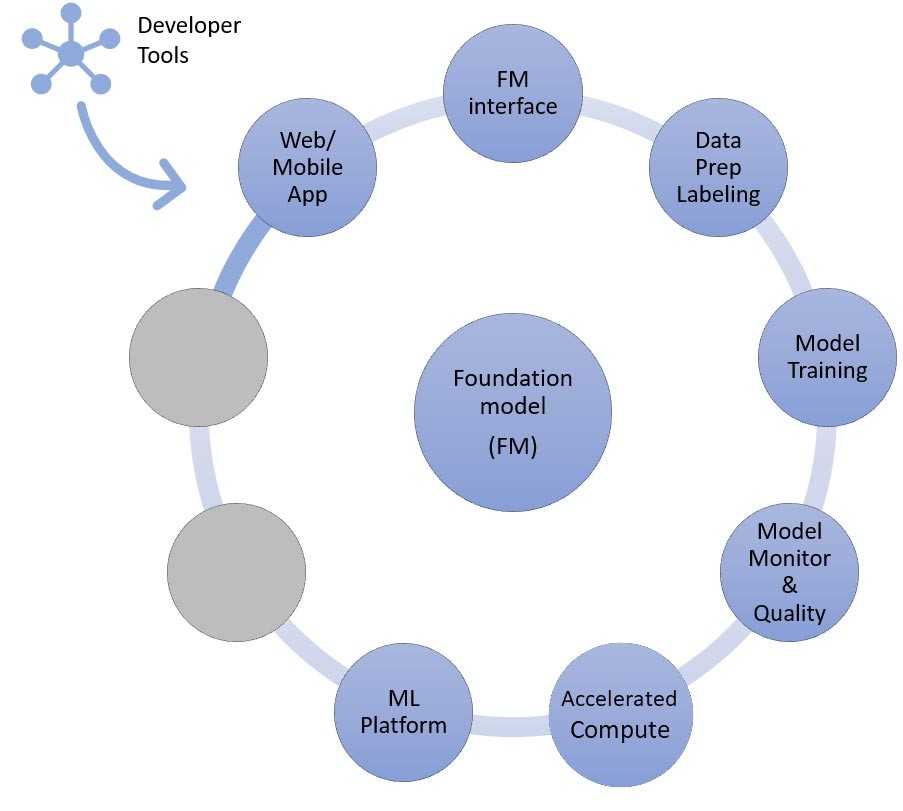
Die Datenaufbereitung (manchmal auch als Vorverarbeitung oder Anmerkung bezeichnet) ist besonders wichtig bei der Feinabstimmung, bei der Sie kleinere und beschriftete Datensätze benötigen. Startups können mit Amazon SageMaker Data Wrangler ganz einfach loslegen. Dieser Service trägt dazu bei, die Zeit, die für die Aggregation und Vorbereitung von Tabellen- und Bilddaten für Machine Learning benötigt wird, von Wochen auf Minuten zu reduzieren. Sie können auch das Inferenz-Pipeline-Feature dieses Services nutzen, um den Vorverarbeitungs-Workflow mit Schulungs- oder Feinabstimmungsaufgaben zu verknüpfen.
Wenn Ihr Startup einen riesigen Korpus von unstrukturierten und unbeschrifteten Datensätzen in Ihrem Data Lake auf Amazon S3 vorverarbeiten muss, haben Sie mehrere Optionen:
- Wenn Sie Python und beliebte Python-Bibliotheken verwenden, ist es sinnvoll, AWS Glue for Ray zu nutzen. AWS Glue verwendet Ray, ein einheitliches Open-Source-Rechenframework, das zur Skalierung von Python-Workloads verwendet wird
- Alternativ kann Amazon EMR bei der Verarbeitung großer Datenmengen mithilfe von Open-Source-Tools wie Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi und Prestohelfen.
Für die Modellschulungskomponente dieses Ansatzes ermöglicht Ihnen Amazon Bedrock, FMs privat mit Ihren eigenen Daten anzupassen. Es verwaltet Ihre FMs in großer Skalierung, ohne dass Sie eine Infrastruktur verwalten müssen (dies ist die API-Methode zur Feinabstimmung). Alternativ bietet der SageMaker-Jumpstart-Ansatz eine Schnellstartlösung zur privaten Feinabstimmung (bei ausgewählten Modellen) für Anleitungen oder Domainanpassungen unter Verwendung Ihrer eigenen Daten. Sie können das mitgelieferte Schulungsskript von SageMaker JumpStart an Ihre Bedürfnisse anpassen, oder Sie können Ihre eigenen Schulungsskripte für Open-Source-Modelle mitbringen und diese als Schulungsaufgabe von SageMaker einreichen. Wenn Sie das Modell weiter vorab trainieren müssen (in der Regel bei Open-Source-Modellen), können Sie die verteilten Schulungsbibliotheken von SageMaker nutzen, um alle GPUs einer ML-Instance zu beschleunigen und effizient zu nutzen.
Darüber hinaus können Sie auch eine vollständig verwaltete Datengenerierung, Datenannotierungsdienste und Modellentwicklung mit der Technik Reinforced Learning from Human Feedback unter Verwendung von Amazon SageMaker Ground Truth Plus in Betracht ziehen.
Ein Beispiel für eine Architektur
Wie sehen also all diese Komponenten aus, wenn ein generativer KI-Anwendungsfall realisiert wird? Zwar hat jedes Startup einen anderen Anwendungsfall und einzigartige Ansätze zur Lösung realer Probleme, aber ein gemeinsames Thema oder Ausgangspunkt, den ich bei der Entwicklung generativer KI-Anwendungen gesehen habe, ist der Ansatz der generativen Generierung durch Retrieval Augmented. Nach dem Einfügen all der oben beschriebenen AWS-Services sieht die Architektur wie folgt aus:
Ingestion-Pipeline – Die Domain-spezifischen oder proprietären Daten werden als Textdaten vorverarbeitet. Sie werden entweder stapelweise verarbeitet (in Amazon S3 gespeichert) oder gestreamt (mit Amazon Kinesis), wenn sie während des Einbettungsprozesses erstellt oder aktualisiert werden, und in einer dichten Vektordarstellung gespeichert.

Pipeline zum Abrufen – Wenn ein Benutzer die in Vektordarstellung gespeicherten proprietären Daten abfragt, ruft er die zugehörigen Dokumente mithilfe von k Nearest Neighbor (kNN) oder semantischer Suche ab. Es wird dann wieder in Klartext dekodiert. Die Ausgabe dient als reichhaltiger und dichter Kontext für die Eingabeaufforderung.

Pipeline zur Generierung von Zusammenfassungen – Der Kontext wird der Aufforderung mit der ursprünglichen Benutzerabfrage hinzugefügt, um einen Einblick oder eine Zusammenfassung aus dem abgerufenen Dokument zu erhalten.

All diese Ebenen können mit wenigen Codezeilen mithilfe von Entwicklertools wie LangChain erstellt werden.
Fazit
Dies ist eine Möglichkeit, mithilfe von AWS-Services eine generative End-to-End-KI-Anwendung zu erstellen. Die AWS-Services, die Sie auswählen, variieren je nach Anwendungsfall oder Anpassungsansatz. Bleiben Sie auf dem Laufenden über die neuesten AWS-Versionen, Lösungen und Blogs zum Thema generative KI, indem Sie diesen Link mit einem Lesezeichen versehen.
Lassen Sie uns generative KI-Anwendungen auf AWS erstellen! Starten Sie Ihre Reise mit generativer KI mit AWS Activate, einem kostenlosen Programm, das speziell für Startups und Unternehmer in der Anfangsphase entwickelt wurde und die Ressourcen bietet, die Sie für den Einstieg in AWS benötigen.

Hrushikesh Gangur
Hrushikesh Gangur ist Principal Solutions Architect für KI/ML-Startups mit Fachkenntnissen sowohl in den Bereichen Machine Learning als auch in Netzwerkservices von AWS. Er hilft Startups beim Aufbau von Plattformen für generative KI, autonome Fahrzeuge und Machine Learning, damit sie ihr Geschäft effizient und effektiv in AWS betreiben können.
Wie war dieser Inhalt?