Come ti è sembrato il contenuto?
- Scopri
- Creazione di applicazioni di IA generativa per la tua startup
Creazione di applicazioni di IA generativa per la tua startup
I recenti progressi dell'IA generativa stanno innalzando il livello degli strumenti che possono aiutare le startup a costruire, scalare e innovare rapidamente. Questa diffusa adozione e democratizzazione del machine learning (ML), in particolare con l' architettura di rete neurale Transformer, rappresenta un punto di svolta entusiasmante nella tecnologia. Con gli strumenti giusti, le startup possono sviluppare nuove idee o trasformare il prodotto esistente per sfruttare i vantaggi dell'IA generativa per i propri clienti.
Sei pronto a creare un'applicazione di IA generativa per la tua startup? Esaminiamo innanzitutto i concetti, le idee fondamentali e gli approcci comuni per creare applicazioni di IA generativa.
Cosa sono le applicazioni di IA generativa?
Le applicazioni di IA generativa sono programmi basati su un tipo di intelligenza artificiale in grado di creare nuovi contenuti e idee, tra cui conversazioni, storie, immagini, video, codice e musica. Come tutte le applicazioni di intelligenza artificiale, le applicazioni di IA generativa sono alimentate da modelli ML pre-addestrati su grandi quantità di dati e comunemente denominati modelli di fondazione (FM).
Un esempio di applicazione di IA generativa è Amazon CodeWhisperer, uno strumento di programmazione IA complementare che aiuta gli sviluppatori a creare applicazioni in modo più rapido e sicuro fornendo suggerimenti di codice per linee complete e funzionanti nel tuo ambiente di sviluppo integrato (IDE). CodeWhisperer è addestrato su miliardi di righe di codice ed è in grado di generare istantaneamente suggerimenti di codice che vanno da frammenti a funzioni complete, in base ai commenti e al codice esistente. Le startup possono utilizzare i crediti AWS Activate con CodeWhisperer livello professionale o iniziare con il livello individuale, che è gratuito.
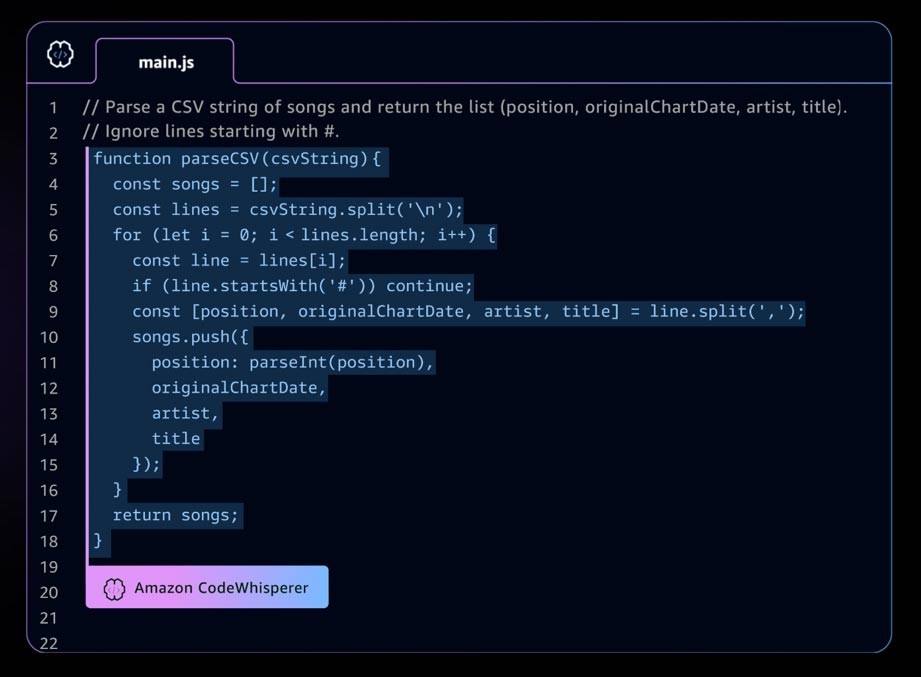
Il panorama dell'IA generativa è in rapido sviluppo
C'è una rapida crescita nelle startup di IA generativa e anche all'interno delle startup che creano strumenti per semplificare l'adozione dell'IA generativa. Strumenti come LangChain, un framework open source per lo sviluppo di applicazioni basate su modelli linguistici, stanno rendendo l'IA generativa più accessibile a una gamma più ampia di organizzazioni, il che porterà a un'adozione più rapida. Questi strumenti includono anche la progettazione dei prompt, i servizi di potenziamento (come strumenti di incorporamento o database vettoriali), il monitoraggio dei modelli, la misurazione della qualità dei modelli, i guardrail, l'annotazione dei dati, l'apprendimento rafforzato dal feedback umano (RLHF) e molti altri.
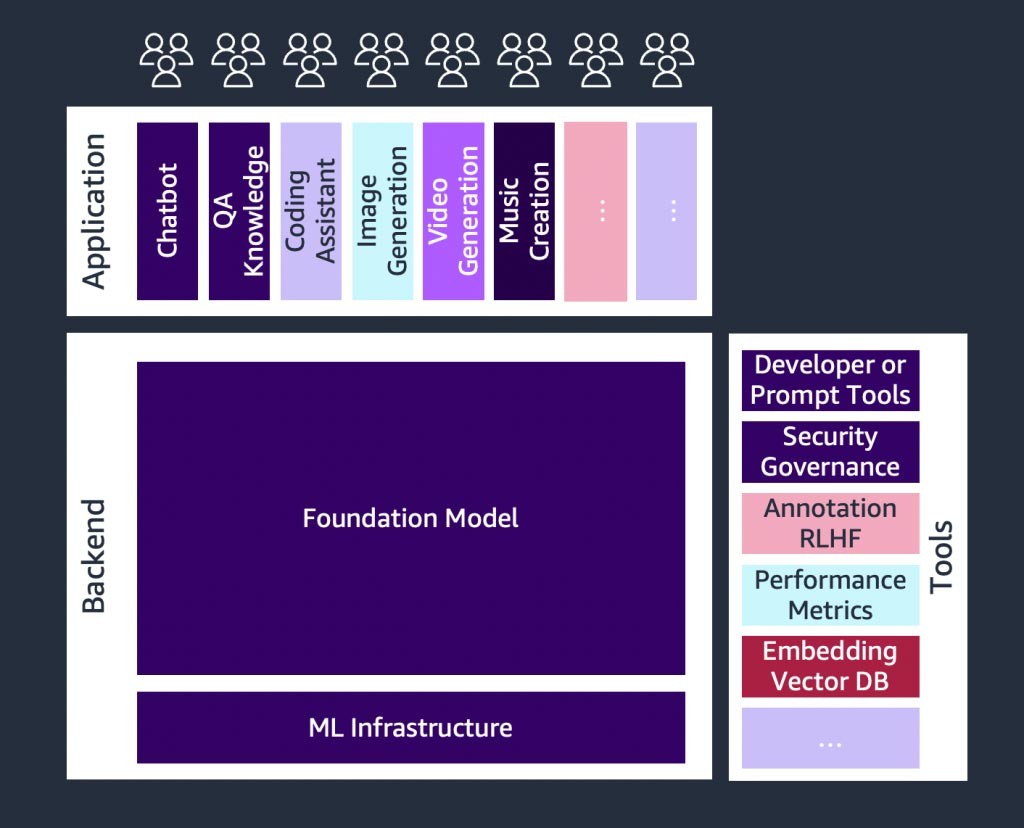
Un'introduzione ai modelli di fondazione
Per un'applicazione o uno strumento di IA generativa, al centro c'è il modello di fondazione. I modelli di fondazione sono una classe di potenti modelli di machine learning che si differenziano per la loro capacità di essere pre-addestrati su grandi quantità di dati per eseguire un'ampia gamma di attività a valle. Queste attività includono la generazione di testo, il riepilogo, l'estrazione di informazioni, le domande e risposte e/o i chatbot. Al contrario, i modelli ML tradizionali vengono addestrati a eseguire un'attività specifica da un set di dati.
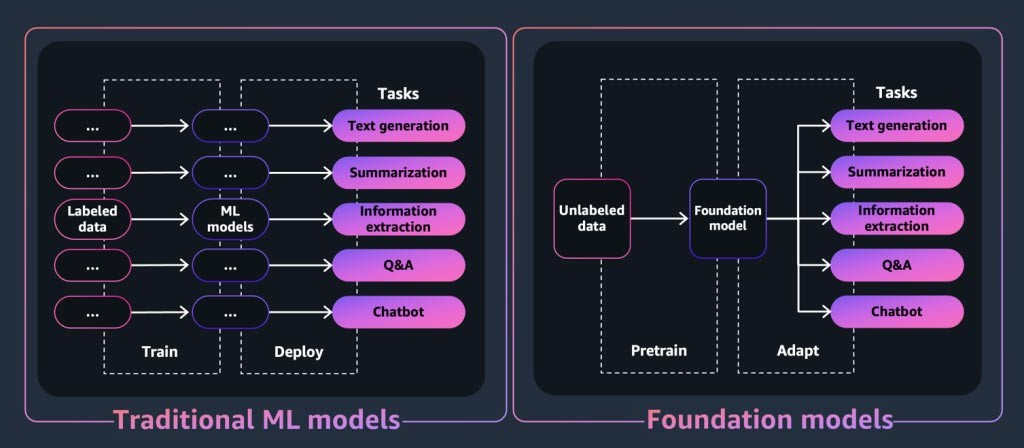
Quindi, come fa un modello di fondazione a "generare" l'output per cui sono note le applicazioni di IA generativa? Queste funzionalità derivano da modelli e relazioni di apprendimento che consentono al modello di fondazione di prevedere l'elemento o gli elementi successivi in una sequenza o di generarne uno nuovo:
- Nei modelli di generazione di testo, i modelli di fondazione emettono la parola successiva, la frase successiva o la risposta a una domanda.
- Per i modelli di generazione di immagini, i modelli di fondazione emettono un'immagine basata sul testo.
- Quando un'immagine è un input, i modelli di fondazione emettono l'immagine, l'animazione o le immagini 3D successive pertinenti o ingrandite.
In ogni caso, il modello inizia con un vettore seed derivato da un prompt: i prompt descrivono l'attività che il modello deve eseguire. La qualità e il dettaglio (noti anche come contesto) del prompt determinano la qualità e la pertinenza dell'output.
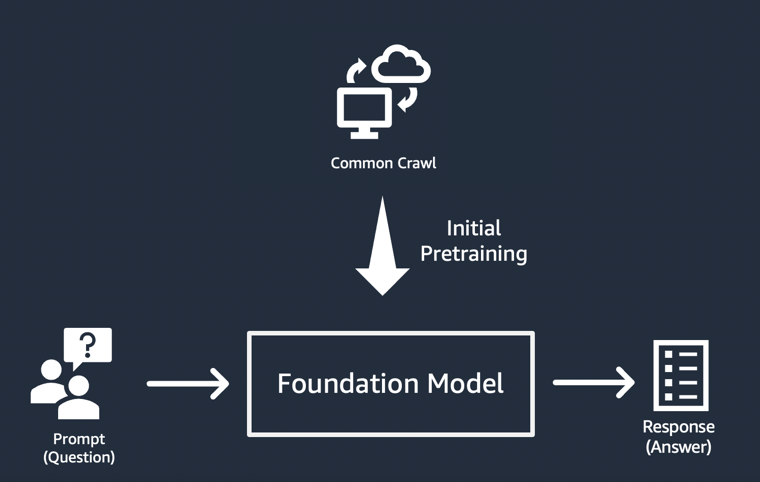
L'implementazione più semplice di applicazioni di IA generativa
L'approccio più semplice per creare un'applicazione di IA generativa consiste nell'utilizzare un modello di fondazione ottimizzato per le istruzioni e fornire un prompt significativo (progettazione dei prompt) utilizzando l'apprendimento zero-shot o l'apprendimento few-shot. Un modello ottimizzato per le istruzioni (come FLAN T5 XXL, Open-Llama o Falcon 40B Instruct) sfrutta la comprensione delle attività o dei concetti correlati per generare previsioni in base ai prompt. Ecco alcuni esempi rapidi:
Apprendimento zero-shot
Titolo: \"L'università ha una nuova struttura in arrivo"\\n Dato il titolo di un articolo immaginario sopra riportato, immagina l'articolo.\n
Apprendimento few+shot
Ma è fantastico! // Positivo
Ma che brutto! // Negativo
Quel film era terribile! // Negativo
Che spettacolo orribile! //
RISPOSTA: Negativa
Le startup, in particolare, possono trarre vantaggio dalla rapida implementazione, dal fabbisogno minimo di dati e dall'ottimizzazione dei costi derivanti dall'utilizzo di un modello ottimizzato per le istruzioni.
Per ulteriori informazioni sulle considerazioni relative alla scelta di un modello di fondazione, consulta Scelta del modello di fondazione corretto per la tua startup.
Personalizzazione dei modelli di fondazione
Non tutti i casi d'uso possono essere soddisfatti utilizzando la progettazione dei prompt su modelli ottimizzati per le istruzioni. I motivi per personalizzare un modello di fondazione per la propria startup possono includere:
- Aggiunta di un'attività specifica (come la generazione di codice) al modello di fondazione
- Generazione di risposte basate sul set di dati proprietario dell'azienda
- Ricerca di risposte generate da set di dati di qualità superiore rispetto a quelli che hanno pre-addestrato il modello
- Ridurre le "allucinazioni", ovvero risultati che non sono di fatto corretti o ragionevoli
Esistono tre tecniche comuni per personalizzare un modello di fondazione.
Ottimizzazione basata su istruzioni
Questa tecnica prevede l'addestramento del modello di fondazione per completare un'attività specifica sulla base di un set di dati etichettato specifico per l'attività. Un set di dati etichettato è costituito da coppie di richieste e risposte. Questa tecnica di personalizzazione è utile per le startup che desiderano personalizzare la propria FM in modo rapido e con un set di dati minimo: l’addestramento richiede meno set di dati e passaggi. I pesi del modello vengono aggiornati in base all'attività o al livello che state perfezionando.
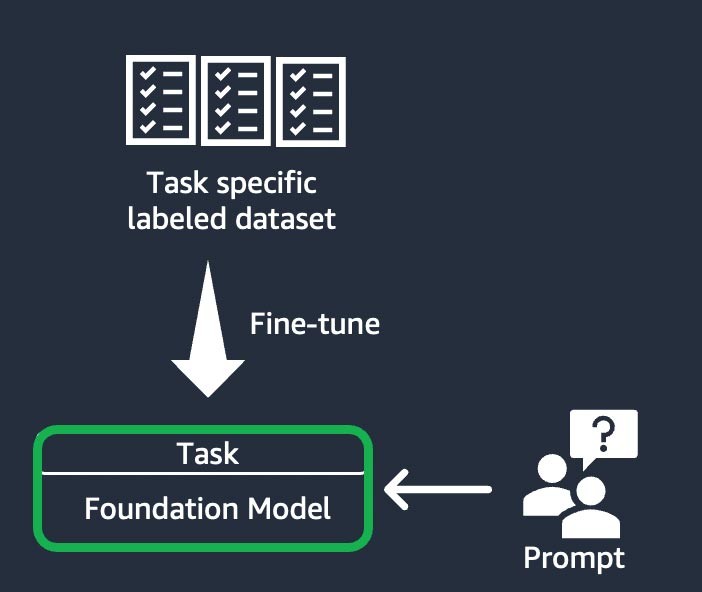
Adattamento al dominio (noto anche come "ulteriore addestramento preliminare")
Questa tecnica prevede l'addestramento del modello di fondazione utilizzando un ‘corpus’ (ovvero un insieme di materiali di addestramento) di dati non etichettati specifici del dominio (noto come apprendimento con supervisione autonoma). Questa tecnica si avvantaggia di casi d'uso che includono dati statistici e gergali specifici del dominio che il modello di fondazione esistente non aveva mai visto prima. Ad esempio, le startup che creano un'applicazione di IA generativa per lavorare con dati proprietari nel settore finanziario possono trarre vantaggio da un'ulteriore addestramento preliminare della FM sul vocabolario personalizzato e dalla "tokenizzazione", un processo di suddivisione del testo in unità più piccole chiamate token.
Per ottenere una qualità superiore, alcune startup implementano tecniche di apprendimento rafforzato dal feedback umano (RLHF) in questo processo. Inoltre, sarà necessaria una ottimizzazione basata su istruzioni per mettere a punto un'attività specifica. Si tratta di una tecnica costosa e dispendiosa in termini di tempo rispetto alle altre. I pesi del modello vengono aggiornati su tutti i livelli.
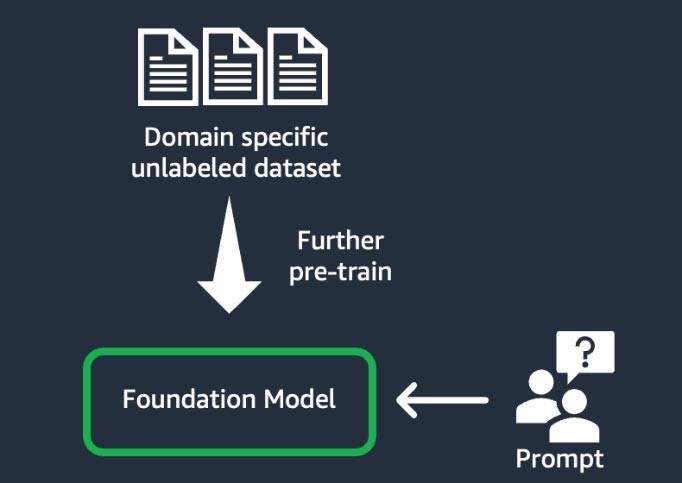
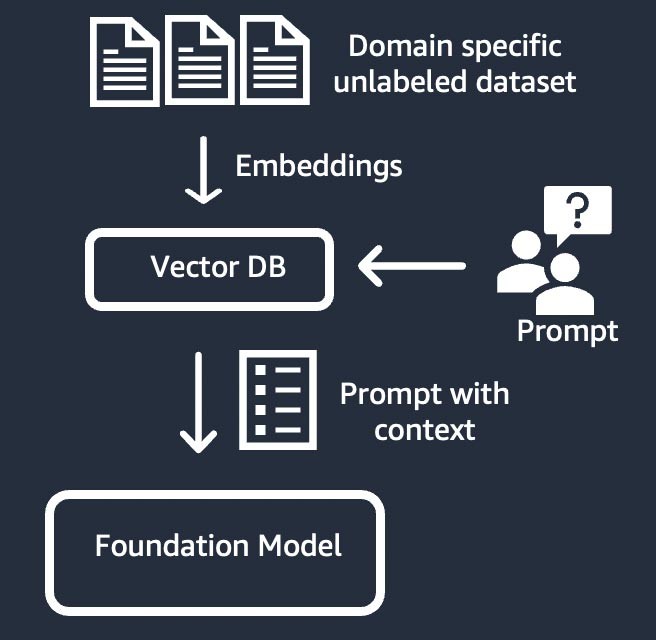
Recupero delle informazioni (noto anche come "retrieval-augmented generation" o "RAG")
Questa tecnica amplia il modello di fondazione con un sistema di recupero delle informazioni basato su una rappresentazione vettoriale densa. La conoscenza a dominio chiuso o i dati proprietari vengono sottoposti a un processo di incorporamento del testo per generare una rappresentazione vettoriale del corpus e vengono archiviati in un database vettoriale. Un risultato di ricerca semantico basato sulla query dell'utente diventa il contesto per il prompt. Il modello di fondazione viene utilizzato per generare una risposta basata sul prompt con contesto. In questa tecnica, il peso del modello di fondazione non viene aggiornato.
Componenti di un'applicazione di IA generativa
Nelle sezioni precedenti, abbiamo appreso vari approcci che le startup possono adottare con i modelli di fondazione quando creano applicazioni di IA generativa. Ora, esaminiamo in che modo questi modelli di fondazione fanno parte degli ‘ingredienti’ o dei componenti tipici necessari per creare un'applicazione di IA generativa.
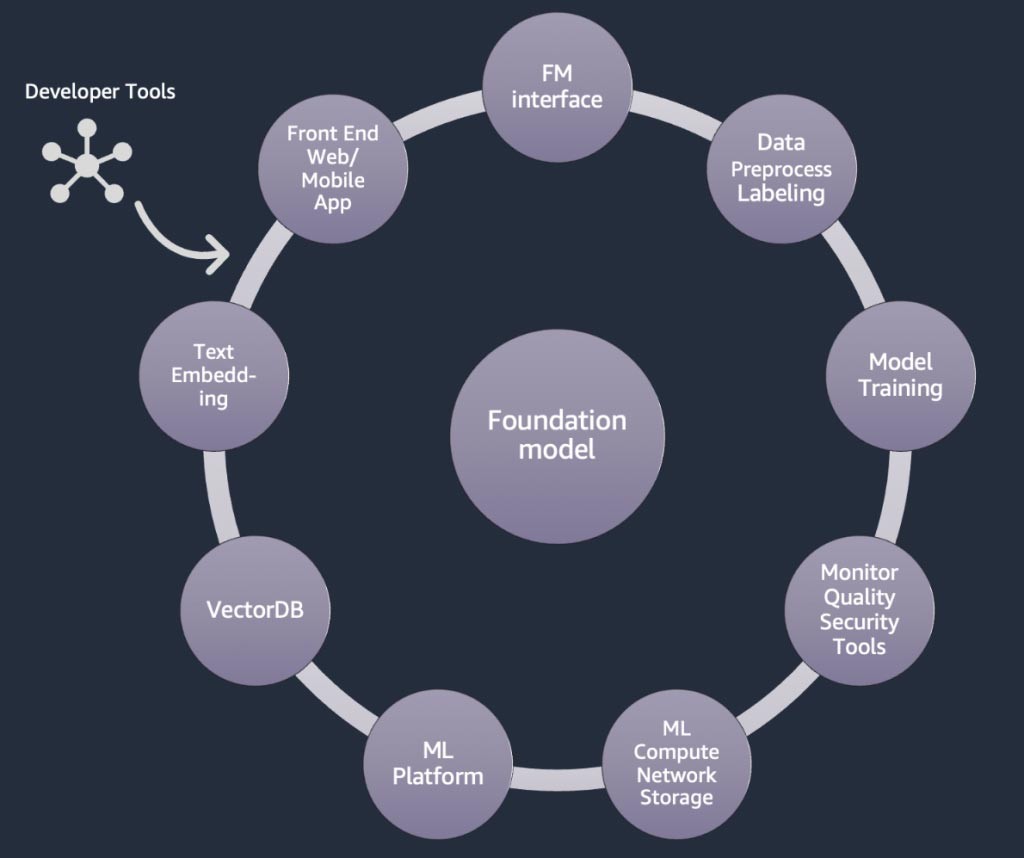
Al centro c'è un modello di fondazione. Nell'approccio più semplice discusso in precedenza in questo blog, ciò richiede un'applicazione Web o un'app per dispositivi mobili (in alto a sinistra) che acceda al modello di fondazione tramite un'API (in alto). Questa API è un servizio gestito tramite un provider di modelli o ospitato autonomamente utilizzando un modello open source o proprietario. Nel caso del self-hosting, potrebbe essere necessaria una piattaforma di machine learning supportata da istanze a calcolo accelerato per ospitare il modello.
Nella tecnica RAG, è necessario aggiungere un endpoint per l'incorporamento del testo e un database vettoriale (a sinistra e in basso a sinistra). Entrambi sono forniti come servizio API o ospitati autonomamente. L'endpoint di incorporamento del testo è supportato da un modello di fondazione e la scelta del modello di fondazione dipende dalla logica di incorporamento e dal supporto alla tokenizzazione. Tutti questi componenti sono collegati tra loro tramite strumenti di sviluppo che forniscono il framework per lo sviluppo di applicazioni di IA generativa.
Infine, quando si scelgono le tecniche di personalizzazione di messa a punto o ulteriore addestramento preliminare di un modello di fondazione (a destra), sono necessari componenti che aiutino con la pre-elaborazione e l'annotazione dei dati (in alto a destra) e una piattaforma ML (in basso) per eseguire il processo di addestramento su istanze a calcolo accelerato specifiche. Alcuni fornitori di modelli supportano l'ottimizzazione basata su API e, in questi casi, non è necessario preoccuparsi della piattaforma ML e dell'hardware sottostante.
Indipendentemente dall'approccio di personalizzazione, potresti anche voler integrare componenti che forniscono monitoraggio, parametri di qualità e strumenti di sicurezza (in basso a destra).
Quali servizi AWS devo usare per creare la mia applicazione di IA generativa?
Il diagramma seguente, Figura 9, mappa ogni componente ai servizi AWS corrispondenti. Tieni presente che si tratta di un set curato di servizi AWS da cui vedo le startup trarne vantaggio; tuttavia, sono disponibili altri servizi AWS.
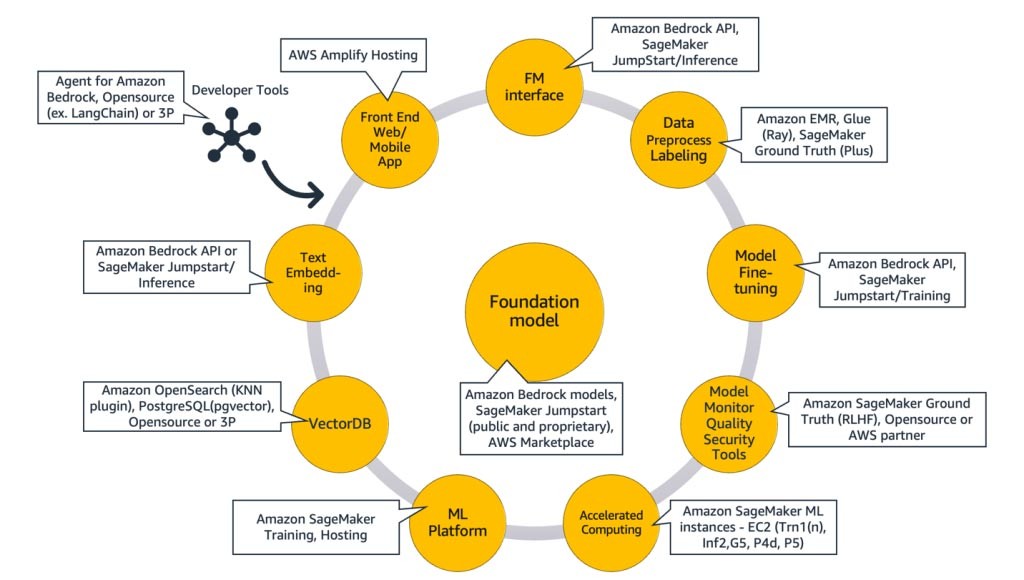
Per approfondire, inizierò con la mappatura dei servizi AWS sui componenti comuni di un'applicazione di IA generativa. Quindi spiegherò i servizi AWS che si associano ai componenti rimanenti nella Figura 9, in base agli approcci utilizzati per implementare l'applicazione.
Componenti comuni
I componenti comuni di un'applicazione di IA generativa sono il modello di fondazione (FM), la sua interfaccia e, facoltativamente, la piattaforma di machine learning (ML) e il calcolo accelerato. Questi possono essere ottenuti utilizzando le offerte gestite disponibili da AWS:
Amazon Bedrock (modello di fondazione e relativi componenti di interfaccia)
Amazon Bedrock, un servizio completamente gestito che rende disponibili tramite API modelli di fondazione delle principali startup di intelligenza artificiale (Jurassic di AI21, Claude di Anthropic, Command and Embedding di Cohere, modelli SDXL di Stability) e Amazon (modelli Titan Text and Embeddings), così puoi scegliere tra un'ampia gamma di FM per trovare il modello più adatto al tuo caso d'uso. Amazon Bedrock fornisce API o accesso serverless a una serie di modelli di fondazione per fornire tre funzionalità: incorporamento di testo, prompt/response e ottimizzazione (su modelli selezionati).
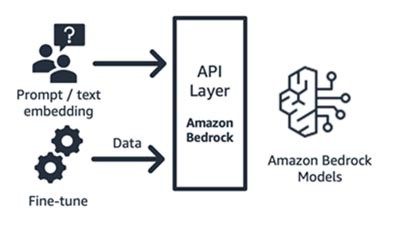
Amazon Bedrock è ideale per le startup di consumatori basate su applicazioni o modelli che stanno sviluppando servizi a valore aggiunto (progettazione dei prompt, generazione aumentata con recupero e altro ancora) sulla base di un modello di fondazione di loro scelta. Il suo modello di prezzo è basato sul pagamento per uso, in genere nell'unità di milioni di token elaborati. Amazon Bedrock è generalmente disponibile; tuttavia alcune delle funzionalità discusse in questo blog sono disponibili in anteprima privata. Scopri di più qui.
Amazon SageMaker JumpStart (modello di fondazione e relativi componenti di interfaccia)
AWS offre funzionalità di IA generativa ad Amazon SageMaker Jumpstart: un hub di modelli di fondazione che contiene modelli proprietari e disponibili pubblicamente, soluzioni di avvio rapido e notebook di esempio per distribuire e ottimizzare i modelli. Quando si distribuiscono questi modelli, si crea un endpoint di inferenza in tempo reale a cui è possibile accedere direttamente utilizzando l'SDK/API SageMaker. In alternativa, puoi utilizzare come front-end l'endpoint del modello base di SageMaker con AWS API Gateway e una logica di calcolo leggera in una funzione AWS Lambda . Puoi anche sfruttare alcuni di questi modelli per l'incorporamento del testo.
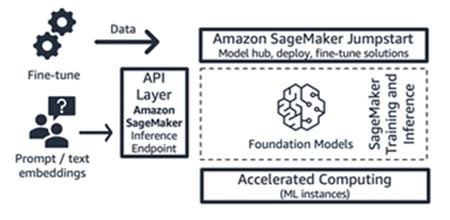
Sia l'endpoint di inferenza che i processi di addestramento di ottimizzazione vengono eseguiti su istanze ML gestite a scelta (consulta "Calcolo accelerato” nella Figura 9) utilizzando SageMaker come piattaforma ML (consulta "Piattaforma ML" nella Figura 9). SageMaker Jumpstart è ideale per le startup consumer basate su applicazioni o modelli che desiderano un maggiore controllo sulla propria infrastruttura e che dispongono di competenze e conoscenze di machine learning di livello moderato. Il suo modello di prezzo è basato sul pagamento in base all'uso, in genere nell'unità di ore di istanza. Tutti i modelli e le soluzioni di questa offerta sono generalmente disponibili.
Addestramento e inferenza di Amazon SageMaker (piattaforma ML)
Le startup possono sfruttare le funzionalità di addestramento e inferenza di Amazon SageMaker per funzionalità avanzate come addestramento distribuito, inferenza distribuita, endpoint multi-modello e altro ancora. Puoi importare i modelli di fondazione dall'hub di modelli che preferisci, che si tratti di SageMaker JumpStart o Hugging Face o Marketplace AWS, oppure puoi creare il tuo modello di fondazione da zero.
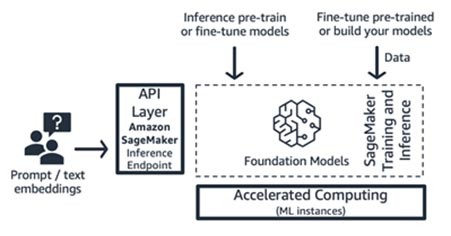
SageMaker è ideale per i costruttori di applicazioni di IA generativa complete (dai fornitori di modelli ai loro consumatori) o per i fornitori di modelli con team con competenze avanzate di machine learning e pre-elaborazione dei dati. SageMaker offre anche un modello di tariffazione basato sull'uso, in genere nell'unità di ore-istanza.
AWS Trainium e AWS Inferentia (calcolo accelerato)
Nell'aprile 2023, AWS ha annunciato la disponibilità generale delle istanze Amazon EC2 Trn1n con tecnologia AWS Trainium e delle istanze Amazon EC2 Inf2 con tecnologia AWS Inferentia2. Puoi sfruttare gli acceleratori AWS appositamente progettati (AWS Trainium e AWS Inferentia) utilizzando SageMaker come piattaforma ML.
Il test di benchmark per i carichi di lavoro di inferenza riporta che le istanze Inf2 offrono prestazioni con costi inferiori del 52% rispetto a un'istanza Amazon EC2 comparabile ottimizzata per l'inferenza. Suggerisco di tenere d'occhio i cicli di sviluppo rapidi di SDK AWS Neuron, in cui circa ogni mese AWS aggiunge una nuova architettura di modello nella propria matrice di supporto sia per l’addestramento che per l'inferenza.
Approcci per la creazione di applicazioni di IA generativa
Ora, esaminiamo ciascuno dei componenti nella Figura 9 dal punto di vista dell'implementazione.
L'approccio di inferenza didattica zero-shot o few-shot
Come accennato in precedenza, l'apprendimento zero-shot o few-shot è l'approccio più semplice per creare un'applicazione di IA generativa. Per creare applicazioni basate su questo approccio, tutto ciò di cui hai bisogno sono i servizi per i quattro componenti comuni (modello di fondazione, interfaccia, piattaforma ML e calcolo), il codice personalizzato per generare prompt e un'app Web/mobile front-end.
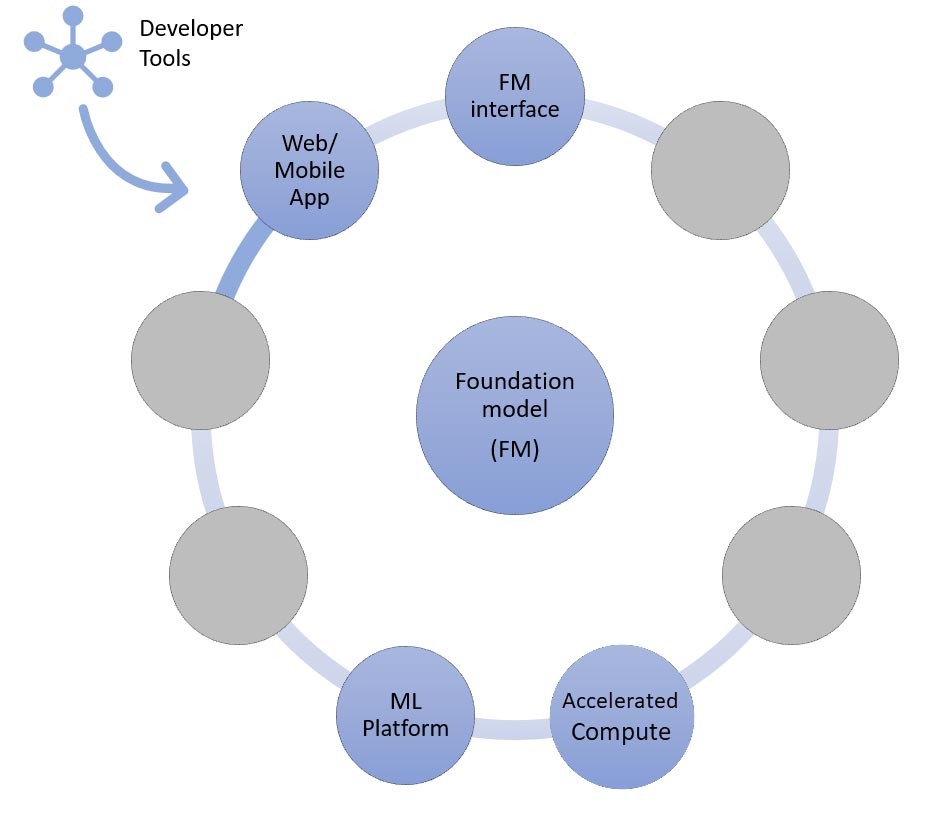
Per ulteriori informazioni sulla selezione di un modello di fondazione tramite Amazon Bedrock o Amazon SageMaker JumpStart, consulta le linee guida per la selezione del modello qui.
Il codice personalizzato può sfruttare strumenti di sviluppo come LangChain per modelli e generazione di prompt. La community LangChain ha già aggiunto il supporto per gli endpoint Amazon Bedrock, Gateway Amazon API e SageMaker. Ti ricordo che potresti anche sfruttare AWS Amazon CodeWhisperer, uno strumento di codifica complementare, per migliorare l'efficienza degli sviluppatori.
Le startup che creano un'app Web front-end o un'app mobile possono facilmente avviare e scalare utilizzando AWS Amplify e ospitare queste app Web in modo rapido, sicuro e affidabile utilizzando Hosting AWS Amplify.
Dai un'occhiata a questo esempio di apprendimento zero-shot sviluppato con SageMaker Jumpstart.
L'approccio al recupero delle informazioni
Come accennato, uno dei modi in cui una startup può personalizzare i modelli di fondazione è attraverso l'aumento con un sistema di recupero delle informazioni, più comunemente noto come Retrieval-Augmented Generation (RAG). Questo approccio coinvolge tutti i componenti menzionati nell'apprendimento zero-shot e few-shot, oltre al database degli endpoint e vettoriale che incorporano testo.
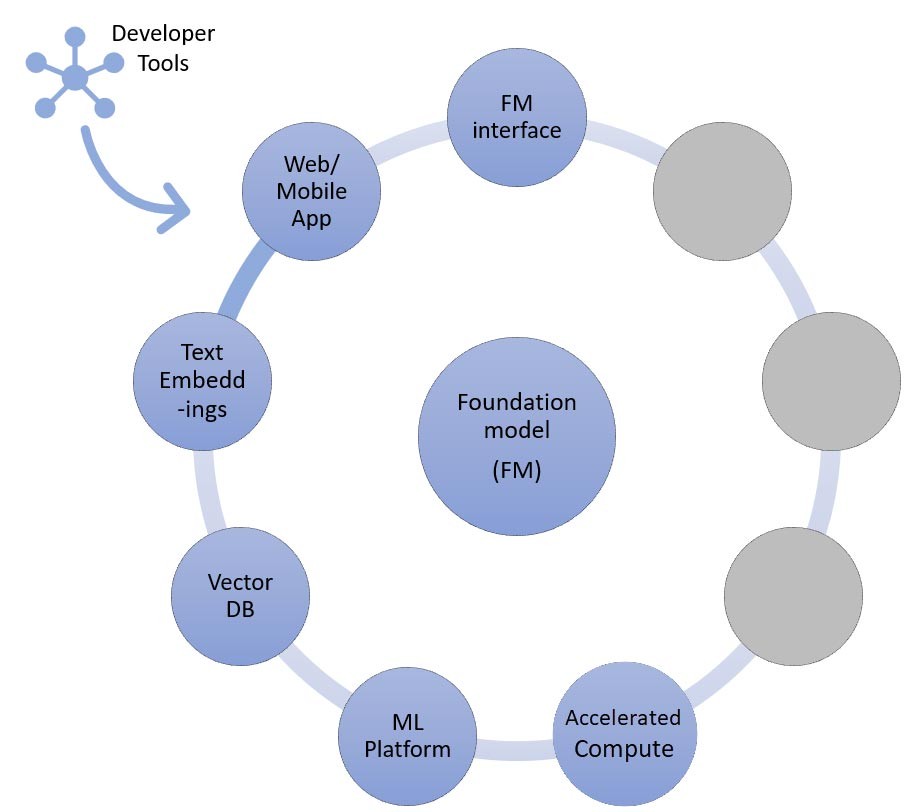
Le opzioni per l'endpoint degli incorporamenti di testo variano a seconda del servizio gestito AWS selezionato:
- Amazon Bedrock offre un modello linguistico di grandi dimensioni (LLM) per gli incorporamenti che traduce gli input di testo tra cui parole, frasi e grandi unità di testo in rappresentazioni numeriche (note come incorporamenti) che contengono il significato semantico del testo.
- Se utilizzi SageMaker JumpStart, puoi ospitare un modello di incorporamento come GPT-J 6B o qualsiasi altro LLM a tua scelta dall'hub del modello. L'endpoint SageMaker può essere richiamato dall’SDK SageMaker o Boto3 per tradurre gli input di testo in incorporamenti.
Gli incorporamenti possono quindi essere archiviati in un datastore vettoriale per eseguire ricerche semantiche utilizzando l'estensione pgvector di Amazon RDS per PostgreSQL o il plug-in k-NN del servizio OpenSearch di Amazon . Le startup preferiscono l'uno o l'altro in base al servizio che in genere utilizzano più a loro agio. In alcuni casi, le startup utilizzano database vettoriali nativi basati sull'intelligenza artificiale dei partner AWS o open source. Per indicazioni sulla selezione dei datastore vettoriali, fai riferimento a Il ruolo dei datastore vettoriali nelle applicazioni di IA generativa.
Anche in questo approccio, gli strumenti di sviluppo svolgono un ruolo fondamentale. Forniscono un semplice framework plug-n-play, modelli di prompt e un ampio supporto per le integrazioni.
In futuro, potrai anche sfruttare gli agenti per Amazon Bedrock, una nuova funzionalità per gli sviluppatori in grado di gestire le chiamate API ai tuoi sistemi aziendali.
Dai un'occhiata a questo esempio di utilizzo della generazione aumentata di recupero con modelli di fondazione in Amazon SageMaker Jumpstart.
L’approccio di ottimizzazione o ulteriore pre-addestramento
Ora, associamo i componenti ai servizi AWS necessari per l'ultimo approccio all'implementazione di un'applicazione di IA generativa: l’ottimizzazione o l’ulteriore pre-addestramento di un modello di fondazione. Questo approccio coinvolge tutti i componenti discussi nell'apprendimento zero-shot o few-shot, oltre alla pre-elaborazione dei dati e all’addestramento dei modelli.
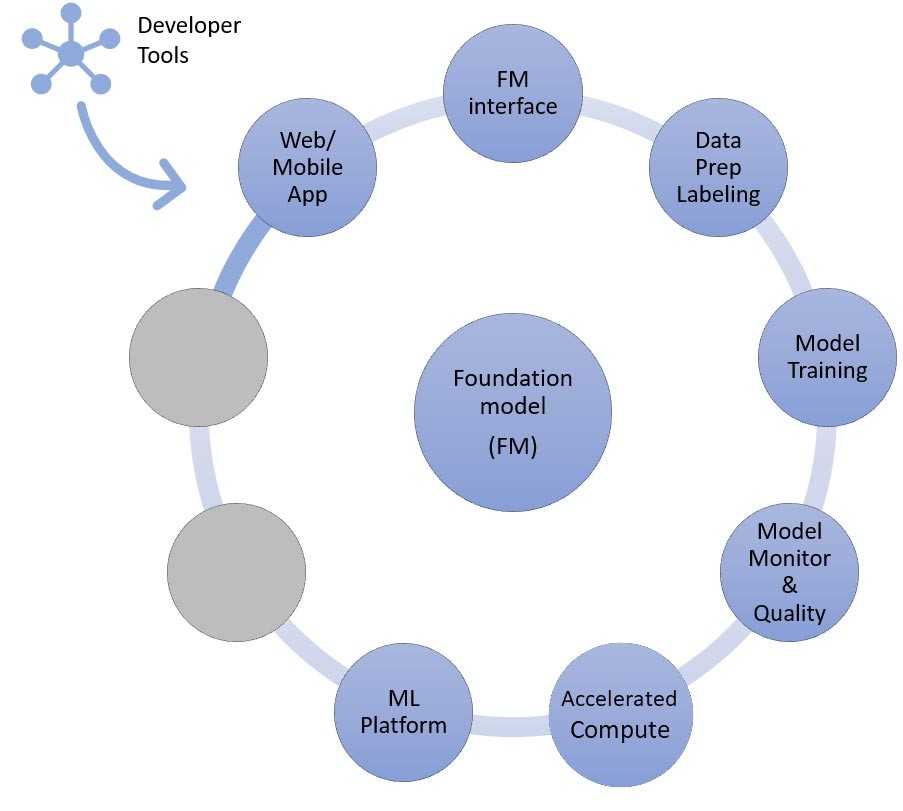
La preparazione dei dati (a volte chiamata pre-elaborazione o annotazione) è particolarmente importante durante l’ottimizzazione, in cui sono necessari set di dati più piccoli ed etichettati. Le startup possono iniziare facilmente a usare Amazon SageMaker Data Wrangler. Questo servizio aiuta a ridurre il tempo necessario per aggregare e preparare dati tabulari e di immagini per il machine learning da settimane a minuti. È inoltre possibile sfruttare la funzionalità di pipeline di inferenza di questo servizio per concatenare il flusso di lavoro di pre-elaborazione all’addestramento o all’ottimizzazione.
Se la tua startup deve pre-elaborare un enorme corpus di set di dati non strutturati e senza etichetta nel tuo data lake su Amazon S3, hai le seguenti opzioni:
- Se utilizzi Python e le librerie Python più diffuse, è utile sfruttare AWS Glue per Ray. AWS Glue utilizza Ray, un framework di elaborazione unificato open source utilizzato per scalare i carichi di lavoro Python
- In alternativa, Amazon EMR può aiutare a elaborare grandi quantità di dati utilizzando strumenti open source come Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi e Presto.
Per la componente di addestramento dei modelli di questo approccio, Amazon Bedrock ti consente di personalizzare privatamente i modelli di fondazione con i tuoi dati. Gestisce i modelli di fondazione su larga scala senza dover gestire alcuna infrastruttura (questo è il metodo di ottimizzazione delle API). In alternativa, l'approccio di SageMaker Jumpstart offre una soluzione rapida per ottimizzare privatamente (su modelli selezionati) le istruzioni o l’ adattamento del dominio utilizzando i propri dati. È possibile modificare lo script di addestramento in bundle di SageMaker JumpStart in base alle proprie esigenze, oppure aggiungere i propri script di addestramento per modelli open source e inviarli come lavoro di addestramento di SageMaker. Se è necessario pre-addestrare ulteriormente il modello (in genere per modelli open source), è possibile sfruttare le librerie di addestramento distribuito di SageMaker per velocizzare e utilizzare in modo efficiente tutte le GPU di un'istanza ML.
Inoltre, puoi prendere in considerazione la generazione di dati, i servizi di annotazione dei dati e lo sviluppo di modelli completamente gestiti con la tecnica Reinforced Learning from Human Feedback utilizzando Amazon SageMaker Ground Truth Plus.
Un esempio di architettura
Quindi, come appaiono tutti questi componenti quando si realizza un caso d'uso dell'IA generativa? Sebbene ogni startup abbia un caso d'uso diverso e approcci unici per risolvere i problemi del mondo reale, un tema o un punto di partenza comune che ho riscontrato nella creazione di applicazioni di IA generativa è l'approccio della generazione aumentata con recupero. Dopo aver collegato tutti i servizi AWS sopra descritti, l'architettura si presenta così:
Pipeline di inserimento : i dati proprietari o specifici del dominio vengono pre-elaborati come dati di testo. Vengono elaborati in batch (archiviati in Amazon S3) o trasmessi in streaming (utilizzando Amazon Kinesis) man mano che vengono creati o aggiornati tramite il processo di incorporamento e archiviati in una rappresentazione vettoriale densa.

Pipeline di recupero : quando un utente interroga i dati proprietari memorizzati nella rappresentazione vettoriale, recupera i documenti correlati utilizzando k nearest neighbor (kNN) o la ricerca semantica. Viene quindi decodificato nuovamente in testo non crittografato. L'output funge da contesto ricco e denso per il prompt.

Pipeline di generazione del riepilogo : il contesto viene aggiunto al prompt con la query originale dell'utente per ottenere informazioni o riepiloghi dal documento recuperato.

Tutti questi livelli possono essere creati con poche righe di codice utilizzando strumenti di sviluppo come LangChain.
Conclusioni
Questo è un modo per creare un'applicazione di IA generativa end-to-end utilizzando i servizi AWS. I servizi AWS selezionati varieranno in base al caso d'uso o all'approccio di personalizzazione adottato. Resta aggiornato sulle ultime versioni, soluzioni e blog di AWS in materia di IA generativa aggiungendo questo link
Iniziamo a creare applicazioni di IA generativa su AWS. Comincia il tuo percorso verso l'IA generativa con AWS Activate, un programma gratuito progettato specificamente per le startup e gli imprenditori in fase iniziale che offre le risorse necessarie per iniziare a usare AWS.

Hrushikesh Gangur
Hrushikesh Gangur è un Principal Solutions Architect per startup nel campo dell'IA/ML con esperienza sia nel machine learning che nei servizi di rete AWS. Aiuta le startup che sviluppano IA generativa, veicoli a guida autonoma e piattaforme di ML a gestire la loro attività su AWS in modo efficiente ed efficace.
Come ti è sembrato il contenuto?