Makine Öğreniminde Katıştırma nedir?
Makine öğreniminde yerleştirmeler nedir?
Gömülemeler, makine öğrenimi (ML) ve yapay zeka (AI) sistemlerinin insanlar gibi karmaşık bilgi alanlarını anlamak için kullandığı gerçek dünya nesnelerinin sayısal temsilleridir. Örneğin, hesaplama algoritmaları, 2 ile 3 arasındaki farkın 1 olduğunu ve 2 veya 100'e kıyasla 2 ile 3 arasında yakın bir ilişki olduğunu gösterir. Bununla birlikte, gerçek dünya verileri daha karmaşık ilişkiler içerir. Örneğin, bir kuş yuvası ve bir aslan yuvası benzerken gündüz-gece ise zıt terimlerdir. Gömmeler gerçek dünyadaki nesneleri, gerçek dünya verileri arasındaki doğal özellikleri ve ilişkileri yakalayan, karmaşık matematiksel temsillere dönüştürür. Tüm süreç otomatiktir, yapay zeka sistemleri eğitim sırasında kendi kendine yerleştirmeler oluşturur ve bunları yeni görevleri tamamlamak için gerektiği şekilde kullanır.
Gömmeler neden önemlidir?
Gömmeler, derin öğrenme modellerinin gerçek dünya veri etki alanlarını daha etkili bir şekilde anlamasını sağlar. Semantik ve söz dizimsel ilişkileri korurken gerçek dünya verilerinin temsilini basitleştirirler. Bu, makine öğrenimi algoritmalarının karmaşık veri türlerini ayıklayıp işlemesine ve yenilikçi yapay zeka uygulamalarını etkinleştirmesine olanak tanır. Aşağıdaki bölümlerde bazı önemli faktörler açıklanmaktadır.
Veri boyutluluğunu azaltma
Veri bilimcileri, düşük boyutlu bir alanda yüksek boyutlu verileri temsil etmek için gömmeleri kullanır. Veri biliminde boyut terimi, tipik olarak verilerin bir özelliğini veya niteliğini ifade eder. Yapay zekadaki daha yüksek boyutlu veriler, her veri noktasını tanımlayan birçok özelliğe veya özniteliğe sahip veri kümelerini ifade eder. Bu onlarca, yüzlerce hatta binlerce boyut anlamına gelebilir. Örneğin, her piksel renk değeri ayrı bir boyut olduğundan bir görüntü yüksek boyutlu veri olarak kabul edilebilir.
Yüksek boyutlu verilerle sunulduğunda derin öğrenme modelleri doğru bir şekilde öğrenmek, analiz etmek ve çıkarım yapmak için daha fazla hesaplama gücü ve zaman gerektirir. Gömmeler, çeşitli özellikler arasındaki ortak noktaları ve kalıpları belirleyerek boyut sayısını azaltır. Sonuç olarak bu, ham verileri işlemek için gereken bilgi işlem kaynaklarını ve süresini azaltır.
Büyük dil modellerini eğitme
Yerleştirmeler, büyük dil modellerini (LLM'ler) eğitirken veri kalitesini iyileştirir. Örneğin veri bilimcileri, eğitim verilerini model öğrenmeyi etkileyen düzensizliklerden arındırmak için gömmeleri kullanır. Aynı zamanda ML mühendisleri, altyapı modelini yeni veri kümeleriyle iyileştirmeyi gerektiren aktarım öğrenimi için yeni gömmeler ekleyerek önceden eğitilmiş modelleri yeniden kullanabilir. Mühendisler gömmelerle gerçek dünyadan özel veri kümeleri için bir modele ince ayar yapabilir.
Yenilikçi uygulamalar oluşturma
Yerleştirmeler, yeni derin öğrenme ve üretken yapay zeka (üretken AI) uygulamalarını mümkün kılar. Sinir ağı mimarisinde uygulanan farklı gömme teknikleri, doğru AI modellerinin çeşitli alanlarda ve uygulamalarda geliştirilmesine, eğitilmesine ve dağıtılmasına olanak tanır. Örneğin:
- Mühendisler görüntü gömmeleriyle nesne algılama, görüntü tanıma ve görselle ilgili diğer görevler için yüksek hassasiyetli bilgisayarlı görü uygulamaları oluşturabilirler.
- Kelime gömmeleriyle doğal dil işleme yazılımı, kelimelerin bağlamını ve ilişkilerini daha doğru bir şekilde anlayabilir.
- Grafik gömmeleri, ağ analizini desteklemek için birbirine bağlı düğümlerden ilgili bilgileri çıkarır ve kategorilere ayırır.
Bilgisayar görme modelleri, AI sohbet robotları ve AI tavsiye sistemlerinin tümü, insan zekasını taklit eden karmaşık görevleri tamamlamak için gömülü kullanır.
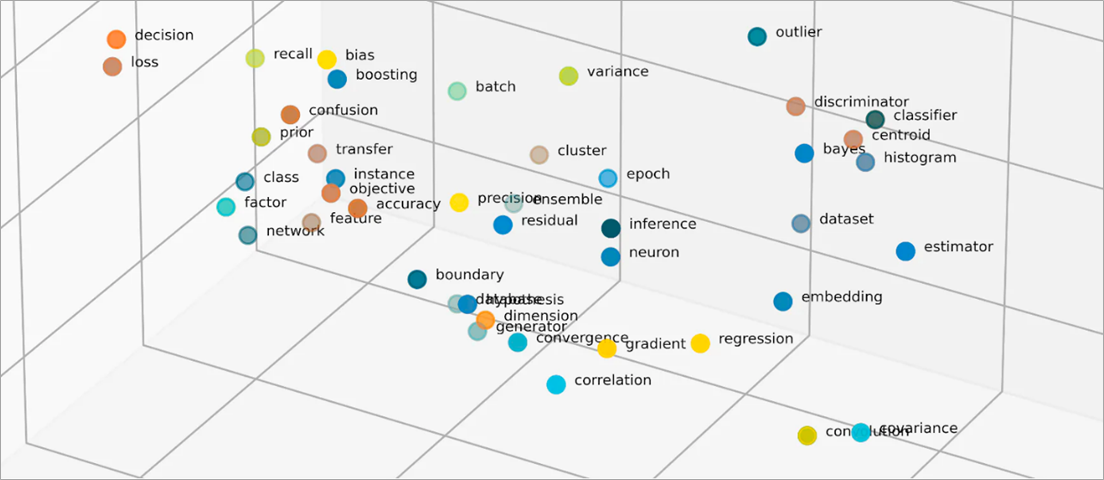
Gömmelerdeki vektörler nelerdir?
ML modelleri bilgileri ham biçimlerinde anlaşılır bir şekilde yorumlayamaz ve girdi olarak sayısal veri gerektirir. Gerçek kelime bilgilerini vektör adı verilen sayısal temsillere dönüştürmek için sinir ağı gömmeleri kullanırlar. Vektörler, çok boyutlu bir alanda bilgi temsil eden sayısal değerlerdir. ML modellerinin seyrek dağıtılmış ögeler arasında benzerlikler bulmasına yardımcı olurlar.
Bir ML modelinin öğrendiği her nesnenin çeşitli nitellikleri veya özellikleri vardır. Basit bir örnek olarak, aşağıdaki filmleri ve TV şovlarına göz atın. Her biri janr, tür ve çıkış yılı ile karakterize edilir.
The Conference (Korku, 2023, Film)
Upload (Komedi, 2023, TV Şovu, 3 Sezon)
Tales from the Crypt (Korku, 1989, TV Şovu, 7 Sezon)
Dream Scenario (Korku-Komedi, 2023, Film)
ML modelleri, yıl gibi sayısal değişkenleri yorumlayabilse de janr, tür, bölüm ve toplam sezon gibi sayısal olmayan değişkenleri karşılaştıramaz. Gömme vektörleri, sayısal olmayan verileri ML modellerinin anlayabileceği ve ilişkilendirebileceği bir dizi değere kodlar. Örneğin, aşağıdakiler daha önce listelenen TV programlarının varsayımsal bir temsilidir.
The Conference (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
Vektördeki ilk sayı, belirli bir türe karşılık gelir. Bir ML modeli, The Conference ve Tales from the Crypt'in aynı janr olduğunu görecektir. Benzer şekilde model; biçim, sezon ve bölümleri temsil eden üçüncü sayıya dayalı olarak Upload ve Tales from the Crypt arasında daha fazla yakınlık bulacaktır. Daha fazla değişken tanıtıldıkça daha küçük bir vektör alanında daha fazla bilgi yoğunlaştırmak için modeli hassaslaştırabilirsiniz.
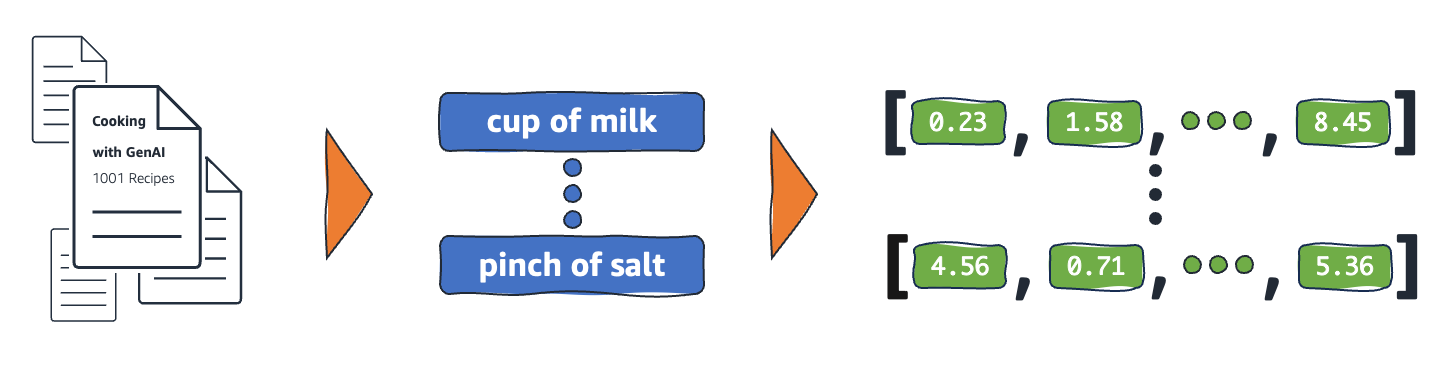
Gömme işlemleri nasıl çalışır?
Gömmeler, ham verileri ML modellerinin yorumlayabileceği sürekli değerlere dönüştürür. Geleneksel olarak ML modelleri, kategorik değişkenleri öğrenebilecekleri formlara eşlemek için one-hot encoding kullanır. Kodlama yöntemi, her kategoriyi satırlara ve sütunlara böler ve ikili değerler atar. Aşağıdaki ürün kategorileri ve fiyatlarına göz atın.
|
Meyveler |
Fiyat |
|
Apple |
5,00 |
|
Portakal |
7,00 |
|
Havuç |
10,00 |
Değerlerin one-hot encoding ile temsil edilmesi aşağıdaki tabloda sonuçlanır.
|
Apple |
Portakal |
Armut |
Fiyat |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
Tablo matematiksel olarak [1,0,0,5.00], [0,1,0,7.00] ve [0,0,1,10.00] vektörleri şeklinde temsil edilir.
One-hot encoding, modellerin farklı nesneleri ilişkilendirmesine yardımcı olan bilgi sağlama ile 0 ve 1 boyutsal değerlerini genişletir. Örneğin, model meyve olmasına rağmen elma ve portakal arasında benzerlikler bulamaz, portakal ve havucu meyve ve sebze olarak ayırt edemez. Listeye daha fazla kategori eklendikçe kodlama, çok büyük bellek alanı tüketen birçok boş değere sahip, seyrek dağılmış değişkenlerle sonuçlanır.
Gömmeler, sayısal değerlere sahip nesneler arasındaki benzerlikleri temsil ederek nesneleri düşük boyutlu bir alana vektörleştirir. Sinir ağı gömmeleri, genişleyen giriş özellikleriyle boyut sayısının yönetilebilir kalmasını sağlar. Giriş özellikleri, bir ML algoritmasının analiz etmekle görevlendirildiği belirli nesnelerin özellikleridir. Boyutsallık azaltma, gömmelerin ML modellerinin giriş verilerinden benzerlikleri ve farklılıkları bulmak için kullandığı bilgileri korumasına olanak tanır. Veri bilimcileri, dağıtılmış nesnelerin ilişkilerini daha iyi anlamak için gömmeleri iki boyutlu bir alanda da görselleştirebilir.
Gömme modelleri nelerdir?
Gömme modelleri, bilgiyi çok boyutlu bir alanda yoğun temsiller olarak özetlemek için eğitilmiş algoritmalardır. Veri bilimcileri, ML modellerinin yüksek boyutlu verileri anlamasını ve akıl yürütmesini sağlamak için gömme modelleri kullanır. Bunlar, ML uygulamalarında kullanılan yaygın gömme modelleridir.
Temel bileşen analizi
Temel bileşen analizi (PCA), karmaşık veri türlerini düşük boyutlu vektörlere indirgeyen bir boyut azaltma tekniğidir. Benzerlikleri olan veri noktalarını bulur ve bunları orijinal verileri yansıtan gömme vektörlerine sıkıştırır. PCA, modellerin ham verileri daha verimli bir şekilde işlemesine izin verirken işleme sırasında bilgi kaybı meydana gelebilir.
Tekil değer ayrışımı
Tekil değer ayrışımı (SVD), bir matrisi tekil matrislere dönüştüren bir gömme modelidir. Ortaya çıkan matrisler, modellerin temsil ettikleri verilerin anlamsal ilişkilerini daha iyi anlamalarına izin verirken orijinal bilgileri korur. Veri bilimcileri görüntü sıkıştırma, metin sınıflandırması ve öneri dahil olmak üzere çeşitli ML görevlerini etkinleştirmek için SVD'yi kullanır.
Word2Vec
Word2Vec, kelimeleri ilişkilendirmek ve bunları gömme alanında temsil etmek için eğitilmiş bir ML algoritmasıdır. Veri bilimcileri, doğal dil anlamayı sağlamak için Word2Vec modelini büyük metinsel veri kümeleriyle besler. Model, bağlamlarını ve anlamsal ilişkilerini dikkate alarak kelimelerdeki benzerlikleri bulur.
Word2Vec'in iki çeşidi vardır: Continuous Bag of Words (CBOW) ve Skip-gram. CBOW, modelin verilen bağlamdan bir kelimeyi tahmin etmesine izin verirken Skip-gram, bağlamı belirli bir kelimeden türetir. Word2Vec etkili bir kelime gömme tekniği olsa da farklı anlamları ima etmek için kullanılan aynı kelimenin bağlamsal farklılıklarını doğru bir şekilde ayırt edemez.
BERT
BERT, insanların anladığı gibi dilleri anlamak için devasa veri kümeleriyle eğitilmiş dönüştürücü tabanlı bir dil modelidir. Word2Vec gibi BERT de eğitildiği giriş verilerinden kelime gömmeleri oluşturabilir. Ek olarak BERT, farklı ifadelere uygulandığında kelimelerin bağlamsal anlamlarını ayırt edebilir. Örneğin, BERT, "Yaz, en sevdiğim mevsimdir" ve "Bu deftere yaz" gibi "yaz" kelimesi için farklı gömmeler oluşturur.
Gömmeler nasıl oluşturulur?
Mühendisler gömme oluşturmak için sinir ağ larını kullanır. Sinir ağları, yinelemeli olarak karmaşık kararlar veren gizli nöron katmanlarından oluşur. Gömme oluştururken gizli katmanlardan biri, girdi özelliklerinin vektörlere nasıl ayrıştırılacağını öğrenir. Bu, özellik işleme katmanlarından önce gerçekleşir. Bu süreç, mühendisler tarafından aşağıdaki adımlarla denetlenir ve yönlendirilir:
- Mühendisler sinir ağını manuel olarak hazırlanan bazı vektörleştirilmiş örneklerle besler.
- Sinir ağı, örnekte keşfedilen kalıpları öğrenir ve görünmeyen verilerden doğru tahminler üretmek üzere bilgi kullanır.
- Bazen mühendislerin giriş özelliklerini uygun boyutsal alana dağıtmasını sağlamak için modele ince ayar yapması gerekebilir.
- Zaman içinde gömmeler bağımsız olarak çalışır ve ML modellerinin vektörleştirilmiş temsillerden öneriler üretmesine izin verir.
- Mühendisler, gömme performansını izlemeye ve yeni verilerle ince ayar yapmaya devam ediyor.
AWS, gömme gereksinimlerinize nasıl yardımcı olur?
Amazon Bedrock, önde gelen yapay zeka şirketlerinden yüksek performanslı temel modelleri (FM) seçeneklerinin yanı sıra üretken yapay zeka (üretici AI) uygulamaları oluşturmak için geniş bir özellik kümesi sunan, tam olarak yönetilen bir hizmettir. Amazon Nova, son teknoloji ürünü (SOTA) temel modellerinin (FM'ler) yeni neslidir ve sektör lideri fiyat performansı sunar. Çeşitli kullanım alanlarını desteklemek üzere oluşturulmuş güçlü, genel kullanım amaçlı modellerdir. Bunları olduğu gibi kullanabilir veya kendi verilerinizle özelleştirebilirsiniz.
Titan Embeddings, metni sayısal bir temsile çeviren bir LLM'dir. Titan Embeddings modeli metin alımını, anlamsal benzerliği ve kümelemeyi destekler. Maksimum giriş metni 8K belirteçtir ve maksimum çıktı vektör uzunluğu 1.536'dır.
Makine öğrenimi ekipleri, gömülmeler oluşturmak için Amazon SageMak er'ı da kullanabilir. Amazon SageMaker, makine öğrenimi modellerini güvenli ve ölçeklenebilir bir ortamda oluşturabileceğiniz, eğitebileceğiniz ve dağıtabileceğiniz bir merkezdir. Mühendislerin düşük boyutlu bir alanda yüksek boyutlu verileri vektörleştirebilecekleri, Object2Vec adlı bir gömme tekniği sunar. Öğrenilen gömmeleri, sınıflandırmalar ve regresyon gibi alt görevler için nesneler arasındaki ilişkileri hesaplamak üzere kullanabilirsiniz.
Hemen bir hesap oluşturarak AWS'de gömülmeye başlayın.
AWS'de Sonraki Adımlar
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages