تحديات الأنظمة الموزعة
التصميم | المستوى 200
مقدمة
عندما أضفنا الخادم الثاني، أصبحت الأنظمة الموزعة نمطًا للحياة في Amazon. عندما بدأت العمل في شركة Amazon عام 1999، كان لدينا عدد قليل للغاية من الخوادم التي كان بوسعنا أن نطلق على بعضها أسماء معروفة مثل "fishy" أو "online-01". بيد أنه حتى في عام 1999، لم يكن استخدام الحوسبة الموزعة أمرًا سهلاً. ثم، كما هو الحال حتى الآن، تضمنت تحديات الأنظمة الموزعة وقت الاستجابة، والتوسّع، وفهم واجهات برمجة التطبيقات (APIs) للشبكات، وتنظيم البيانات وإلغاء تنظيمها، وتعقد لوغاريتمات مثل Paxos. ومع الزيادة السريعة التي حدثت في الأنظمة وزيادة توزيعها، أصبحت ما كانت تعد حالات نظرية للتخزين المؤقت حالات تحدث بانتظام.
إن تطوير خدمات حوسبة المرافق الموزعة، مثل شبكات الهاتف التي يمكن الاعتماد عليها لمسافات طويلة، أو خدمات Amazon Web Services (AWS)، أمر صعب. كما تعد الحوسبة الموزعة أغرب وأقل سهولة من أشكال الحوسبة الأخرى وذلك بسبب مشكلتين مترابطتين. تُعد الأعطال المستقلة وعدم الحتمية من أكثر المشكلات تأثيرًا في الأنظمة الموزعة. بالإضافة إلى أعطال الحوسبة النمطية التي اعتاد عليها معظم المهندسين، يمكن أن تحدث أعطال في الأنظمة الموزعة بطرق أخرى عديدة. والأسوأ من ذلك، تستحيل على الدوام معرفة ما إذا تعطل شيء ما.
وفي مختلف أنحاء مكتبة المنشئين في Amazon نعالج كيفية تعامل AWS مع المشاكل المعقدة للتطوير والتشغيل والناشئة عن الأنظمة الموزعة. قبل الخوض في هذه التقنيات بالتفصيل في مقالات أخرى، من المفيد مراجعة المفاهيم التي تساهم في سبب كون الحوسبة الموزعة غريبة جدًا بشكل جيد. أولا، دعونا نستعرض أنواع الأنظمة الموزعة.
أنواع الأنظمة الموزعة
في الواقع، تختلف الأنظمة الموزعة من حيث صعوبة التنفيذ. فعلى أحد طرفي الطيف، لدينا أنظمة موزعة دون اتصال. وتشمل أنظمة المعالجة بالدفعات ومجموعات تحليل البيانات الضخمة ومزارع عرض مشاهد الأفلام ومجموعات طي البروتين، وما إلى ذلك. على الرغم من سهولة تنفيذ الأنظمة الموزعة غير المتصلة، إلا أنها تتمتع بجميع مزايا الحوسبة الموزعة (قابلية التوسع وتدارك الأخطاء) وتتجنب جميع الجوانب السلبية تقريبًا (أنماط الأعطال المعقدة وغير الحتمية).
وفي وسط الطيف، لدينا أنظمة الوقت الفعلي المرن الموزعة. هذه الأنظمة بالغة الأهمية فعليها أن تنتج أو تُحدّث النتائج بشكل مستمر، ولكنها تتمتع بإطار زمني سخي نسبيًا للقيام بذلك. تتضمن أمثلة هذه الأنظمة بعض منشئي فهرس البحث والأنظمة التي تبحث عن خوادم معطلة وأدوار Amazon Elastic Compute Cloud (Amazon EC2)وما إلى ذلك. قد تكون أداة فهرس البحث غير متصلة (حسب التطبيق) من 10 دقائق إلى عدة ساعات دون أي تأثير غير ضروري على العميل. يجب أن ترسل أدوار Amazon EC2 بيانات الاعتماد المحدثة (بشكل أساسي) إلى كل مثيل EC2، ولكن تتوفر لديها ساعات للقيام بذلك حيث تستمر صلاحية بيانات الاعتماد القديمة لبعض الوقت.
وعلى الطرف الآخر من الطيف، وهو الأكثر صعوبة، لدينا أنظمة الوقت الفعلي الحرج الموزعة. وهي ما تسمى غالبًا بخدمات الطلب/الرد. في Amazon، عندما نفكر في بناء نظام موزع، فإن نظام الوقت الفعلي الكلي الموزع هو أول نوع نفكر فيه. ولكن من المؤسف أن أنظمة الوقت الفعلي الحرج الموزعة هي الأصعب على الإطلاق في تنفيذها بشكل سليم. وما يجعلها صعبة هو أن الطلبات تصل بشكل غير متوقع ويجب أن تتم الاستجابات بسرعة (على سبيل المثال، العميل ينتظر الاستجابة بفعالية). ومن الأمثلة على ذلك خوادم الويب الأمامية، ومسار الطلب، ومعاملات بطاقات الائتمان، وكل AWS API، والاتصالات الهاتفية، وما إلى ذلك. إن أنظمة الوقت الفعلي الحرج الموزعة هي ما تركز عليه هذه المقالة.
أنظمة الوقت الفعلي الحرج تتسم بالغرابة
في أحد خطوط المؤامرة من الكتب الهزلية لسوبرمان، يواجه سوبرمان شخصية أخرى يُطلق عليها Bizarro تعيش على كوكب (Bizarro World) حيث كل شيء معكوس. يبدو أن Bizarro يشبه سوبرمان نوعًا ما ولكنه في الحقيقة شرير. وكذلك أنظمة الوقت الفعلي الحرج الموزعة. فهي تشبه الحوسبة العادية إلى حد ما، ولكنها في واقع الأمر مختلفة، وبصراحة تميل بعض الشيء إلى الجانب الشرير.
يعد تطوير أنظمة الوقت الفعلي الحرج الموزعة غريبًا وذلك لسبب واحد وهو: الاتصال الشبكي للطلب/الرد. لا نعني التفاصيل الجوهرية لـ TCP/IP أو DNS أو المقابس أو غيرها من البروتوكولات. من المحتمل أن تكون هذه الموضوعات صعبة الإدراك، ولكنها تشبه مشاكل أخرى صعبة في الحوسبة.
ما يجعل أنظمة الوقت الفعلي الحرج الموزعة صعبة هو أن الشبكة تمكن إرسال الرسائل من نطاق معطل إلى آخر. قد يبدو إرسال رسالة أمرًا غير ضار. في الواقع، يبدأ كل شيء في التعقيد أكثر من المعتاد من إرسال الرسائل.
لنأخذ مثالاً بسيطًا، ونلق نظرة على التعليمات البرمجية التالية المقتطفة من تطبيق Pac-Man. فهو مصمم للتشغيل على جهاز واحد، ولا يرسل أية رسائل عبر أي شبكة.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
والآن، لنتخيل القيام بتطوير نسخة من هذه التعليمات البرمجية متصلة بشبكة، حيث يتم الحفاظ على حالة عنصر اللوحة على خادم منفصل. سيؤدي كل اتصال بعنصر اللوحة، مثل findAll()، إلى إرسال واستلام رسائل بين خادمين.
عندما يتم إرسال رسالة طلب/رد بين خادمين، يجب أن تحدث دائمًا نفس المجموعة المكونة من ثماني خطوات، كحد أدنى. لفهم التعليمات البرمجية لـ Pac-Man المتصلة بالشبكة، دعونا نراجع أساسيات إرسال رسائل الطلب/الرد.
إرسال رسائل عبر شبكة
إرسال رسائل الطلب/الرد عبر شبكة
يتضمن إجراء رحلة ذهاب وإياب لرسالة طلب/رد الخطوات نفسها دائمًا. كما هو موضح في الرسم التخطيطي التالي، يرسل CLIENT من جهاز العميل MESSAGE طلبًا عبر NETWORK اتصال الشبكة إلى SERVER جهاز الخادم، الذي يرد برسالة REPLY عبر NETWORK الشبكة أيضًا.
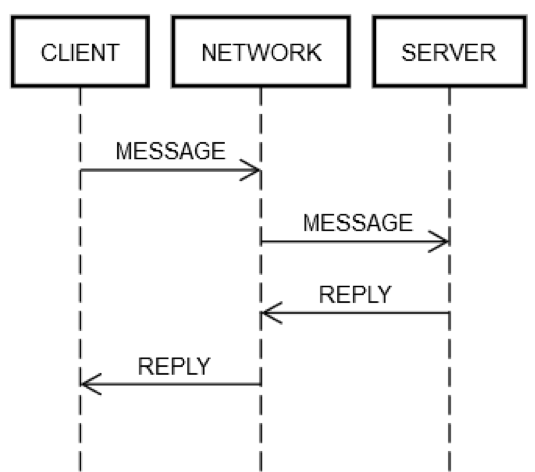
وفي أفضل الأحوال عند حدوث كل شيء كما يجب، تتم الخطوات التالية:
-
POST REQUEST: يرسل العميل MESSAGE طلبًا إلى NETWORK.
-
DELIVER REQUEST: تقوم NETWORK بتسليم MESSAGE إلى SERVER.
-
VALIDATE REQUEST: يتحقق SERVER من MESSAGE.
-
UPDATE SERVER STATE: يُحدِّث SERVER حالته، إذا لزم الأمر، استنادًا إلى MESSAGE.
-
POST REPLY: يقوم SERVER بإرسال رد REPLY إلى NETWORK.
-
DELIVER REPLY: تقوم NETWORK بتسليم REPLY إلى CLIENT.
-
VALIDATE REPLY: يتحقق CLIENT من REPLY.
-
UPDATE CLIENT STATE: يحدث CLIENT حالته، إذا لزم الأمر، استنادًا إلى REPLY.
إنها خطوات كثيرة لرحلة ذهاب وإياب واحدة بسيطة! ومع ذلك، فإن هذه الخطوات هي تعريف لاتصال الطلب/الرد عبر الشبكة؛ ولا توجد طريقة لتخطي أي منها. فعلى سبيل المثال، يستحيل تخطي الخطوة 1. يجب أن يرسل العميل MESSAGE إلى NETWORK الشبكة بطريقة ما. وفعليًا، يعني ذلك إرسال الحزم عبر محول الشبكة، مما يتسبب في انتقال إشارات كهربائية عبر الأسلاك عبر سلسلة من أجهزة التوجيه التي تشكل الشبكة بين CLIENT وSERVER. وهذه الخطوة منفصلة عن الخطوة الثانية حيث قد تفشل الخطوة الثانية لأسباب مستقلة، مثل فقدان SERVER للطاقة فجأة وعدم قدرته على قبول الحزم الواردة. يمكن تطبيق نفس المنطق على الخطوات المتبقية.
وهكذا، فإن رسالة طلب/رد واحدة عبر الشبكة تحول شيئًا واحدًا (يدعى طريقة) إلى ثمانية أشياء. الأسوأ من ذلك، كما هو مذكور أعلاه، أن CLIENT وSERVER وNETWORK قد يفشلون بشكل مستقل عن بعضهم البعض. ويجب أن تعالج التعليمات البرمجية للمهندسين أيًا من أعطال الخطوات المذكورة سابقًا. وهذا نادر الحدوث في الهندسة النموذجية. لمعرفة السبب، لنراجع التعبير التالي من التعليمات البرمجية من إصدار الجهاز الفردي.
board.find("pacman")
تقنيًا، هناك بعض الطرق الغريبة التي قد تسبب فشل هذه التعليمات البرمجية أثناء التشغيل، حتى لو كان تنفيذ board.find نفسه خاليًا من الأخطاء. على سبيل المثال، قد ترتفع درجة حرارة وحدة المعالجة المركزية (CPU) تلقائيًا أثناء التشغيل. وقد يتعطل مزود الطاقة الخاص بالماكينة، بشكل تلقائي أيضًا. قد يصدر صوت إنذار مفاجئ من الداخل. يمكن أن تمتلئ الذاكرة، ولا يمكن إنشاء بعض الأشياء التي تحاول board.find إنشاءها. أو قد يمتلئ القرص الموجود على الجهاز الذي تشغله هذه التعليمات، وقد يفشل board.find في تحديث بعض ملفات الإحصائيات ومن ثم يحدث خطأ ما، بالرغم من أنه لا ينبغي حدوث ذلك على الأرجح. يمكن أن تصل أشعة جاما إلى الخادم وتؤثر بعض الشيء في ذاكرة الوصول العشوائي (RAM). ولكن غالبًا لا ينزعج المهندسون من هذه الأمور. فعلى سبيل المثال، لا تتناول اختبارات الوحدة "ماذا يحدث إذا تعطلت وحدة المعالجة المركزية" مطلقًا، ونادرًا ما تتناول حالات نفاد الذاكرة.
ففي الهندسة النموذجية، تحدث هذه الأنواع من الأعطال في جهاز واحد؛ ويعد هذا عطل مجال فردي. على سبيل المثال، إذا فشلت طريقة board.find نظرًا لأن وحدة المعالجة المركزية تتعطل تلقائيًا، فلا ضرر من أن نفترض أن الجهاز قد توقف بأكمله. وليس من الممكن حتى معالجة هذا الخطأ من الناحية النظرية. ويمكن وضع افتراضات مماثلة حول أنواع الأخطاء الأخرى المذكورة سابقًا. يمكنك محاولة إنشاء اختبارات لبعض هذه الحالات، إلا أن فائدة الهندسة النموذجية منها تكاد لا تذكر. إذا حدثت هذه الأعطال، فلا ضرر من افتراض أن كل شيء آخر سيتعطل أيضًا. لذا، نستطيع القول بأن هذه الأعطال ذات مصير مشترك من الناحية الفنية. يحد المصير المشترك بقدر كبير من أنماط الأعطال المختلفة التي يتعين على المهندس معالجتها.
فشل المعالجة
معالجة أنماط الفشل في أنظمة الوقت الفعلي الحرج الموزعة
يجب على المهندسين، الذين يعملون على أنظمة الوقت الفعلي الحرج الموزعة، اختبار جميع جوانب أعطال الشبكة نظرًا لعدم مشاركة المصير بين الخوادم والشبكة. أما إذا تعطلت الشبكة، فإن جهاز العميل سيستمر في العمل، خلافًا للحالة التي عليها الجهاز الواحد. أما إذا تعطل الجهاز البعيد، فإن جهاز العميل سيستمر في العمل، وهكذا.
لإجراء اختبار شامل لحالات أعطال خطوات الطلب/الرد الموضحة مسبقًا، يجب أن يفترض المهندسون أن كل خطوة قد تتعطل. ويجب عليهم التأكد من أن التعليمات البرمجية (بالنسبة للعميل والخادم على السواء) تعمل دائمًا بشكل صحيح في ظل تلك الأعطال.
لننظر إلى رحلة الذهاب والإياب لإجراء طلب/رد حيث تتعطل الأشياء:
-
تعطلPOST REQUEST: إما فشلت NETWORK في إيصال الرسالة (على سبيل المثال، تعطل الجهاز الموجّه المتوسط في وقت غير مناسب) أو رفضها SERVER بشكل صريح.
-
فشل طلب DELIVER REQUEST: تقوم NETWORK بنجاح بتسليم MESSAGE إلى SERVER، ولكن يتعطل SERVER مباشرة بعد استلام MESSAGE.
-
فشل طلب VALIDATE REQUEST: يقرر SERVER أن MESSAGE غير صالح. يمكن أن يعود السبب إلى أي شيء تقريبًا. مثل الحزم التالفة أو إصدارات البرامج غير المتوافقة أو الأخطاء الموجودة عند العميل أو الخادم.
-
فشل تحديث حالة SERVER: يحاول SERVER تحديث حالته، لكن ذلك لا ينجح.
-
فشل نشر الرد POST REPLY: بغض النظر عما إذا كان يحاول الرد بالنجاح أو الفشل، قد يفشل SERVER في نشر الرد. على سبيل المثال، قد تتعطل بطاقة الشبكة لديها في وقت غير مناسب.
-
فشل تسليم الرد DELIVER REPLY: قد تفشل NETWORK في تسليم REPLY إلى CLIENT كما هو موضح سابقًا، حتى وإن كانت NETWORK تعمل في خطوة سابقة.
-
فشل التحقق من الرد VALIDATE REPLY: يقرر CLIENT أن REPLY غير صالح.
-
فشل تحديث حالة CLIENT: قد يستلم CLIENT رسالة REPLY لكنه يفشل في تحديث حالته الخاصة، أو يفشل في فهم الرسالة (بسبب عدم التوافق)، أو يفشل لسبب آخر.
تتسبب أنماط الأعطال هذه في جعل الحوسبة الموزعة صعبة للغاية. أدعوها بأنماط الأعطال الثمانية المكتشفة. وفي ظل أنماط الأعطال هذه، لنراجع هذا التعبير من التعليمات البرمجية لـ Pac-Man مرة أخرى.
board.find("pacman")
يمتد هذا التعبير إلى نشاطات العميل التالية:
-
يمكنك إرسال رسالة، مثل {فعل: "اعثر"، اسم: "pacman"، معرف المستخدم: "8765309"}، yGN الشبكة، موجهة إلى جهاز Board.
-
إذا كانت الشبكة غير متوفرة، أو تم رفض الاتصال بجهاز Board بشكل صريح، فيحدث خطأ. تعد هذه حالة خاصة إلى حد ما نظرًا لأن العميل يعرف جيدًا بأنه من المحتمل ألا يتلقى جهاز الخادم الطلب.
-
انتظر ردًا.
-
إذا لم يتم تلق أي رد، فينتهي الوقت المحدد. وفي هذه الخطوة، يشير انتهاء الوقت المحدد إلى أن نتيجة الطلب UNKNOWN. قد يحدث هذا الأمر أو لا. يجب أن يتعامل العميل مع النتيجة UNKNOWN بشكل صحيح.
-
في حال تلقي رد، حدد إذا كان الرد ناجحًا أو ردًا خطأ أو ردًا غير مفهوم/تالفًا.
-
إذا لم يحدث خطأ، فقم بتنظيم الاستجابة وحولها إلى عنصر يمكن أن تفهمه التعليمات البرمجية.
-
إذا حدث خطأ أو رد غير مفهوم، فيحدث استثناء.
-
ينبغي على ما يعالج هذا الاستثناء أن يحدد ما إذا كان يجب إعادة محاولة الطلب أو الاستسلام وعدم المحاولة وإيقاف اللعبة.
يبدأ التعبير أيضًا نشاطات جانب الخادم التالية:
-
تلق الطلب (قد لا يحدث هذا الأمر على الإطلاق).
-
التحقق من صحة الطلب.
-
ابحث عن المستخدم لمعرفة ما إذا كان المستخدم لا يزال على قيد الحياة. (ربما تخلى الخادم عن المستخدم لأنه لم يتلق منه أي رسائل لفترة طويلة جدًا.)
-
قم بتحديث جدول استمرارية المستخدم حتى يعرف الخادم أنه (ربما) ما زال موجودًا.
-
ابحث عن مكان المستخدم.
-
ارسل ردًا يتضمن شيئًا مثل {xPos: 23 ،yPos: 92، الساعة: 23481984134}.
-
يجب أن يعالج أي منطق آخر للخادم التأثيرات المستقبلية للعميل بشكل صحيح. على سبيل المثال، الفشل في تلقي الرسالة، أو استلامها ولكن دون فهمها، أو استلامها وتعطلها، أو معالجتها بنجاح.
باختصار، يتحول تعبير واحد في التعليمات البرمجية العادية إلى خمسة عشر خطوة إضافية في التعليمات البرمجية لأنظمة الوقت الفعلي الكلية الموزعة. ويرجع سبب هذا التوسع إلى النقاط الثمانية المختلفة التي يمكن أن يفشل عندها كل اتصال كامل بين العميل والخادم. أي تعبير يمثل اتصالاً كاملاً عبر الشبكة، مثل board.find ("pacman")، ينتج عنه ما يلي.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
ولا يمكن تفادي هذا التعقيد. إذا لم تعالج التعليمات البرمجية جميع الحالات بشكل صحيح، فستفشل الخدمة في نهاية المطاف بطرق غريبة. تخيل أنك تحاول إجراء اختبارات لجميع أنماط الأعطال التي قد يتعرض لها نظام العميل / الخادم مثل لعبة Pac-Man!
الاختبار
إجراء اختبار لأنظمة الوقت الفعلي الحرج الموزعة
يعد إجراء اختبار لإصدار الجهاز الفردي من أجزاء التعليمات البرمجية لـ Pac-Man واضحًا ومباشرًا بشكل نسبي. قم بإنشاء بعض مكونات Board المختلفة، وضعها في حالات مختلفة، وأنشئ بعض مواضيع المستخدم في مواضع مختلفة، وما إلى ذلك. لقد تعمق المهندسون بشدة في التفكير بشأن شروط التخزين المؤقت، وربما يستخدمون الاختبارات التوليدية أو الخاطئة.
في التعليمات البرمجية للعبة Pac-Man، هناك أربعة أماكن حيث يتم استخدام موضوع اللوحة. في لعبة Pac-Man الموزعة، هناك أربع نقاط في التعليمات البرمجية لها خمس نتائج مختلفة ممكنة، كما هو موضح سابقًا (POST_FAILED أو RETRYABLE أو FATAL أو UNKNOWN أو SUCCESS). تضاعف هذه النتائج مساحة حالة الاختبارات بشكل كبير. على سبيل المثال، يجب على مهندسي أنظمة الوقت الفعلي الحرج الموزعة معالجة العديد من التباديل. افترض أن الاتصال بـ board.find فشل بـ POST_FAILED. بعد ذلك، يجب عليك اختبار ما يحدث عندما يفشل اتصال board.find بـ RETRYABLE، ثم يجب بعد ذلك اختبار ما يحدث إذا فشل بالاتصال بـ FATAL وهكذا.
ومع ذلك فإن هذا الاختبار غير كافٍ. ففي التعليمات البرمجية النموذجية، قد يفترض المهندسون أنه في حالة عمل board.find، سيعمل أيضًا الاتصال التالي باللوحة وboard.move. أما في هندسة أنظمة الوقت الفعلي الحرج الموزعة، فلا يوجد مثل هذا الضمان. قد يتعطل جهاز الخادم بشكل مستقل في أي وقت. ونتيجة لذلك، يتعين على المهندسين إجراء اختبارات لجميع الحالات الخمس لكل اتصال باللوحة. دعنا نَقُل إن المهندس قد أتى بـ 10 سيناريوهات لاختبار إصدار الآلة المنفردة لـ Pac-Man. ولكن في إصدار الأنظمة الموزعة، يكون عليه اختبار كل من هذه السيناريوهات 20 مرة. مما يعني أن بالونات مصفوفة الاختبار تتراوح بين 10 إلى 200!
ولكن انتظر، هناك المزيد. يمكن للمهندس أيضًا أن يمتلك كود الخادم. وبغض النظر عن حدوث مزيج من أخطاء من جانب جهاز العميل والخادم والشبكة، ينبغي للمهندس إجراء اختبار حتى لا يصل كلٌ من جهاز الخادم والعميل إلى حالة التلف. وقد يبدو كود الخادم كما يلي.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
توجد أربع دوال من جانب الخادم مطلوب اختبارها. دعنا نفترض أن هناك خمسة اختبارات لكل دالة على كل جهاز منفرد. بهذا يكون لدينا هنا 20 حالة اختبار. ونظرًا لأن أجهزة العميل ترسل رسائل متعددة إلى الخادم نفسه، يجب أن تحاكي الاختبارات تتابع الطلبات المختلفة للتأكد من بقاء الخادم في حالة قوية. وتشمل الأمثلة على هذه الطلبات، إيجاد find ونقل move وإزالة remove وإيجاد الكل findAll.
دعنا نقل إن للبنية الواحدة 10 سيناريوهات مختلفة بمتوسط ثلاثة استدعاءات في كل سيناريو. وبهذا يكون لدينا 30 حالة اختبار أخرى. ولكن يجب أيضًا اختبار حالات الفشل في واحد من السيناريوهات. ونحتاج في كل حالة من حالات الاختبار هذه إلى محاكاة ما يحدث في حالة استقبال العميل لأي من أنواع الفشل الأربعة (POST_FAILED وRETRYABLE وFATAL وUNKNOWN) ثم يستدعي الخادم مجددًا بطلب غير صالح. فعلى سبيل المثال، يمكن أن يستدعي العميل أمر find بنجاح ولكن في بعض الحالات قد يسترجع خطأ UNKNOWN عند استدعاء أمر move. ثم قد يستدعي أمر find مجددًا لسبب ما. هل يُعالِج الخادم هذه الحالة بطريقة صحيحة؟ ربما، ولكن لن تعرف أبدًا حتى تختبر هذا الأمر. لذلك، كما هو الحال مع الكود من جانب العميل، يسود التعقيد في مصفوفة الاختبار من جانب الخادم أيضًا.
معالجة أخطاء UNKNOWN غير المعروفة
معالجة أخطاء UNKNOWN غير المعروفة
من المذهل التفكير في كل تباديل حالات الفشل التي يمكن أن يواجهها النظام الموزع، خاصةً في حالة الطلبات المتعددة. وقد توصلنا إلى طريقة للوصول إلى الهندسة الموزعة وهي من خلال الشك في كل شيء. كل سطر من سطور الكود قد لا يؤدي المهمة المفترض به تأديتها، ما لم يتعذر عليه تحقيق اتصال مع الشبكة بشكل محتمل.
ربما تكون المشكلة الأصعب في المعالجة هي نوع الخطأ UNKNOWN المبينة في القسم السابق. وقد لا يعرف العميل في كل مرة إذا ما كان الطلب قد تحقق أم لا. ربما نقل الطلب Pac-Man (أو في سياق الخدمات البنكية، سحب الأموال من الحساب البنكي للمستخدم)، أو ربما لم يقم بتنفيذ المطلوب. كيف يمكن للمهندسين أن يعالجوا هذا الأمر؟ من الصعب معالجة هذا الأمر لأن المهندسين بشر في النهاية، وعادةً ما يصارع البشر حالات عدم اليقين الفعلية. اعتاد البشر على النظر للتعليمات البرمجية كالتالي.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
يفهم البشر هذا الكود لأنه يؤدي ما يتوجب عليه تأديته. يتعامل البشر بصعوبة مع النسخة الموزعة من التعليمات البرمجية، والتي توزع بعض الأعمال لخدمة ما.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
يكاد يكون من المستحيل على الإنسان معرفة كيفية التعامل مع خطأ UNKNOWN بشكل صحيح. ماذا يعني خطأ UNKNOWN؟ هل يجب على الكود إعادة المحاولة؟ وإذا كان كذلك، كم من المرات؟ كم من الوقت يجب الانتظار بين مرات المحاولة؟ تزداد الأمور سوءًا عندما يكون للكود آثار جانبية. يسهل سحب الأموال من حساب داخل تطبيق إعداد الموازنة الذي يعمل على جهاز منفرد، كما هو موضح في المثال التالي.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
ومع ذلك، فإن الإصدار الموزع من هذا التطبيق يكون غريبًا بسبب خطأ UNKNOWN.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
يُعد التعرف على كيفية التعامل مع نوع الخطأ غير المعروف UNKNOWN أحد الأسباب التي تجعل الأمور في الهندسة الموزعة ليست كما تبدو دائمًا.
المجموعات
مجموعات من أنظمة الوقت الفعلي الحرج الموزعة
يمكن أن تحدث أوضاع الفشل الثمانية عند أي مستوى من التجريد ضمن النظام الموزع. كان المثال السابق محصورًا على جهاز عميل أو شبكة أو جهاز خادم واحد. حتى في هذا السيناريو البسيط، ساد التعقيد في مصفوفة حالات الفشل. تحتوي أنظمة الوقت الفعلي الموزعة على مصفوفات حالات فشل أكثر تعقيدًا من مثال جهاز العميل الواحد. تتكون أنظمة الوقت الفعلي الموزعة من أجهزة متعددة يمكن عرضها على مستويات متعددة من التجريد:
-
أجهزة منفردة
-
مجموعات من الأجهزة
-
مجموعات من مجموعات الأجهزة
-
وهكذا (على نحو محتمل)
فعلى سبيل المثال، قد تقوم خدمة مبنية على AWS بتجميع الأجهزة المخصصة معًا لمعالجة الموارد الموجودة في منطقة توافر خدمات معينة. وقد يكون هناك أيضًا مجموعتان إضافيتان من الأجهزة التي تتعامل مع اثنتين من مناطق توافر الخدمات. ثم قد يتم تجميع هاتين المجموعتين في مجموعة "منطقة خدمات AWS". ويمكن لمجموعة "منطقة الخدمات" هذه أن تتواصل (منطقيًا) مع مجموعات أخرى من "منطقة الخدمات". لسوء الحظ، حتى في هذا المستوى الأعلى والأكثر منطقية، تنطبق جميع المشكلات نفسها.
دعنا نفترض أن هناك خدمة قامت بتجميع بعض الخوادم في مجموعة منطقية واحدة. (مجموعة 1). أحيانًا، ربما ترسل المجموعة (مجموعة 1) رسائل إلى مجموعة أخرى من الخوادم، (مجموعة 2). ويعد هذا مثالاً على الهندسة الموزعة التكرارية. ويمكن هنا أن تنطبق جميع أوضاع فشل الشبكات الموصوفة سابقًا. لنفترض أن (مجموعة 1) أرسلت طلبًا إلى (مجموعة 2). فإن تفاعل الطلب/الرد بين الجهازين يكون أشبه بمثال الجهاز المنفرد الذي تحدثنا عنه سابقًا، كما هو موضح في الرسم التخطيطي التالي.
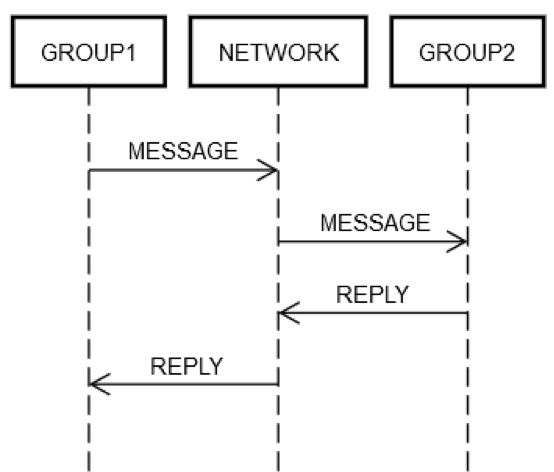
بشكل أو بآخر، يجب على بعض الأجهزة داخل (مجموعة 1) أن تضع رسالة على الشبكة، (الشبكة)، تكون موجهة (منطقيًا) إلى (مجموعة 2). كما يجب على بعض الأجهزة ضمن (مجموعة 2) معالجة الطلب وهكذا دواليك. ولا تتغير هذه الأسس بالرغم من أن (مجموعة 1) و(مجموعة 2) تتألفان من مجموعات من الأجهزة. ورغم ذلك، يمكن أن تفشل (مجموعة 1) و(مجموعة 2) و(الشبكة) كل على حدى.
ومع ذلك، فهذه هي طريقة عرض مستوى المجموعات. وهناك أيضًا تفاعل على مستوى كل جهاز وآخر داخل كل مجموعة. على سبيل المثال، قد تكون (مجموعة 2) مهيكلة كما هو موضح في الرسم التخطيطي التالي.
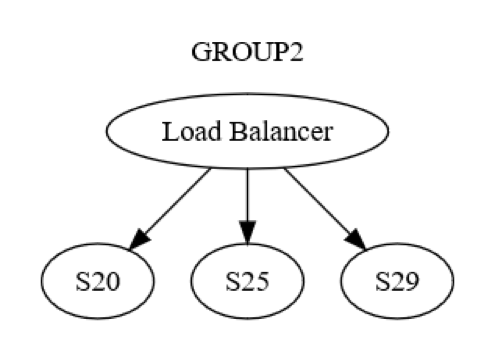
في البداية ، يتم إرسال رسالة إلى (مجموعة 2)، عبر موازن الأحمال إلى جهاز واحد (ربما S20) داخل المجموعة. يعرف مصممو النظام أن الجهاز S20 قد يفشل أثناء مرحلة حالة التحديث (UPDATE STATE). ونتيجة لذلك، قد يحتاج S20 إلى تمرير الرسالة إلى جهاز واحد آخر على الأقل، إما يكون أحد أقرانه أو جهازًا في مجموعة مختلفة. كيف يقوم الجهاز S20 بذلك في الواقع؟ عن طريق إرسال رسالة طلب/رد إلى (الجهاز S25، مثلاً)، كما هو موضح في الرسم التخطيطي التالي.
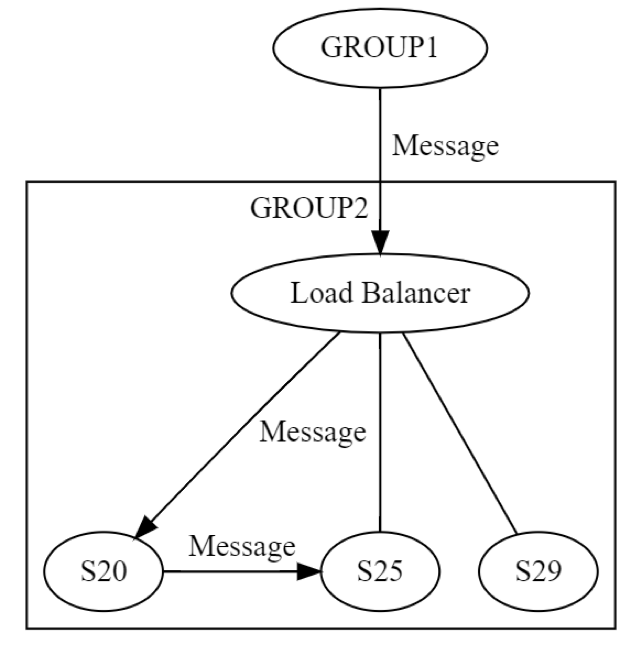
وبالتالي فإن الجهاز S20 يؤدي عملية تواصل شبكي بشكل متكرر. ويمكن أن تحدث جميع حالات الفشل الثمانية نفسها بشكل مستقل مرة أخرى. وتحدث الهندسة الموزعة مرتين بدلاً من مرة واحدة. ويمكن أن تفشل رسالة (مجموعة 1) إلى (مجموعة 2) على المستوى المنطقي بجميع الطرق الثمانية. وينتج عن هذه الرسالة رسالة أخرى يمكن أن تفشل بذاتها بشكل مستقل، بجميع الطرق الثمانية التي ناقشناها سابقًا. قد يتضمن اختبار هذا السيناريو ما يلي على الأقل:
-
اختبار لكل الطرق الثماني التي يمكن أن تفشل فيها المراسلة من مجموعة 1 إلى مجموعة 2 على مستوى المجموعة.
-
اختبار لكل الطرق الثمانية التي يمكن أن تفشل فيها المراسلة من الجهاز (S20) إلى الجهاز (S25) على مستوى الخوادم.
يوضح هذا المثال لمراسلة الطلب/الرد السبب في أن اختبار الأنظمة الموزعة لا يزال يمثل مشكلة مزعجة بشكل خاص، حتى بعد أكثر من 20 عامًا من الخبرة في هذا الجانب. ويمثل الاختبار تحديًا نظرًا لاتساع حالات التخزين المؤقت، لكنه مهم بشكل خاص في هذه الأنظمة. قد يستغرق ظهور الأخطاء وقتًا طويلاً بعد نشر الأنظمة. ويمكن أن يكون للأخطاء تأثير واسع بشكل غير متوقع على النظام والأنظمة المتصلة به.
الأخطاء الموزعة
الأخطاء الموزعة غالبًا ما تكون مستترة
إذا كان سيحدث فشل في نهاية المطاف، فمن الأفضل منطقيًا أن يحدث عاجلاً وليس آجلاً. على سبيل المثال، من الأفضل اكتشاف مشكلة نطاق استخدام الخدمة، والتي ستتطلب ستة أشهر لإصلاحها، ستة أشهر على الأقل قبل أن تحقق تلك الخدمة نطاق الاستخدام هذا. وبالمثل، ينبغي لك اكتشاف الأخطاء قبل وصولها إلى الإنتاج. إذا وصلت المشكلة إلى الإنتاج، فمن الأفضل العثور عليها بسرعة، قبل أن تؤثر على العديد من العملاء أو أن يكون لديها آثار ضارة أخرى.
وهذه الأخطاء الموزعة غالبًا ما تكون عظيمة الأثر؛ وهي تلك الأخطاء الناتجة عن الفشل في التعامل مع كل التباديل لأنماط الفشل الثمانية للعناصر المكتشفة. وتحدث حالات مماثلة عديدة بمرور الوقت في النظم الموزعة الكبيرة، وتبدأ من أنظمة الاتصالات السلكية واللاسلكية انتهاءً بأنظمة الإنترنت الأساسية. وهذه الانقطاعات ليست واسعة المدى ومكلفة فحسب، بل يمكن أن يكون سببها الأخطاء التي تم نشرها قبل أشهر من الإنتاج. ثم يستغرق الأمر بعض الوقت لاستدعاء مجموعة من السيناريوهات التي تؤدي فعليًا إلى حدوث هذه الأخطاء (وانتشارها عبر النظام بأكمله).
تنتشر الأخطاء الموزعة بطريقة وبائية
لنصف مشكلة أخرى أساسية للأخطاء الموزعة:
-
الأخطاء الموزعة تتضمن بالضرورة استخدام الشبكة.
-
لذلك، من المحتمل أن تنتشر الأخطاء الموزعة إلى أجهزة أخرى (أو مجموعات من الأجهزة)، نظرًا لأنها، بحكم تعريفها تتضمن بالفعل الشيء الوحيد الذي يربط الأجهزة مع بعضها البعض.
عانت Amazon من هذه الأخطاء الموزعة أيضًا. مثال قديم، ولكنه ذو صلة، وهو فشل على مستوى الموقع www.amazon.com بأكمله. حدث هذا الفشل بسبب فشل خادم واحد داخل خدمة كتالوج عن بُعد عند امتلاء القرص الخاص به.
ونظرًا لسوء التعامل مع حالة الخطأ هذه، بدأ خادم الكتالوج عن بُعد في إرجاع استجابات فارغة لكل طلب تلقاه. كما بدأ في إعادتها بسرعة كبيرة، لأنه أسرع بكثير في إرجاع الاستجابات الفارغة من إرجاع الاستجابات ذات القيم (على الأقل كان كذلك في هذه الحالة). وفي الوقت نفسه، لم يلاحظ موازن الأحمال بين موقع الويب وخدمة الكتالوج عن بُعد، أن جميع الاستجابات كانت صفرية الطول. لكن لاحظ موازن الأحمال أنها كانت أسرع من جميع خوادم الكتالوج عن بُعد الأخرى. وهكذا، أرسل موازن الأحمال عددًا كبيرًا من نسب استخدام الشبكة من www.amazon.com إلى خادم الكتالوج عن بُعد الذي كان قرصه ممتلئًا. وتعطل موقع الويب بالكامل فعليًا نظرًا لعدم قدرة أحد الخوادم عن بُعد على عرض أي معلومات عن المنتج.
ووجدنا الخادم غير الصالح بسرعة، وأزلناه من الخدمة لاستعادة موقع الويب. بعد ذلك، عملنا على متابعة عمليتنا المعتادة المتمثلة في تحديد الأسباب الأساسية وتحديد المشكلات لمنع حدوث هذا الموقف مرة أخرى. وشاركنا هذه الدروس عبر Amazon للمساعدة في منع الأنظمة الأخرى من مواجهة المشكلة نفسها. بالإضافة إلى تعلم الدروس المحددة حول وضع الفشل هذا، كان هذا الحادث بمثابة مثال رائع عن كيفية انتشار أنماط الفشل بسرعة وبشكلٍ غير متوقع في الأنظمة الموزعة.
الملخص
ملخص المشكلات التي تحدث في الأنظمة الموزعة
باختصار، هندسة النظم الموزعة صعبة للأسباب التالية:
-
لا يمكن للمهندسين تجميع حالات الخطأ. بدلاً من ذلك، يجب عليهم التفكير في العديد من تباديل حالات الفشل. يمكن أن تحدث معظم الأخطاء في أي وقت، دون أن ترتبط بحالة خطأ أخرى وقد ترتبط بشكل محتمل بحالة خطأ أخرى.
-
أي عملية على الشبكة قد تكون نتيجتها غير معروفة، وفي هذه الحالة قد يكون ينجح الطلب أو يفشل أو يتم استلامه دون أن تتم معالجته.
-
تحدث المشكلات الموزعة على جميع المستويات المنطقية للنظام الموزع، وليس فقط على المستوى المنخفض للأجهزة المادية.
-
تتفاقم المشكلات الموزعة في المستويات العليا من النظام، بسبب التكرار.
-
تظهر الأخطاء الموزعة غالبًا بعد نشرها في النظام لفترة طويلة.
-
يمكن أن تنتشر الأخطاء الموزعة عبر النظام بأكمله.
-
تنشأ العديد من المشكلات المذكورة أعلاه من قوانين فيزياء الشبكات، والتي لا يمكن تغييرها.
كون الحوسبة الموزعة صعبة - وغريبة - لا يعني أنه لا توجد طرق لمعالجة هذه المشكلات. في جميع أنحاء «مكتبة المنشئين في Amazon»، ندرس كيفية إدارة AWS للأنظمة الموزعة. نأمل أن تجد بعضًا مما تعلمناه قيمًا أثناء إنشائك للمحتوى لعملائك.
نبذة عن المؤلف
يشغل جاكوب غابرييلسون منصب كبير المهندسين الأساسيين في Amazon Web Services. يعمل جاكوب غابرييلسون في شركة Amazon منذ 17 عامًا، في المقام الأول على النظم الأساسية للخدمات المصغرة الداخلية. وعلى مدار الأعوام الثمانية الماضية، عمل في EC2 وECS، بما في ذلك أنظمة نشر البرامج، وخدمات مستوى التحكم، وسوق Spot، وLightsail، ومؤخرًا الحاويات. إن شغف جاكوب يكمن في برمجة النظم ولغات البرمجة والحوسبة الموزعة. وأكثر ما لا يرغب به هو السلوك ثنائي النمط، خاصة في حالات الفشل. وهو حاصل على درجة البكالوريوس في علوم الكمبيوتر من جامعة واشنطن في سياتل.

هل وجدت ما كنت تبحث عنه اليوم؟
أخبرنا حتى نتمكن من تحسين جودة المحتوى الموجود على صفحاتنا