AWS Big Data Blog
Category: Analytics
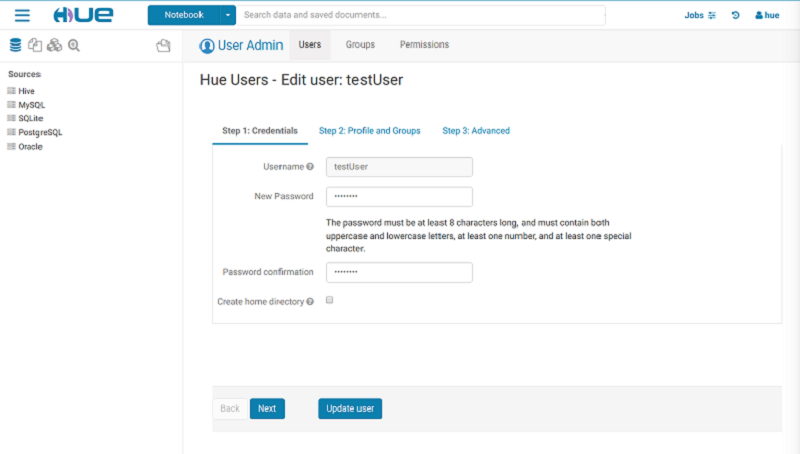
How to migrate a Hue database from an existing Amazon EMR cluster
This post describes the step-by-step process for migrating the Hue database from an existing EMR cluster.
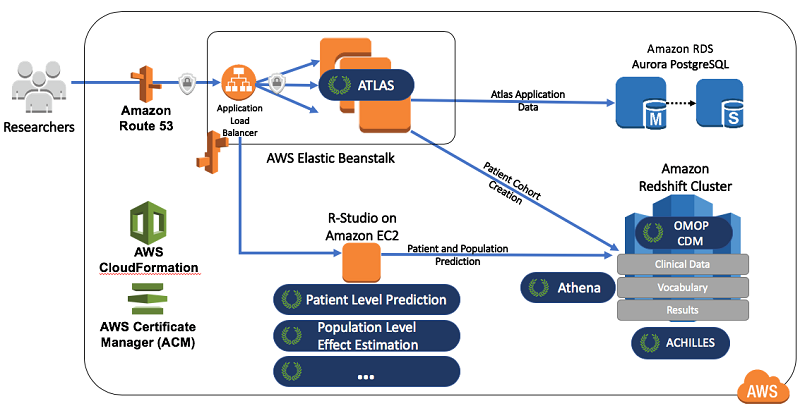
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.
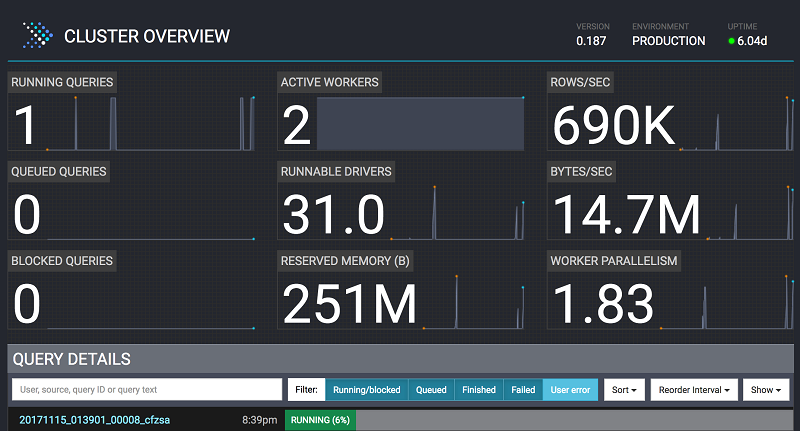
Easily manage table metadata for Presto running on Amazon EMR using the AWS Glue Data Catalog
In this post, we will explore how the AWS Glue Data Catalog addresses discoverability and manageability for table metadata for Presto on Amazon EMR.
Improve the Operational Efficiency of Amazon Elasticsearch Service Domains with Automated Alarms Using Amazon CloudWatch
A customer has been successfully creating and running multiple Amazon Elasticsearch Service (Amazon ES) domains to support their business users’ search needs across products, orders, support documentation, and a growing suite of similar needs. The service has become heavily used across the organization. This led to some domains running at 100% capacity during peak times, while others began to run low on storage space. Because of this increased usage, the technical teams were in danger of missing their service level agreements. They contacted me for help.
This post shows how you can set up automated alarms to warn when domains need attention.

Best Practices for Running Apache Kafka on AWS
The best practices described in this post are based on our experience in running and operating large-scale Kafka clusters on AWS for more than two years. Our intent for this post is to help AWS customers who are currently running Kafka on AWS, and also customers who are considering migrating on-premises Kafka deployments to AWS.

Amazon Redshift – 2017 Recap
We have been busy adding new features and capabilities to Amazon Redshift, and we wanted to give you a glimpse of what we’ve been doing over the past year. In this article, we recap a few of our enhancements and provide a set of resources that you can use to learn more and get the most out of your Amazon Redshift implementation.
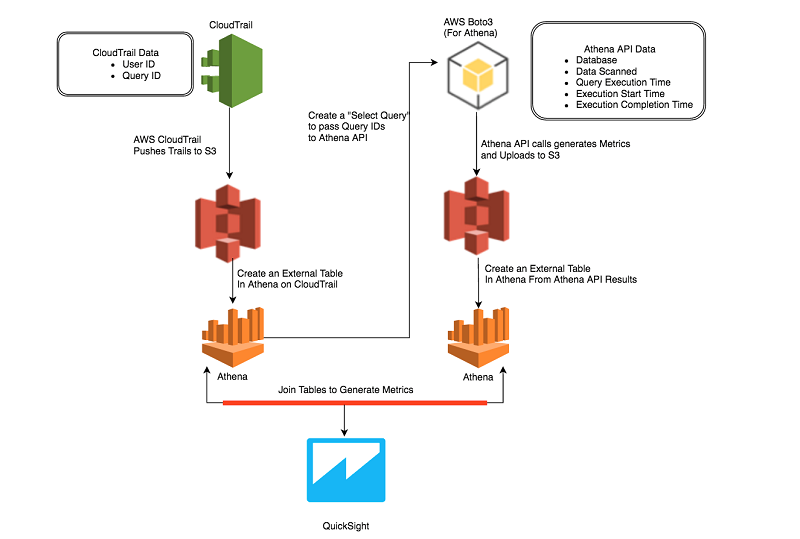
How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight
In this post, I discuss how to build a solution for monitoring Athena usage. To build this solution, you rely on AWS CloudTrail. CloudTrail is a web service that records AWS API calls for your AWS account and delivers log files to an S3 bucket.

How I built a data warehouse using Amazon Redshift and AWS services in record time
Over the years, I have developed and created a number of data warehouses from scratch. Recently, I built a data warehouse for the iGaming industry single-handedly. To do it, I used the power and flexibility of Amazon Redshift and the wider AWS data management ecosystem. In this post, I explain how I was able to build a robust and scalable data warehouse without the large team of experts typically needed.

Build a Multi-Tenant Amazon EMR Cluster with Kerberos, Microsoft Active Directory Integration and IAM Roles for EMRFS
In this post, we will discuss what EMRFS authorization is (Amazon S3 storage-level access control) and show how to configure the role mappings with detailed examples.

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.