AWS Big Data Blog
Category: Management Tools

Implement continuous integration and delivery of serverless AWS Glue ETL applications using AWS Developer Tools
In this post, I walk you through a solution that implements a CI/CD pipeline for serverless AWS Glue ETL applications supported by AWS Developer Tools (including AWS CodePipeline, AWS CodeCommit, and AWS CodeBuild) and AWS CloudFormation.
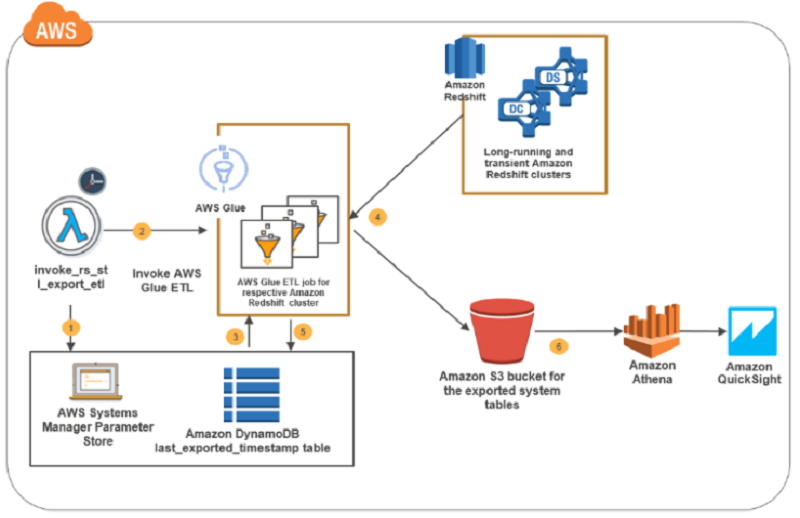
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.
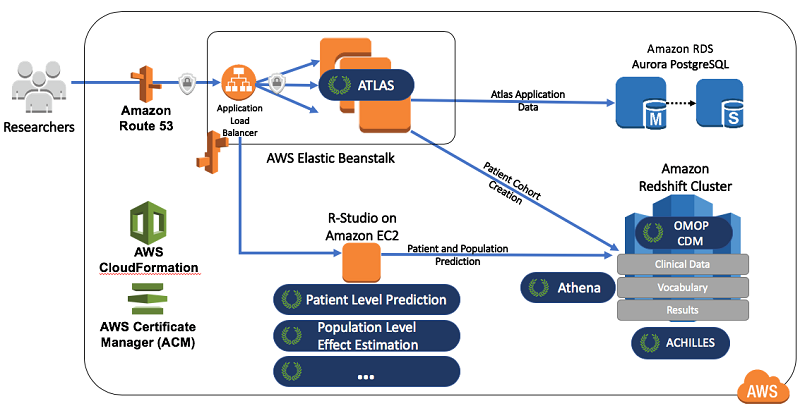
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.
Improve the Operational Efficiency of Amazon Elasticsearch Service Domains with Automated Alarms Using Amazon CloudWatch
A customer has been successfully creating and running multiple Amazon Elasticsearch Service (Amazon ES) domains to support their business users’ search needs across products, orders, support documentation, and a growing suite of similar needs. The service has become heavily used across the organization. This led to some domains running at 100% capacity during peak times, while others began to run low on storage space. Because of this increased usage, the technical teams were in danger of missing their service level agreements. They contacted me for help.
This post shows how you can set up automated alarms to warn when domains need attention.
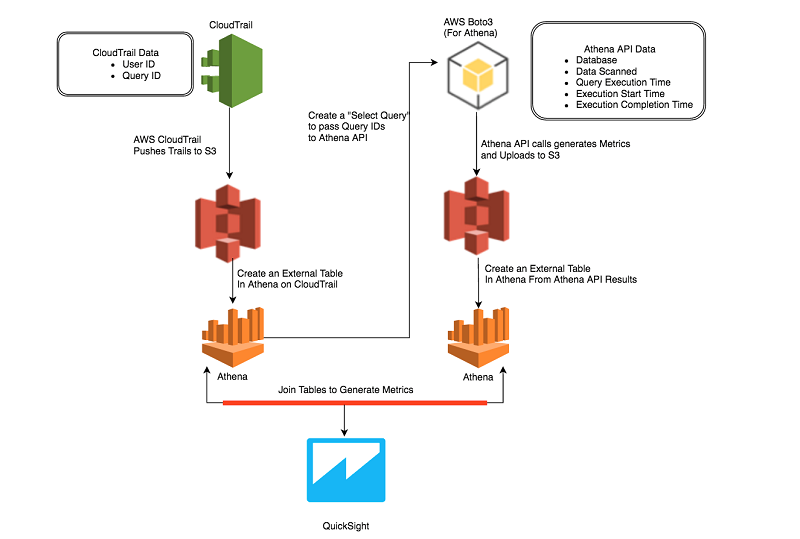
How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight
In this post, I discuss how to build a solution for monitoring Athena usage. To build this solution, you rely on AWS CloudTrail. CloudTrail is a web service that records AWS API calls for your AWS account and delivers log files to an S3 bucket.

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.

Visualize AWS Cloudtrail Logs Using AWS Glue and Amazon QuickSight
In this post, I walk through using AWS Glue and AWS Lambda to convert AWS CloudTrail logs from JSON to a query-optimized format dataset in Amazon S3. I then use Amazon Athena and Amazon QuickSight to query and visualize the data.
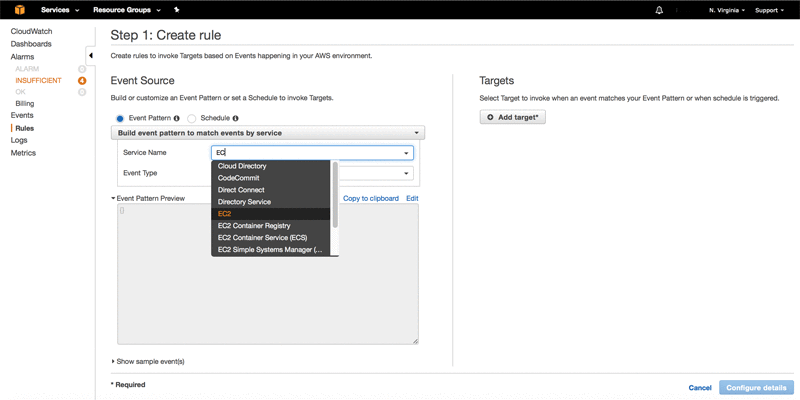
Visualize and Monitor Amazon EC2 Events with Amazon CloudWatch Events and Amazon Kinesis Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Monitoring your AWS environment is important for security, performance, and cost control purposes. For example, by monitoring […]

Analyze Security, Compliance, and Operational Activity Using AWS CloudTrail and Amazon Athena
As organizations move their workloads to the cloud, audit logs provide a wealth of information on the operations, governance, and security of assets and resources. As the complexity of the workloads increases, so does the volume of audit logs being generated. It becomes increasingly difficult for organizations to analyze and understand what is happening in […]
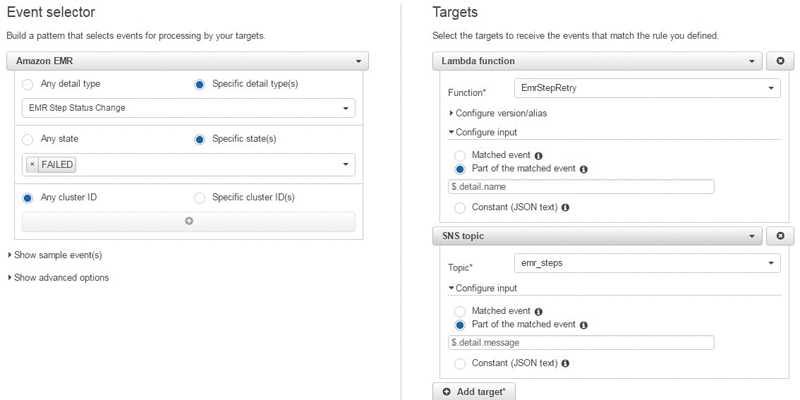
Respond to State Changes on Amazon EMR Clusters with Amazon CloudWatch Events
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers can take advantage of the Amazon EMR API to create and terminate EMR clusters, scale clusters using Auto Scaling or manual resizing, and submit and run Apache Spark, Apache Hive, or Apache Pig workloads. These decisions are often triggered from cluster state-related information. Previously, […]