AWS Big Data Blog
Category: Technical How-to

Use custom domain names with Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. Amazon Redshift now supports custom URLs or custom domain names for your data warehouse. You might want to use a custom domain name […]

Visualize Amazon DynamoDB insights in Amazon QuickSight using the Amazon Athena DynamoDB connector and AWS Glue
May 2025: This post was reviewed for accuracy. Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for […]

Implement data warehousing solution using dbt on Amazon Redshift
Amazon Redshift is a cloud data warehousing service that provides high-performance analytical processing based on a massively parallel processing (MPP) architecture. Building and maintaining data pipelines is a common challenge for all enterprises. Managing the SQL files, integrating cross-team work, incorporating all software engineering principles, and importing external utilities can be a time-consuming task that […]

Decentralize LF-tag management with AWS Lake Formation
In today’s data-driven world, organizations face unprecedented challenges in managing and extracting valuable insights from their ever-expanding data ecosystems. As the number of data assets and users grow, the traditional approaches to data management and governance are no longer sufficient. Customers are now building more advanced architectures to decentralize permissions management to allow for individual […]
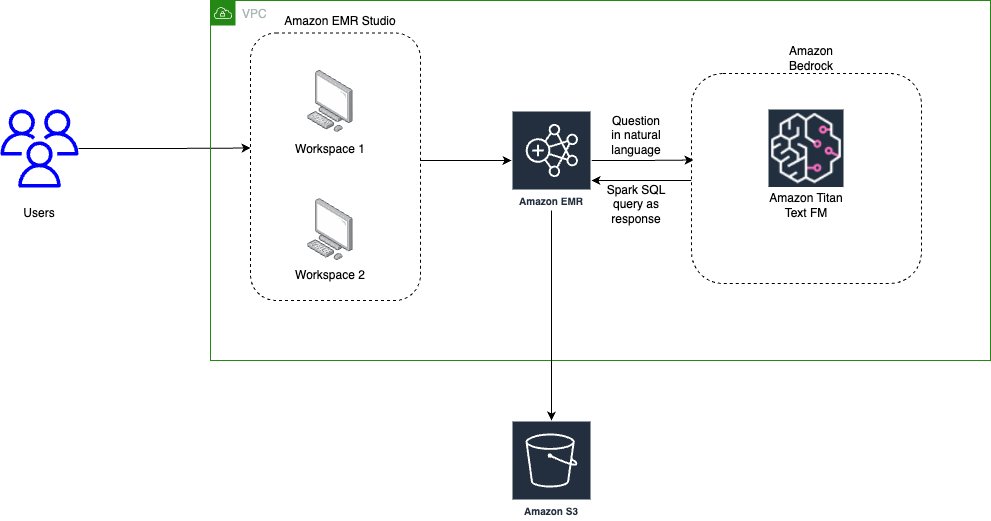
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]

Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case […]
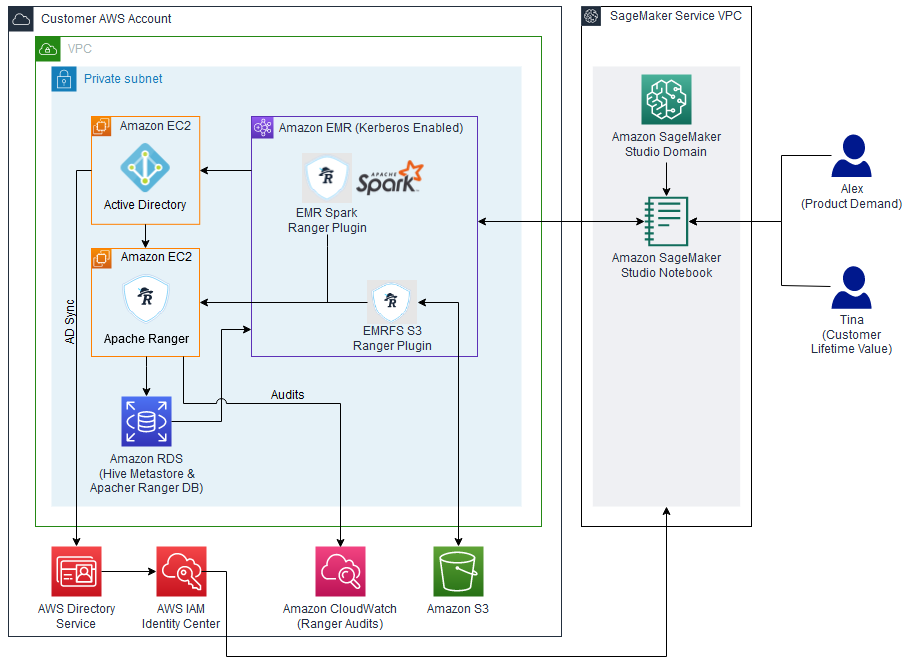
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.