AWS Big Data Blog
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
Amazon Redshift is a data warehouse service that logs the history of the system in STL log tables. The STL log tables manage disk space by retaining only two to five days of log history, depending on log usage and available disk space.
Amazon Redshift provides an automatic logging of some STL tables to S3 for audit data. The included logs are primarily those concerned with DB security and queries run. Usage of these audit logs was described in the previous post, Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum.
If you want to retain system data from STL tables’ data not included in the audit logging, you usually have to create a replica table for every system table. Then, for each you load the data from the system table into the replica at regular intervals. By maintaining replica tables for STL tables, you can run diagnostic queries on historical data from the STL tables. You then can derive insights from query execution times, query plans, and disk-spill patterns, and make better cluster-sizing decisions. However, refreshing replica tables with live data from STL tables at regular intervals requires schedulers such as Cron or AWS Data Pipeline. Also, these tables are specific to one cluster and they are not accessible after the cluster is terminated. This is especially true for transient Amazon Redshift clusters that last for only a finite period of ad hoc query execution.
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.
I also provide another CloudFormation template later in this post. This second template helps to automate the creation of tables in the AWS Glue Data Catalog for the system tables’ data stored in Amazon S3. After the system tables are exported to Amazon S3, you can run cross-cluster diagnostic queries on the system tables’ data and derive insights about query executions in each Amazon Redshift cluster. You can do this using Amazon QuickSight, Amazon Athena, Amazon EMR, or Amazon Redshift Spectrum.
You can find all the code examples in this post, including the CloudFormation templates, AWS Glue extract, transform, and load (ETL) scripts, and the resolution steps for common errors you might encounter in this GitHub repository.
Solution overview
The solution in this post uses AWS Glue to export system tables’ log data from Amazon Redshift clusters into Amazon S3. The AWS Glue ETL jobs are invoked at a scheduled interval by AWS Lambda. AWS Systems Manager, which provides secure, hierarchical storage for configuration data management and secrets management, maintains the details of Amazon Redshift clusters for which the solution is enabled. The last-fetched time stamp values for the respective cluster-table combination are maintained in an Amazon DynamoDB table.
The following diagram covers the key steps involved in this solution.
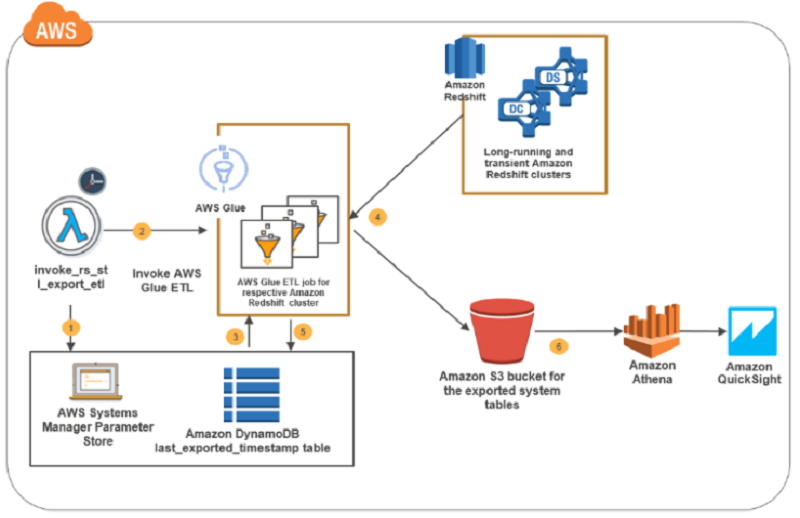
The solution as illustrated in the preceding diagram flows like this:
- The Lambda function, invoke_rs_stl_export_etl, is triggered at regular intervals, as controlled by Amazon CloudWatch. It’s triggered to look up the AWS Systems Manager parameter store to get the details of the Amazon Redshift clusters for which the system table export is enabled.
- The same Lambda function, based on the Amazon Redshift cluster details obtained in step 1, invokes the AWS Glue ETL job designated for the Amazon Redshift cluster. If an ETL job for the cluster is not found, the Lambda function creates one.
- The ETL job invoked for the Amazon Redshift cluster gets the cluster credentials from the parameter store. It gets from the DynamoDB table the last exported time stamp of when each of the system tables was exported from the respective Amazon Redshift cluster.
- The ETL job unloads the system tables’ data from the Amazon Redshift cluster into an Amazon S3 bucket.
- The ETL job updates the DynamoDB table with the last exported time stamp value for each system table exported from the Amazon Redshift cluster.
- The Amazon Redshift cluster system tables’ data is available in Amazon S3 and is partitioned by cluster name and date for running cross-cluster diagnostic queries.
Understanding the configuration data
This solution uses AWS Systems Manager parameter store to store the Amazon Redshift cluster credentials securely. The parameter store also securely stores other configuration information that the AWS Glue ETL job needs for extracting and storing system tables’ data in Amazon S3. Systems Manager comes with a default AWS Key Management Service (AWS KMS) key that it uses to encrypt the password component of the Amazon Redshift cluster credentials.
The following table explains the global parameters and cluster-specific parameters required in this solution. The global parameters are defined once and applicable at the overall solution level. The cluster-specific parameters are specific to an Amazon Redshift cluster and repeat for each cluster for which you enable this post’s solution. The CloudFormation template explained later in this post creates these parameters as part of the deployment process.
| Parameter name | Type | Description |
| Global parameters—defined once and applied to all jobs | ||
| redshift_query_logs.global.s3_prefix | String | The Amazon S3 path where the query logs are exported. Under this path, each exported table is partitioned by cluster name and date. |
| redshift_query_logs.global.tempdir | String | The Amazon S3 path that AWS Glue ETL jobs use for temporarily staging the data. |
| redshift_query_logs.global.role> | String | The name of the role that the AWS Glue ETL jobs assume. Just the role name is sufficient. The complete Amazon Resource Name (ARN) is not required. |
| redshift_query_logs.global.enabled_cluster_list | StringList | A comma-separated list of cluster names for which system tables’ data export is enabled. This gives flexibility for a user to exclude certain clusters. |
| Cluster-specific parameters—for each cluster specified in the enabled_cluster_list parameter | ||
| redshift_query_logs.<<cluster_name>>.connection | String | The name of the AWS Glue Data Catalog connection to the Amazon Redshift cluster. For example, if the cluster name is product_warehouse, the entry is redshift_query_logs.product_warehouse.connection. |
| redshift_query_logs.<<cluster_name>>.user | String | The user name that AWS Glue uses to connect to the Amazon Redshift cluster. |
| redshift_query_logs.<<cluster_name>>.password | Secure String | The password that AWS Glue uses to connect the Amazon Redshift cluster’s encrypted-by key that is managed in AWS KMS. |
For example, suppose that you have two Amazon Redshift clusters, product-warehouse and category-management, for which the solution described in this post is enabled. In this case, the parameters shown in the following screenshot are created by the solution deployment CloudFormation template in the AWS Systems Manager parameter store.

Solution deployment
To make it easier for you to get started, I created a CloudFormation template that automatically configures and deploys the solution—only one step is required after deployment.
Prerequisites
To deploy the solution, you must have one or more Amazon Redshift clusters in a private subnet. This subnet must have a network address translation (NAT) gateway or a NAT instance configured, and also a security group with a self-referencing inbound rule for all TCP ports. For more information about why AWS Glue ETL needs the configuration it does, described previously, see Connecting to a JDBC Data Store in a VPC in the AWS Glue documentation.
To start the deployment, launch the CloudFormation template:
![]()
CloudFormation stack parameters
The following table lists and describes the parameters for deploying the solution to export query logs from multiple Amazon Redshift clusters.
| Property | Default | Description |
| S3Bucket | mybucket | The bucket this solution uses to store the exported query logs, stage code artifacts, and perform unloads from Amazon Redshift. For example, the mybucket/extract_rs_logs/data bucket is used for storing all the exported query logs for each system table partitioned by the cluster. The mybucket/extract_rs_logs/temp/ bucket is used for temporarily staging the unloaded data from Amazon Redshift. The mybucket/extract_rs_logs/code bucket is used for storing all the code artifacts required for Lambda and the AWS Glue ETL jobs. |
| ExportEnabledRedshiftClusters | Requires Input | A comma-separated list of cluster names from which the system table logs need to be exported. |
| DataStoreSecurityGroups | Requires Input | A list of security groups with an inbound rule to the Amazon Redshift clusters provided in the parameter, ExportEnabledClusters. These security groups should also have a self-referencing inbound rule on all TCP ports, as explained on Connecting to a JDBC Data Store in a VPC. |
After you launch the template and create the stack, you see that the following resources have been created:
- AWS Glue connections for each Amazon Redshift cluster you provided in the CloudFormation stack parameter, ExportEnabledRedshiftClusters.
- All parameters required for this solution created in the parameter store.
- The Lambda function that invokes the AWS Glue ETL jobs for each configured Amazon Redshift cluster at a regular interval of five minutes.
- The DynamoDB table that captures the last exported time stamps for each exported cluster-table combination.
- The AWS Glue ETL jobs to export query logs from each Amazon Redshift cluster provided in the CloudFormation stack parameter, ExportEnabledRedshiftClusters.
- The IAM roles and policies required for the Lambda function and AWS Glue ETL jobs.
After the deployment
For each Amazon Redshift cluster for which you enabled the solution through the CloudFormation stack parameter, ExportEnabledRedshiftClusters, the automated deployment includes temporary credentials that you must update after the deployment:
- Go to the parameter store.
- Note the parameters <<cluster_name>>.user and redshift_query_logs.<<cluster_name>>.password that correspond to each Amazon Redshift cluster for which you enabled this solution. Edit these parameters to replace the placeholder values with the right credentials.
For example, if product-warehouse is one of the clusters for which you enabled system table export, you edit these two parameters with the right user name and password and choose Save parameter.


Querying the exported system tables
Within a few minutes after the solution deployment, you should see Amazon Redshift query logs being exported to the Amazon S3 location, <<S3Bucket_you_provided>>/extract_redshift_query_logs/data/. In that bucket, you should see the eight system tables partitioned by customer name and date: stl_alert_event_log, stl_dlltext, stl_explain, stl_query, stl_querytext, stl_scan, stl_utilitytext, and stl_wlm_query.

To run cross-cluster diagnostic queries on the exported system tables, create external tables in the AWS Glue Data Catalog. To make it easier for you to get started, I provide a CloudFormation template that creates an AWS Glue crawler, which crawls the exported system tables stored in Amazon S3 and builds the external tables in the AWS Glue Data Catalog.
![]()
Launch this CloudFormation template to create external tables that correspond to the Amazon Redshift system tables. S3Bucket is the only input parameter required for this stack deployment. Provide the same Amazon S3 bucket name where the system tables’ data is being exported. After you successfully create the stack, you can see the eight tables in the database, redshift_query_logs_db, as shown in the following screenshot.

Now, navigate to the Athena console to run cross-cluster diagnostic queries. The following screenshot shows a diagnostic query executed in Athena that retrieves query alerts logged across multiple Amazon Redshift clusters.

You can also query the same AWS Glue Data Catalog external tables from Redshift Spectrum on one of your existing clusters.
You can build the following example Amazon QuickSight dashboard by running cross-cluster diagnostic queries on Athena to identify the hourly query count and the key query alert events across multiple Amazon Redshift clusters.

How to extend the solution
You can extend this post’s solution in two ways:
- Add any new Amazon Redshift clusters that you spin up after you deploy the solution.
- Add other system tables or custom query results to the list of exports from an Amazon Redshift cluster.
Extend the solution to other Amazon Redshift clusters
To extend the solution to more Amazon Redshift clusters, add the three cluster-specific parameters in the AWS Systems Manager parameter store following the guidelines earlier in this post. Modify the redshift_query_logs.global.enabled_cluster_list parameter to append the new cluster to the comma-separated string.
Extend the solution to add other tables or custom queries to an Amazon Redshift cluster
The current solution ships with the export functionality for the following Amazon Redshift system tables:
- stl_alert_event_log
- stl_dlltext
- stl_explain
- stl_query
- stl_querytext
- stl_scan
- stl_utilitytext
- stl_wlm_query
You can easily add another system table or custom query by adding a few lines of code to the AWS Glue ETL job, <<cluster-name>_extract_rs_query_logs. For example, suppose that from the product-warehouse Amazon Redshift cluster you want to export orders greater than $2,000. To do so, add the following five lines of code to the AWS Glue ETL job product-warehouse_extract_rs_query_logs, where product-warehouse is your cluster name:
- Get the last-processed time-stamp value. The function creates a value if it doesn’t already exist.
salesLastProcessTSValue = functions.getLastProcessedTSValue(trackingEntry=”mydb.sales_2000",job_configs=job_configs)
- Run the custom query with the time stamp.
returnDF=functions.runQuery(query="select * from sales s join order o where o.order_amnt > 2000 and sale_timestamp > '{}'".format (salesLastProcessTSValue) ,tableName="mydb.sales_2000",job_configs=job_configs)
- Save the results to Amazon S3.
functions.saveToS3(dataframe=returnDF,s3Prefix=s3Prefix,tableName="mydb.sales_2000",partitionColumns=["sale_date"],job_configs=job_configs)
- Get the latest time-stamp value from the returned data frame in Step 2.
latestTimestampVal=functions.getMaxValue(returnDF,"sale_timestamp",job_configs)
- Update the last-processed time-stamp value in the DynamoDB table.
functions.updateLastProcessedTSValue(“mydb.sales_2000",latestTimestampVal[0],job_configs)
Conclusion
In this post, I demonstrate a serverless solution to retain the system tables’ log data across multiple Amazon Redshift clusters. By using this solution, you can incrementally export the data from system tables into Amazon S3. By performing this export, you can build cross-cluster diagnostic queries, build audit dashboards, and derive insights into capacity planning by using services such as Athena. I also demonstrate how you can extend this solution to other ad hoc query use cases or tables other than system tables by adding a few lines of code.
Additional Reading
If you found this post useful, be sure to check out Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production and Amazon Redshift – 2017 Recap.

About the Author
 Karthik Sonti is a senior big data architect at Amazon Web Services. He helps AWS customers build big data and analytical solutions and provides guidance on architecture and best practices.
Karthik Sonti is a senior big data architect at Amazon Web Services. He helps AWS customers build big data and analytical solutions and provides guidance on architecture and best practices.