AWS Executive in Residence Blog
The Fast and the Furious: How the Evolution of Cloud Computing Is Accelerating Builder Velocity

© Ozzy Delaney https://www.flickr.com/photos/24931020@N02/15854782234
In my role as Head of Enterprise Strategy for AWS, I have a lot to be grateful for. After having led a large-scale business transformation using the cloud as the CIO of Dow Jones, I now have a front-row seat to watch some of the largest companies in the world (News Corp, Capital One, GE) transform their business using the cloud. This seat affords me the opportunity to learn from some of the brightest and most innovative minds in the industry — both from our customers and from within AWS. As often happens in life, I sometimes run into ideas from others that “if I only knew then,” I would have done things a lot differently. One such set of ideas was recently gifted to me by Ilya Epshteyn, one of AWS’ well-tenured Solution Architects. More below…….
***
In a world of unprecedented market disruption, where barriers to entry are crumbling and a great user experience means more than a hundred-year-old brand name, CEOs are coming to expect a different conversation with IT. CIOs and CTOs are trying to change the conversation from that of an IT Supplier to that of a Business Partner. An IT Supplier conversation (Business waiting on IT) sounds familiar: “when will the infrastructure be ready, when will you deliver X capability, how can you reduce my budget by X?” By contrast, a Business Partner conversation (IT waits on Business) sounds very different: “feel free to start building what you need when you need to by provisioning on demand; here is a new security API you can leverage; here are the results of a pilot we ran; and by the way, we cut your costs by X this month.” The latter is initiated by IT with a single goal in mind: bringing products to market. And accelerating innovation and product development hinges on increasing the velocity of your builders.
To make this happen, IT needs to focus on the tasks that differentiate the business and enable builders to move faster. IT tasks that do not differentiate the business should be automated and offloaded to a platform that provides as much of that functionality as possible out-of-the-box. This paradigm shift requires a transformation, and, as Stephen often points out, it’s often more about the people and your organization than the underlying technology. For many of our customers, this is a multi-year journey, one that began long before cloud came along — whether they realize it or not.
Pre-Virtualization Era
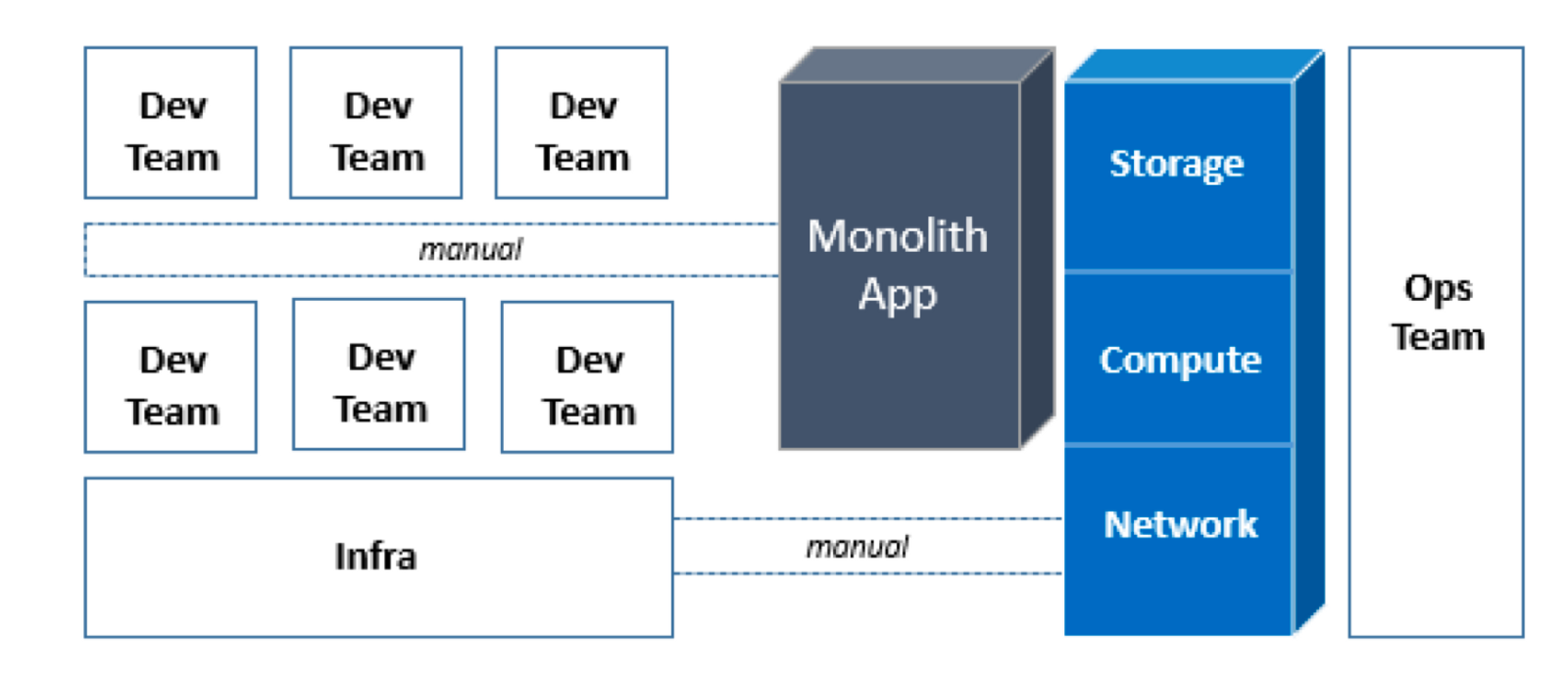
In the pre-virtualization era, infrastructure deployment was manual. Infrastructure took months to be provisioned, racked, stacked, wired, installed, and configured. Most applications were monolithic, with tight inter-dependencies and manual deployment. Installation and configuration guides commonly ran dozens, if not hundreds, of pages long. Data center efficiency was also a challenge. With such long provisioning cycles, businesses would often provision 25–40% more than what was needed during peak usage. With so much wasted capacity, utilization rates were often less than 10%. In this model, the development, infrastructure and operations teams all operated in silos, requiring weeks or months of planning for every change. Operations itself became a major challenge since everything was managed and operated manually, with little standardization across environments.
Promises of Virtualization / Private Cloud
Virtualization and private cloud promised a better way. They sought to improve server efficiency, shrink infrastructure footprint, enable automation and new service delivery models, and, most importantly, bring agility to business.

In reality, while server virtualization had positive impacts on power and cooling consumption and even allowed organizations to consolidate and/or rationalize some data centers, many of the promised benefits have not been fully achieved. Server provisioning time has decreased and servers can often be spun up in minutes, but the reality is that provisioning and capacity planning has not significantly improved. Builders are still forced to procure capacity required for peak based on anticipated (and elusive) usage patterns of their product. In some cases, builders then have to double that to accommodate for disaster recovery (DR, or n-1) scenarios. Business cases to spread this across multiple business units are developed 3–5 years out to justify the capital expenditure, and in most cases we’ve found that they don’t end up paying off.
The infrastructure teams have started to take advantage of the automation that virtualization enables, but for the most part this capability has not been extended to the development teams. “Self-service” delivery models are still mostly manual, often requiring days or weeks of approvals using limited automation. Changes are hard since teams are still operating in silos, and orchestrating changes across these silos often comes with a lot of bureaucratic overhead that is rarely managed well. Ultimately, very little has been achieved in terms of builder velocity. Builders are still frustrated by limited automation, which impacts their productivity. It still takes too long to get things done for the business.
The good news is that organizations that have taken steps to virtualize their environments or pursue a private cloud strategy are able to move to the next phase of this evolution at a faster pace than customers that have not already made that shift. Virtualization not only simplifies the actual migration of VMs, but it’s also a reflection of an organization’s ability to transform, adapt to business needs, and upskill its IT workforce.
Journey to the Cloud
Completing the shift to the cloud helps customers realize the unfulfilled promises of virtualization. The on-demand provisioning of network, compute, storage, database, and other resources in a pay-as-you-go model provides unprecedented agility and helps accelerate the velocity of the development teams. But even in the cloud, this transformation is not instantaneous. Rather, the velocity of the development teams accelerates as the customer journeys through various stages of adoption.

Cloud Adoption — Project Through Migration Stages

During the first three stages of cloud adoption, where organizations 1) start with a few projects to learn the benefits, 2) lay the foundation for organizational transformation through a cloud center of excellence (CCoE) team, and 3) execute mass migrations, we start to see realization of several key factors that directly accelerate the velocity of your builders.
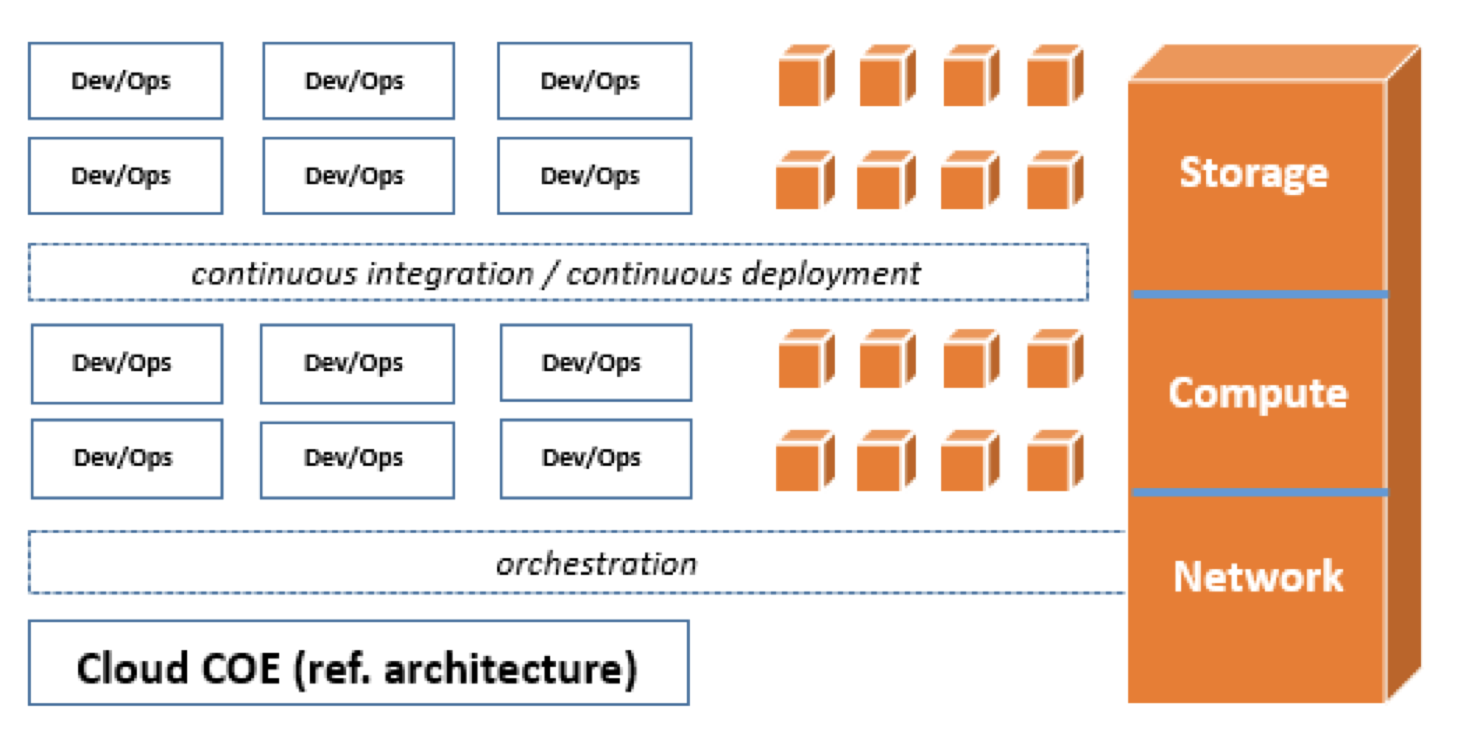
- Infrastructure as Code: early in the Project stage, customers may do certain things manually. As they move to Foundation and Migration stages, however, they embrace Infrastructure as Code. This means that all infrastructure is not simply automated with scripts, but is developed and maintained as code (i.e. CloudFormation). These templates can be reused to deploy entire environments and stacks within minutes.
- Cloud COE: the Cloud COE team develops and maintains the core infrastructure templates, designs reference architectures, educates the dev teams and helps them migrate applications to the cloud. The development teams leverage infrastructure as code pipelines and are starting to develop continuous integration pipelines for their applications.
- Adoption of AWS Services: during these early stages, we see a high degree of adoption of AWS foundational services, including Amazon Elastic Compute Cloud (EC2), Amazon Elastic Block Store (EBS), Amazon Elastic Load Balancing (ELB), Amazon Simple Storage Service (S3), AWS Identity and Access Management (IAM), AWS Key Management Service (KMS), AWS CloudFormation, and Amazon CloudWatch. Customers are also starting to decouple their monolithic applications and take advantage of AWS managed services when possible. The degree of adoption of higher level services at these stages usually depends on the customer’s migration strategy and what percentage of applications is cloud native and what percentage is being re-hosted, re-platformed, or re-factored to take advantage of the full breadth of the AWS platform.
- Security: although security can traditionally be a big obstacle to agility, when implemented properly in AWS it can bring a level of transparency, auditability, and automation far greater than what can be achieved on premise.
Cloud Adoption — Reinvention Phase
There is no doubt that the velocity of the dev teams is greatly improved once the customer moves through the initial stages of adoption. But in most cases, the opportunity to optimize does not end with the Migration stage. Rarely do customers have the opportunity or resources to re-architect all of their applications to be cloud native as part of the migration (see Cloud-Native vs. Lift-and-Shift). This creates an opportunity for constant reinvention to further accelerate builder velocity. Re-architecting the applications often entails decoupling and decomposing the monolith into smaller services with APIs while maximizing reusability. As part of this process, customers are looking to offload the undifferentiated portions of the application to the AWS platform and laser focus on the business logic instead.
During the Reinvention phase, organizations typically opt for more fully managed services such as Amazon Kinesis for ingestion of data, AWS Lambda for real time processing, Amazon Aurora and Amazon DynamoDB for relational and NoSQL databases, and Amazon Redshift for data warehousing, so that builders can spend maximum amount of time on the business differentiators. Developing the best queuing, messaging or API management solution is unlikely to move the needle for your business. Rather, it’s your algorithms, business workflows, and real time analytics that will delight your customers and help grow your business. At this stage, we also see a more focused effort to transform Operations to a true DevOps model. The Cloud COE also focuses more on developing reference architectures, governance, and compliance frameworks and allowing the development team more autonomy to deploy both infrastructure and applications through a unified CI/CD pipeline. And the security teams are accelerating their velocity by embracing DevSecOps methodologies and exposing security capabilities via APIs.
Evolution of Compute and Big Data
To put this into perspective, let’s look at how this evolution has played out in the areas of compute and big data in the cloud.
The first major compute evolution in recent times was from physical servers to virtual servers in data centers. This stage brought about higher utilization, uniformed environments, hardware independence, and new DR capabilities. The next phase was virtual servers in the cloud. This brought about on-demand resources, greater scalability and agility, and improved availability and fault tolerance. But from a builder velocity perspective, there is still room for improvement. You still need to worry about high availability and DR, need to manage golden images and patch the servers, and need to right size the instances to your workload. From a builder perspective, all you want to do is focus on the business logic and have it run on schedule or in response to an event.
This is where AWS Lambda and the transition to serverless computing come in. With AWS Lambda, there are no servers to manage or patch. The builder simply writes his or her function while the Lambda service automatically manages execution, high availability, and scalability. VidRoll, for example, uses AWS Lambda to power its business logic for real time ad bidding and to transcode videos in real time. With Lambda, VidRoll can have 2–3 engineers doing the work of 8–10 engineers, a direct result of code reusability and not having to understand or worry about the infrastructure.
Another similar example is in the evolution of big data services on AWS. Customers may run a self-managed Hadoop cluster on EC2 and EBS. In fact, they may see some initial benefits in terms of on-demand provision of resources, pay-as-you-go model, many different instance types, and more. But many of the challenges with such architectures on premise may continue to persist in the cloud. For example, because of the coupled nature of compute and storage, your cluster will be over-utilized during peak hours and underutilized at other times. You can’t shut down the cluster easily during off peak since you need to persist the data in HDFS, and you constantly need to move large amounts of data to local HDFS before you can even run a query.
Amazon EMR addresses these issues by decoupling your compute and storage and leveraging S3 as your persisted data lake. FINRA, for example, is able to launch a new HBase cluster on EMR and accept queries in less than 30 minutes because the data stays on S3, as compared to two days on FINRA’s self-managed EC2 cluster. Leveraging S3 for data storage has also reduced FINRA’s cost and enabled FINRA to right-size the cluster for the workload. The builders and data engineers are also no longer locked into long-term technology decisions, but can evolve the analytics platform and experiment with new tools as business demands. And what if the data scientists don’t want to manage any cluster at all? Amazon Athena offers a completely Serverless option. With zero spin time and transparent upgrades, the data scientist can simply write an SQL query and have Presto engine execute it immediately.
With any transformation, it can be hard to know how to measure success and keep the end goal in sight. Focusing on the velocity of your dev teams provides a great yardstick for cloud success, and can help guide your decisions as you become a Business Partner and continue to evolve and reinvent with AWS.