Artificial Intelligence
Build a multi-lingual document translation workflow with domain-specific and language-specific customization
In the digital world, providing information in a local language isn’t novel, but it can be a tedious and expensive task. Advancements in machine learning (ML) and natural language processing (NLP) have made this task much easier and less expensive.
We have seen increased adoption of ML for multi-lingual data and document processing workloads. Enterprise and government customers are migrating their manual translation workloads to take advantage of automated ML translation services. Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation between several thousand language pairings that can be used for synchronous (real-time) or asynchronous translation tasks. For a complete list of available translation pairs, refer to Supported languages and language codes.
Customers migrating and modernizing their translation workloads need the ability to customize translations for their business domain. A translation workload may also need the ability to adapt to regional language dialects or usage. For example, the Spanish translation of “elderly” is anciano(a) but in Puerto Rico the word envejeciente is preferred.
In this post, we demonstrate how to incorporate Amazon Translate’s Active Custom Translation (ACT) feature. We propose a solution to create a multi-lingual document translation workflow with domain- and language-specific customizations that you can review and augment as needed to continuously improve results and delight end-users.
Solution overview
ACT produces custom-translated output without the need to build and maintain a custom translation model. Using ACT, Amazon Translate will use your preferred translation examples as parallel data to customize your translation result, eliminating the time and cost of required to build and train a new machine learning model.
The solution covered in this post explains how to create a human-in-the-loop workflow using Amazon Augmented AI (Amazon A2I) to continuously improve the customized translation. Amazon A2I provides a simple way to integrate human oversight into your ML workflows, with no ML experience required. Amazon A2I makes it straightforward to integrate human judgement and AI into any ML application, regardless of whether it’s run on AWS or on another platform.
For more information refer to Designing human review workflows with Amazon Translate and Amazon Augmented AI post.
The following diagram displays the command flow and data flow of the solution. The command flow shows the logical sequence of events in the workflow. A data flow indicates how data is being created or used by various components in the solution.

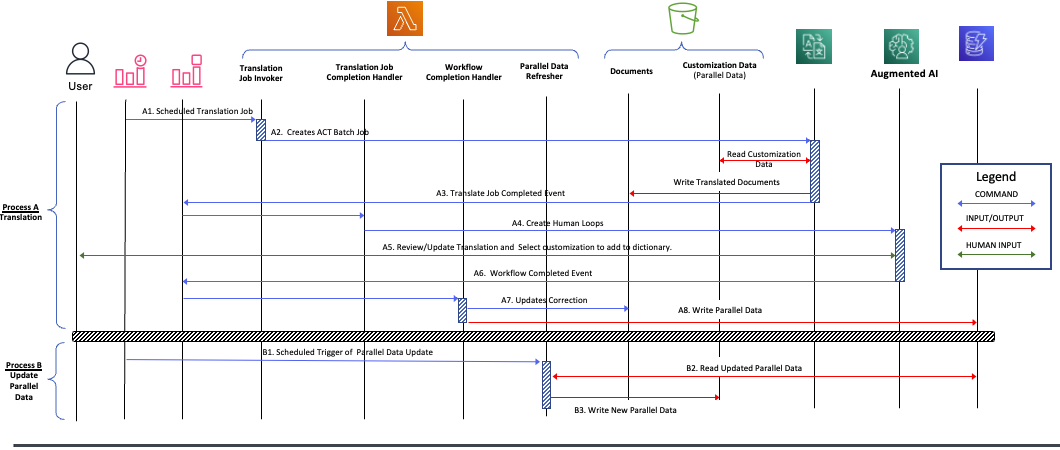
The following sequence diagram shows two separate processes in the solution: the translation workflow (A) and the process to update parallel data (B).
The translation workflow is initiated by an Amazon CloudWatch scheduled event which starts the Translation Job Invoker AWS Lambda function. This function creates an asynchronous translation job in Amazon Translate, passing along the document to translate and the location of the parallel data to customize the translation. The translation job reads the parallel data, performs the translation, and writes the translated result back to an Amazon S3 bucket. As of this writing, only asynchronous translation jobs can use parallel data.
When the translation job is complete, an event is generated that triggers the Translation Job Completion Handler Lambda function. This function creates a human workflow loop—the main component of the Amazon A2I portion of the workflow.
Human reviewers assess the translation and accept or modify the translation. Any corrections are used to update the translated document and also added to a customization dictionary. When the review is finalized, another event is generated to trigger the Workflow Completion Handler function. This function writes the latest translated document back to Amazon S3. The customization data is used to update an Amazon DynamoDB table with the source and translated text pairs.
To close the loop, we must incorporate this customization data stored in DynamoDB back into the parallel data stored in Amazon S3. To accomplish this, we use a scheduled CloudWatch event to trigger the Parallel Data Refresher function, which reads the data from the DynamoDB table, reformats it as parallel data, and updates the S3 bucket, storing the parallel data.
Deploy the solution with AWS CloudFormation
Launch the provided AWS CloudFormation template to deploy the solution in your account. This stack only works in the us-east-1 Region. If you want to deploy this solution in other Regions, refer to the following GitHub repo.
- Choose Launch Stack:

- Follow the instructions to populate the necessary parameters. If you’re running this stack for the first time, SNS Email is the only required parameter.
- On the Review page, in the Capabilities section, select the check box and choose Create stack.
The stack creates the following key components:
- Customization data – A DynamoDB table (
translate_parallel_data) to maintain the customization data. You migrate the existing customization data to this table. This table is used to continuously add and update customizations. - Parallel Data Refresher – The Lambda function to convert the customization data in the DynamoDB table to a parallel data format—CSV, TSV, or TMX—and store it in Amazon S3. It creates and updates parallel data with the new parallel data file in Amazon S3.
- Translation Job Invoker – The Lambda function to start the Amazon Translate batch job with parallel data.
- Translation Job Completion Handler – This Lambda function is triggered when the Amazon Translate batch job is complete. The function creates one human loop per document (we’ll refine this in the future to create a human loop only for a select percentage of documents processed). It uses the original and translated documents to create the human loop.
- Amazon A2I customized template – This template is used to render the translation pair for human review. The template has the Add option for every translation segment. Users can select this option to add the corrections to the customization data. The new customization data is used in the next batch translation job.
- Workflow Completion Handler – This Lambda function is triggered when the human workflow is complete. The function updates the translated document with corrections and checks for parallel data updates. New parallel data is added to the DynamoDB table.
- Amazon A2I private team – An Amazon A2I private team is created with a human worker using the email provided. Initial credentials are emailed upon successful creation of the private team. You use this email and credential to log in to the Amazon A2I worker portal.
Test the solution
The sample_text.txt file would have been created under the input prefix of the S3 bucket created by the stack. We use this file for our testing. It contains the following content:
To test the solution, complete the following steps:
- Invoke the Translation Job Invoker function manually, or wait for it to be triggered by CloudWatch based on the cron schedule you specified.
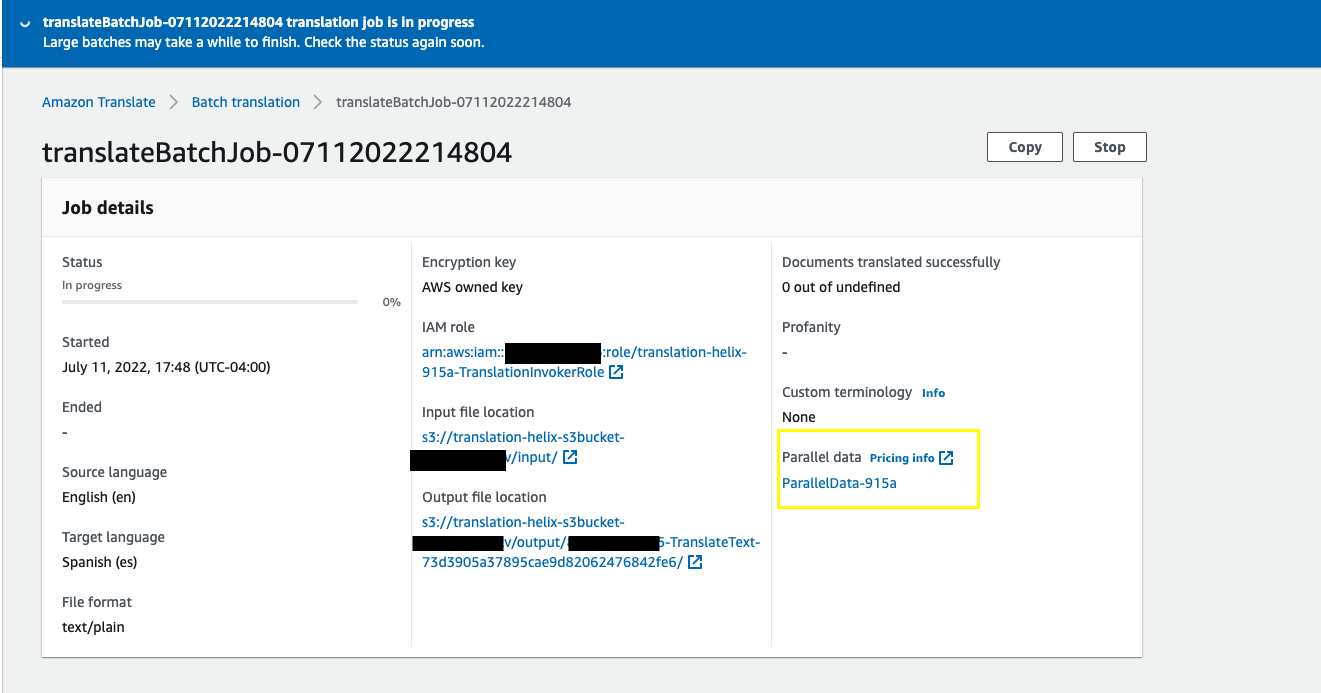
This function triggers the Amazon Translate batch job. You can observe the progress of the job on the Amazon Translate console.
 This batch job takes approximately 30 minutes to complete. When it’s complete, the
This batch job takes approximately 30 minutes to complete. When it’s complete, the TextTranslationJobstate change event triggers the Translation Job Completion Handler function. This function creates one human loop per translated document. - Navigate to the Amazon A2I workforces page.
- Choose the Private tab.

- Log in to the Amazon A2I worker portal by choosing the link for Labelling portal sign-in URL.
- Select the task
Human review taskin the jobs list. - Choose Start working.

You can see the following page displayed.

- Follow the instructions to make domain- and language-specific corrections.
In the preceding screenshot, the phrase “The use of health status in any group health insurance policy is prohibited by law” has been translated to “La ley prohíbe el uso del estado de salud en cualquier póliza de seguro médico de grupo.” Although the translation is accurate, the phrases have been rearranged. - Let’s modify this to “El uso del estado de salud en cualquier póliza de seguro de salud grupal está prohibido por ley” to make this a more direct translation reflecting the original phraseology.
- Select Add to add this to the dictionary.
- When you’re done, choose Submit.

This triggers the Workflow Completion Handler function, and the customization data is updated in the DynamoDB table. The function also stores the corrected translation under the post-edits prefix.
You can observe the customizations being added to translate_parallel_data table on the DynamoDB console.

Command flow
The Parallel Data Refresher function is triggered every hour by a CloudWatch scheduled event. This function checks for new updates in the translate_parallel_data table, creates a new parallel data TMX file in Amazon S3 under the parallel_data prefix, and updates the Amazon Translate parallel data component. You can trigger this function manually if you don’t want to wait for the scheduled event trigger.
You can observe the parallel data being updated on the Amazon Translate console.
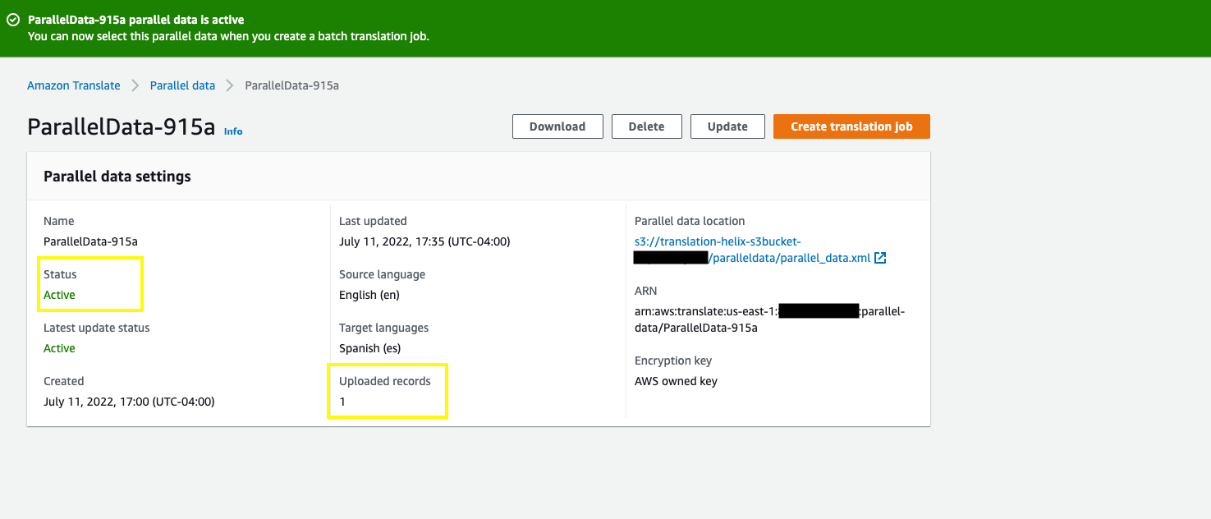
When it’s complete, the job status should be Active and the value for Updated records should reflect the number of customizations you added (in this case 1).
Now we can run the translation job again with the updated data. Trigger the Translation Job Invoker function again to observe the customization being added to the translation in the second iteration. Amazon Translate now uses the parallel data provided to customize the translation.
You can observe the change in the translation output in the labeling portal. Instead of the default translation, we see the customized translation being applied.

This workflow helps create a virtuous cycle to continuously improve translation output using Amazon A2I and Amazon Translate customization features.
Cost
With Amazon Translate and Amazon A2I, you pay as you go based on the number of text characters that you processed and for each human-reviewed object. We use DynamoDB on-demand mode for this example. DynamoDB charges you for the reads and writes performed on your tables. Refer to the pricing pages for Amazon Translate, Amazon A2I, and Amazon DynamoDB for actual costs.
Clean up
When you’re finished experimenting with this solution, clean up your resources by using the AWS CloudFormation console to delete all the resources deployed in this example. This helps you avoid continuing costs in your account.
Conclusion
You can use the solution presented in this post to build a multi-lingual translation workflow that uses and augments domain-specific customization incrementally to continuously improve translation results. We provided a simple mechanism to integrate your existing customization assets with managed AI services like Amazon Translate and Amazon A2I to build a robust translation service for your application. Amazon Translate can help you scale this solution to support over 5,550 translation pairs out of the box. Amazon A2I can help you easily integrate with your in-house linguistic expert or take advantage of an external workforce to scale the solution.
For more information about Amazon Translate, visit Amazon Translate resources to find video resources and blog posts, and refer to AWS Translate FAQs. Please share your thoughts with us in the comments section, or in the issues section of the project’s Github repository.
About the Authors
 Sathya Balakrishnan is a Sr Customer Delivery Architect in the Professional Services team at AWS, specializing in Data/ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr Customer Delivery Architect in the Professional Services team at AWS, specializing in Data/ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Paul W. Joireman is a Sr Customer Delivery Architect in Professional Services at AWS, specializing in Application Migration and working with US federal financial clients. Paul enjoys creating technology solutions, traveling with family and hiking in the Shenandoah National Park, as long as the hike finishes at a local craft brewery.
Paul W. Joireman is a Sr Customer Delivery Architect in Professional Services at AWS, specializing in Application Migration and working with US federal financial clients. Paul enjoys creating technology solutions, traveling with family and hiking in the Shenandoah National Park, as long as the hike finishes at a local craft brewery.