Artificial Intelligence
Developing advanced machine learning systems at Trumid with the Deep Graph Library for Knowledge Embedding
This is a guest post co-written with Mutisya Ndunda from Trumid.
Like many industries, the corporate bond market doesn’t lend itself to a one-size-fits-all approach. It’s vast, liquidity is fragmented, and institutional clients demand solutions tailored to their specific needs. Advances in AI and machine learning (ML) can be employed to improve the customer experience, increase the efficiency and accuracy of operational workflows, and enhance performance by supporting multiple aspects of the trading process.
Trumid is a financial technology company building tomorrow’s credit trading network—a marketplace for efficient trading, information dissemination, and execution between corporate bond market participants. Trumid is optimizing the credit trading experience by combining leading-edge product design and technology principles with deep market expertise. The result is an integrated trading solution delivering a full ecosystem of protocols and execution tools within one intuitive platform.
The bond trading market has traditionally involved offline buyer/seller matching processes aided by rules-based technology. Trumid has embarked on an initiative to transform this experience. Through its electronic trading platform, traders can access thousands of bonds to buy or sell, a community of engaged users to interact with, and a variety of trading protocols and execution solutions. With an expanding network of users, Trumid’s AI and Data Strategy team partnered with the AWS Machine Learning Solutions Lab. The objective was to develop ML systems that could deliver a more personalized trading experience by modeling the interest and preferences of users for bonds available on Trumid.
These ML models can be used to speed up time to insight and action by personalizing how information is displayed to each user to ensure that the most relevant and actionable information a trader may care about is prioritized and accessible.
To solve this challenge, Trumid and the ML Solutions Lab developed an end-to-end data preparation, model training, and inference process based on a deep neural network model built using the Deep Graph Library for Knowledge Embedding (DGL-KE). An end-to-end solution with Amazon SageMaker was also deployed.
Benefits of graph machine learning
Real-world data is complex and interconnected, and often contains network structures. Examples include molecules in nature, social networks, the internet, roadways, and financial trading platforms.
Graphs provide a natural way to model this complexity by extracting important and rich information that is embedded in the relations between entities.
Traditional ML algorithms require data to be organized as tables or sequences. This generally works well, but some domains are more naturally and effectively represented by graphs (such as a network of objects related to each other, as illustrated later in this post). Instead of coercing these graph datasets into tables or sequences, you can use graph ML algorithms to both represent and learn from the data as presented in its graph form, including information about constituent nodes, edges, and other features.
Considering that bond trading is inherently represented as a network of interactions between buyers and sellers involving various types of bond instruments, an effective solution needs to harness the network effects of the communities of traders that participate in the market. Let’s look at how we leveraged the trading network effects and implemented this vision here.
Solution
Bond trading is characterized by several factors, including trade size, term, issuer, rate, coupon values, bid/ask offer, and type of trading protocol involved. In addition to orders and trades, Trumid also captures “indications of interest” (IOIs). The historical interaction data embodies the trading behavior and the market conditions evolving over time. We used this data to build a graph of timestamped interactions between traders, bonds, and issuers, and used graph ML to predict future interactions.
The recommendation solution comprised four main steps:
- Preparing the trading data as a graph dataset
- Training a knowledge graph embedding model
- Predicting new trades
- Packaging the solution as a scalable workflow
In the following sections, we discuss each step in more detail.
Preparing the trading data as a graph dataset
There are many ways to represent trading data as a graph. One option is to represent the data exhaustively with nodes, edges, and properties: traders as nodes with properties (such as employer or tenure), bonds as nodes with properties (issuer, amount outstanding, maturity, rate, coupon value), and trades as edges with properties (date, type, size). Another option is to simplify the data and use only nodes and relations (relations are typed edges like traded or issued-by). This latter approach worked better in our case, and we used the graph represented in the following figure.
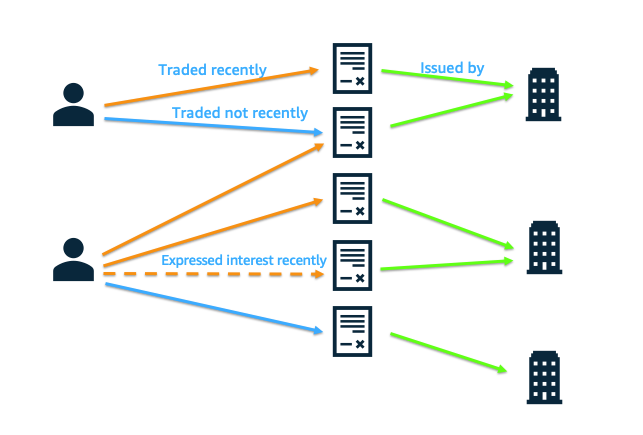
Graph of relations between traders, bonds and bond issuers
Additionally, we removed some of the edges considered obsolete: if a trader interacted with more than 100 different bonds, we kept only the last 100 bonds.
Finally, we saved the graph dataset as a list of edges in TSV format:
Training a knowledge graph embedding model
For graphs composed only of nodes and relations (often called knowledge graphs), the DGL team developed the knowledge graph embedding framework DGL-KE. KE stands for knowledge embedding, the idea being to represent nodes and relations (knowledge) by coordinates (embeddings) and optimize (train) the coordinates so that the original graph structure can be recovered from the coordinates. In the list of available embedding models, we selected TransE (translational embeddings). TransE trains embeddings with the objective of approximating the following equality:
Source node embedding + relation embedding = target node embedding (1)
We trained the model by invoking the dglke_train command. The output of the training is a model folder containing the trained embeddings.
For more details about TransE, refer to Translating Embeddings for Modeling Multi-relational Data.
Predicting new trades
To predict new trades from a trader with our model, we used the equality (1): add the trader embedding to the trade-recent embedding and looked for bonds closest to the resulting embedding.
We did this in two steps:
- Compute scores for all possible trade-recent relations with
dglke_predict. - Compute the top 100 highest scores for each trader.
For detailed instructions on how to use the DGL-KE, refer to Training knowledge graph embeddings at scale with the Deep Graph Library and DGL-KE Documentation.
Packaging the solution as a scalable workflow
We used SageMaker notebooks to develop and debug our code. For production, we wanted to invoke the model as a simple API call. We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing. SageMaker processing allows you to run a script remotely on a chosen instance type and Docker image without having to worry about resource allocation and data transfer. This was simple and cost-effective for us, because the GPU instance is only used and paid for during the 15 minutes needed for the script to run.
For detailed instructions on how to use SageMaker processing, see Amazon SageMaker Processing – Fully Managed Data Processing and Model Evaluation and Processing.
Results
Our custom graph model performed very well compared to other methods: performance improved by 80%, with more stable results across all trader types. We measured performance by mean recall (percentage of actual trades predicted by the recommender, averaged over all traders). With other standard metrics, the improvement ranged from 50–130%.
This performance enabled us to better match traders and bonds, indicating an enhanced trader experience within the model, with machine learning delivering a big step forward from hard-coded rules, which can be difficult to scale.
Conclusion
Trumid is focused on delivering innovative products and workflow efficiencies to their community of users. Building tomorrow’s credit trading network requires continuous collaboration with peers and industry experts like the AWS ML Solutions Lab, designed to help you innovate faster.
For more information, see the following resources:
- For a background on graph ML and use cases, refer to How AWS uses graph neural networks to meet customer needs.
- For more information about graph ML tools, explore DGL-KE, DGL, and Amazon Neptune.
- Deliver product recommendations with Amazon Personalize.
- Collaborate with the AWS Machine Learning Solutions Lab.
About the authors
 Marc van Oudheusden is a Senior Data Scientist with the Amazon ML Solutions Lab team at Amazon Web Services. He works with AWS customers to solve business problems with artificial intelligence and machine learning. Outside of work you may find him at the beach, playing with his children, surfing or kitesurfing.
Marc van Oudheusden is a Senior Data Scientist with the Amazon ML Solutions Lab team at Amazon Web Services. He works with AWS customers to solve business problems with artificial intelligence and machine learning. Outside of work you may find him at the beach, playing with his children, surfing or kitesurfing.
 Mutisya Ndunda is the Head of Data Strategy and AI at Trumid. He is a seasoned financial professional with over 20 years of broad institutional experience in capital markets, trading, and financial technology. Mutisya has a strong quantitative and analytical background with over a decade of experience in artificial intelligence, machine learning and big data analytics. Prior to Trumid, he was the CEO of Alpha Vertex, a financial technology company offering analytical solutions powered by proprietary AI algorithms to financial institutions. Mutisya holds a bachelor’s degree in Electrical Engineering from Cornell University and a master’s degree in Financial Engineering from Cornell University.
Mutisya Ndunda is the Head of Data Strategy and AI at Trumid. He is a seasoned financial professional with over 20 years of broad institutional experience in capital markets, trading, and financial technology. Mutisya has a strong quantitative and analytical background with over a decade of experience in artificial intelligence, machine learning and big data analytics. Prior to Trumid, he was the CEO of Alpha Vertex, a financial technology company offering analytical solutions powered by proprietary AI algorithms to financial institutions. Mutisya holds a bachelor’s degree in Electrical Engineering from Cornell University and a master’s degree in Financial Engineering from Cornell University.
 Isaac Privitera is a Senior Data Scientist at the Amazon Machine Learning Solutions Lab, where he develops bespoke machine learning and deep learning solutions to address customers’ business problems. He works primarily in the computer vision space, focusing on enabling AWS customers with distributed training and active learning.
Isaac Privitera is a Senior Data Scientist at the Amazon Machine Learning Solutions Lab, where he develops bespoke machine learning and deep learning solutions to address customers’ business problems. He works primarily in the computer vision space, focusing on enabling AWS customers with distributed training and active learning.