Artificial Intelligence
Tag: Amazon Machine Learning

Control which domains your AI agents can access
In this post, we show you how to configure AWS Network Firewall to restrict AgentCore resources to an allowlist of approved internet domains. This post focuses on domain-level filtering using SNI inspection — the first layer of a defense-in-depth approach.

Accelerating LLM fine-tuning with unstructured data using SageMaker Unified Studio and S3
Last year, AWS announced an integration between Amazon SageMaker Unified Studio and Amazon S3 general purpose buckets. This integration makes it straightforward for teams to use unstructured data stored in Amazon Simple Storage Service (Amazon S3) for machine learning (ML) and data analytics use cases. In this post, we show how to integrate S3 general purpose buckets with Amazon SageMaker Catalog to fine-tune Llama 3.2 11B Vision Instruct for visual question answering (VQA) using Amazon SageMaker Unified Studio.

Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobs
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Using Strands Agents to create a multi-agent solution with Meta’s Llama 4 and Amazon Bedrock
In this post, we explore how to build a multi-agent video processing workflow using Strands Agents, Meta’s Llama 4 models, and Amazon Bedrock to automatically analyze and understand video content through specialized AI agents working in coordination. To showcase the solution, we will use Amazon SageMaker AI to walk you through the code.

How the Amazon AMET Payments team accelerates test case generation with Strands Agents
In this post, we explain how we overcame the limitations of single-agent AI systems through a human-centric approach, implemented structured outputs to significantly reduce hallucinations and built a scalable solution now positioned for expansion across the AMET QA team and later across other QA teams in International Emerging Stores and Payments (IESP) Org.

Safeguard generative AI applications with Amazon Bedrock Guardrails
In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails.

Applying data loading best practices for ML training with Amazon S3 clients
In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets.
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
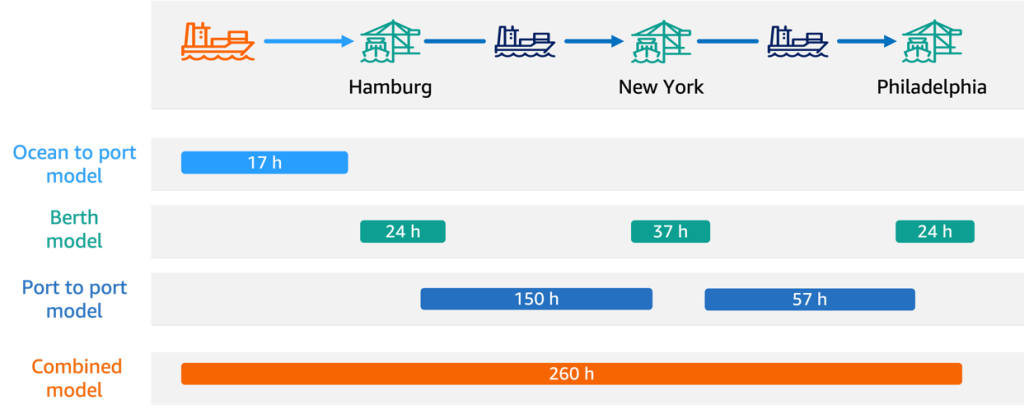
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.