亚马逊AWS官方博客
CyberCRX 如何使用 AWS Step Functions 分布式 Map 将机器学习处理时间从 8 天缩短到 56 分钟
去年 12 月,Sébastien Stormacq 撰写了关于 AWS Step Functions 分布式 Map 状态可用性的文章,这是一项允许您在云中协调大规模并行工作负载的新功能。那时,一家名为 CyberGRX 的公司的数据系统工程师 Charles Burton 发现了这一点并重构了他的工作流,将机器学习(ML)处理作业的处理时间从 8 天缩短到 56 分钟。以前,运行这项作业需要工程师对其进行持续监控;现在,可以在不到一个小时的时间内运行,无需任何支持。此外,使用 AWS Step Functions 分布式 Map 的新实现成本低于其最初的成本。
CyberGRX 通过该解决方案取得的成就完美地说明了无服务器技术所包含的内容:让云尽可能多地完成无差别的繁重工作,这样工程师和数据科学家就有更多时间专注于对业务至关重要的工作。在这种情况下,这意味着继续改进 CyberGRX 其中一个关键产品的模型和流程,CyberGRX 是一家使用来自其庞大且不断增长的数据库中的机器学习洞察对第三方进行网络风险评测的公司。
业务挑战是什么?
CyberGRX 与其客户共享第三方网络风险(TPCRM)数据。该公司满怀信心地预测第三方公司将如何回应风险评测问卷。为此,他们必须对其平台上的每家公司运行预测模型;他们目前拥有超过 22.5 万家公司的预测数据。每当有新公司或公司的数据发生变化时,他们都会通过处理整个数据集来重新生成预测模型。随着时间的推移,CyberGRX 数据科学家会改进模型或向其添加新功能,这也需要重新生成模型。
面临的挑战是如何在实际操作资源尽可能少的情况下,及时为 22.5 万家公司运行这项作业。该作业为每个公司运行一组操作,每家公司的计算都独立于其他公司。这意味着,在理想情况下,可以同时处理每家公司的数据。但是,实现如此大规模的并行化是一个难以解决的问题。
第一次迭代
考虑到这一点,该公司使用 Kubernetes 和 Argo Worksworks 构建了管线的第一次迭代,Argo Worksworks 是一个用于在 Kubernetes 上编排并行作业的开源容器原生工作流引擎。这些是他们熟悉的工具,因为他们已经在其基础设施中使用这些工具。
但是,当他们试图为平台上的所有公司运行这项作业时,他们遇到了其系统能够高效处理的极限。因为该解决方案依赖于集中式控制器 Argo Workflows,所以并不稳健,并且在此期间控制器已扩展到其最大容量。当时,他们只有 15 万家公司。对所有公司运行该作业大约需要 8 天时间,在此期间,系统会崩溃并需要重启。这项工作非常耗费人力,而且总是需要一名待命工程师来监控作业并进行问题排查。
转折点出现在 2022 年初 Charles 加入分析团队时。他的首要任务之一是对当时大约 17 万家公司进行全面的模型运行。模型运行持续了整整一周,于周日凌晨 2:00 结束。那时他切实感觉到他们的系统需要发展。
第二次迭代
Charles 深思熟虑了上次运行模型时的痛苦,他仔细考虑了如何重写工作流。他的第一个想法是使用 AWS Lambda 和 SQS,但他意识到该解决方案中需要一个编排工具。这就是他选择 Step Functions 的原因,这是一项无服务器服务,可帮助您实现流程自动化、编排微服务以及创建数据和机器学习管线;此外,还可以根据需要进行扩展。
Charles 获得了新版本的工作流,Step Functions 在大约 2 周内开始运行。他采取的第一步是调整现有 Docker 映像,使其使用 Lambda 的容器映像打包格式在 Lambda 中运行。由于容器已经可以完成他的数据处理任务,因此这项更新很简单。他调度 Lambda 预置并发,以确保启动作业时所需的所有函数都已准备就绪。他还配置了预留并发,以确保 Lambda 能够一次处理最大并发执行次数。为了支持同时执行这么多函数,他提高了每个账户的 Lambda 并发执行限额。
为了确保步骤并行运行,他使用了 Step Functions 和 Map 状态。Map 状态允许 Charles 为数据集中的每个项目运行一组工作流步骤。迭代是并行运行的。由于 Step Functions Map 状态提供 40 个并发执行,而且 CyberGRX 需要更多并行化,因此他们创建了一个并行启动多个状态机的解决方案;通过这种方式,他们能够在所有公司之间快速迭代。创建这个复杂的解决方案需要一个预处理器来处理系统并发的启发式算法,并将输入数据拆分到多个状态机上。
第二次迭代已经比第一次迭代要好了,因为现在能够毫无问题地完成执行,并且可以在 90 分钟内迭代超过 20 万家公司。但是,预处理器是系统中非常复杂的部分,由于并行化量大,已达到了 Lambda 和 Step Functions API 的极限。

第三次也是最后一次迭代
然后,在 AWS re:Invent 2022 期间,AWS 宣布了 Step Functions 的分布式 Map,这是一种新型的 Map 状态,允许您编写 Step Functions 来协调大规模并行工作负载。使用这项新功能,您可以轻松迭代存储在 Amazon Simple Storage Service(Amazon S3)中的数百万个对象,然后分布式 Map 可以启动多达 1 万个并行子工作流来处理数据。
当 Charles 在新闻博客中读到有关 1 万个并行工作流执行的文章时,他立即想到了尝试这种新状态。在几周内,Charles 构建了工作流的新迭代。
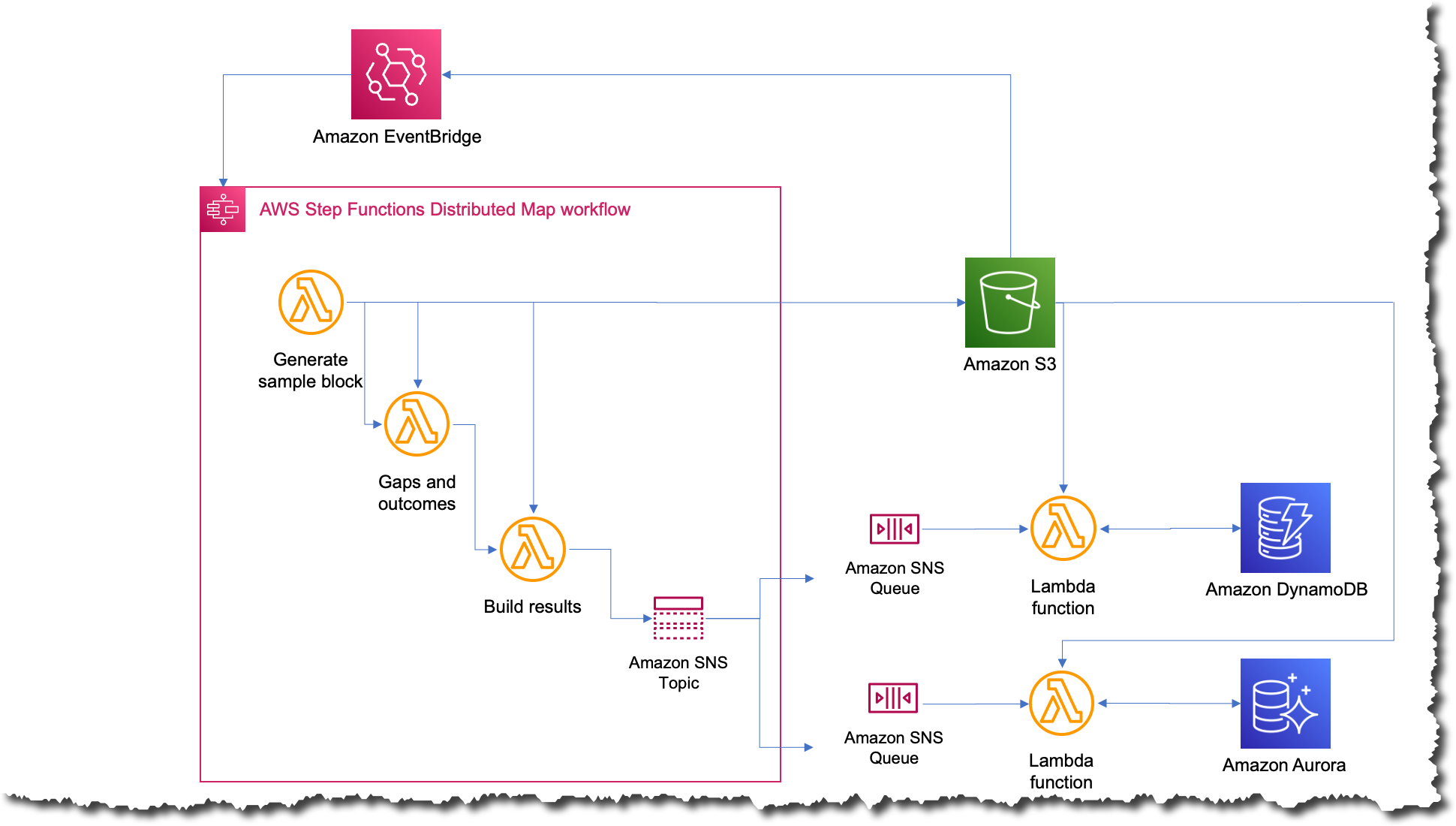
由于分布式 Map 状态将输入拆分为不同的处理器并处理不同执行的并发,因此 Charles 能够删除复杂的预处理器代码。
新流程是有史以来最简单的;现在,每当他们想运行作业时,他们只需将包含输入数据的文件上传到 Amazon S3 即可。此操作触发 Amazon EventBridge 规则,该规则以具有分布式 Map 的状态机为目标。然后,状态机将该文件作为输入执行,并将结果发布到 Amazon Simple Notification Service(Amazon SNS)主题。
产生了什么影响?
在完成第三次迭代几周后,他们不得不对其平台上的所有 22.7 万家公司运行这项作业。作业完成后,Charles 的团队大吃一惊;整个过程只用了 56 分钟就完成了。他们估计,在这 56 分钟内,这项作业进行了超过 570 亿次计算。

下图显示了 Amazon CloudWatch 图形,其中显示了一个 Lambda 函数在工作流运行期间的并行执行情况。在此期间,有将近 1 万个函数并行运行。

简化和缩短工作时间为 CyberGRX 和数据科学团队开拓了很多可能性。当一位数据科学家想要运行这项作业以测试他们对模型所做的一些改进时,效果立竿见影。他们能够独立运行作业,无需工程师的帮助。
而且,由于预测模型本身是 CyberGRX 的其中一项关键产品,因此由于预测分析可以每天进行完善,该公司现在拥有更具竞争力的产品。
了解有关使用 AWS Step Functions 的更多信息:
您还可以查看我们在 Serverless Land 中提供的无服务器工作流集合,供您测试和了解有关这项新功能的更多信息。
– Marcia