Was ist MLOps?
Was ist MLOps?
Machine Learning Operations (MLOps) sind eine Reihe von Praktiken, mit denen Workflows und Bereitstellungen für Machine Learning (ML) automatisiert und vereinfacht werden. Machine Learning und künstliche Intelligenz (KI) sind Kernfunktionen, die Sie implementieren können, um komplexe reale Probleme zu lösen und Ihren Kunden einen Mehrwert zu bieten. MLOps ist eine ML-Kultur und -Praxis, die ML-Anwendungsentwicklung (Dev) mit ML-Systembereitstellung und -betrieb (Ops) vereint. Ihr Unternehmen kann MLOps verwenden, um Prozesse im gesamten ML-Lebenszyklus zu automatisieren und zu standardisieren. Diese Prozesse umfassen Modellentwicklung, Tests, Integration, Veröffentlichung und Infrastrukturverwaltung.
Warum ist MLOps erforderlich?
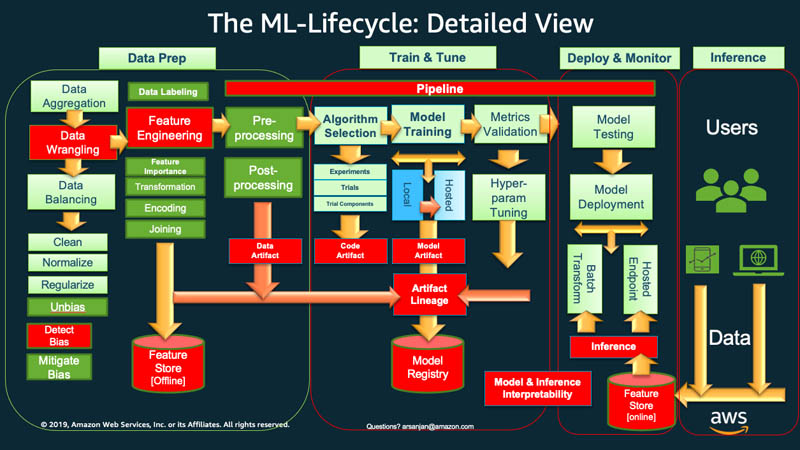
Auf einer höheren Stufee muss Ihr Unternehmen in der Regel mit der Datenaufbereitung beginnen, um den Lebenszyklus des Machine Learning zu beginnen. Sie rufen Daten verschiedener Typen aus verschiedenen Quellen ab und führen Aktivitäten wie Aggregation, Duplikatbereinigung und Feature-Engineering durch.
Danach verwenden Sie die Daten, um das ML-Modell zu trainieren und zu validieren. Anschließend können Sie das trainierte und validierte Modell als Prognosedienst bereitstellen, auf den andere Anwendungen über APIs zugreifen können.
Bei der explorativen Datenanalyse müssen Sie häufig mit verschiedenen Modellen experimentieren, bis die beste Modellversion einsatzbereit ist. Dies führt zu häufigen Bereitstellungen von Modellversionen und Datenversionierung. Die Nachverfolgung von Experimenten und die Verwaltung der ML-Trainingspipeline sind unerlässlich, bevor Ihre Anwendungen das Modell in ihren Code integrieren oder verwenden können.
MLOps ist entscheidend, um die Veröffentlichung neuer ML-Modelle mit Anwendungscode- und Datenänderungen systematisch und gleichzeitig zu verwalten. Eine optimale MLOps-Implementierung behandelt die ML-Assets ähnlich wie andere Softwareressourcen für Continuous-Integration-and-Delivery-Umgebungen (CI/CD). Sie stellen ML-Modelle zusammen mit den Anwendungen und Diensten, die sie verwenden, und denen, die sie nutzen, als Teil eines einheitlichen Release-Prozesses bereit.
Was sind die Grundsätze von MLOps?
Als Nächstes erklären wir vier Hauptprinzipien von MLOps.
Versionskontrolle
Dieser Prozess beinhaltet die Verfolgung von Änderungen in den Machine Learning-Assets, damit Sie die Ergebnisse reproduzieren und bei Bedarf zu früheren Versionen zurückkehren können. Jeder ML-Trainingscode oder jede Modellspezifikation durchläuft eine Code-Review-Phase. Jedes Modell ist versioniert, um das Training von ML-Modellen reproduzierbar und überprüfbar zu machen.
Die Reproduzierbarkeit in einem ML-Workflow ist in jeder Phase wichtig, von der Datenverarbeitung bis zur Bereitstellung von ML-Modellen. Das bedeutet, dass jede Phase bei gleichem Input zu identischen Ergebnissen führen sollte.
Automatisierung
Automatisieren Sie verschiedene Phasen in der Machine-Learning-Pipeline, um Wiederholbarkeit, Konsistenz und Skalierbarkeit zu gewährleisten. Dies umfasst Phasen von der Datenaufnahme über die Vorverarbeitung, das Modelltraining und die Validierung bis hin zur Bereitstellung.
Dies sind einige Faktoren, die das automatisierte Training und die Bereitstellung von Modellen auslösen können:
- Messaging
- Überwachung oder Kalenderereignisse
- Änderungen der Daten
- Änderungen am Modelltrainingscode
- Änderungen des Anwendungscodes.
Automatisierte Tests helfen Ihnen, Probleme frühzeitig zu erkennen, um Fehler schnell zu beheben und daraus Erkenntnisse zu ziehen. Automatisierung ist mit Infrastructure as Code (IaC) effizienter. Sie können Tools verwenden, um die Infrastruktur zu definieren und zu verwalten. Dadurch wird sichergestellt, dass sie reproduzierbar ist und konsistent in verschiedenen Umgebungen eingesetzt werden kann.
Kontinuierliches X
Durch Automatisierung können Sie kontinuierlich Tests ausführen und Code in Ihrer gesamten ML-Pipeline bereitstellen.
In MLOps bezieht sich der Begriff kontinuierlich auf vier Aktivitäten, die kontinuierlich ablaufen, wenn irgendwo im System Änderungen vorgenommen werden:
- Kontinuierliche Integration erweitert die Validierung und das Testen von Code auf Daten und Modelle in der Pipeline
- Kontinuierliche Bereitstellung stellt das neu trainierte Modell oder den Modellvorhersagedienst automatisch bereit
- Durch kontinuierliches Training werden ML-Modelle automatisch für den erneuten Einsatz neu geschult
- Die kontinuierliche Überwachung betrifft die Datenüberwachung und die Modellüberwachung anhand von Geschäftskennzahlen.
Modell-Governance
Governance beinhaltet die effiziente Verwaltung aller Aspekte von ML-Systemen. Sie sollten viele Aktivitäten zur Governance durchführen:
- Fördern Sie die enge Zusammenarbeit zwischen Datenwissenschaftlern, Ingenieuren und Geschäftsinteressenten
- Verwenden Sie klare Unterlagen und effektive Kommunikationskanäle, um sicherzustellen, dass alle auf dem Laufenden sind
- Etablieren Sie Mechanismen, um Feedback zu Modellvorhersagen zu sammeln und Modelle weiter zu trainieren
- Stellen Sie sicher, dass sensible Daten geschützt, der Zugriff auf Modelle und Infrastruktur sicher ist und die Compliance-Anforderungen erfüllt werden
Es ist auch wichtig, über einen strukturierten Prozess zur Überprüfung, Validierung und Genehmigung von Modellen zu verfügen, bevor sie live gehen. Dies kann die Überprüfung auf Fairness, Voreingenommenheit und ethische Überlegungen beinhalten.
Welche Vorteile bietet MLOps?
Machine Learning hilft Unternehmen dabei, Daten zu analysieren und Erkenntnisse für die Entscheidungsfindung abzuleiten. Es ist jedoch ein innovatives und experimentelles Feld, das mit eigenen Herausforderungen verbunden ist. Der Schutz sensibler Daten, kleine Budgets, Fachkräftemangel und sich ständig weiterentwickelnde Technologien schränken den Erfolg eines Projekts ein. Ohne Kontrolle und Anleitung können die Kosten in die Höhe schnellen, und Datenwissenschaftsteams erzielen möglicherweise nicht die gewünschten Ergebnisse.
MLOps bietet einen Leitfaden, der ML-Projekte unabhängig von den Einschränkungen zum Erfolg führt. Hier sind einige der wichtigsten Vorteile von MLOps.
Schnellere Markteinführung
MLOps bietet Ihrem Unternehmen ein Framework, mit dem Sie Ihre datenwissenschaftlichen Ziele schneller und effizienter erreichen können. Ihre Entwickler und Manager können in der Modellverwaltung strategischer und agiler werden. ML-Techniker können die Infrastruktur über deklarative Konfigurationsdateien bereitstellen, um Projekte reibungsloser zu starten.
Die Automatisierung der Modellerstellung und -bereitstellung führt zu schnelleren Markteinführungszeiten bei niedrigeren Betriebskosten. Datenwissenschaftler können die Daten eines Unternehmens schnell untersuchen, um allen mehr Geschäftswert zu bieten.
Verbesserte Produktivität
MLOps-Praktiken steigern die Produktivität und beschleunigen die Entwicklung von ML-Modellen. Sie können beispielsweise die Entwicklungs- oder Experimentierumgebung standardisieren. Anschließend können Ihre ML-Techniker neue Projekte starten, zwischen Projekten rotieren und ML-Modelle anwendungsübergreifend wiederverwenden. Sie können wiederholbare Prozesse für schnelles Experimentieren und Modellschulung erstellen. Softwareentwicklungsteams können während des gesamten ML-Softwareentwicklungszyklus zusammenarbeiten und sich koordinieren, um die Effizienz zu steigern.
Effiziente Modellbereitstellung
MLOps verbessert die Fehlerbehebung und die Modellverwaltung in der Produktion. Softwareingenieure können beispielsweise die Modellleistung überwachen und das Verhalten zur Fehlerbehebung reproduzieren. Sie können Modellversionen verfolgen und zentral verwalten und die richtige Version für verschiedene Geschäftsanwendungsfälle auswählen.
Wenn Sie Modell-Workflows in CI/CD-Pipelines (Continuous Integration and Continuous Delivery) integrieren, begrenzen Sie Leistungseinbußen und sorgen für eine gleichbleibende Qualität Ihres Modells. Dies gilt auch nach Upgrades und Modelltunings.
Wie implementiert man MLOps in der Organisation
Es gibt drei Stufen der MLOps-Implementierung, abhängig vom Automatisierungsgrad in Ihrem Unternehmen.
MLOps Stufe 0
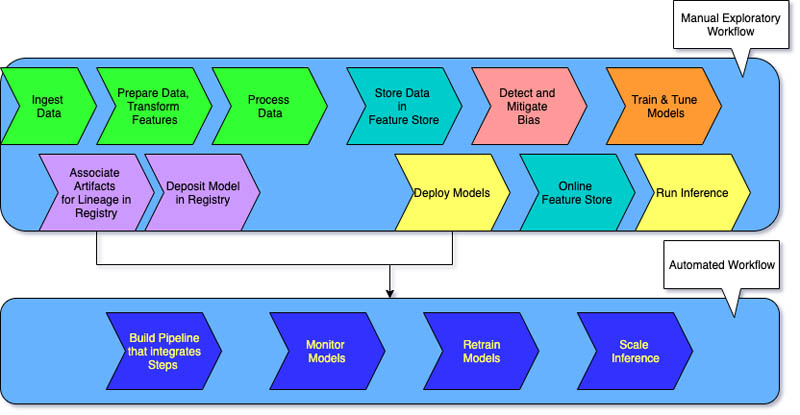
Manuelle ML-Workflows und ein von Datenwissenschaftlern gestützter Prozess kennzeichnen Stufe 0 für Unternehmen, die gerade erst mit Machine-Learning-Systemen beginnen.
Jeder Schritt erfolgt manuell, einschließlich Datenaufbereitung, ML-Training sowie Modellleistung und -validierung. Es erfordert einen manuellen Übergang zwischen den Schritten, und jeder Schritt wird interaktiv ausgeführt und verwaltet. Die Datenwissenschaftler übergeben trainierte Modelle in der Regel als Artefakte, die das Entwicklungsteam auf der API-Infrastruktur einsetzt.
Der Prozess unterscheidet zwischen Datenwissenschaftlern, die das Modell erstellen, und Ingenieuren, die es einsetzen. Unregelmäßige Veröffentlichungen bedeuten, dass die Datenwissenschaftsteams Modelle möglicherweise nur wenige Male im Jahr neu trainieren. Für ML-Modelle mit dem Rest des Anwendungscodes gibt es keine CI/CD-Überlegungen. Ebenso gibt es keine aktive Leistungsüberwachung.
MLOps Stufe 1
Unternehmen, die dieselben Modelle mit neuen Daten trainieren möchten, benötigen häufig eine Stufe-1-Reifegradimplementierung. MLOps Stufe 1 zielt darauf ab, das Modell kontinuierlich zu trainieren, indem die ML-Pipeline automatisiert wird.
In Stufe 0 stellen Sie ein trainiertes Modell in die Produktion ein. Im Gegensatz dazu stellen Sie für Stufe 1 eine Schulungspipeline bereit, die wiederholt ausgeführt wird, um das geschulte Modell für Ihre anderen Apps bereitzustellen. Sie erreichen mindestens eine kontinuierliche Bereitstellung des Modellvorhersagedienstes.
Der Reifegrad der Stufe 1 weist folgende Merkmale auf:
- Schnelle ML-Experimentschritte, die eine erhebliche Automatisierung beinhalten
- Kontinuierliche Schulung des Modells in der Produktion mit aktuellen Daten als Auslöser für die Live-Pipeline
- Gleiche Pipeline-Implementierung in Entwicklungs-, Vorproduktions- und Produktionsumgebungen
Ihre Entwicklungsteams arbeiten mit Datenwissenschaftlern zusammen, um modularisierte Codekomponenten zu erstellen, die wiederverwendbar, zusammensetzbar und potenziell über ML-Pipelines gemeinsam genutzt werden können. Sie erstellen auch einen zentralen Feature Store, der die Speicherung, den Zugriff und die Definition von Features für ML-Schulung und -Serving standardisiert. Darüber hinaus können Sie Metadaten verwalten, z. B. Informationen zu jedem Lauf der Pipeline und Reproduzierbarkeitsdaten.
MLOps Stufe 2
MLOps Stufe 2 richtet sich an Unternehmen, die mehr experimentieren und häufig neue Modelle entwickeln möchten, die kontinuierliche Schulung erfordern. Es eignet sich für technologieorientierte Unternehmen, die ihre Modelle innerhalb von Minuten aktualisieren, sie stündlich oder täglich neu trainieren und sie gleichzeitig auf Tausenden von Servern erneut einsetzen.
Da mehrere ML-Pipelines im Spiel sind, erfordert ein MLOps-Stufe-2-Setup das gesamte MLOps-Stufe-1-Setup. Zudem ist erforderlich:
- Ein ML-Pipeline-Orchestrator
- Ein Modellregister zur Nachverfolgung mehrerer Modelle
Die folgenden drei Phasen wiederholen sich maßstabsgetreu für mehrere ML-Pipelines, um die kontinuierliche Bereitstellung des Modells sicherzustellen.
Pipeline bauen
Sie probieren iterativ neue Modellierungs- und neue ML-Algorithmen aus und stellen gleichzeitig sicher, dass die Versuchsschritte orchestriert werden. In dieser Phase wird der Quellcode für Ihre ML-Pipelines ausgegeben. Sie speichern den Code in einem Quell-Repository.
Pipeline bereitstellen
Als Nächstes erstellen Sie den Quellcode und führen Tests durch, um Pipeline-Komponenten für die Bereitstellung zu erhalten. Die Ausgabe ist eine bereitgestellte Pipeline mit der neuen Modellimplementierung.
Pipeline bedienen
Schließlich stellen Sie die Pipeline als Prognosedienst für Ihre Anwendungen bereit. Sie sammeln Statistiken über den bereitgestellten Modellvorhersagedienst anhand von Live-Daten. Diese Stufenausgabe ist ein Auslöser für den Betrieb der Pipeline oder eines neuen Experimentzyklus.
Was ist der Unterschied zwischen MLOps und DevOps?
MLOps und DevOps sind beides Methoden, die darauf abzielen, Prozesse zu verbessern, bei denen Sie Softwareanwendungen entwickeln, bereitstellen und überwachen.
DevOps zielt darauf ab, die Lücke zwischen Entwicklungs- und Betriebsteams zu schließen. DevOps trägt dazu bei, dass Codeänderungen automatisch getestet, integriert und effizient und zuverlässig in der Produktion eingesetzt werden. Sie fördert eine Kultur der Zusammenarbeit, um schnellere Veröffentlichungszyklen, verbesserte Anwendungsqualität und effizientere Nutzung von Ressourcen zu erreichen.
MLOps hingegen ist eine Reihe von bewährten Methoden, die speziell für Machine-Learning-Projekte entwickelt wurden. Obwohl es relativ einfach sein kann, herkömmliche Software bereitzustellen und zu integrieren, stellen ML-Modelle einzigartige Herausforderungen dar. Sie umfassen Datenerfassung, Modelltraining, Validierung, Bereitstellung sowie kontinuierliche Überwachung und Umschulung.
MLOps konzentriert sich auf die Automatisierung des ML-Lebenszyklus. Sie trägt dazu bei, dass Modelle nicht nur entwickelt, sondern auch systematisch und wiederholt eingesetzt, überwacht und umgeschult werden. Es integriert DevOps-Prinzipien in ML. MLOps führt zu einer schnelleren Bereitstellung von ML-Modellen, zu einer höheren Genauigkeit im Laufe der Zeit und zu einer größeren Sicherheit, dass sie einen echten geschäftlichen Nutzen bieten.
Wie kann AWS Ihre MLOps-Anforderungen unterstützen?
Amazon SageMaker ist ein vollständig verwalteter Service, mit dem Sie Daten vorbereiten und ML-Modelle erstellen, trainieren und bereitstellen können. Sie eignet sich für jeden Anwendungsfall mit vollständig verwalteter Infrastruktur, Tools und Workflows.
SageMaker bietet speziell entwickelte Tools für MLOps zur Automatisierung von Prozessen im gesamten ML-Lebenszyklus. Durch die Verwendung von Sagemaker for MLOps Tools können Sie schnell und in großem Umfang MLOps-Reifegrad der Stufe 2 erreichen.
Hier sind die wichtigsten Features von SageMaker, die Sie verwenden können:
- Verwenden Sie SageMaker Experimente, um Artefakte im Zusammenhang mit Ihren Modelltrainingsaufträgen zu verfolgen, wie Parameter, Metriken und Datensätze.
- Konfigurieren Sie SageMaker-Pipelines so, dass sie automatisch in regelmäßigen Abständen oder bei Auslösung bestimmter Ereignisse ausgeführt werden.
- Verwenden Sie SageMaker Model Registry, um Modellversionen nachzuverfolgen. Sie können auch ihre Metadaten verfolgen, z. B. die Gruppierung von Anwendungsfällen, und Baselines für Leistungsmetriken in einem zentralen Repository modellieren. Sie können diese Informationen verwenden, um das beste Modell für Ihre Geschäftsanforderungen auszuwählen.
Beginnen Sie mit MLOps auf Amazon Web Services (AWS), indem Sie noch heute ein Konto erstellen.
Nächste Schritte mit AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages