Was ist verstärkendes Lernen?
Was ist verstärkendes Lernen?
Reinforcement Learning (RL) ist eine Technik des maschinellen Lernens (ML), bei der Software trainiert wird, Entscheidungen zu treffen, um optimale Ergebnisse zu erzielen. Es ahmt den Lernprozess nach, mit dem Menschen durch Versuch und Irrtum ihre Ziele erreichen. Softwareaktionen, die auf Ihr Ziel hinarbeiten, werden verstärkt, während Aktionen, die vom Ziel ablenken, ignoriert werden.
RL-Algorithmen verwenden bei der Verarbeitung von Daten ein Belohnungs- und Bestrafungsparadigma. Sie lernen aus dem Feedback jeder Aktion und finden selbst heraus, welche Verarbeitungswege am besten geeignet sind, um Endergebnisse zu erzielen. Die Algorithmen sind auch in der Lage, die Befriedigung zu verzögern. Die beste Gesamtstrategie kann kurzfristige Opfer erfordern. Daher kann der beste Ansatz, den sie entdecken, einige Strafen oder Rückschritte beinhalten. RL ist eine leistungsstarke Methode, mit der Systeme künstlicher Intelligenz (KI) in unsichtbaren Umgebungen optimale Ergebnisse erzielen können.
Was sind die Vorteile von Reinforcement Learning?
Der Einsatz von Reinforcement Learning (RL) bietet viele Vorteile. Diese drei sind jedoch hervorzuheben.
Hervorragend in komplexen Umgebungen
RL-Algorithmen können in komplexen Umgebungen mit vielen Regeln und Abhängigkeiten eingesetzt werden. In derselben Umgebung ist ein Mensch möglicherweise nicht in der Lage, den besten Weg zu bestimmen, selbst wenn er die Umgebung besser kennt. Stattdessen passen sich modellfreie RL-Algorithmen schnell an sich ständig ändernde Umgebungen an und finden neue Strategien zur Optimierung der Ergebnisse.
Erfordert weniger menschliche Interaktion
Bei herkömmlichen ML-Algorithmen müssen Menschen Datenpaare kennzeichnen, um den Algorithmus zu steuern. Wenn Sie einen RL-Algorithmus verwenden, ist dies nicht erforderlich. Es lernt von selbst. Gleichzeitig bietet es Mechanismen zur Integration von menschlichem Feedback und ermöglicht Systeme, die sich an menschliche Präferenzen, Fachkenntnisse und Korrekturen anpassen.
Optimiert für langfristige Ziele
RL konzentriert sich von Natur aus auf die langfristige Maximierung der Belohnung und eignet sich daher für Szenarien, in denen Maßnahmen anhaltende Konsequenzen haben. Es eignet sich besonders gut für reale Situationen, in denen Feedback nicht sofort für jeden Schritt verfügbar ist, da es aus verzögerten Belohnungen lernen kann.
Entscheidungen über den Energieverbrauch oder die Speicherung könnten beispielsweise langfristige Folgen haben. RL kann verwendet werden, um die Energieeffizienz und die Kosten langfristig zu optimieren. Mit geeigneten Architekturen können RL-Agenten ihre erlernten Strategien auch auf ähnliche, aber nicht identische Aufgaben verallgemeinern.
Was sind die Anwendungsfälle von Reinforcement Learning?
Reinforcement Learning (RL) kann auf eine Vielzahl von realen Anwendungsfällen angewendet werden. Im Folgenden geben wir einige Beispiele.
Personalisierung des Marketings
In Anwendungen wie Empfehlungssystemen kann RL Vorschläge an einzelne Benutzer auf der Grundlage ihrer Interaktionen anpassen. Dies führt zu personalisierteren Erlebnissen. Beispielsweise kann eine Anwendung einem Benutzer Werbung anzeigen, die auf einigen demografischen Informationen basieren. Bei jeder Werbungsinteraktion lernt die Anwendung, welche Werbung dem Nutzer angezeigt werden soll, um den Produktverkauf zu optimieren.
Herausforderungen bei der Optimierung
Herkömmliche Optimierungsmethoden lösen Probleme, indem sie mögliche Lösungen anhand bestimmter Kriterien bewerten und vergleichen. Im Gegensatz dazu lernt RL aus Interaktionen, um im Laufe der Zeit die besten oder bestmöglichen Lösungen zu finden.
Beispielsweise verwendet ein System zur Optimierung der Cloud-Ausgaben RL, um sich an schwankende Ressourcenanforderungen anzupassen und optimale Instance-Typen, Mengen und Konfigurationen auszuwählen. Es trifft Entscheidungen auf der Grundlage von Faktoren wie der aktuellen und verfügbaren Cloud-Infrastruktur, den Ausgaben und der Nutzung.
Finanzielle Prognosen
Die Dynamik der Finanzmärkte ist komplex und ihre statistischen Eigenschaften ändern sich im Laufe der Zeit. RL-Algorithmen können langfristige Renditen optimieren, indem sie Transaktionskosten berücksichtigen und sich an Marktveränderungen anpassen.
Ein Algorithmus könnte beispielsweise die Regeln und Muster der Börse beobachten, bevor er Aktionen testet und die damit verbundenen Belohnungen aufzeichnet. Es erstellt dynamisch eine Wertfunktion und entwickelt eine Strategie zur Gewinnmaximierung.
Wie funktioniert Reinforcement-Learning?
Der Lernprozess von Reinforcement-Learning-Algorithmen (RL) ähnelt dem Verstärkungslernen von Tieren und Menschen im Bereich der Verhaltenspsychologie. Ein Kind kann zum Beispiel feststellen, dass es von den Eltern gelobt wird, wenn es einem Geschwister hilft oder putzt, aber negative Reaktionen bekommt, wenn es Spielzeug wirft oder schreit. Bald lernt das Kind, welche Kombination von Aktivitäten am Ende zur Belohnung führt.
Ein RL-Algorithmus ahmt einen ähnlichen Lernprozess nach. Es werden verschiedene Aktivitäten ausprobiert, um die damit verbundenen negativen und positiven Werte zu lernen, um das Endergebnis der Belohnung zu erzielen.
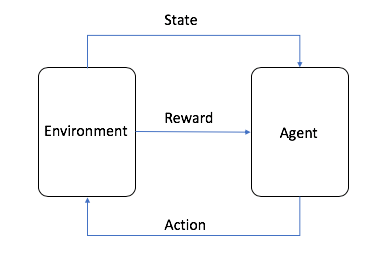
Wichtige Konzepte
Beim Reinforcement-Learning gibt es einige Schlüsselkonzepte, mit denen Sie sich vertraut machen sollten:
- Der Agent ist der ML-Algorithmus (oder das autonome System)
- Die Umgebung ist der adaptive Problemraum mit Attributen wie Variablen, Grenzwerten, Regeln und gültigen Aktionen
- Die Aktion ist ein Schritt, den der RL-Agent unternimmt, um in der Umgebung zu navigieren.
- Der Staat ist die Umwelt zu einem bestimmten Zeitpunkt
- Die Belohnung ist der positive, negative oder Nullwert – mit anderen Worten, die Belohnung oder Bestrafung – für das Ergreifen einer Handlung
- Die kumulative Belohnung ist die Summe aller Prämien oder der Endwert
Grundlagen des Algorithmus
Reinforcement Learning basiert auf dem Markov-Entscheidungsprozess, einer mathematischen Modellierung der Entscheidungsfindung, die diskrete Zeitschritte verwendet. Bei jedem Schritt ergreift der Agent eine neue Aktion, die zu einem neuen Umgebungsstatus führt. In ähnlicher Weise wird der aktuelle Status der Reihenfolge früherer Aktionen zugeschrieben.
Durch Versuch und Irrtum beim Durchlaufen der Umgebung erstellt der Agent eine Reihe von Wenn-Dann-Regeln oder Richtlinien. Die Richtlinien helfen ihr bei der Entscheidung, welche Maßnahmen als Nächstes ergriffen werden müssen, um eine optimale kumulative Belohnung zu erzielen. Der Agent muss außerdem wählen, ob er die Umgebung weiter erkunden möchte, um neue Belohnungen für staatliche Aktionen zu erhalten, oder ob er bekannte Aktionen mit hoher Belohnung aus einem bestimmten Zustand auswählen möchte. Dies wird als Kompromiss zwischen Exploration und Ausbeutung bezeichnet.
Was sind die Arten von Reinforcement-Learning-Algorithmen?
Beim Reinforcement Learning (RL) kommen verschiedene Algorithmen zum Einsatz – etwa Q-Learning, Policy-Gradient-Methoden, Monte-Carlo-Methoden und Temporal Difference Learning. Deep RL ist die Anwendung tiefer neuronaler Netze für Reinforcment Learning. Ein Beispiel für einen tiefen RL-Algorithmus ist Trust Region Policy Optimization (TRPO).
All diese Algorithmen können in zwei große Kategorien eingeteilt werden.
Modellbasiertes RL
Modellbasiertes RL wird in der Regel verwendet, wenn Umgebungen klar definiert und unveränderlich sind und wenn Tests in realen Umgebungen schwierig sind.
Der Agent erstellt zunächst eine interne Repräsentation (Modell) der Umgebung. Er verwendet diesen Prozess, um dieses Modell zu erstellen:
- Er ergreift Maßnahmen innerhalb der Umgebung und notiert den neuen Zustand und den Belohnungswert
- Er verbindet den Übergang in den Aktionszustand mit dem Belohnungswert.
Sobald das Modell fertiggestellt ist, simuliert der Agent Aktionssequenzen auf der Grundlage der Wahrscheinlichkeit optimaler kumulativer Belohnungen. Anschließend weist es den Aktionssequenzen selbst weitere Werte zu. Der Agent entwickelt somit verschiedene Strategien innerhalb der Umgebung, um das gewünschte Endziel zu erreichen.
Beispiel
Stellen Sie sich einen Roboter vor, der lernt, in einem neuen Gebäude zu navigieren, um einen bestimmten Raum zu erreichen. Zunächst erkundet der Roboter frei und erstellt ein internes Modell (oder eine Karte) des Gebäudes. Zum Beispiel könnte er lernen, dass er auf einen Aufzug trifft, nachdem er sich 10 Meter vom Haupteingang vorwärts bewegt hat. Sobald er die Karte erstellt hat, kann er eine Reihe von Sequenzen mit kürzesten Pfaden zwischen verschiedenen Orten im Gebäude erstellen, die er häufig besucht.
Modellfreies RL
Modellfreies RL eignet sich am besten, wenn die Umgebung groß, komplex und nicht leicht beschreibbar ist. Es ist auch ideal, wenn die Umgebung unbekannt ist und sich ändert und umgebungsbasiertes Testen keine wesentlichen Nachteile mit sich bringt.
Der Agent erstellt kein internes Modell der Umgebung und ihrer Dynamik. Stattdessen wird innerhalb der Umgebung ein Trial-and-Error-Ansatz verwendet. Er bewertet und notiert Zustands-/Aktions-Paare – und Sequenzen von Zustands-/Aktions-Paaren –, um eine Herangehensweise zu entwickeln.
Beispiel
Stellen Sie sich ein selbstfahrendes Auto vor, das sich im Stadtverkehr zurechtfinden muss. Straßen, Verkehrsmuster, Fußgängerverhalten und unzählige andere Faktoren können die Umwelt hochdynamisch und komplex machen. KI-Teams trainieren das Fahrzeug in der Anfangsphase in einer simulierten Umgebung. Das Fahrzeug ergreift auf der Grundlage seines aktuellen Zustands Maßnahmen und erhält Belohnungen oder Strafen.
Im Laufe der Zeit lernt das Fahrzeug, indem es Millionen von Kilometern in verschiedenen virtuellen Szenarien zurücklegt, welche Aktionen für jeden Zustand am besten geeignet sind, ohne die gesamte Verkehrsdynamik explizit zu modellieren. Bei der Einführung in der realen Welt verwendet das Fahrzeug die erlernte Herangehensweise, verfeinert sie jedoch weiterhin mit neuen Daten.
Was ist der Unterschied zwischen Reinforcement-, überwachtem und unüberwachtem Machine Learning?
Während überwachtes Lernen, unüberwachtes Lernen und Reinforcement Learning (RL) allesamt ML-Algorithmen im Bereich KI sind, gibt es Unterschiede zwischen den dreien.
Mehr über überwachtes und unüberwachtes Lernen lesen »
Reinforcement Learning vs. überwachtes Lernen
Beim überwachten Lernen definieren Sie sowohl die Eingabe als auch die erwartete zugehörige Ausgabe. Sie können beispielsweise eine Reihe von Bildern mit der Bezeichnung Hunde oder Katzen bereitstellen, und es wird erwartet, dass der Algorithmus dann ein neues Tierbild als Hund oder Katze identifiziert.
Algorithmen für überwachtes Lernen lernen Muster und Beziehungen zwischen den Eingabe- und Ausgabepaaren. Anschließend prognostizieren sie Ergebnisse auf der Grundlage neuer Eingabedaten. Es erfordert, dass ein Supervisor, in der Regel ein Mensch, jeden Datensatz in einem Trainingsdatensatz mit einer Ausgabe kennzeichnet.
Im Gegensatz dazu hat RL ein klar definiertes Endziel in Form eines gewünschten Ergebnisses, aber keinen Supervisor, der die zugehörigen Daten im Voraus kennzeichnet. Während des Trainings versucht es nicht, Eingaben bekannten Ausgaben zuzuordnen, sondern Eingaben möglichen Ergebnissen zuzuordnen. Indem Sie erwünschte Verhaltensweisen belohnen, gewichten Sie die besten Ergebnisse.
Reinforcement Learning vs. unüberwachtes Lernen
Algorithmen für unüberwachtes Lernen empfangen während des Trainingsprozesses Eingaben ohne spezifizierte Ausgaben. Mit statistischen Mitteln finden sie versteckte Muster und Zusammenhänge innerhalb der Daten. Sie könnten beispielsweise eine Reihe von Dokumenten bereitstellen, und der Algorithmus kann sie in Kategorien gruppieren, die er anhand der Wörter im Text identifiziert. Sie erhalten keine spezifischen Ergebnisse; sie liegen innerhalb einer bestimmten Bandbreite.
Umgekehrt hat RL ein vorgegebenes Endziel. Obwohl es sich um einen explorativen Ansatz handelt, werden die Erkundungen kontinuierlich validiert und verbessert, um die Wahrscheinlichkeit zu erhöhen, dass das Endziel erreicht wird. Es kann sich selbst beibringen, ganz bestimmte Ergebnisse zu erzielen.
Was sind die Herausforderungen beim Reinforcement Learning?
Obwohl Reinforcement-Learning-Anwendungen (RL) die Welt potenziell verändern können, ist es möglicherweise nicht einfach, diese Algorithmen einzusetzen.
Praktikabilität
Das Experimentieren mit realen Belohnungs- und Bestrafungssystemen ist möglicherweise nicht praktikabel. Zum Beispiel würde das Testen einer Drohne in der realen Welt ohne vorherige Tests in einem Simulator zu einer erheblichen Anzahl kaputter Fluggeräte führen. Reale Umgebungen ändern sich häufig, erheblich und mit begrenzter Vorwarnung. Dies kann es für den Algorithmus schwieriger machen, in der Praxis effektiv zu sein.
Interpretierbarkeit
Wie jedes Wissenschaftsgebiet befasst sich auch die Datenwissenschaft mit aussagekräftigen Forschungen und Erkenntnissen, um Standards und Verfahren festzulegen. Datenwissenschaftler bevorzugen es zu wissen, wie eine bestimmte Schlussfolgerung aus Gründen der Beweisbarkeit und Replikation gezogen wurde.
Bei komplexen RL-Algorithmen kann es schwierig sein, die Gründe zu ermitteln, warum eine bestimmte Abfolge von Schritten unternommen wurde. Welche Aktionen in einer Sequenz haben zum optimalen Endergebnis geführt? Dies kann schwer abzuleiten sein, was zu Schwierigkeiten bei der Implementierung führt.
Wie kann AWS beim Reinforcement Learning helfen?
Amazon Web Services (AWS) bietet zahlreiche Angebote, die Sie bei der Entwicklung, Schulung und Bereitstellung von Reinforcement-Learning-Algorithmen (RL) für reale Anwendungen unterstützen.
Mit Amazon SageMaker können Entwickler und Datenwissenschaftler schnell und einfach skalierbare RL-Modelle entwickeln. Kombinieren Sie ein Deep-Learning-Framework (wie TensorFlow oder Apache MXNet), ein RL-Toolkit (wie RL Coach oder RLlib) und eine Umgebung, um ein reales Szenario nachzuahmen. Sie können es verwenden, um Ihr Modell zu erstellen und zu testen.
Mit AWS RoboMaker können Entwickler Simulationen mit RL-Algorithmen für Robotik ohne Infrastrukturanforderungen ausführen, skalieren und automatisieren.
Holen Sie sich praktische Erfahrungen mit AWS DeepRacer, dem vollautonomen Rennwagen im Maßstab 1:18. Er verfügt über eine vollständig konfigurierte Cloud-Umgebung, mit der Sie Ihre RL-Modelle und neuronalen Netzwerkkonfigurationen trainieren können.
Beginnen Sie mit Reinforcement Learning auf AWS, indem Sie noch heute ein Konto erstellen.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages