AWS Storage Blog

Unlocking data residency use cases with Amazon S3 in AWS Local Zones
Organizations running workloads in metros and geographies far from major cloud infrastructure need scalable, fully managed object storage, but regulations or business requirements mandate that data stays within specific national or metropolitan boundaries. This is particularly true for financial services, healthcare, and public sector, where compliance frameworks not only dictate where primary data resides but […]
Optimize Amazon EBS volumes to get the right performance at the right time
Business-critical applications depend on reliable storage performance. However, workloads aren’t static and can vary by time of day, day of week, or business cycle. Matching storage performance to these shifting demands is essential for maintaining application reliability without overspending. Under-provisioning can affect your applications when demand peaks, while provisioning too much for too long means […]

Manage storage consumption at scale using quotas on Amazon FSx for NetApp ONTAP
Learn how to configure ONTAP tree quotas on Amazon FSx for NetApp ONTAP to enforce per-workload capacity boundaries within a shared volume. This post walks through creating qtrees, defining quota policy rules with hard limits, soft limits, and thresholds, activating enforcement, and monitoring consumption using native quota reports and EMS events.

How Vanderbilt University scales digital archive discovery with Amazon S3 Metadata
Managing massive digital collections is hard. When you’re preserving decades of historical content and adding new materials daily, making that content discoverable matters more than the storage itself. Vanderbilt University Library discovered this firsthand while managing their extensive digital archives, including the renowned Vanderbilt Television News Archive (VTNA). Amazon S3 Metadata accelerates data discovery by […]

Zero-downtime Amazon S3 Versioning: Architectural patterns for mission-critical workloads
Organizations delivering content on a global scale rely on distributed edge networks to cache and serve billions of requests daily. These architectures depend on highly aggressive Time-To-Live (TTL) configurations to maximize performance and minimize origin load. On a cache miss, the network falls through to the origin to retrieve the requested content. At this scale, […]
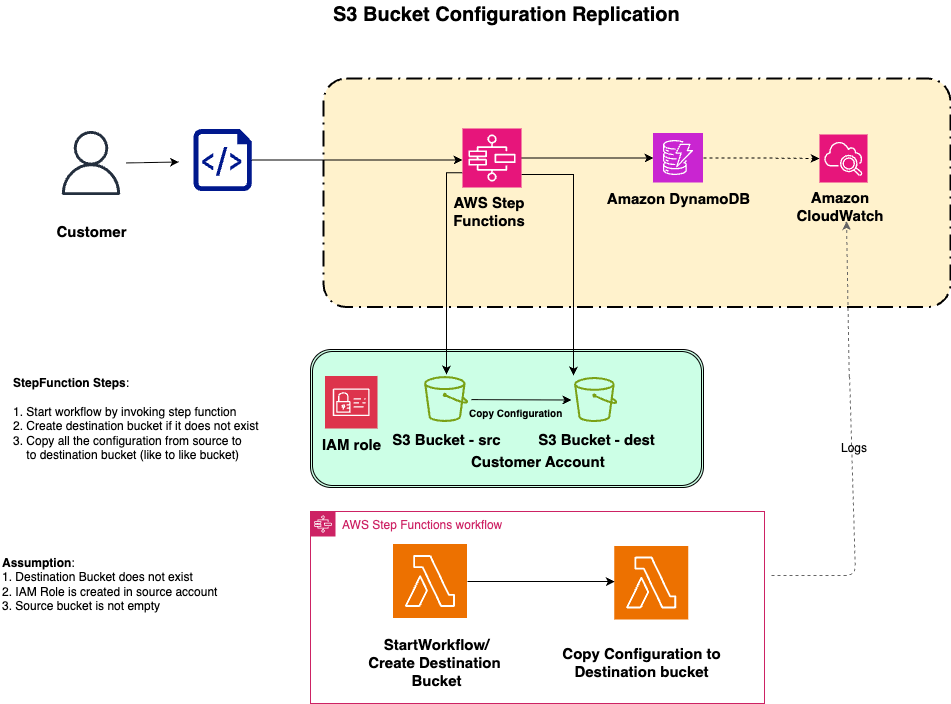
Replicate Amazon S3 bucket configurations across AWS Regions with AWS Step Functions
Many organizations operate thousands of Amazon S3 buckets in a single AWS Region, each with its own configuration accumulated over the years. Some were created manually in the AWS Management Console and others by scripts that are no longer actively maintained, provisioned by different business units with their own policies, lifecycle rules, encryption, and tags. […]
Integrating Amazon FSx for NetApp ONTAP and Amazon FSx for Windows File Server using Microsoft Entra Domain Services
Organizations are increasingly adopting cloud-based identity solutions to reduce infrastructure overhead and improve their security posture. For customers running file workloads on AWS, both Amazon FSx for NetApp ONTAP and Amazon FSx for Windows File Server require joining a Microsoft Active Directory domain to serve SMB file shares and support Windows-based authentication. When customers have […]

Query Amazon S3 access logs instantly with CloudWatch and S3 Tables
Knowing who accessed your data, when, and how is the foundation for security investigations, compliance audits, cost attribution, and performance troubleshooting. Detailed access logs capture every request: who made it, which resource was accessed, and what response was returned. In practice, though, they arrive as semi-structured records spread across different locations. Turning them into actionable […]
Simplify workforce data access with AWS Transfer Family web apps and Terraform
Enterprises increasingly need direct access to data stored in Amazon Simple Storage Service (Amazon S3) for analytics, reporting, collaboration, and decision-making. Enabling this access for non-technical users can be challenging: training staff on the AWS Management Console, building custom portals, or adopting third-party tools each carry trade-offs in cost, complexity, or security posture. And as […]

Gain workload-specific storage insights with Amazon S3 Storage Lens groups
As industries generate and store growing volumes of data, gaining meaningful insights into storage usage becomes increasingly complex. You need to understand your data growth patterns and drivers while optimizing storage investments across different business units and workloads. However, obtaining the necessary visibility by data categories, departments, or applications remains operationally difficult, limiting the ability […]