Quelle est la différence entre ETL et ELT ?
Quelle est la différence entre ETL et ELT ?
L'extraction, transformation et chargement (ETL) et l'extraction, chargement et transformation (ELT) sont deux approches de traitement des données destinées à l'analytique. Les grandes entreprises disposent de plusieurs centaines (voire de milliers) de sources de données provenant de tous les aspects de leurs opérations, tels que les applications, les capteurs, l'infrastructure informatique et les partenaires tiers. Ils doivent filtrer, trier et nettoyer ce volume de données important pour le rendre utile à des fins d'analytique et d'informatique décisionnelle. L'approche ETL utilise un ensemble de règles métier visant à traiter les données provenant de plusieurs sources avant l'intégration centralisée. L'approche ELT charge les données telles qu'elles sont et les transforme ultérieurement, en fonction du cas d'utilisation et des exigences analytiques. Le processus ETL nécessite davantage de définition au début. L'analytique doit être prise en compte dès le début, afin de définir les types, structures et relations des données. Les scientifiques des données recourent principalement à l'ETL pour charger les bases de données existantes dans l'entrepôt de données, tandis que l'ELT est devenue la norme actuelle.
Quelles sont les similitudes entre ETL et ELT ?
Tant l'extraction, transformation et chargement (ETL) que l'extraction, chargement et transformation (ELT) sont des séquences de processus qui préparent des données en vue d'une analytique plus approfondie. Ils capturent, traitent et chargent des données à des fins d'analytique en trois étapes.
Extraction
L'extraction est la première étape de l'ETL et de l'ELT. Cette étape consiste à collecter des données brutes provenant de différentes sources. Il peut s'agir de bases de données, de fichiers, d'applications de logiciel en tant que service (SaaS), de capteurs de l'Internet des objets (IoT) ou d'événements applicatifs. Vous pouvez collecter des données semi-structurées, structurées ou non structurées à ce stade.
Transformation
Dans le processus ETL, la transformation est la deuxième étape, tandis que dans l'ELT, c'est la troisième. Cette étape se concentre sur la modification des données brutes depuis leur structure d'origine vers un format qui répond aux exigences du système cible dans lequel vous prévoyez de stocker les données à des fins d'analytique. Voici quelques exemples de transformation :
- Modification des types ou des formats de données
- Suppression des données incohérentes ou inexactes.
- Suppression des doublons de données.
Vous appliquez des règles et des fonctions pour nettoyer et préparer les données en vue de leur analyse dans le système cible.
Chargement
Au cours de cette phase, vous stockez les données dans la base de données cible. Les processus ETL chargent les données comme étape finale, afin que les outils de création de rapports puissent les utiliser directement pour générer des rapports et des informations exploitables. Toutefois, dans ELT, vous devez toujours transformer les données extraites après les avoir chargées.
En quoi les processus ELT et ETL diffèrent-ils ?
Ci-après, nous décrivons les processus d'extraction, transformation et chargement (ETL) et d'extraction, chargement et transformation (ELT). Vous pouvez également lire quelques informations historiques.
Processus ETL
L'ETL comporte trois étapes :
- Vous extrayez des données brutes de différentes sources
- Vous utilisez un serveur de traitement secondaire pour transformer ces données
- Vous chargez ces données dans une base de données cible
L'étape de transformation garantit la conformité aux exigences structurelles de la base de données cible. Vous ne déplacez les données qu'une fois qu'elles sont transformées et prêtes.
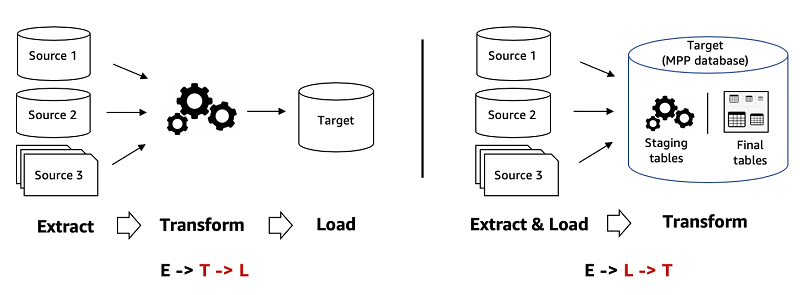
Processus ELT
Voici les trois étapes de l'ELT :
- Vous extrayez des données brutes de différentes sources
- Vous les chargez dans leur état naturel dans un entrepôt de données ou un lac de données
- Vous les transformez selon vos besoins dans le système cible
Avec l'ELT, tout le nettoyage, la transformation et l'enrichissement des données s'effectuent au sein de l'entrepôt de données. Vous pouvez interagir avec les données brutes et les transformer autant de fois que nécessaire.
Histoire de l'ETL et de l'ELT
L'ETL existe depuis les années 1970 et est devenu particulièrement populaire avec l'essor des entrepôts de données. Toutefois, les entrepôts de données traditionnels nécessitaient des processus ETL personnalisés pour chaque source de données.
L'évolution des technologies cloud a bouleversé ce qui était possible. Les entreprises peuvent désormais stocker un nombre illimité de données brutes à grande échelle et les analyser ultérieurement selon les besoins. L'ELT est devenue la méthode moderne d'intégration de données pour une analytique efficace.
Principales différences : ETL versus ELT
Le processus d'extraction, chargement et transformation (ELT) a amélioré celui de l'extraction, transformation et chargement (ETL) de plusieurs manières.
Emplacement de la transformation et du chargement
La transformation et le chargement se produisent à différents endroits et utilisent des processus distincts. Le processus ETL transforme les données sur un serveur de traitement secondaire.
En revanche, le processus ELT charge les données brutes directement dans l'entrepôt de données cible. Une fois sur place, vous pouvez transformer les données quand vous en avez besoin.
Compatibilité des données
L'ETL est particulièrement adapté aux données structurées que vous pouvez représenter dans des tableaux comportant des lignes et des colonnes. Il transforme un jeu de données structurées en un autre format structuré, puis le charge.
En revanche, l'ELT gère tous les types de données, y compris les données non structurées telles que les images ou les documents que vous ne pouvez pas stocker sous forme de tableau. Avec l'ELT, le processus charge les différents formats de données dans l'entrepôt de données cible. À partir de là, vous pouvez le transformer dans le format que vous souhaitez.
Rapidité
L'ELT est plus rapide que l'ETL. L'ETL comporte une étape supplémentaire avant de charger des données dans la cible, ce qui est difficile à dimensionner et ralentit le système à mesure que la taille des données augmente.
En revanche, l'ELT charge les données directement dans le système de destination et les transforme en parallèle. Il utilise la puissance de traitement et la parallélisation qu'offrent les entrepôts de données cloud pour effectuer une transformation des données en temps réel ou quasi réel à des fins d'analytique.
Coûts
Le processus ETL nécessite l'intervention de l'analytique dès le départ. Les analystes doivent planifier à l'avance les rapports qu'ils souhaitent générer et définir les structures et la mise en forme des données. Le temps nécessaire à la configuration augmente, ce qui augmente les coûts. Une infrastructure serveur supplémentaire pour les transformations peut également coûter plus cher.
L'ELT possède moins de systèmes que l'ETL, car toutes les transformations se produisent dans l'entrepôt de données cible. Avec moins de systèmes, il y a moins de maintenance à effectuer, ce qui permet de simplifier la pile de données et de réduire les coûts de configuration.
Sécurité
Lorsque vous travaillez avec des données personnelles, vous devez respecter les réglementations en matière de confidentialité des données. Les entreprises doivent protéger les données d'identification personnelle (PII) contre tout accès non autorisé.
Dans l'ETL, les développeurs doivent créer des solutions personnalisées, telles que le masquage des données d'identification personnelle pour surveiller et protéger les données.
D'autre part, les solutions ELT fournissent de nombreuses fonctionnalités de sécurité, telles que le contrôle d'accès granulaire et l'authentification multifactorielle, directement au sein de l'entrepôt de données. Vous pouvez consacrer plus de temps à l'analytique et moins de temps à répondre aux exigences en matière de réglementation des données.
Quand utiliser l'ETL par rapport à l' ELT
Extraction, chargement et transformation (ELT) est le choix standard pour l'analytique moderne. Toutefois, vous pouvez envisager l'extraction, transformation et chargement (ETL) dans les scénarios suivants.
Bases de données existantes
Il est parfois plus avantageux d'utiliser l'ETL pour intégrer des bases de données existantes ou des sources de données tierces avec des formats de données prédéterminés. Vous n'avez qu'à transformer et à charger une seule fois dans votre système. Une fois transformé, vous pouvez utiliser le jeu de données plus efficacement pour toute analytique future.
Expérimentation
Dans les grandes entreprises, les ingénieurs des données mènent des expériences, par exemple en découvrant des sources de données cachées à des fins d'analytique et en testant de nouvelles idées pour répondre aux demandes des entreprises. L'ETL est utile dans les expériences de données pour comprendre la base de données et son utilité dans un scénario particulier.
Analytique complexe
L'ETL et l'ELT peuvent tous deux être utilisés ensemble pour d'analytique complexe qui utilise plusieurs formats de données provenant de sources variées. Les scientifiques des données peuvent configurer des pipelines ETL à partir de certaines sources et utiliser l'ELT avec les autres. Cela améliore l'efficacité de l'analytique et augmente les performances des applications dans certains cas.
Applications IoT
Les applications de l'Internet des objets (IoT) qui utilisent des flux de données de capteurs bénéficient souvent de l'ETL plutôt que de l'ELT. À titre d'exemple, voici quelques cas d'utilisation courants de l'ETL en périphérie :
- Vous souhaitez recevoir des données provenant de différents protocoles et les convertir en formats de données standard pour les utiliser dans des charges de travail cloud
- Vous souhaitez filtrer des données à haute fréquence, effectuer des fonctions de calcul de moyenne sur de grands jeux de données, puis charger des valeurs moyennes ou filtrées à un rythme réduit
- Vous souhaitez calculer des valeurs à partir de sources de données disparates sur l'appareil local et envoyer des valeurs filtrées au backend cloud
- Vous souhaitez nettoyer, dédupliquer ou compléter des éléments de données de séries chronologiques manquants
Résumé des différences : ETL versus ELT
| Catégorie |
ETL |
ELT |
|
Signification |
Extraction, transformation et chargement |
Extraction, chargement et transformation |
|
Traitement |
Prend des données brutes, les transforme dans un format prédéterminé, puis les charge dans l'entrepôt de données cible. |
Prend des données brutes, les charge dans l'entrepôt de données cible, puis les transforme juste avant l'analyse. |
|
Lieux de transformation et de chargement |
La transformation s'effectue sur un serveur de traitement secondaire. |
La transformation a lieu dans l'entrepôt de données cible. |
|
Compatibilité des données |
Idéal avec des données structurées. |
Peut gérer des données structurées, non structurées et semi-structurées. |
|
Rapidité |
L'ETL est plus lent que l'ELT. |
L'ELT est plus rapide que l'ETL, car il peut utiliser les ressources internes de l'entrepôt de données. |
|
Coûts |
La configuration peut être longue et coûteuse en fonction des outils ETL utilisés. |
Plus rentable en fonction de l'infrastructure ELT utilisée. |
|
Sécurité |
Peut nécessiter la création d'applications personnalisées pour répondre aux exigences de protection des données. |
Vous pouvez utiliser les fonctionnalités intégrées de la base de données cible pour gérer la protection des données. |
Comment AWS peut-il répondre à vos exigences en matière d'ETL et d'ELT ?
Analytics on AWS décrit la vaste sélection de services d'analyse d'Amazon Web Services (AWS) qui répondent à tous vos besoins en matière d'analyse de données. Avec AWS, les organisations de toutes tailles et de tous secteurs peuvent réinventer leur activité grâce aux données.
Voici certains des services AWS que vous pouvez utiliser pour répondre à vos besoins en matière d'ETL et d'ELT :
- Amazon Aurora prend en charge l'intégration zéro ETL avec Amazon Redshift. Cette intégration permet l'analytique en temps quasi réel et le machine learning via Amazon Redshift sur des pétaoctets (Po) de données transactionnelles provenant d'Aurora.
- AWS Glue est un service d'intégration de données sans serveur pour les tâches ETL pilotées par des événements et les tâches ETL sans code.
- AWS IoT Greengrass prend en charge vos cas d'utilisation de l'ETL en périphérie en apportant le traitement et la logique du cloud localement aux appareils de périphérie.
- Amazon Redshift vous permet de configurer tous les flux de travail ELT et d'interroger directement des ensembles de données provenant de différentes sources.
Commencez à utiliser ELT et ETL sur AWS en créant un compte gratuit dès aujourd'hui.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages