Qual è la differenza tra apprendimento supervisionato e non supervisionato?
Argomenti della pagina
- Qual è la differenza tra machine learning supervisionato e non supervisionato?
- Tecniche di apprendimento supervisionato e non supervisionato
- Quando utilizzare l'apprendimento supervisionato oppure quello non supervisionato
- È possibile utilizzare insieme l'apprendimento supervisionato e quello non supervisionato?
- Riepilogo delle differenze tra apprendimento supervisionato e non supervisionato
- In che modo AWS può facilitare l'apprendimento supervisionato e non supervisionato?
Qual è la differenza tra machine learning supervisionato e non supervisionato?
L'apprendimento automatico (ML) supervisionato e non supervisionato sono due categorie di algoritmi ML . Gli algoritmi di ML elaborano grandi quantità di dati storici per identificare modelli di dati attraverso l'inferenza.
Gli algoritmi di apprendimento supervisionato vengono addestrati su dati di esempio che specificano sia l'input sia l'output dell'algoritmo. Ad esempio, i dati potrebbero consistere in immagini di numeri scritti a mano che sono state annotate indicando quali numeri rappresentano. Con un numero sufficiente di dati etichettati, nel corso del tempo, il sistema di apprendimento supervisionato sarebbe in grado di riconoscere i cluster di pixel e le forme associate a ciascun numero scritto a mano.
Di contro, gli algoritmi di apprendimento non supervisionato vengono addestrati sulla base di dati non etichettati. Possono esaminare nuovi dati e cercare di stabilire relazioni significative tra l'input sconosciuto e gli output predeterminati. Ad esempio, gli algoritmi di apprendimento non supervisionato possono raggruppare articoli da diversi siti di notizie in categorie comuni come sport, cronaca, ecc.
Tecniche di apprendimento supervisionato e non supervisionato
Nel machine learning, si "insegna" a un computer a fare previsioni o inferenze. Innanzitutto, si utilizzano un algoritmo e dati di esempio per addestrare un modello. Quindi, si integra il modello in un'applicazione per generare inferenze in tempo reale e su larga scala. L'apprendimento supervisionato e quello non supervisionato sono due categorie distinte di algoritmi.
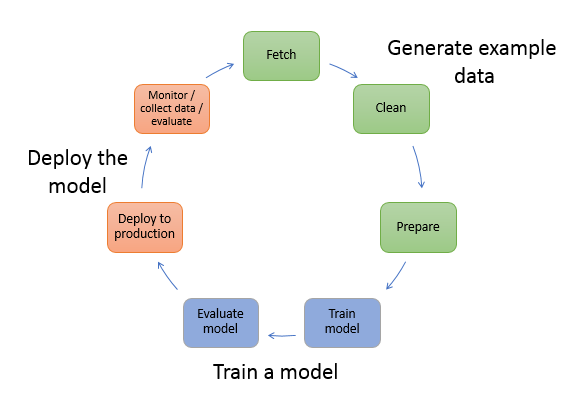
Apprendimento supervisionato
Nell'apprendimento supervisionato, si addestra il modello con una serie di dati di input e un set corrispondente di dati di output etichettati abbinati. L'etichettatura viene in genere eseguita manualmente. Di seguito sono riportati alcuni tipi di tecniche di machine learning supervisionato.
Regressione logistica
La regressione logistica prevede un output categorico basato su uno o più input. La classificazione binaria si verifica quando l'output rientra in una delle due categorie, ad esempio sì/no oppure esito positivo/negativo. La classificazione a classi multiple si verifica quando l'output rientra in più di due categorie, ad esempio gatto, cane o coniglio. Un esempio di regressione logistica consiste nel prevedere se uno studente supererà o fallirà un'unità in base al numero di accessi al materiale didattico.
Scopri di più sulla regressione logistica»
Regressione lineare
La regressione lineare si riferisce a modelli di apprendimento supervisionato che, sulla base di uno o più input, prevedono un valore lungo una scala continua. Un esempio di regressione lineare è la previsione del prezzo di una casa. È possibile prevedere il prezzo di una casa in base alla posizione, all'epoca di costruzione e al numero di camere, dopo aver addestrato un modello con una serie di dati storici delle vendite con tali variabili.
Scopri di più sulla regressione lineare»
Albero decisionale
La tecnica di machine learning supervisionato ad albero decisionale prende in considerazione alcuni input forniti e applica una struttura if-else per predire un risultato. Relativamente all'albero decisionale, un tipo di problema può essere la previsione del tasso di abbandono dei clienti. Ad esempio, se un cliente non visita un'applicazione dopo la registrazione, il modello potrebbe prevedere il tasso di abbandono. Oppure, se il cliente accede all'applicazione su più dispositivi e il tempo medio di sessione supera una determinata soglia, il modello potrebbe prevedere la fidelizzazione.
Rete neurale
Una soluzione di rete neurale è una tecnica di apprendimento supervisionato più complessa. Per produrre un determinato risultato, essa prende in considerazione alcuni input forniti e effettua una o più fasi di trasformazione matematica basate sull'aggiustamento dei pesi dei dati. Un esempio di tecnica di rete neurale è la previsione di una cifra da un'immagine scritta a mano.
Scopri di più sulle reti neurali»
Apprendimento non supervisionato
Il machine learning non supervisionato avviene quando si forniscono all'algoritmo dati di input senza dati di output etichettati. Quindi, da solo, l'algoritmo identifica modelli e relazioni all'interno e tra i dati. Di seguito sono riportati alcuni tipi di tecniche di apprendimento non supervisionato.
Raggruppamento
La tecnica di apprendimento non supervisionato con raggruppamento in cluster raggruppa determinati input di dati in modo che possano essere classificati nel loro insieme. Esistono vari tipi di algoritmi di raggruppamento in cluster a seconda dei dati di input. Un esempio di raggruppamento in cluster è l'identificazione di diversi tipi di traffico di rete per prevedere potenziali incidenti di sicurezza.
Apprendimento delle regole dell'associazione
Le tecniche di apprendimento delle regole di associazione individuano relazioni basate su regole tra gli input in un set di dati. Ad esempio, l'algoritmo Apriori svolge un'analisi del paniere di mercato per identificare regole come ad esempio il fatto che il caffè e il latte vengono spesso acquistati insieme.
Densità di probabilità
Le tecniche di densità di probabilità nell'apprendimento non supervisionato stimano la probabilità o la possibilità che il valore di un output si trovi all'interno dell'intervallo considerato normale per un input. Ad esempio, un indicatore di temperatura in una sala server generalmente registra valori compresi in un certo intervallo di gradi. Tuttavia, se improvvisamente misura un valore basso in base alla distribuzione di probabilità, ciò potrebbe indicare un malfunzionamento dell'apparecchiatura.
Riduzione della dimensionalità
La riduzione della dimensionalità è una tecnica di apprendimento non supervisionato che riduce il numero di caratteristiche in un set di dati. Viene spesso utilizzata per preparare i dati per altre funzioni di machine learning e ridurre la complessità e i costi aggiuntivi. Ad esempio, può sfocare o ritagliare le caratteristiche dello sfondo in un'applicazione di riconoscimento delle immagini.
Quando utilizzare l'apprendimento supervisionato oppure quello non supervisionato
È possibile utilizzare tecniche di apprendimento supervisionato per risolvere problemi con risultati noti e per i quali sono disponibili dati etichettati. Gli esempi includono la classificazione dello spam via e-mail, il riconoscimento delle immagini e le previsioni dei prezzi delle azioni basate su dati storici noti.
È possibile utilizzare l'apprendimento non supervisionato per scenari in cui i dati non sono etichettati e l'obiettivo è scoprire modelli, raggruppare istanze simili o rilevare anomalie. È possibile utilizzarlo anche per attività esplorative in cui non sono presenti dati etichettati. Gli esempi includono l'organizzazione di archivi di dati di grandi dimensioni, la creazione di sistemi di raccomandazione e il raggruppamento dei clienti in base ai loro comportamenti di acquisto.
È possibile utilizzare insieme l'apprendimento supervisionato e quello non supervisionato?
L'apprendimento semi-supervisionato si verifica quando si applicano tecniche di apprendimento supervisionato e non supervisionato a un problema comune. È una categoria di machine learning a sé stante.
È possibile applicare l'apprendimento semi-supervisionato quando è difficile ottenere etichette per un set di dati. Potresti avere un volume ridotto di dati etichettati ma una quantità significativa di dati non etichettati. Se combini tecniche di apprendimento supervisionato e non supervisionato, avrai una maggiore precisione ed efficienza che non utilizzando soltanto il set di dati etichettato.

Ecco alcuni esempi di applicazioni di apprendimento semi-supervisionato.
Identificazione delle frodi
All'interno di un ampio set di dati transazionali, esiste un sottoinsieme di dati etichettati in cui gli esperti hanno confermato transazioni fraudolente. Per un risultato più accurato, la soluzione di machine learning dovrebbe addestrarsi prima sui dati non etichettati e poi sui dati etichettati.
Analisi delle emozioni
Se si considera l'ampiezza delle interazioni testuali con i clienti di un'organizzazione, potrebbe non essere conveniente classificare o etichettare il sentiment su tutti i canali. Un'organizzazione potrebbe addestrare un modello prima sulla porzione più ampia di dati non etichettata e poi su un campione già etichettato. Ciò fornirebbe all'organizzazione un maggior grado di fiducia nel sentiment dei clienti in tutta l'azienda.
Classificazione dei documenti
Quando si applicano categorie a una base di documenti di grandi dimensioni, potrebbero esserci troppi documenti da etichettare fisicamente. Ad esempio, potrebbero esistere innumerevoli rapporti, trascrizioni o specifiche. L'addestramento iniziale sui dati non etichettati aiuta a identificare i documenti simili ai fini dell'etichettatura.
Riepilogo delle differenze tra apprendimento supervisionato e non supervisionato
|
|
Apprendimento senza supervisione |
|
|
Di che cosa si tratta? |
Si addestra il modello con un set di dati di input e un set corrispondente di dati di output etichettati accoppiati. |
Si addestra il modello per scoprire modelli nascosti in dati non etichettati. |
|
Tecniche |
Regressione logistica, regressione lineare, albero decisionale e rete neurale. |
Raggruppamento in cluster, apprendimento delle regole di associazione, densità di probabilità e riduzione della dimensionalità. |
|
Obiettivo |
Prevedere un output in base a input noti. |
Identificare informazioni preziose sulle relazioni tra i punti dati di input. Questo può quindi essere applicato a nuovi input per ricavare informazioni simili. |
|
Approccio |
Ridurre al minimo l'errore tra gli output previsti e le etichette reali. |
Trovare modelli, analogie o anomalie all'interno dei dati. |
In che modo AWS può facilitare l'apprendimento supervisionato e non supervisionato?
Amazon Web Services (AWS) offre un'ampia gamma di servizi per facilitare l'utilizzo del machine learning (ML) supervisionato, non supervisionato e semi-supervisionato. Puoi creare, eseguire e integrare soluzioni di qualsiasi dimensione, complessità o caso d'uso.
Amazon SageMaker è una piattaforma completa per creare soluzioni ML da zero. SageMaker dispone di una suite completa di modelli predefiniti di apprendimento supervisionato e non supervisionato, funzionalità di archiviazione e calcolo, e un ambiente completamente gestito.
Ad esempio, ecco le funzionalità di SageMaker che puoi utilizzare nel tuo lavoro:
-
Usa Amazon SageMaker Canvas per esplorare automaticamente diverse soluzioni e trovare il modello migliore per un determinato set di dati.
-
Usa Amazon SageMaker Data Wrangler per selezionare i dati, comprenderne le informazioni e trasformarli per prepararli al machine learning.
-
Usa Amazon SageMaker Experiments per analizzare e confrontare le iterazioni di formazione ML per scegliere il modello con le migliori prestazioni.
-
Usa Amazon SageMaker Clarify per rilevare e misurare potenziali distorsioni. In questo modo, gli sviluppatori di machine learning possono risolvere potenziali pregiudizi e spiegare le previsioni dei modelli.
Inizia a usare l'apprendimento automatico supervisionato e non supervisionato su AWS creando un account oggi stesso.
Fasi successive con AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages